本文介紹異常檢測演算法的概念和時序異常檢測的文法。
引擎與版本
時序異常檢測僅支援時序引擎。無版本要求。
使用限制
時序異常檢測必須和SAMPLE BY語句搭配使用。
功能簡介
時序異常檢測用於檢測指定時間軸上異常點的值,支援阿里達摩院自研的線上異常檢測演算法。異常檢測演算法在檢測過程中持續學習時序資料的特徵(例如資料趨勢或者周期),從而完成對新插入時序點的檢測。例如新插入的時序資料有一個非常大的尖刺,檢測結果可能為異常。
時序異常檢測搭配SAMPLE BY語句可以實現以下功能:
文法
select_sample_by_statement ::= SELECT ( select_clause )
FROM table_identifier
WHERE where_clause
SAMPLE BY 0
select_clause ::= selector [ AS identifier ] ( ',' selector [ AS identifier ] )
selector ::= tag_identifier, | time | anomaly_detect '(' field_identifier ',' algo_identifier | model_identifier [ ',' options] ')'
where_clause ::= relation ( AND relation )* (OR relation)*
relation ::= ( field_identifier| tag_identifier, ) operator term
operator ::= '=' | '<' | '>' | '<=' | '>=' | '!=' | IN | CONTAINS | CONTAINS KEYanomaly_detect代表時序異常檢測函數,相關參數說明如下:
參數 | 描述 |
field_identifier | Field列名。 說明 Field列的類型不能是VARCHAR和BOOLEAN類型。 |
algo_identifier | 異常檢測演算法名稱。支援阿里達摩院自研線上異常檢測演算法。
說明 algo_identifer參數適用於未開通資料庫內機器學習功能,但有使用時序異常檢測需求的情境。 |
model_identifier | 模型名稱。 說明
|
options | 調整異常檢測演算法的檢測效果。選擇性參數。格式為: |
演算法分類
時序引擎支援以下異常檢測演算法,演算法名稱和適用情境如下表:
演算法名稱 | 適用情境 |
esd |
|
nsigma |
說明 不建議在資料點中有少量顯著離群點的情境中使用,因為這種情況下計算的檢測值不準確可能導致檢測結果誤判。 |
ttest |
|
Incremental STL with ESD(簡稱istl-esd) | 適用於周期性訊號。istl-esd演算法屬於達摩院自研OneShot STL(也稱Incremental STL)演算法。Incremental STL是可以即時增量地將周期訊號分解成周期項、趨勢項和殘餘項的演算法,需要對4個周期的訊號進行初始化。此檢測演算法中包含Incremental STL演算法和esd演算法,先用Incremental STL對訊號進行即時增量分解,再對殘餘項使用esd演算法檢測異常。通過對殘餘項進行esd演算法檢測,可以檢測到非周期性尖刺。 |
Incremental STL with Nsigma(簡稱istl-nsigma) | 適用於周期性訊號。Incremental STL是可以即時增量地將周期訊號分解成周期項、趨勢項和殘餘項的演算法,需要對4個周期的訊號進行初始化。此檢測演算法中包含Incremental STL演算法和nsigma演算法,先用Incremental STL對訊號進行即時增量分解,再對殘餘項用nsigma檢測異常。通過對殘餘項進行nsigma檢測,可以檢測到非周期性尖刺。 |
演算法適用情境的曲線圖如下:
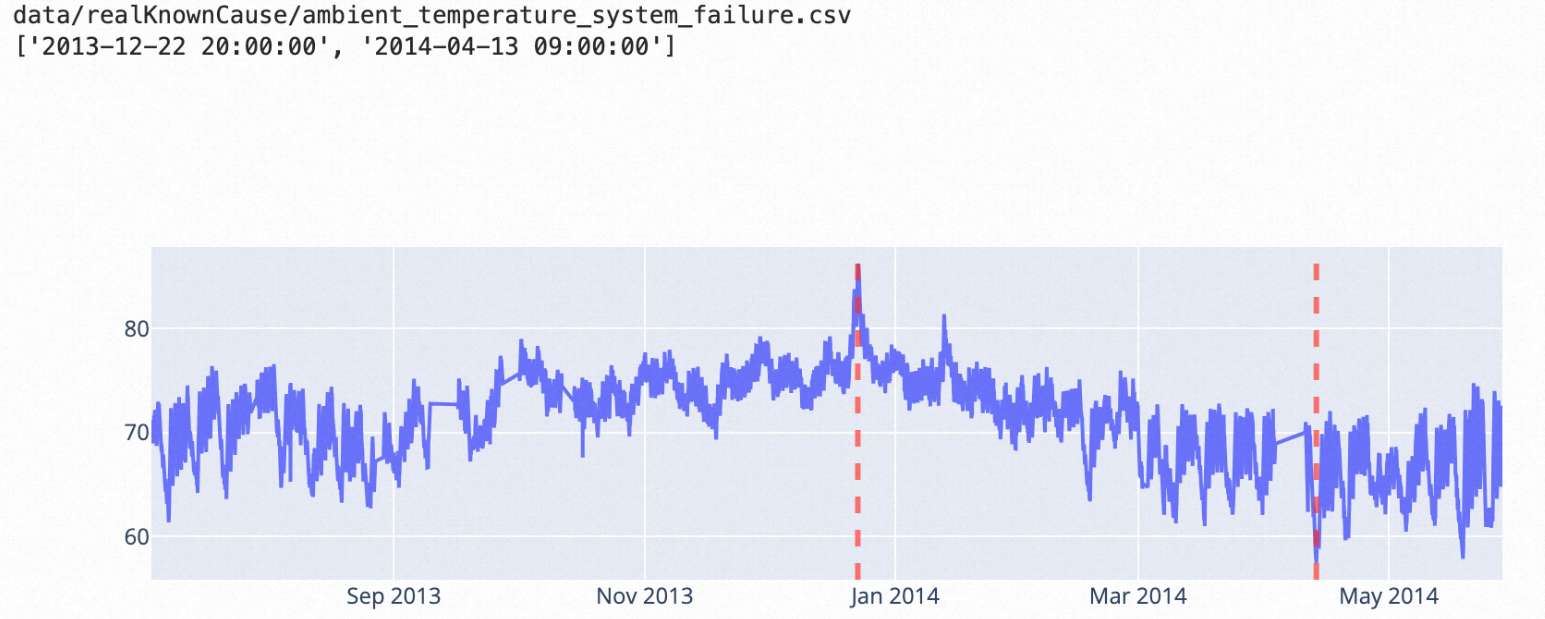
esd演算法:用於檢測每個時序點,適用於相對穩定的訊號中出現少量異常值的情境。
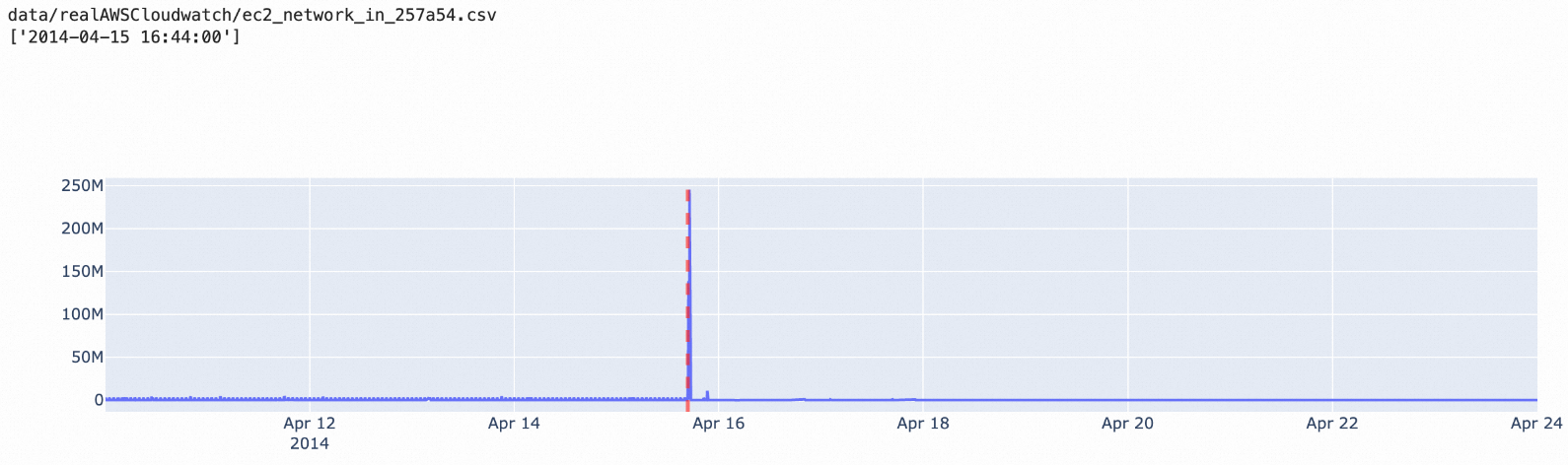
nsigma演算法:用於檢測每個時序點,適用於異常點相對於歷史平均值有較大差異(通過演算法的參數n來調節)的情境。
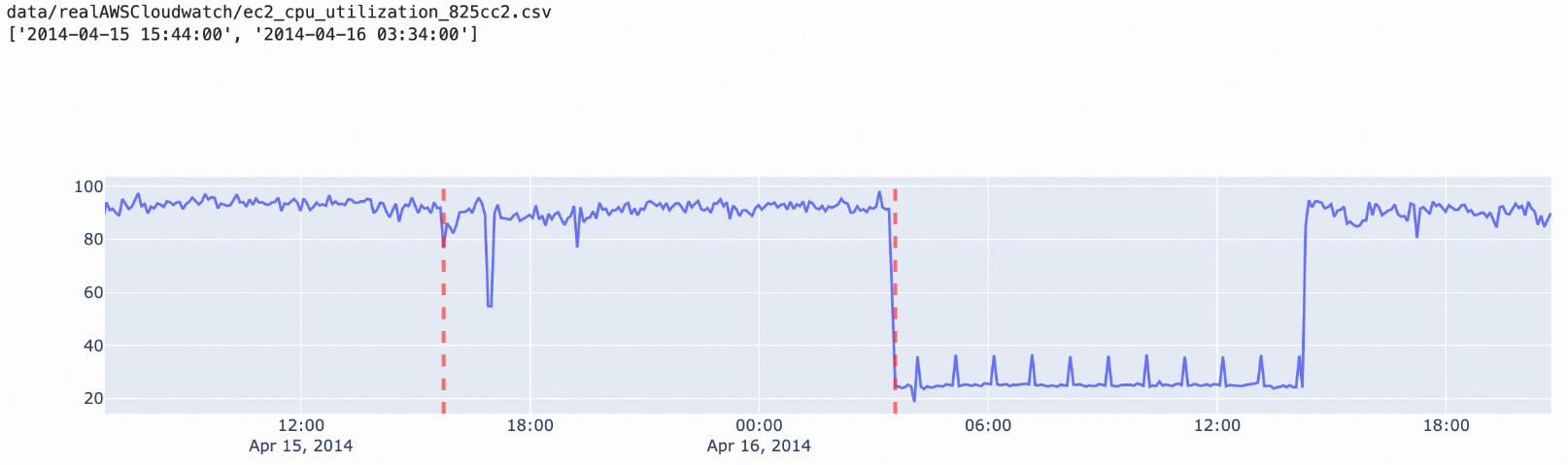
ttest演算法:用於檢測一段時間視窗內的時序資料。適用於以下兩個連續時間段內均值變化異常的情境。
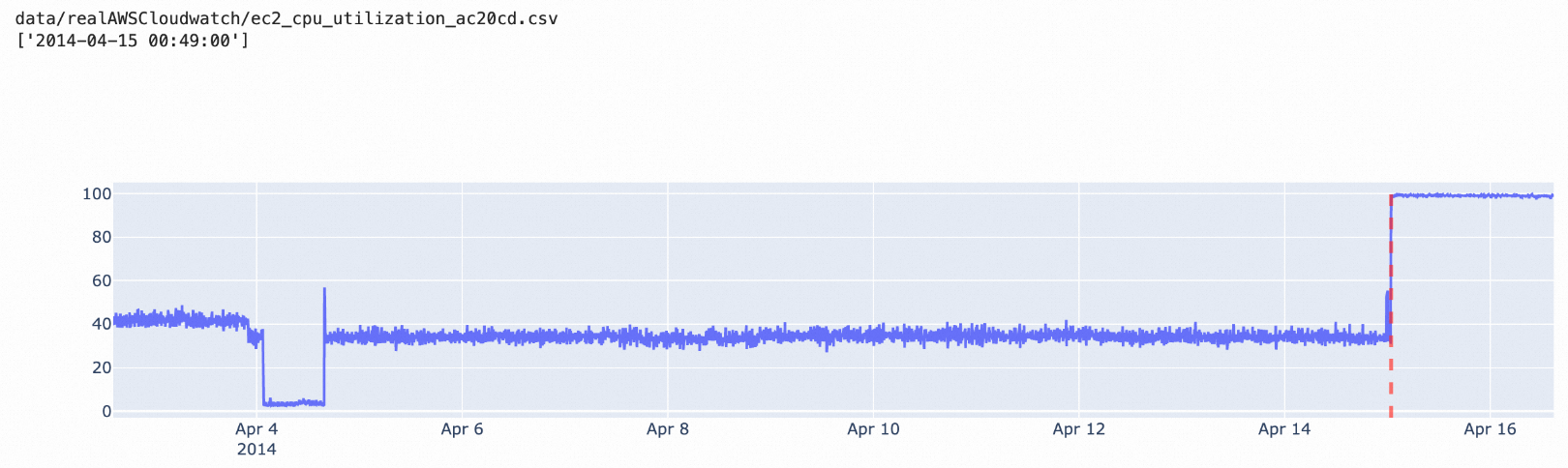
istl-esd演算法:Incremental STL演算法用於檢測帶周期性訊號的時序資料。Incremental STL演算法會在去除未經處理資料的周期趨勢量後,對殘餘項使用esd演算法進行檢測。適用於相對穩定的周期訊號中出現少量異常值的情境。
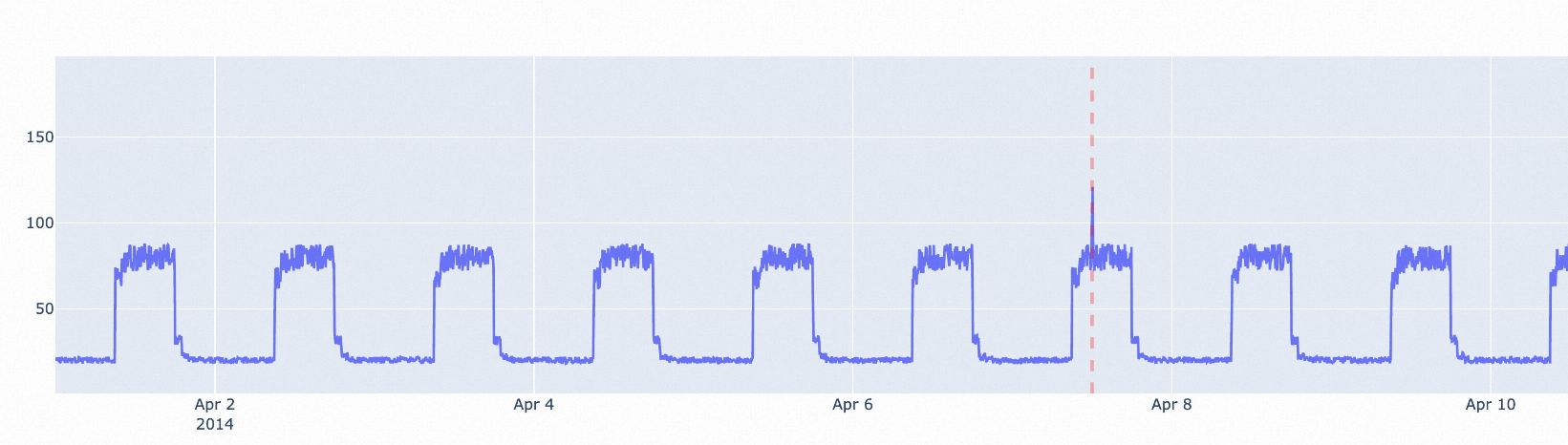
istl-nsigma演算法:Incremental STL演算法用於檢測帶周期性訊號的時序資料。Incremental STL演算法會在去除未經處理資料的周期趨勢量後,對殘餘項使用nsigma演算法進行檢測。適用於異常點相對於歷史平均值有較大差異的情境。
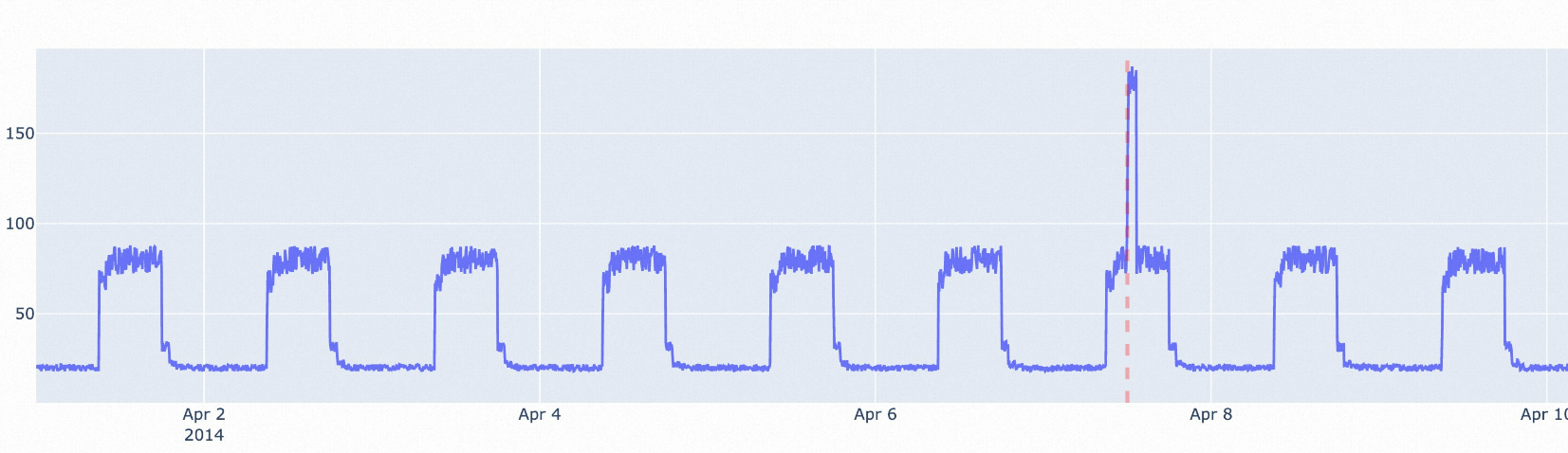
參數說明
異常檢測演算法支援配置演算法參數,包括公用參數、訓練參數和推理參數。您可以通過調整選擇性參數options來實現不同的異常檢測效果。
公用參數、訓練參數和推理參數實際傳參時都是在同一個列表內指定。以ttest為例,傳參時可以指定為:
lenDetectWindow=100,adhoc_stat=true。如何通過調整參數得到理想的檢測結果,請參見統計類演算法參數調優和分解類演算法參數調優。
公用參數
通用的公用參數控制檢測過程中的調試診斷和行為,可以使用到所有的異常檢測演算法中。公用參數說明如下表:
參數名稱 | 類型 | 預設值 | 說明 |
verbose | BOOLEAN | FALSE | 是否返回更多詳細資料,並標識目標列是否異常。具體返回的資訊由各演算法決定。取值如下:
取值為 |
adhoc_state | BOOLEAN | FALSE | 是否將演算法的異常檢測狀態限制在本次查詢檢測中,有關異常檢測狀態的描述請參見異常檢測狀態。 |
direction | VARCHAR | UP | 檢測異常的方向。取值如下:
|
訓練參數
使用異常檢測演算法時,指定演算法名稱和訓練參數會確定一個具體的異常檢測演算法模型。訓練參數在Lindorm時序引擎重啟後會失效,需要重新對資料點進行訓練(訓練的操作是檢測過程中即時適應時序資料的特性)。
配置訓練參數時需要注意以下幾點:
參數名稱不區分大小寫。
參數值的類型支援數值、布爾和字串,不支援NULL等特殊值。
參數值必須在指定的取值範圍內。
演算法名稱 | 參數名稱 | 類型 | 取值 | 說明 |
esd | compression | INTEGER | 正整數,預設值為100,取值範圍為 | 演算法中資料結構的空間複雜度。參數值越大演算法在運行過程中越佔用記憶體,但是演算法結果越準確。 |
lenHistoryWindow | INTEGER | 正整數,預設值為null,取值≥20。 | 演算法參考的時間視窗長度。如果時間視窗長度比較短,計算過程中只會將最近的資料點作為參考值。當lenHistoryWindow=null時,表示沒有指定參考的時間視窗長度,此時會用第一次檢測以來的所有時間點作為參考的時間視窗長度。 | |
nsigma | lenHistoryWindow | INTEGER | 正整數,預設值為null,取值≥20。 | 演算法參考的時間視窗長度。如果時間視窗長度比較短只會參考最近的資料點作為參考值。當lenHistoryWindow=null時,表示沒有指定參考的時間視窗長度,此時會用第一次檢測以來的所有時間點作為參考的時間視窗長度。 |
ttest | lenDetectWindow | INTEGER | 正整數,預設值為10。 | 待檢測的最近的時間視窗的長度。 |
lenHistoryWindow | INTEGER | 正整數,預設值為100,取值≥20。 | 演算法參考的時間視窗長度。如果時間視窗長度比較短,計算過程中只會將最近的資料點作為參考值。當 說明 此參數值必須大於lenDetectWindow參數值。 | |
istl-esd | frequency | VARCHAR | 用數字和時間單位表示的字串。例如5M、24H、1D。 表示時間單位的有效取值及含義:
| 時間序列的採集頻率。例如每小時一個點則 重要
|
periods | VARCHAR | 用數字和時間單位表示的字串。例如5M、24H、1D。 表示時間單位的有效取值及含義如下:
| 周期訊號的所有周期長度。可以通過索引符傳遞多個周期長度。例如: 說明 如果未設定該參數,演算法會自動檢測周期。 | |
esd.* | 不涉及 | 定義esd演算法所需的訓練參數,請參考esd演算法的訓練參數。使用時通過添加esd.首碼進行關聯到esd演算法參數。例如: | ||
istl-nsigma | frequency | VARCHAR | 用數字和時間單位表示的字串。例如5M、24H、1D。 表示時間單位的有效取值及含義如下:
| 時間序列的採集頻率。例如 重要
|
periods | VARCHAR | 用數字和時間單位表示的字串。例如5M、24H、1D。 表示時間單位的有效取值及含義如下:
| 周期訊號的所有周期長度。可以通過索引符傳遞多個周期長度。例如: 說明 如果未設定該參數,演算法會自動檢測周期。 | |
nsigma.* | 不涉及 | 定義nsigma演算法所需的訓練參數,請參考nsigma演算法的訓練參數。使用時通過添加nsigma.首碼進行關聯到nsigma演算法參數。例如: | ||
推理參數
推理參數只在檢測時起作用,且參數名稱大小寫不敏感。
演算法名稱 | 參數名稱 | 類型 | 取值 | 說明 |
esd | alpha | DOUBLE | 預設值為0.1,取值範圍為 | 異常檢測的敏感程度。參數值越大,對異常檢測越敏感,會報出比較多的異常。 |
direction | VARCHAR | 預設值為Up。 | 檢測異常的方向。
| |
maxAnomalyRatio | DOUBLE | 預設值為0.3,取值範圍為 | 最大的異常比例。例如:當maxAnomalyRatio=0.3並且direction=Up時,表示值小於第70百分位元的點不會被認為是異常。
| |
warmupCount | INTEGER | 正整數,預設值為20。 | 至少需要多少個點才會開始報異常。例如:warmupCount=20表示資料點小於20個不會報異常。 | |
nsigma | n | DOUBLE | 非零浮點數,預設值為3.0。 |
|
warmupCount | INTEGER | 正整數,預設值為20。 | 至少需要多少個點才會報異常。例如:warmupCount=20表示資料點小於20個不會報異常。 | |
ttest | alpha | DOUBLE | 預設值為0.05,取值範圍為 | 異常檢測的敏感程度。參數值越大,對異常檢測越敏感,會報出比較多的異常。 |
direction | VARCHAR | 預設為Up。 | 檢測異常的方向。
| |
istl-esd | esd.* | 不涉及 | 定義esd演算法所需的推理參數,請參考esd演算法的推理參數。使用時通過 | |
istl-nsigma | nsigma.* | 不涉及 | 定義nsigma演算法所需的推理參數,請參考nsigma演算法的推理參數。使用時通過 | |
樣本
樣本1:對時序資料表sensor中指定時間範圍的溫度使用esd演算法進行時序異常檢測。
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;返回結果如下:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | | F07A1261 | south-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:02+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:03+08:00 | false | +-----------+----------+---------------------------+---------------+樣本2:對時序資料表sensor中F07A1260裝置指定時間範圍的溫度使用esd演算法進行時序異常檢測。
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;返回結果如下:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+樣本3:對時序資料表sensor中F07A1260裝置指定時間範圍的溫度使用esd演算法進行時序異常檢測,同時指定演算法參數。
SELECT device_id, region, time, anomaly_detect(temperature, 'esd', 'lenHistoryWindow=30,maxAnomalyRatio=0.1') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;返回結果如下:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+樣本4:與降採樣運算元MAX嵌套使用,降採樣粒度為1分鐘。
SELECT time, anomaly_detect(max(temperature), 'esd') AS ad_result, max(temperature) AS rawVal FROM sensor SAMPLE BY 1m;返回結果如下:
+---------------------------+-----------+-------------+ | time | ad_result | rawVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | null | 923091.3175 | | 2022-04-11T08:00:00+08:00 | null | 8035700 | | 2022-04-11T09:00:00+08:00 | null | 8035690.25 | | 2022-04-11T10:00:00+08:00 | null | 3306277.545 | | 2022-04-11T11:00:00+08:00 | null | 5921167.787 | | 2022-04-11T12:00:00+08:00 | null | 833541.304 | +---------------------------+-----------+-------------+樣本5:與非降採樣運算元LATEST嵌套使用,降採樣粒度為0。
SELECT time, anomaly_detect(latest(temperature), 'esd') AS ad_result, latest(temperature) AS latestVal FROM sensor SAMPLE BY 0;返回結果如下:
+---------------------------+-----------+-------------+ | time | ad_result | latestVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | false | 923091.3175 | | 2022-04-13T07:00:00+08:00 | false | 8037506.75 | | 2022-04-13T07:00:00+08:00 | false | 50490.2 | +---------------------------+-----------+-------------+