本文介紹了時序表的索引機制,以及查詢時序表的最佳實務。
背景資訊
時序資料的模型請參見如何設計時序資料表,資料是按照時間序列來進行組織的。所以在時序資料表中,所有標記TAG的列(標籤列)會被建立為索引列,來表示每一條資料具體所屬於哪個時間序列,從而顯示資料的來源。
以時序資料表為例,具體請參見如何設計時序資料表,這些資料都屬於同一個時間序列,如下圖所示。
如果標籤列的值發生變化,則資料將屬於不同的時間序列。通常情況下,一個時間序列可以標記一個產生時序資料的資料來源。
時序引擎會根據每個標籤列建立索引,其索引形態是倒排索引,以標籤列的列名和值作為索引鍵來索引所有擁有該索引值對的時間序列,用於從時間序列維度快速定位某個標籤對應的資料範圍。隨著資料的不斷寫入,時序資料表的倒排索引將會呈現以下形態。
對於時間戳記列,時序引擎會預設建立資料區塊範圍索引,確保在海量時序資料中快速定位到需要查詢的資料範圍。但對於普通的Field列,時序引擎不會對資料建立索引。
使用建議
結合時序引擎的內部索引機制,對Lindorm時序引擎的時序表進行查詢時需要考慮以下幾點:
建議在查詢的條件陳述式中增加標籤列的等值過濾條件陳述式和時間戳記列的過濾條件陳述式,避免條件陳述式中只有Field列過濾語句。
查詢的條件陳述式中如果包含多個標籤列過濾條件,且這幾個標籤列映射的時間軸範圍存在內含項目關聯性,建議只需要保留選擇區分度最高的標籤列的過濾條件(例如上圖中的id列相對city列選擇區分度更高)。
查詢條件覆蓋的時間範圍過大可能會導致掃描過多的資料,進而導致查詢速度過慢,在這種情況下建議您可以縮小時間戳記列的過濾範圍來提高查詢效能。
常見的時序查詢情境和查詢操作
如果需要複現以下查詢情境的結果,請下載相應的SQL指令碼語句填寫範例資料。
查詢時間範圍內的原始點
使用以下語句查詢餘杭區內裝置從2019-04-18 10:00:00至2019-04-18 10:30:00上報的全部SO2監控指標。
SELECT id, so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00';查詢結果如下。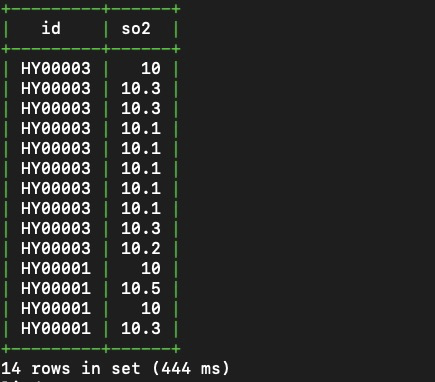
查詢時序資料表中特定標籤列的所有標籤值
當將許多同類裝置上報的資料接入到一張時序資料表中之後,有時會需要查詢接入裝置的某個標籤的標籤值。例如下述SQL就可以查詢時序資料表 aqm 中接入的所有空氣品質監控裝置的裝置id:
SELECT DISTINCT(id) FROM aqm;查詢結果如下。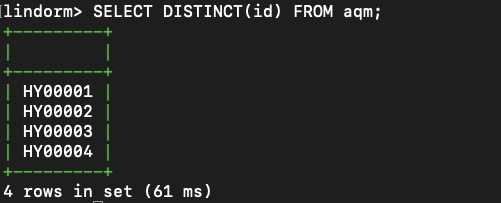
對於標籤列的查詢在儲存引擎層面預設會基於標籤索引進行查詢,因此無需擔心這樣的查詢會走全表掃描而產生效能問題。但若已接入的裝置量非常多時,即使是走標籤索引其查詢耗時也可能會較長。
查詢時間精度的降採樣
查詢餘杭區內裝置從2019-04-18 10:00:00至2019-04-18 10:30:00上報的PM2.5和SO2監控指標,按5分鐘為粒度求平均值。
SELECT id, time, avg(pm2_5) AS avg_pm2_5, avg(so2) AS avg_so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00' SAMPLE BY 5m;查詢結果如下。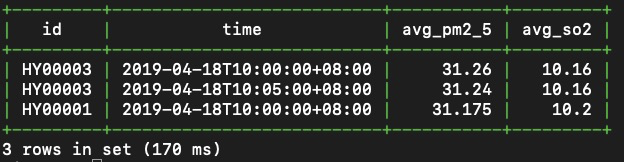
降採樣的實質是以時間序列為單位在時間維度的彙總。關於降採樣查詢的詳細說明請參見 降採樣。
查詢跨裝置的彙總資料
查詢餘杭區內裝置從2019-04-18 10:00:00至2019-04-18 10:30:00上報的PM2.5和SO2監控指標,查詢按照5分鐘粒度的最大平均值。
SELECT max(avg_pm2_5) AS max_avg_pm25, max(avg_so2) AS max_avg_so2 FROM (SELECT district, id, time, avg(pm2_5) AS avg_pm2_5, avg(so2) AS avg_so2 FROM aqm WHERE district='yuhang' AND time >= '2019-04-18 10:00:00' AND time < '2019-04-18 10:30:00' SAMPLE BY 5m) GROUP BY district;查詢結果如下。