Google在2024年02月21日正式推出了首個開源模型族Gemma,並同時上架了2b和7b兩個版本。您可以使用Function Compute的GPU執行個體以及Function Compute的閑置模式低成本快速部署Gemma模型服務。
前提條件
操作步驟
部署Gemma模型服務的過程中將產生部分費用,包括GPU資源使用、vCPU資源使用、記憶體資源使用、磁碟資源使用和公網出流量以及函數調用的費用。具體資訊,請參見計費概述。
建立應用
請根據下列步驟,擷取ACR倉庫的網域名稱和倉庫地址。
登入Container Registry控制台,選擇函數所在的地區,點擊目標企業版執行個體卡片中的管理。
在左側導覽列點擊存取控制,然後選擇公网頁簽。如果訪問入口的開關處於關閉狀態,請開啟開關。如果您希望任何公網機器均可登入您的倉庫,請刪除所有公網白名單。否則,請根據您的情況設定公網白名單。完成後,請儲存該ACR執行個體的網域名稱地址。
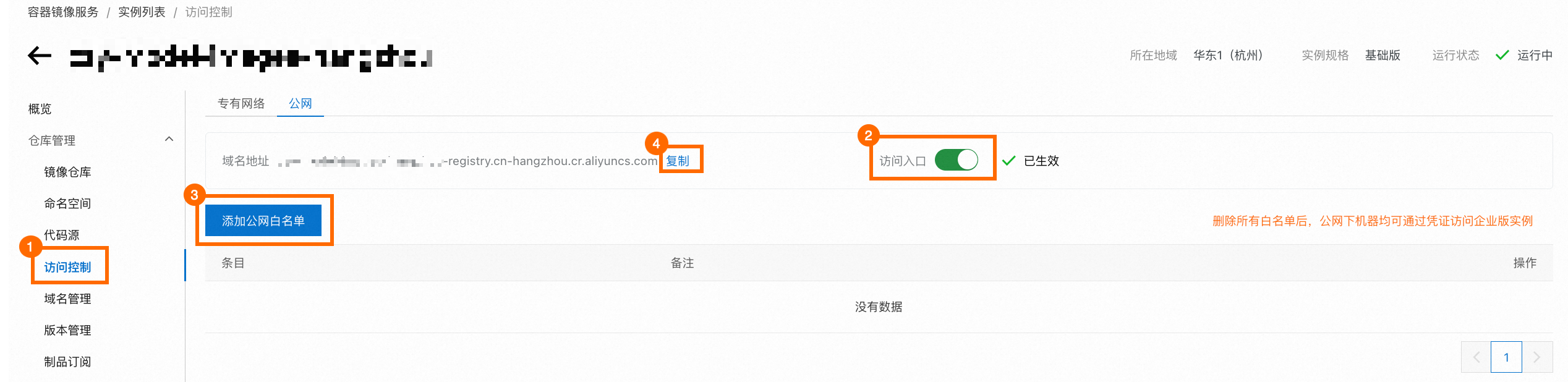
在左側導覽列點擊ACR 镜像仓库,然後點擊目標倉庫的倉庫名稱,進入倉庫詳情頁面。
請儲存該倉庫的公網地址。

下載Gemma模型權重。您可以選擇從Hugging Face或ModelScope平台下載,本文以從ModelScope下載Gemma-2b-it模型為例,詳情請參見Gemma-2b-it。
重要如果您使用Git下載模型,請先安裝Git擴充LFS後,執行
git lfs install初始化Git LFS,然後再執行git clone進行下載。否則,由於模型過大,可能導致下載的模型不完整,無法正常使用Gemma服務。建立Dockerfile文檔和模型服務代碼檔案
app.py。Dockerfile
FROM registry.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17 WORKDIR /usr/src/app COPY . . RUN pip install -U transformers RUN pip install -U accelerate CMD [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000app.py
from flask import Flask, request from transformers import AutoTokenizer, AutoModelForCausalLM model_dir = '/usr/src/app/gemma-2b-it' app = Flask(__name__) tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto") @app.route('/invoke', methods=['POST']) def invoke(): request_id = request.headers.get("x-fc-request-id", "") print("FC Invoke Start RequestId: " + request_id) text = request.get_data().decode("utf-8") print(text) input_ids = tokenizer(text, return_tensors="pt").to("cuda") outputs = model.generate(**input_ids, max_new_tokens=1000) response = tokenizer.decode(outputs[0]) print("FC Invoke End RequestId: " + request_id) return str(response) + "\n" if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=9000)關於Function Compute支援的所有HTTP Header,請參見Function Compute公用要求標頭。
完成後代碼目錄結構如下所示。
. |-- app.py |-- Dockerfile `-- gemma-2b-it |-- config.json |-- generation_config.json |-- model-00001-of-00002.safetensors |-- model-00002-of-00002.safetensors |-- model.safetensors.index.json |-- README.md |-- special_tokens_map.json |-- tokenizer_config.json |-- tokenizer.json `-- tokenizer.model 1 directory, 12 files依次執行以下命令構建並推送鏡像。其中
{REPO_ENDPOINT}是步驟1中目標鏡像倉庫的公網地址,{REGISTRY}是ACR執行個體的網域名稱地址。IMAGE_NAME={REPO_ENDPOINT}:gemma-2b-it docker login --username=mu****@test.aliyunid.com {REGISTRY} docker build -f Dockerfile -t $IMAGE_NAME . docker push $IMAGE_NAME重要當使用Apple晶片的Mac系統構建鏡像時,請將第3行的
docker build命令替換為使用以下命令,以構建相容Function Compute的鏡像。docker build --platform linux/amd64 -f Dockerfile -t $IMAGE_NAME .建立函數。
登入Function Compute控制台,在左側導覽列,選擇函数。
在頂部功能表列,選擇地區,然後在函数頁面單擊创建函数。
在建立函數頁面,選擇使用容器镜像方式,設定以下配置項,然後單擊创建。
重點配置項說明如下,其餘配置項選擇預設值即可。
配置項
說明
镜像配置
镜像选择方式
選擇使用 ACR 中的镜像。
容器镜像
單擊下方的选择 ACR 中的镜像,然後在选择容器镜像面板,選擇步驟3推送的鏡像。
监听端口
設定為9000。
高级配置
是否使用GPU
選擇使用GPU。
GPU 卡型
選擇Tesla 系列 T4 卡型。
规格方案
GPU显存规格設定為16 GB。
vCPU 规格設定為2核。
内存规格設定為16 GB。
待上一步建立的函數的狀態變更為函數已啟用時,您可以為其開啟閑置預留模式。

在函數詳情頁面選擇配置頁簽,在左側導覽列,選擇预留实例,然後單擊创建预留实例数策略。
在创建预留实例数策略面板中,版本或别名選擇LATEST,预留实例数設定為1,闲置模式選擇启用,然後單擊确定。
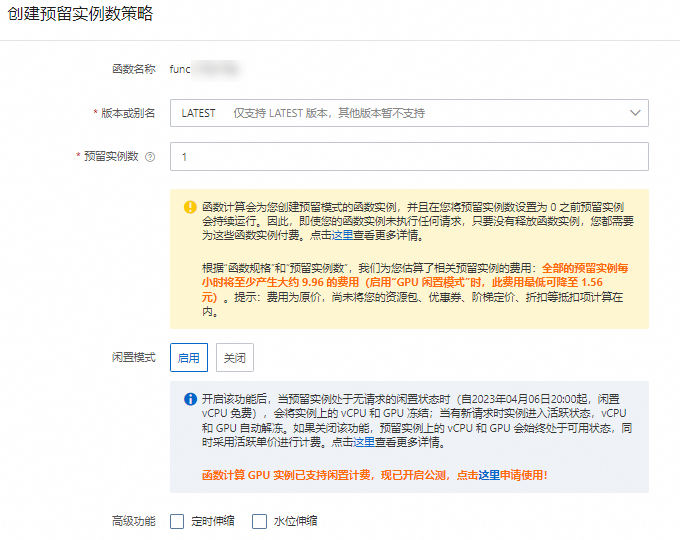
待当前预留实例数變更為1,且您可以看到已开启闲置模式的字樣,表示GPU閑置預留執行個體已成功啟動。

使用Google Gemma服務
在函數詳情頁面,選擇配置頁簽,然後在左側導覽列,選擇触发器,在觸發器頁面擷取觸發器的URL。
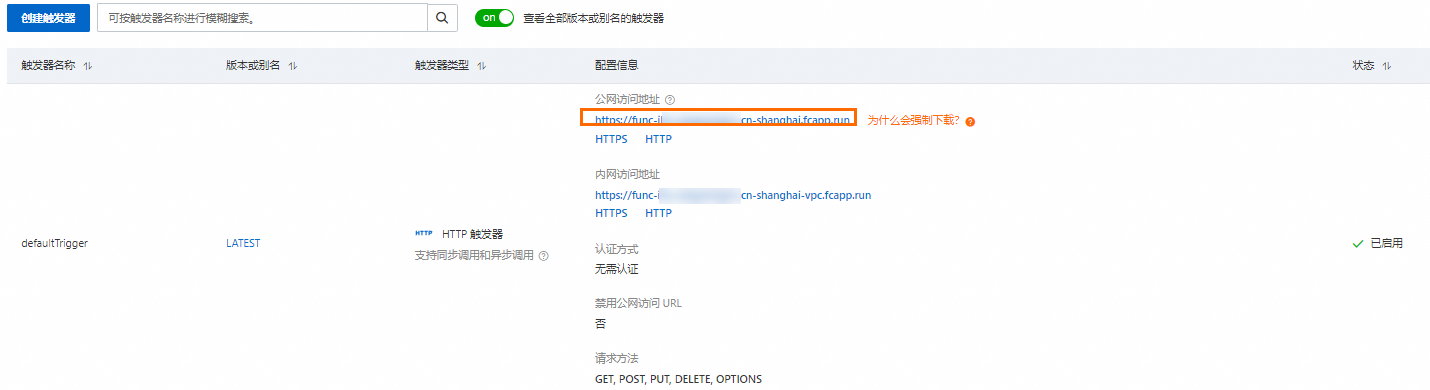
執行以下命令調用函數。
curl -X POST -d "who are you" https://func-i****-****.cn-shanghai.fcapp.run/invoke預期輸出如下。
<bos>who are you? I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way. What can I do for you today?<eos>在函數詳情頁面,選擇实例頁簽,在執行個體頁面單擊目標執行個體ID右側操作列的实例指标,在執行個體詳情頁面的实例指标頁簽查看指標情況。
您可以看到在沒有函數調用發生時,該執行個體的顯存使用量會降至零。而當有新的函數調用請求到來時,Function Compute平台會迅速恢複並分配所需的顯存資源。從而達到降本效果。
說明查看指標的執行個體,需要先啟用日誌功能,具體請參見配置日誌功能。
函數調用結束後,Function Compute會自動將GPU執行個體置為閑置模式,您無需手動操作。在下次調用到來之前,Function Compute將該執行個體喚醒,置為活躍模式進行服務。
刪除資源
如您暫時不需要使用此函數,請及時刪除對應資源。如果您需要長期使用此應用,請忽略此步驟。
返回Function Compute控制台概覽頁面,在左側導覽列,單擊函数。
單擊目標函數右側操作列的,在彈出的對話方塊中,勾選我確認要刪除以上資源,並同時刪除此函數。我已知曉這些資源刪除後將無法找回,然後單擊刪除函數。
費用說明
相關文檔
關於Google發布的開源模型族Gemma的更多詳情,請參見gemma-open-models。
關於GPU執行個體閑置模式計費詳情以及計費樣本,請參見計費概述。