本文介紹什麼是准即時推理情境,以及如何使用GPU按量執行個體,以及如何基於GPU按量執行個體構建使用成本較低的准即時推理服務。
情境介紹
在准即時推理應用情境中,工作負載具有以下一個或多個特徵。
調用稀疏
日均調用幾次到幾萬次,日均GPU實際使用時間長度遠低於8~12小時,GPU存在大量閑置。
單次處理耗時間長度
准即時推理業務的處理耗時一般在秒級~分鐘級。例如,典型的CV任務處於秒層級,典型的視頻處理和AIGC情境均處於分鐘層級。
容忍冷啟動
業務可以容忍GPU冷啟動耗時,或者業務流量波形對應的冷啟動機率低。
Function Compute為準即時推理工作負載提供以下功能優勢。
原生Serverless使用方式
Function Compute平台預設提供的按量GPU執行個體使用方式,會自動管理GPU計算資源。當業務流量變化時自動進行資源伸縮,具備業務波穀時的縮0能力、具備業務波峰時的秒級GPU彈效能力。您只需要關注業務迭代本身,當業務部署到Function Compute平台後,基礎設施將完全由Function Compute平台託管。
規格最優
Function Compute平台提供的GPU執行個體規格,允許您根據工作負載選擇不同的卡型,獨立配置CPU/GPU/MEM/DISK,最小GPU規格為1 GB顯存/算力,為您提供最貼合業務的執行個體規格。
成本最優
Function Compute平台提供的隨用隨付能力,以及秒層級的計費能力,協助業務在GPU規格最優後,達到成本最優。對於低GPU資源使用率的工作負載,降本幅度可達70%以上。
突發流量支撐
Function Compute平台提供充足的GPU資源供給,當業務遭遇突發流量時,Function Compute將以秒級彈性供給海量GPU算力資源,避免因GPU算力供給不足、GPU算力彈性滯後導致的業務受損。
功能原理
當GPU函數部署完成後,Function Compute預設通過按量GPU執行個體為您服務(與之區別的是預留GPU執行個體,具體資訊,請參見執行個體類型及使用模式),提供准即時推理應用情境所需的基礎設施執行環境。
您可以發送推理請求至GPU函數的觸發器(例如,HTTP觸發器收到HTTP請求後觸發函數執行),GPU函數將運行在GPU容器中,完成模型推理,並將推理結果放在響應中返回。Function Compute將自動編排、Auto ScalingGPU計算資源,以服務您的業務流量,您只需為處理請求時使用的GPU資源付費。
容器支援
Function ComputeGPU情境下,當前僅支援以Custom Container(自訂容器運行環境)進行交付。關於Custom Container的使用詳情,請參見Custom Container簡介。
Custom Container函數要求在鏡像內攜帶Web Server,以滿足執行不同代碼路徑、通過事件或HTTP觸發函數的需求。適用於AI學習推理等多重路徑請求執行情境。
GPU執行個體規格
您可以在推理應用情境下,根據業務需要,特別是演算法模型所需要的CPU算力、GPU算力與顯存、記憶體、磁碟,選擇不同的GPU卡型與GPU執行個體規格。關於GPU執行個體規格的詳細資料,請參見執行個體規格。
部署方式
您可以使用多種方式將您的模型部署在Function Compute。
通過Function Compute控制台部署。具體操作,請參見在控制台建立函數。
通過調用SDK部署。更多資訊,請參見API概覽。
通過Serverless devs工具部署。更多資訊,請參見Serverless Devs常用命令。
更多部署樣本,請參見start-fc-gpu。
並發調用
您的GPU函數在某個地區層級,例如華東1(杭州),支援的最大同時呼叫數目數量,取決於GPU函數執行個體的並發度、以及GPU物理卡的使用上限。
GPU函數執行個體並發度
預設情況下,GPU函數執行個體的並發度為1,即一個GPU函數執行個體在同一時刻僅能處理一個請求。您可以通過控制台、ServerlessDevs工具調整GPU函數執行個體的並發度配置。具體操作,請參見設定執行個體並發度。建議根據不同應用情境的需要,選擇不同的並發度配置。
計算密集型的推理應用:建議GPU函數執行個體的並發度保持預設值1。
支援要求批量彙總的推理應用:建議GPU函數執行個體的並發度根據能同時彙總的推理請求數量進行設定,以便批量推理。
GPU物理卡的使用上限
預設情況下,單個阿里雲帳號地區層級的GPU物理卡上限為30卡,實際數值以配額中心為準,如您有更高的物理卡需求,請前往配額中心申請。
冷啟動
當您的GPU函數長時間無業務流量後,所有按量GPU執行個體將被平台釋放。之後的第1個請求會觸發冷啟動,Function Compute平台需要更多的耗時來拉起函數執行個體服務該請求,這個過程通常包括準備GPU計算資源、拉取容器鏡像、啟動GPU容器、載入與初始化演算法模型、啟動推理應用等。更多資訊,請參見Function Compute冷啟動最佳化最佳實務。
AI應用的冷啟動依賴您的鏡像大小、模型尺寸和初始化耗時。您可以通過監控指標觀察冷啟動耗時,以及評估冷啟動機率。
冷啟動效能
在Function ComputeGPU平台上,常見模型的端到端冷啟動效能如下。
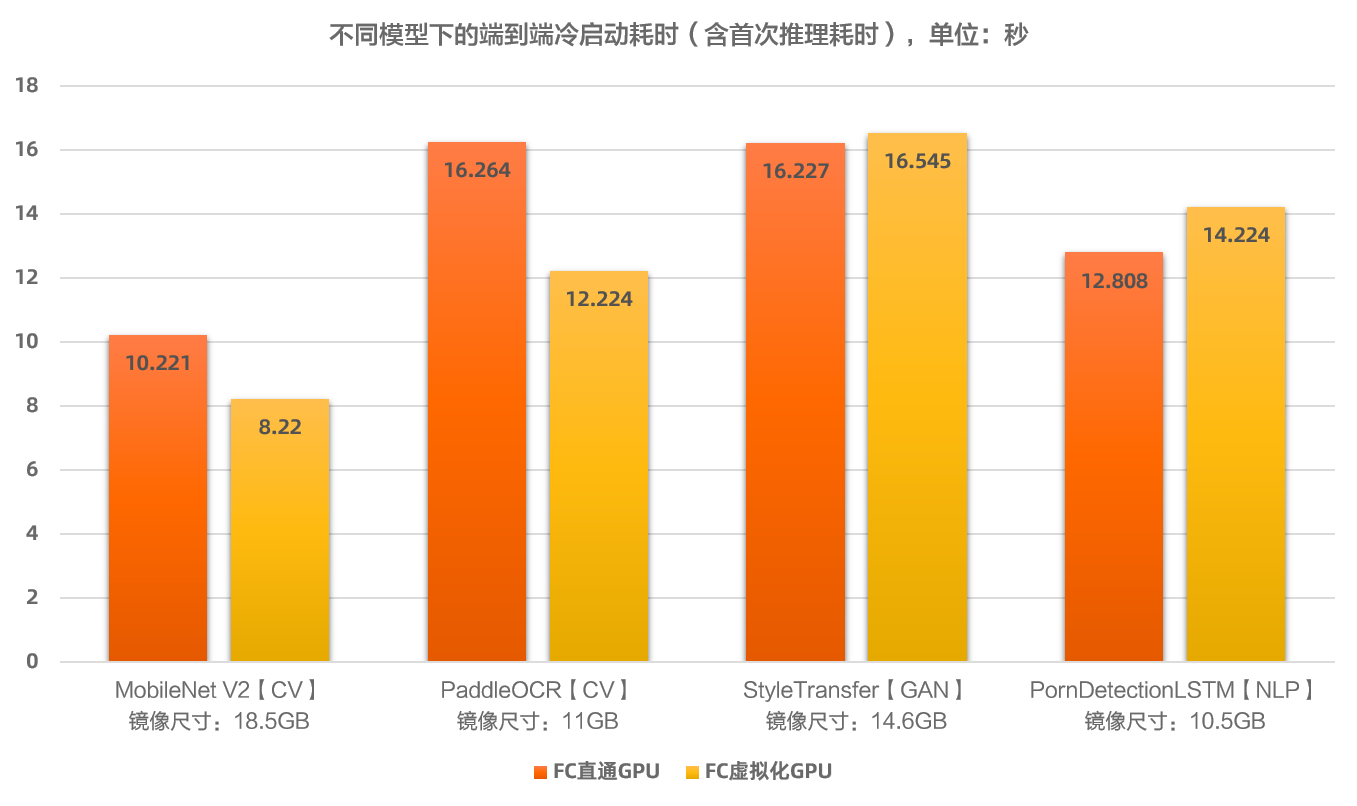
端到端冷啟動耗時(包含冷啟動+首次調用處理耗時):10~30s
冷啟動機率
Function Compute的Serverless GPU中,冷啟動耗時為秒級,而k8s平台通常為分鐘級。Function Compute的冷啟動機率隨著並發度的上升,成比例下降,冷啟動對業務的影響也隨之變小。
成本評估
以下計費單價和樣本僅供參考,實際費用以商務提供的價格為準。
您在使用Function Compute前日均GPU利用率越低,切換至Function Compute後GPU降本幅度越大。
計費樣本如下。本文以購買T4加速類型的GPU雲端服務器為例進行對比說明。與Function Compute同等GPU規格的GPU雲端服務器單價約為USD 2/小時。更多計費詳情,請參見GPU雲端服務器計費。
樣本一
假設您的GPU函數一天調用量為3600次,每次為1秒鐘,使用4 GB顯存規格的GPU執行個體(模型大小為3 GB左右)。
您的日均資源使用率(僅時間維度,不包含顯存維度)=3600秒/86400秒=0.041,即4.1%
您的Elastic Compute Service的日均GPU資源費用=USD 2/小時×24小時=USD 48
您的Function Compute的日均GPU資源費用=3600秒×4 GB×USD 0.000018/GB*秒=USD 0.259
使用Function Compute的GPU後,降本幅度達99%以上。
樣本二
假設您的GPU函數一天調用量為50000次,每次為1秒鐘,使用4 GB顯存規格的GPU執行個體(模型大小為3 GB左右)。
您的日均資源使用率(僅時間維度,不包含顯存維度)=50000秒/86400秒=0.57,即57%
您的Elastic Compute Service的日均GPU資源費用=USD 2/小時×24小時=USD 48
您的Function Compute的日均GPU資源費用=50000秒×4 GB×USD 0.000018元/GB*秒=USD 3.6
使用Function Compute的GPU後,降本幅度達90%以上。