Lindorm支援通過多種方式批量快速匯入資料,本文介紹在如何通過LTS操作頁面提交任務。
建立任務
登入LTS操作頁面,具體操作參見開通並登入LTS。
在左側導覽列,選擇資料來源管理 > 添加資料來源,添加以下資料來源。
添加ODPS資料來源,具體操作請參見ODPS資料來源。
添加Lindorm寬表資料來源,具體操作請參見Lindorm寬表資料來源。
添加HDFS資料來源,具體操作請參見添加HDFS資料來源。
在左側導覽列中,選擇。
說明3.8.12.4.3版本前的LTS請選擇。
LTS的版本可在Lindorm管理主控台執行個體詳情頁的配置資訊地區查看。
單擊建立任務,配置以下參數。
配置項
參數
描述
選擇資料來源
來源資料源
選擇添加的ODPS資料來源或者HDFS資料來源。
目標資料來源
選擇添加的Lindorm寬表資料來源。
檔案類型(非必選)
資料來源為HDFS/OSS時需要選擇讀取的檔案類型。
均衡分區
採樣百分比,具體說明可參見均衡分區。
點擊“均衡分區”選項,開啟均衡分區的能力。
在輸入框中輸入1-100整數數字,來表示採樣百分比(推薦值:1%-5%)。
外掛程式配置
Reader配置
讀外掛程式配置可參考Reader外掛程式配置樣本。
Writer配置
寫外掛程式配置可參考Writer外掛程式配置樣本。
作業運行參數配置
Executor數量
輸入Executor的數量。
任務的最大並發度等於
4 × Executor數量,請根據實際資源和負載需求謹慎配置 Executor數量。spark配置
輸入Spark配置,可不填寫。參數可參考計算引擎作業配置說明。
spark UDF
使用自訂的UDF。僅支援Java開發的UDF,Jar包請通過計算引擎控制台上傳,可參考通過控制台上傳檔案。
單擊建立。
在Bulkload頁面單擊任務名查看快速匯入資料任務。
單擊任務名,可以查看Spark任務的UI介面。
單擊詳情,可以查看Spark任務的執行日誌。
 說明
說明來源資料源遷移到Lindorm寬表,在Lindorm寬表中不同分區的資料分布均勻的情況下,資料容量為100 GB(壓縮比為1:4)壓縮後匯入大概需要1個小時,根據具體情況不同可能會有區別。
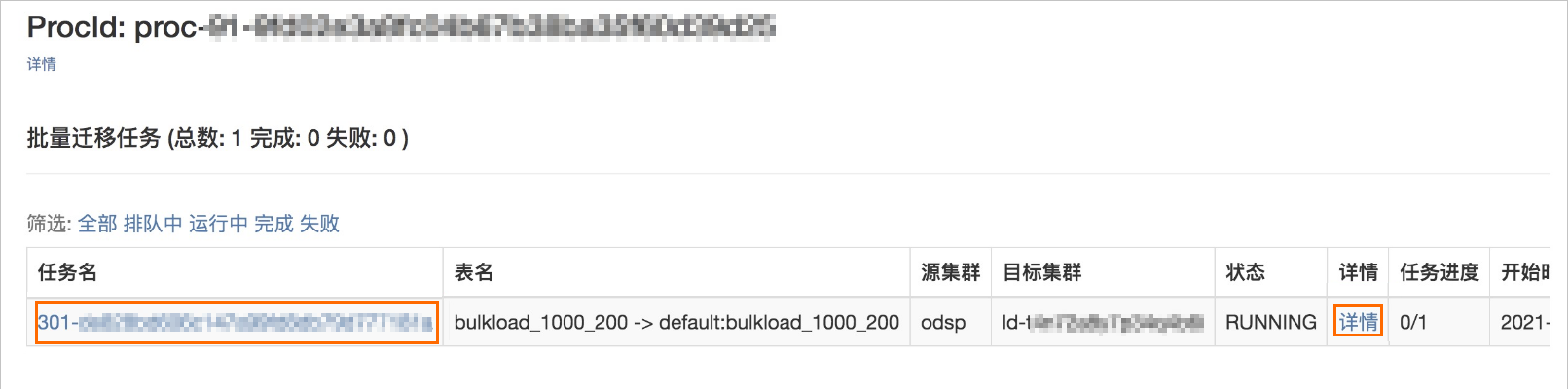
查看任務運行狀態
查看任務進度
點擊任務名列中的連結進入詳情頁。
等任務成功啟動後,點擊具體任務連結。
說明任務啟動需要一定時間,期間任務連結可能打不開,請耐心等待。
查看任務的整體進度。
查看任務日誌
支援通過多種方式查看任務日誌,包括控制台查看失敗日誌、完整記錄檔下載、以及作業記錄即時跟蹤,便於您按需排查問題。
當任務失敗後,在任務詳情中直接查看FAILED日誌。
在任務詳情中下載完整日誌。
在任務進度頁面中查看作業記錄。
均衡分區
應用情境
本功能專為批量資料匯入(Bulkload)模式設計,適用於以下典型情境:
初始建表資料匯入階段
當建立寬表首次進行資料匯入時,系統預設配置的分區數量可能無法匹配海量資料分布特性。若直接匯入,資料將在有限的分區中集中堆積,形成局部負載熱點,導致吞吐效率下降。非均勻資料來源處理情境
當來源資料本身存在分布不均衡時,常規分區策略會使資料在特定分區堆積,引發熱點任務拖慢整體進度,影響大量匯入效率。
技術原理
本功能通過動態分區最佳化演算法實現資料均衡分布,包含三階段智能處理流程:
採樣分析階段
系統抽取未經處理資料集1%-5%的樣本,分析其分布特徵。分區調整階段
基於分析結果,系統動態調整分區策略,確保資料均勻分布。全量匯入階段
在完成分區動態調整後,系統對全量資料啟動分布式並行匯入任務。
Reader外掛程式配置樣本
MaxCompute任務配置樣本
來源資料源為MaxCompute,MaxCompute資料的讀外掛程式配置樣本。
{
"table": "test",
"column": [
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
],
"partition": [
"ds=20250820,hh=12"
],
"numPartitions":10
}參數 | 描述 | 是否必選 | 預設值 |
table | MaxCompute表名。 | 是 | 無 |
column | 需要匯入的ODPS列名。 | 是 | 無 |
partition |
| 否 | 無 |
numPartitions | 讀取源表時的最大並發度,不寫則系統自動計算。 讀取資料需要消耗MaxCompute專案的Tunnel Slot資源,請仔細評估;若Slot資源不足,會導致任務失敗。 參考文檔:Data Transmission Service概述 | 否 | 無 |
Parquet檔案任務配置樣本
來源資料源為HDFS,Parquet檔案的讀外掛程式配置樣本。
{
"filePath":"parquet/",
"column": [ //parquet檔案中的列名
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
]
}參數 | 描述 | 是否必選 | 預設值 |
filePath | 資料所在的路徑,有以下四種情況:
| 是 | 無 |
column | 需要匯入的列名。 | 是 | 無 |
basePath | 指定分區資料集的根目錄,通常在需要擷取分區列的時候使用。
| 否 | 無 |
int96RebaseMode | int96時間戳記解析方式,解析舊版本int96類型需設定為:"LEGACY"。 | 否 | 無 |
pathGlobFilter | 路徑過濾器,支援glob模式的檔案路徑過濾,例如:*.parquet,唯讀取parquet檔案。 | 否 | 無 |
CSV檔案任務配置樣本
來源資料源為HDFS,CSV檔案的讀外掛程式配置樣本。
CSV為純文字格式檔案,配置任務時需要在"schema"中顯式地聲明所有欄位的類型
{
"filePath":"csv/",
"header": false,
"delimiter": ",",
"schema": [
"id|string",
"intcol|int",
"doublecol|double",
"stringcol|string",
"string1col|string",
"decimalcol|decimal"
],
"column": [
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
]
}參數 | 描述 | 是否必選 | 預設值 |
filePath | 資料所在的路徑,有以下四種情況:
| 是 | 無 |
schema | 申明csv檔案的所有列名和類型,格式為:列名|類型,例如:"id|string"。在申明時需要注意:
| 是 | 無 |
basePath | 指定分區資料集的根目錄,通常在需要擷取分區列的時候使用。
| 否 | 無 |
column | 需要匯入的列名,必須存在於上述schema申明中 。 | 是 | 無 |
nullValue | 把欄位中等於指定字串的值識別為 null。例如CSV中經常使用 “NULL” 或 “\N” 表示空值,可設定: "nullValue":"NULL"或 "nullValue":"\N"。 | 否 | 無 |
mode | 異常資料處理模式。
| 否 | PERMISSIVE |
timestampFormat | 時間戳記格式,若欄位以時間戳記類型解析時為必填,例如: "yyyy-MM-dd HH:mm:ss"。 | 否 | 無 |
dateFormat | 日期格式,若欄位以日期類型解析時為必填,例如:"yyyy-MM-dd" | 否 | 無 |
pathGlobFilter | 路徑過濾器,支援glob模式的檔案路徑過濾,例如:*.csv,唯讀取csv檔案。 | 否 | 無 |
ORC檔案任務配置樣本
來源資料源為HDFS,ORC檔案的讀外掛程式配置樣本。
{
"filePath":"orc/",
"column": [
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
]
}參數 | 描述 | 是否必選 | 預設值 |
filePath | 資料所在的路徑,有以下四種情況:
| 是 | 無 |
column | 需要匯入的列名。 | 是 | 無 |
basePath | 指定分區資料集的根目錄,通常在需要擷取分區列的時候使用。
| 否 | 無 |
pathGlobFilter | 路徑過濾器,支援glob模式的檔案路徑過濾,例如:*.orc,唯讀取orc檔案。 | 否 | 無 |
資料轉換配置樣本
注意事項
所有函數必須在reader的配置上使用,常見內建函數使用方法可參考函數說明。
MaxCompute、Parquet、ORC、CSV均支援資料轉換。
支援標準的Spark SQL內建函數,參考文檔:Spark SQL內建函數。
支援使用UDF函數,使用方式參考作業運行參數配置。
{
"column": [
"CAST(intcol as string)", //將整數轉為字串類型,無法轉換則報錯
"TRY_CAST('abc' as INT)", //嘗試轉換類型,失敗返回NULL
"COALESCE(nullable_stringcol,'')", //若欄位為NULL,則返回Null 字元串
"DATE_FORMAT('2023-08-15', 'MM/dd/yyyy')", //對日期進行格式化輸出
"UNIX_MILLIS(CURRENT_TIMESTAMP())", //擷取當前毫秒級時間戳記
"CONCAT(stringcol, 'hello', ' world')", //字串拼接
"SUBSTRING('Spark SQL', 7)", //提取子串,返回:'SQL'
"MD5(stringcol2)" //計算md5的值
]
}Writer外掛程式配置樣本
Lindorm SQL表匯入
匯入Lindorm SQL表格的寫外掛程式配置樣本。
{
"namespace": "default",
"lindormTable": "xxx",
"compression":"zstd",
"sortMode": "row",
"replication":2,
"columns": [
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
]
}Lindorm SQL表動態列匯入
匯入Lindorm SQL表動態列的寫外掛程式配置樣本。
動態列的Schema不持久化儲存,匯入時必須指定列簇和對應的資料類型。
{
"namespace": "default",
"lindormTable": "xxx",
"compression":"zstd",
"sortMode": "row",
"replication":2,
"columns": [
"id",
"intcol",
"doublecol",
"stringcol",
"f:dynamic_intcol||INT",
"f:dynamic_stringcol||STRING"
]
}Lindorm SQL多列簇表匯入
匯入Lindorm SQL多列簇表的寫外掛程式配置樣本。
多列簇表包含多個列簇,其中預設列簇名為'f',同時支援添加其他自訂欄簇(如'cf1'、'cf2')。
{
"namespace": "default",
"lindormTable": "xxx",
"compression":"zstd",
"sortMode": "row",
"replication":2,
"columns": [
"id",
"intcol",
"doublecol",
"stringcol",
"cf1:cf1_int",
"cf2:cf2_string"
]
}Lindorm相容HBase表格匯入
Lindorm相容HBase表格匯入的寫外掛程式配置樣本。
{
"namespace": "default",
"lindormTable": "xxx",
"compression":"zstd",
"sortMode": "row",
"replication":2,
"columns": [
"ROW||String", //ROW固定代表rowkey,String表示類型
"f:intcol||Int", //格式為列簇:列名||列類型
"f:doublecol||Double",
"f:stringcol||String",
"f:string1col||String",
"f:decimalcol||Decimal"
]
}使用API模式匯入Lindorm
當前Bulkload模式無法匯入索引表資料,若需在匯入主表資料時同步構建索引表,可使用API模式。
以下為使用API模式匯入Lindorm的寫外掛程式配置樣本。
使用API模式匯入資料時,會直接消耗Lindorm執行個體的資源,請務必限制匯入速率,防止影響線上生產服務效能。
{
"namespace": "default",
"lindormTable": "xxx",
"compression":"zstd",
"sortMode": "row",
"replication":2,
"columns": [
"id",
"intcol",
"doublecol",
"stringcol",
"string1col",
"decimalcol"
],
"writeMode":"api" //指定為API匯入模式
}Writer配置參數詳情
參數 | 描述 | 是否必選 | 預設值 |
namespace | Lindorm寬表的命名空間 | 是 | 無 |
lindormTable | Lindorm寬表的名稱 | 是 | 無 |
columns | 目標表的列映射配置,根據匯入至目標表類型填寫。
| 是 | 無 |
compression | 壓縮演算法,推薦使用zstd,其他可選snappy、gz、lzo,不使用壓縮演算法配置為none(預設值)。 | 否 | none(不用壓縮) |
timestamp | 指定時間戳記匯入(所有欄位共用一個時間戳記),不配置則預設為系統目前時間。支援以下類型:
| 否 | 系統時間 |
timeCol | 指定來源資料中某一列的值為時間戳記,每一行可以有不同的時間戳記,預設值為-1(無時間列)。
| 否 | -1(無時間列) |
sortMode | Bulkload匯入模式下的資料排序方式,支援row(行排序)和kv(索引值排序)兩種排序方式,預設值為kv。
| 否 | kv(索引值排序) |
replication | 寫入檔案的副本數,預設值為3,推薦2副本。 | 否 | 3 |
writeMode | 資料匯入的方式,分為bulkload和api兩種,預設為bulkload。
| 否 | bulkload |