添加Spark資料來源可以實現批量快速匯入資料功能,本文介紹添加Spark資料來源的方法。
前提條件
已購買引擎類型為LTS的Lindorm執行個體。
已建立Lindorm執行個體並開通計算引擎服務,建立方法請參見建立執行個體。
添加方式
通過Lindorm控制台添加Spark資料來源
登入Lindorm管理主控台。
在執行個體列表頁,單擊引擎類型為LTS的執行個體ID。
在左側導覽列選擇資料來源管理。
切換至計算引擎資料來源頁簽,單擊添加資料來源。
在添加資料來源對話方塊中配置以下資訊。
單擊確定,狀態為已關聯表示Spark資料來源已添加成功。
通過LTS服務添加Spark資料來源
登入LTS服務,具體操作請參見登入LTS服務。
在左側導覽列選擇。
在添加資料來源頁面配置以下參數。
參數
說明
名稱
固定填寫lts_bulkload_spark。
資料來源類型
固定選擇Spark。
資料來源參數
配置Spark資料來源的相關參數。
{ "virtualClusterName":"token", "hdfsUri":"hdfs://nn1:8020,nn2:8020", "sparkEndpoint":"http://192.168.XX.XX:10099" }virtualClusterName:Lindorm計算引擎的JAR地址Token值。通過Lindorm控制台的資料庫連接擷取,如下圖所示。
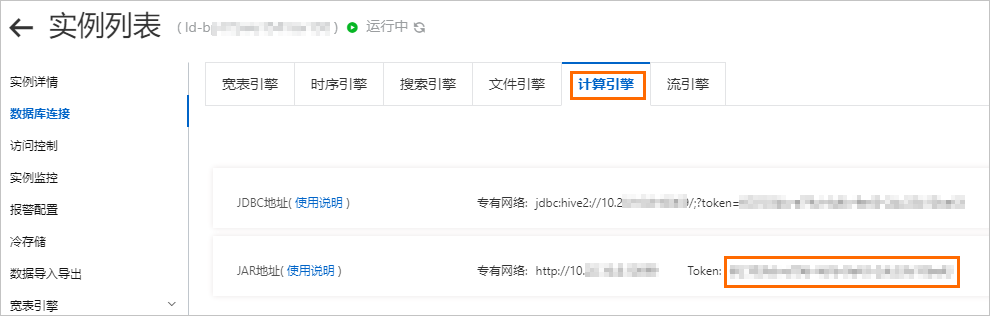
hdfsUri:Lindorm執行個體的HDFS串連地址,格式為:
hdfs://nn1:8020,nn2:8020。說明串連地址中擷取
nn1和nn2的方法請提交工單sparkEndpoint:Lindorm計算引擎的JAR專用網路地址。通過Lindorm控制台的資料庫連接擷取,如下圖所示。
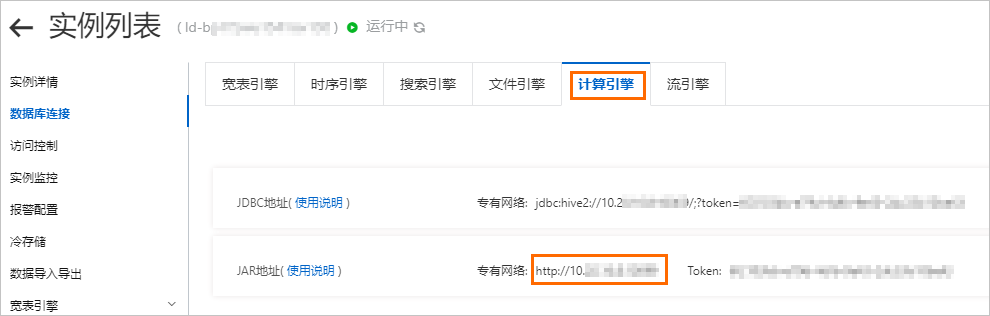
單擊添加。