本文通過自行構建ComfyUI + SD/FLUX鏡像,基於Function Compute的GPU函數能力,快速搭建一個文生圖服務。
方案概覽
使用阿里雲Function Compute快速搭建一個文生圖服務,僅需以下兩步:
選擇公用鏡像或者構建並推送鏡像。
選擇一個公用的ComfyUI + SD/FLUX鏡像,或者自行構建鏡像後,將其推送到您在阿里雲Container Registry中的鏡像倉庫。
建立GPU函數。
在阿里雲Function Compute上,基於上述鏡像建立一個GPU 函數。函數建立成功後,系統將提供一個網域名稱,作為對外提供服務的入口。此網域名稱即為您的文生圖服務的訪問地址。
完成上述步驟後,您的文生圖服務便已成功部署,使用者可以通過公網或者內網訪問該服務,如需通過瀏覽器訪問函數,可為函數配置自訂網域名。
步驟一:基於阿里雲Function Compute構建文生圖服務
鏡像構建與加速
公用鏡像:使用已有的ComfyUI+SD/FLUX公用鏡像,便捷快速。
自建鏡像:根據自身需求定製鏡像,最佳化使用者體驗與效能。
準備Dockerfile檔案
構建鏡像時,使用者可以按照ComfyUI專案 README.md文檔裡的安裝指引進行操作。由於ComfyUI依賴Python,使用者可以選擇一個合適的Python鏡像作為基礎鏡像。Python鏡像可以從Docker Hub等公用鏡像倉庫擷取,以下提供一個自訂樣本鏡像。
# Dockerfile FROM python:3.10 # 安裝系統依賴 RUN apt-get update && apt-get install -y \ git \ wget \ && rm -rf /var/lib/apt/lists/* WORKDIR /app # 複製ComfyUI倉庫 RUN git clone https://github.com/comfyanonymous/ComfyUI.git WORKDIR /app/ComfyUI #設定python 依賴包加速 RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com # 安裝PyTorch(預設NVIDIA CUDA版本,可根據需要修改) RUN pip install torch==2.5.0+cu124 torchvision==0.20.0+cu124 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124 # 安裝專案依賴 RUN pip install -r requirements.txt # 暴露服務連接埠 EXPOSE 8188 # 啟動命令 CMD ["python", "main.py"]加速鏡像下載
若公用鏡像倉庫訪問速度較慢,可通過配置Docker的registry-mirrors來提升下載速度。例如,在Linux系統中,編輯/etc/docker/daemon.json檔案,添加或修改如下配置。
{ ...... "registry-mirrors": [ "https://docker.nju.edu.cn", "https://dockerproxy.com", "https://docker.mirrors.ustc.edu.cn", ...... ] }重新負載檔案並重啟docker,使上一步修改生效。
systemctl daemon-reload # 重新載入設定檔。 systemctl restart docker # 重啟Docker服務。
另外,您也可以將常用基礎鏡像儲存在自己的鏡像倉庫,或者搭建私人的registry-mirror。
加速Python依賴包下載
按照ComfyUI專案的README.md的指引進行安裝時,若Python依賴包下載緩慢,可以配置pip的
index-url來提速,例如使用阿里雲或者清華的Python鏡像源。...... RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com ......構建鏡像
docker build -t comfyui:latest .
將鏡像推送到Container Registry
在Function Compute中,建立自訂鏡像函數必須使用同一帳號下相同地區內阿里雲鏡像服務倉庫中的鏡像。您可以選擇以下方式將鏡像推送到Container Registry。
建立GPU函數
Function Compute預設為所有GPU函數提供鏡像加速功能,支援按需拉取和P2P緩衝,無需額外配置。利用此功能,可快速建立大鏡像容器,提升彈效能力,更多請參見建立GPU函數。但需注意:Function Compute對鏡像大小有限制,應盡量避免將大型模型資料包含在鏡像中,以防加速鏡像建立時間過長,鏡像大小限制和配額申請請參見配額與使用限制。
建立函數的啟動命令和監聽連接埠,樣本如下。
監聽連接埠:8188。說明:監聽連接埠需要和構建的鏡像的連接埠保持一致。
啟動命令:python main.py --listen 0.0.0.0

為函數配置自訂網域名
阿里雲Function Compute為函數提供的網域名稱主要用於API訪問,如需通過ComfyUI可視化介面操作,可以為函數配置自訂網域名。
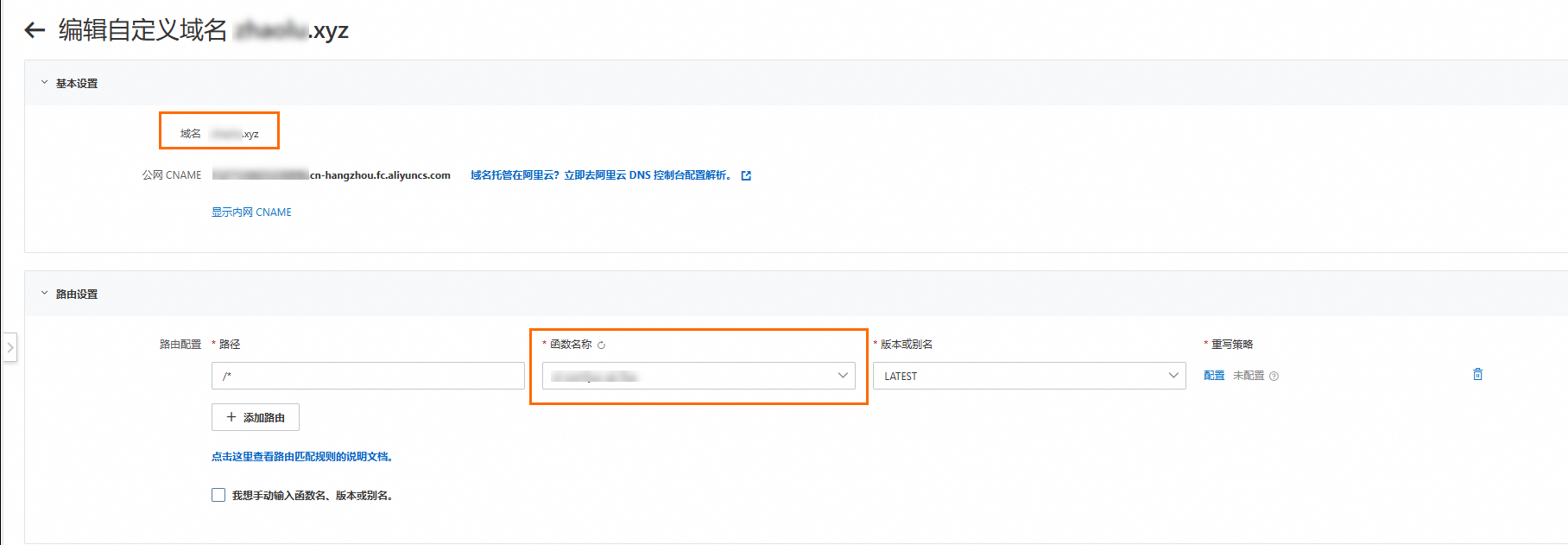
在瀏覽器上訪問配置的自訂網域名開啟comfyUI介面,效果如下圖所示。
步驟二:模型下載與加速
模型可以從Hugging Face、魔搭、civitai等社區下載。魔搭社區中有大量的模型,還提供了很多組織用戶共享鏡像,例如Black Forest Labs,如果訪問Hugging Face網路受限,可選擇魔搭的鏡像源。
Function Compute推薦使用者將模型資料存放區到NAS或者OSS。其中通用型 NAS 中的“效能型”執行個體可以達到約 600MB/s的初始頻寬,而OSS 的頻寬上限較高,相比 NAS 不易出現函數執行個體間頻寬爭搶現象,還可以通過開通 OSS 加速器獲得更高的吞吐能力。更詳細的資訊,請參見AI 情境下,Function Compute GPU 執行個體模型儲存最佳實務。
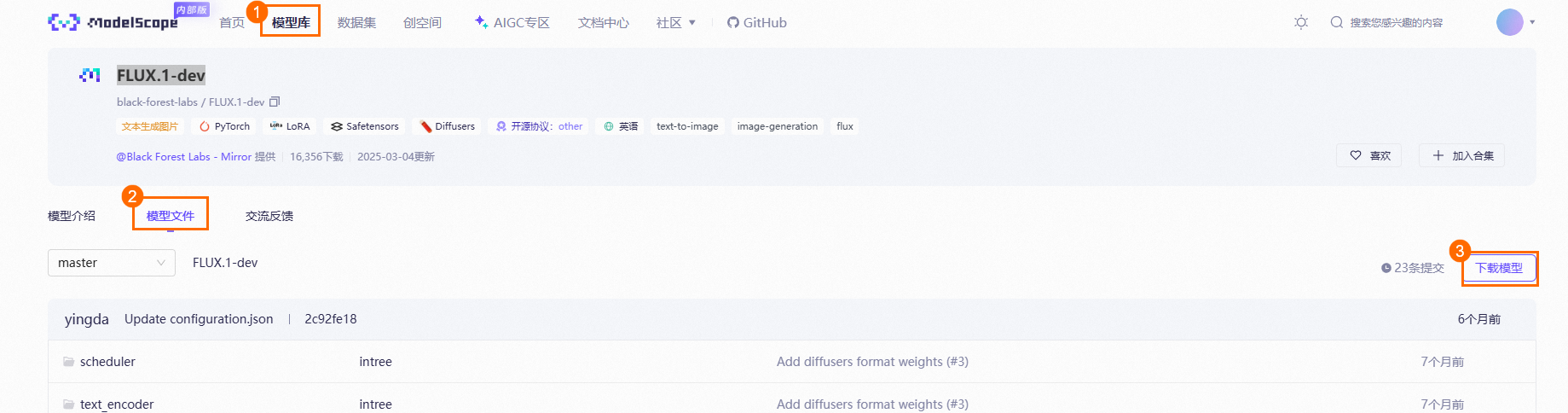
在魔搭的模型庫中搜尋Black Forest Labs,以下以FLUX.1-dev模型為例展示模型下載。
將下載的模型上傳到OSS,需要將下載的模型放在ComfyUI/models/指定檔案夾,例如
flux1-dev.safetensors模型存放unet檔案夾,樣本模型路徑如下所示。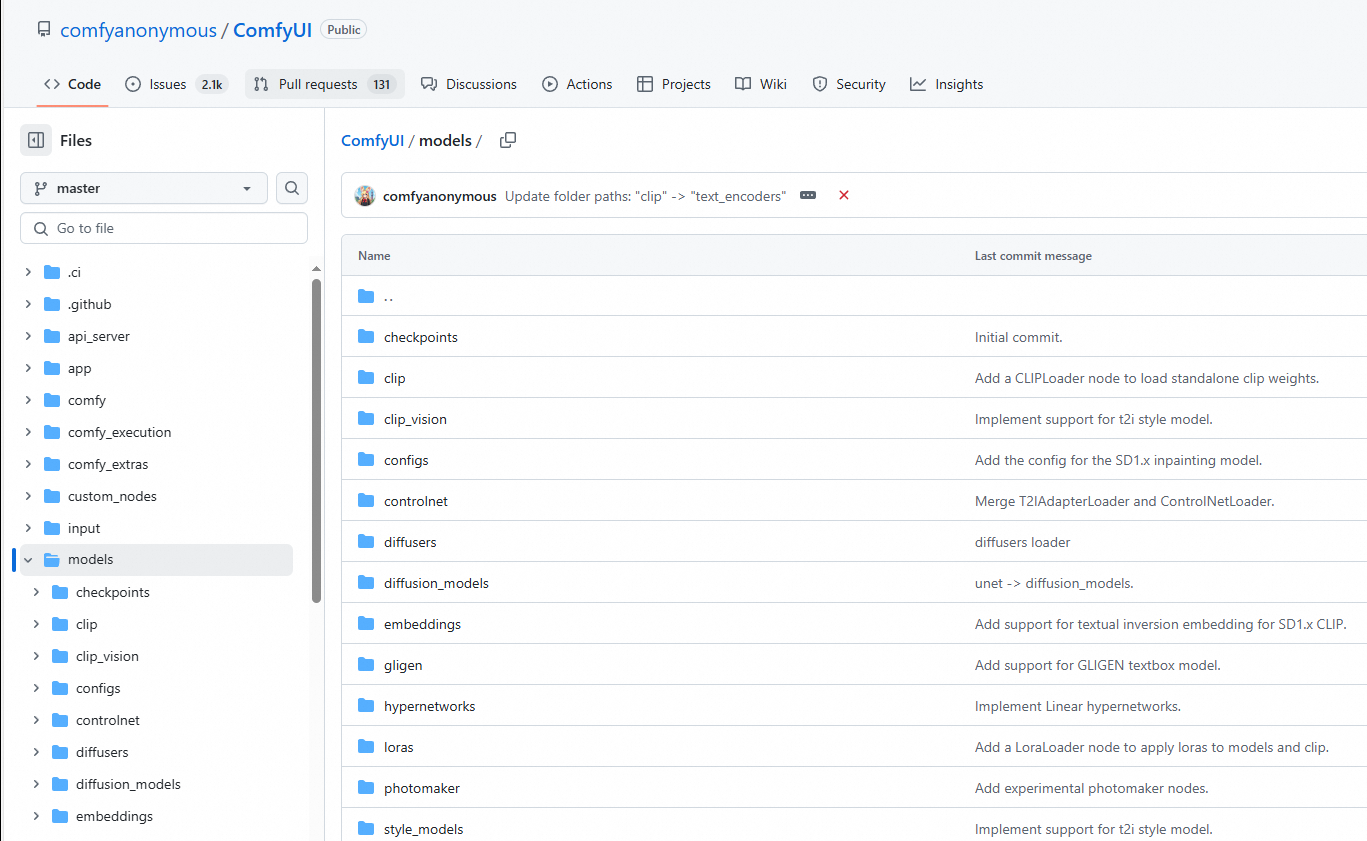
檔案夾名稱
下載的模型
checkpoints
dreamshaperXL_lightningDPMSDE.safetensors
clip
clip_l.safetensors
t5xxl_fp8_e4m3fn.safetensors
clip_vision
clip_vision_g.safetensors
clip_vision_l.safetensors
controlnet
flux-canny-controlnet-v3.safetensors
loras
FLUX1_wukong_lora.safetensors
araminta_k_flux_koda.safetensors
unet
flux1-dev.safetensors
vae
ae.safetensors
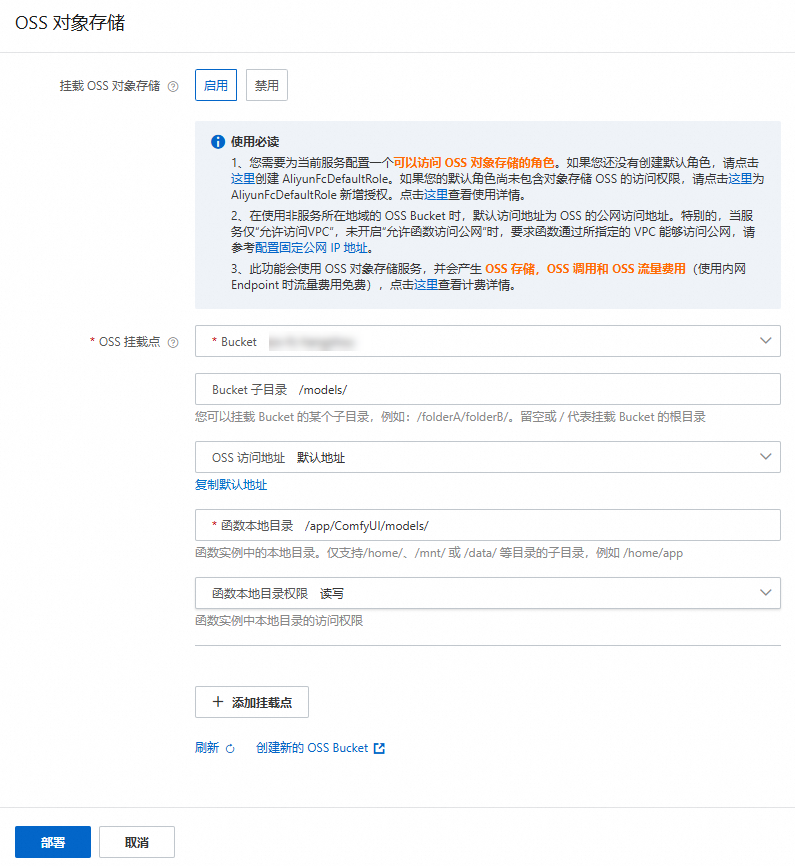
在函數詳情頁面,選擇配置頁簽,在左側導覽列選擇許可權頁簽,為函數配置具有訪問OSS許可權的角色,然後在左側導覽列選擇儲存頁簽,在OSS Object Storage Service地區單擊編輯,在編輯面板中配置以下參數,然後單擊部署。
部署完成後,登入函數執行個體,確認函數本地目錄下模型是否掛載成功。

(可選)開啟ComfyUI,預設的流水線需要一個Checkpoint載入器類型的模型,還需要在OSS的Checkpoint的檔案目錄下上傳Checkpoint類型的模型,例如
dreamshaperXL_lightningDPMSDE.safetensors模型。登入執行個體顯示的路徑如下圖。

點擊執行,查看輸出圖片的效果。
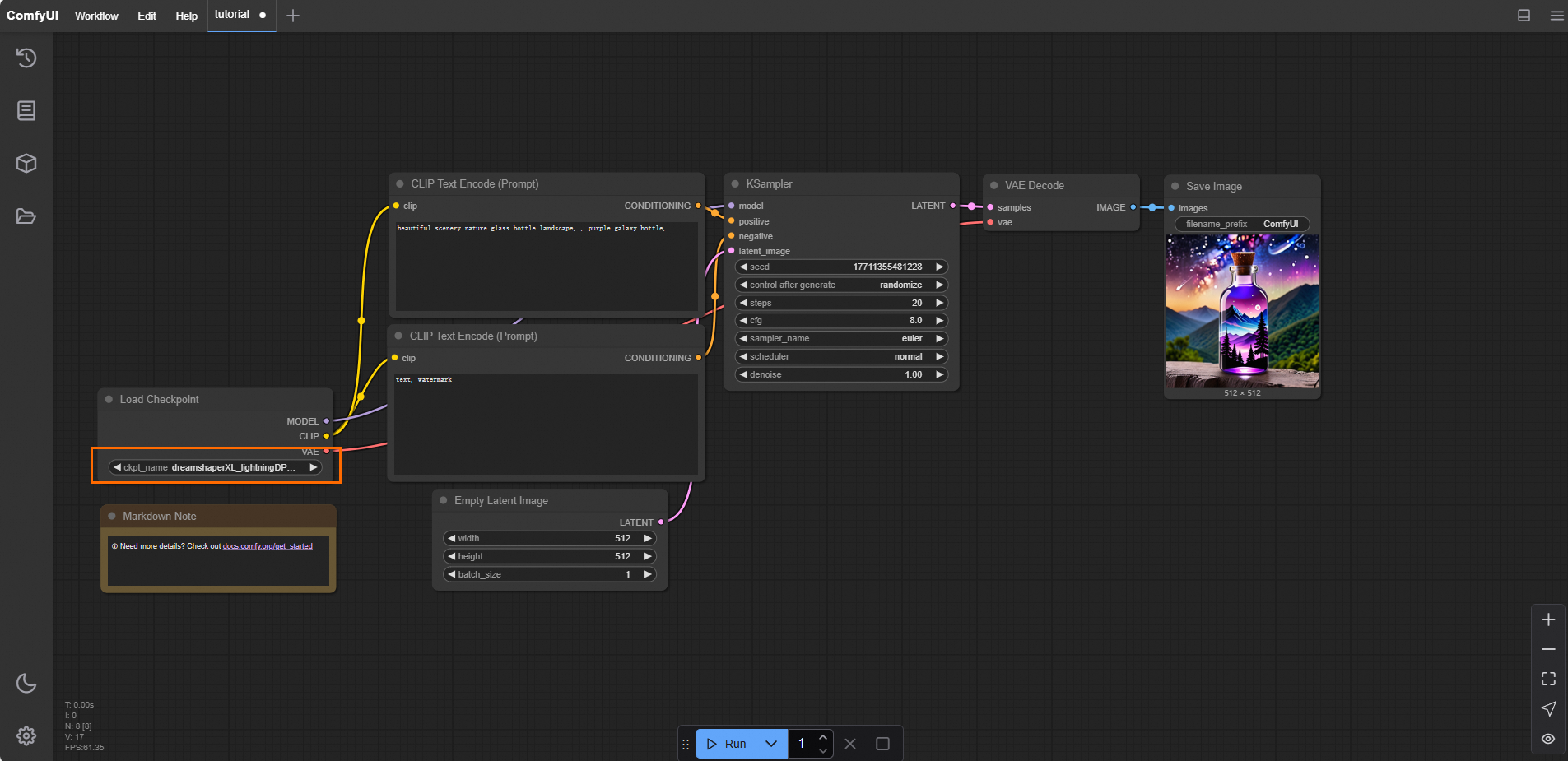
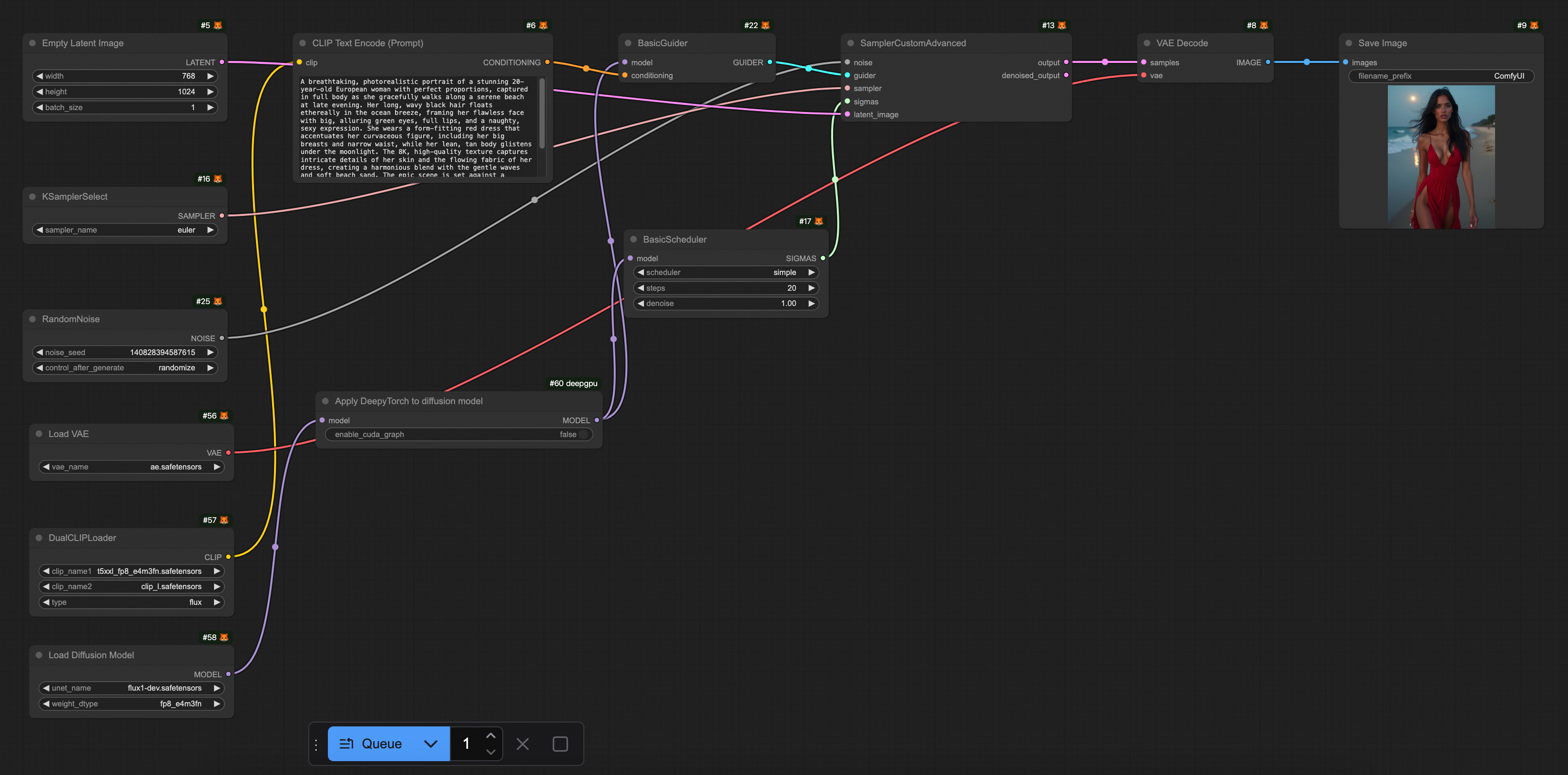
下載預置的工作流程檔案FLUX-base.json。開啟ComfyUI,選擇,匯入已經下載好的FLUX-base.json檔案。這個工作流程使用了
t5xxl_fp8_e4m3fn.safetensors、ae.safetensors和flux1-dev.safetensors模型,點擊運行,效果如下圖所示。
步驟三:推理加速
文生圖服務的推理通常耗時數秒至數十秒,推理加速不僅能縮短回應時間,提升使用者體驗,還能降低資源成本。以下我們介紹兩種推理加速方案:
阿里雲神行工具包(DeepGPU)
什麼是神行工具包(DeepGPU)也提供了對ComfyUI + SD/FLUX的推理加速能力。神行工具包是具有GPU計算服務增強能力的免費工具集,包括業務快速部署工具、GPU資源拆分工具、AI訓練和推理計算最佳化工具以及針對熱門AI模型的專門加速工具等。目前,神行工具包中的推理組件可以免費搭配阿里雲Function Compute,方便使用者更方便、更高效地使用阿里雲Function Compute的GPU資源。
1. DeepGPU安裝
使用DeepGPU加速ComfyUI + SD/FLUX的推理前,需要安裝依賴包:
torch2.5安裝
RUN pip install torch==2.5.0deepgpu-torch安裝
DeepGPU的torch模型加速包,支援FLUX.1、VAE等模型加速。
# ubuntu RUN apt-get update RUN apt-get install which curl iputils-ping -y # centos # RUN yum install which curl iputils -y #先安裝torch,deepgpu-torch依賴python3.10、torch2.5.x+cu124(如需其他版本,請聯絡我們) RUN pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.html把外掛程式下載後,解壓到custom_nodes/目錄下
RUN wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz RUN tar zxf ComfyUI-deepgpu.tar.gz -C /app/ComfyUI/custom_nodes RUN pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.html
2.ComfyUI源碼修改(重要)
依賴的版本
x-flux-comfyui更新到github最新版;
原生LoRA支援
如果有ComfyUI原⽣LoRA模型使⽤LoraLoaderModelOnly載入LoRA模型,並且在使⽤deepgpu-torch加速的情況下,必須修改ComfyUI源碼裡的⼀行代碼。
如果ComfyUI是v0.3.6版本以下
代碼地址:
https://github.com/comfyanonymous/ComfyUI/blob/v0.3.6/comfy/sd.py#L779

在這⼀⾏添加⼀個參數
weight_inplace_update=True。return comfy.model_patcher.ModelPatcher(model, load_device=load_device, off load_device=offload_device, weight_inplace_update=True)如果ComfyUI是v0.3.7版本以上
代碼地址:https://github.com/comfyanonymous/ComfyUI/blob/v0.3.7/comfy/sd.py#L785
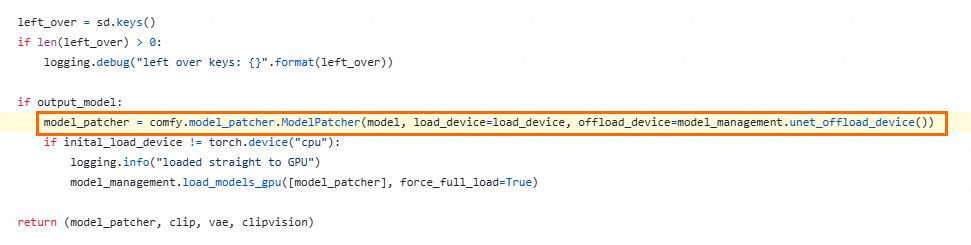
在這⼀⾏添加⼀個參數
weight_inplace_update=True。model_patcher = comfy.model_patcher.ModelPatcher(model, load_device=load_de vice, offload_device=model_management.unet_offload_device(), weight_inplace _update=True)
以下提供一個安裝DeepGPU的樣本鏡像。
# Dockerfile FROM python:3.10 # 安裝系統依賴 RUN apt-get update && apt-get install -y \ git \ wget \ && rm -rf /var/lib/apt/lists/* WORKDIR /app # 複製ComfyUI倉庫 RUN git clone https://github.com/comfyanonymous/ComfyUI.git WORKDIR /app/ComfyUI #設定python 依賴包加速 RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com # 安裝PyTorch(預設NVIDIA CUDA版本,可根據需要修改) RUN pip install torch==2.5.0+cu124 torchvision==0.20.0+cu124 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124 # 安裝專案依賴 RUN pip install -r requirements.txt # ubuntu RUN apt-get update RUN apt-get install which curl iputils-ping -y # centos # RUN yum install which curl iputils -y #先安裝torch,deepgpu-torch依賴python3.10、torch2.5.x+cu124(如需其他版本,請聯絡DeepGPU team) RUN pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.html #把外掛程式下載後,解壓到custom_nodes/目錄下 RUN wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz RUN tar zxf ComfyUI-deepgpu.tar.gz -C /app/ComfyUI/custom_nodes RUN pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.html # 暴露服務連接埠 EXPOSE 8188 # 啟動命令 CMD ["python", "main.py"]
3. 環境變數配置
在阿里雲Function Compute中使用DeepGPU時,需要配置特定的環境變數DEEPGPU_PUB_LS=true和DEEPGPU_ENABLE_FLUX_LORA=true。

4. (可選)配置GPU閑置模式
通過配置預留執行個體,您可以有效降低執行個體冷啟動導致的請求延遲問題。同時,您可以配置預留執行個體的Auto Scaling規則如定時伸縮和水位伸縮,提高執行個體使用率,解決資源浪費問題。
5. DeepGPU ComfyUI外掛程式使用方法
外掛程式中包含4種DeepGPU類型的節點,可以在ComfyUI介面搜尋方塊中通過輸入DeepyTorch找到:
Apply DeepyTorch to disffusion model
Apply DeepyTorch to vae model
DeepTorch Sampler to replace XlabsSampler
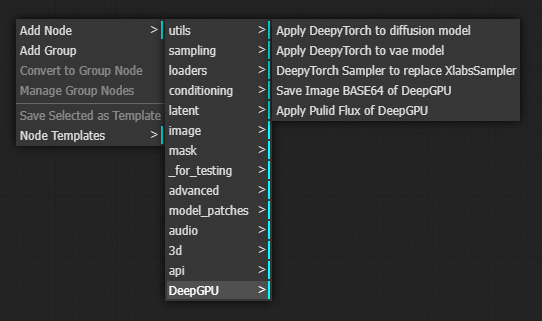
使用指南
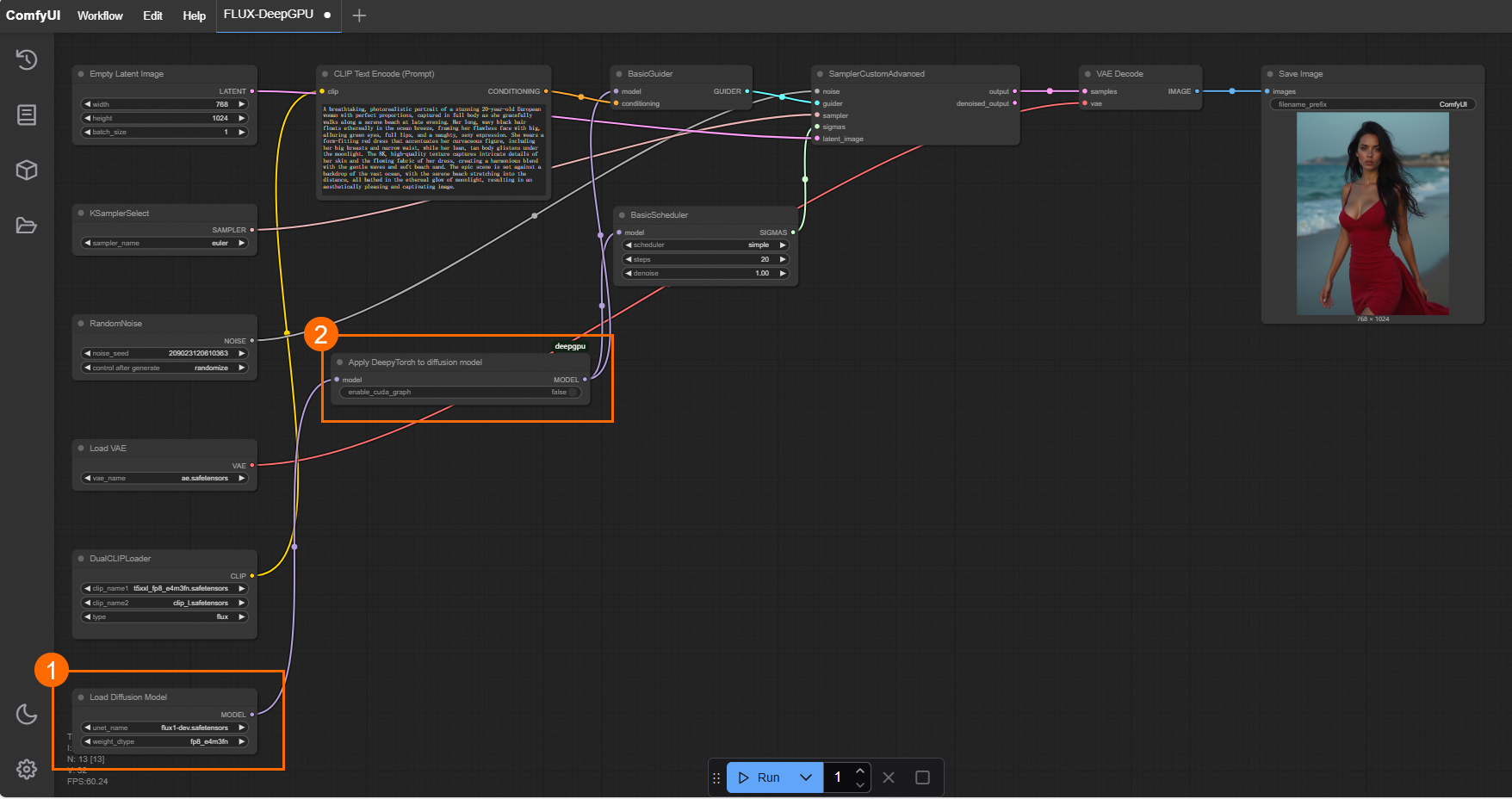
插入位置:針對flux將Apply DeepyTorch to disffusion model節點插入到Load Diffusion Model、或者Load Flux LoRA、或者Apply Flux IPAdapter節點後面,針對其他模型則插入到Load Checkpoint、或者LoraLoaderModelOnly節點後面。以匯入為例,如下圖所示。
Sampler替換:DeepTorch Sampler to replace XlabsSampler節點針對flux用於替換XLabsSampler節點。
ComfyUI TorchCompile*節點
目前有一些開源推理加速節點,包括但不僅限於:
TorchCompileModel
TorchCompileVAE
TorchCompileControlNet
TorchCompileModelFluxAdvanced
這類節點利用PyTorch的即時編譯能力,通過將動態計算圖轉換為高效的靜態代碼,從而最佳化和加速模型執行,提升資源使用率。
當前這些節點多處於BETA或實驗階段。
TorchCompile*節點與 DeepGPU 的使用方式和效能對比
我們對比測試了ComfyUI內建的TorchCompile節點與DeepGPU節點在推理加速方面的表現,分析它們的使用方式、加速效果和適用情境,供使用者參考。
模型列表
檔案夾名稱 | 下載的模型 |
clip | clip_l.safetensors |
t5xxl_fp8_e4m3fn.safetensors | |
clip_vision_l.safetensors | |
loras | FLUX1_wukong_lora.safetensors |
unet | flux1-dev.safetensors |
vae | ae.safetensors |
配置參數
Sampler
steps: 20
Empty Latent Image
width: 768
height: 1024
測試平台
阿里雲Function Compute fc.gpu.ada.1執行個體。
推理加速架構情境支援矩陣 & 推理加速效果
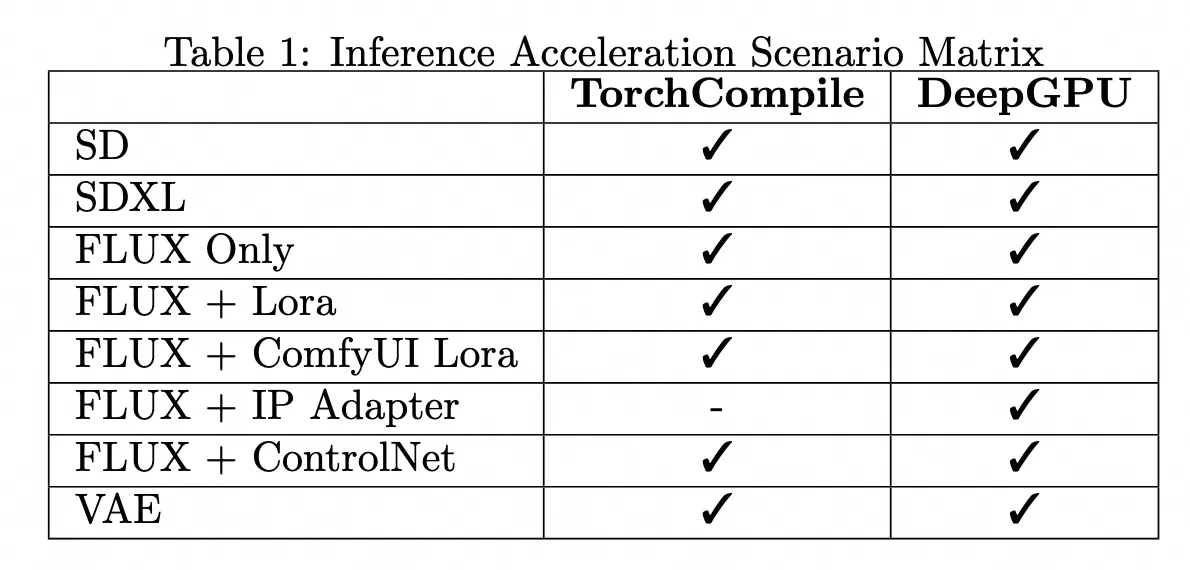
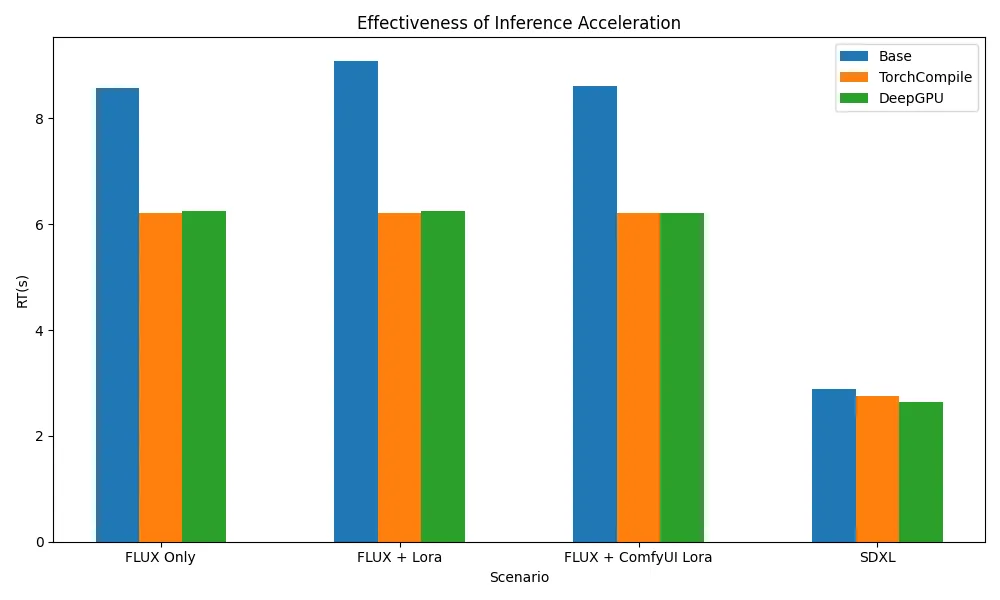
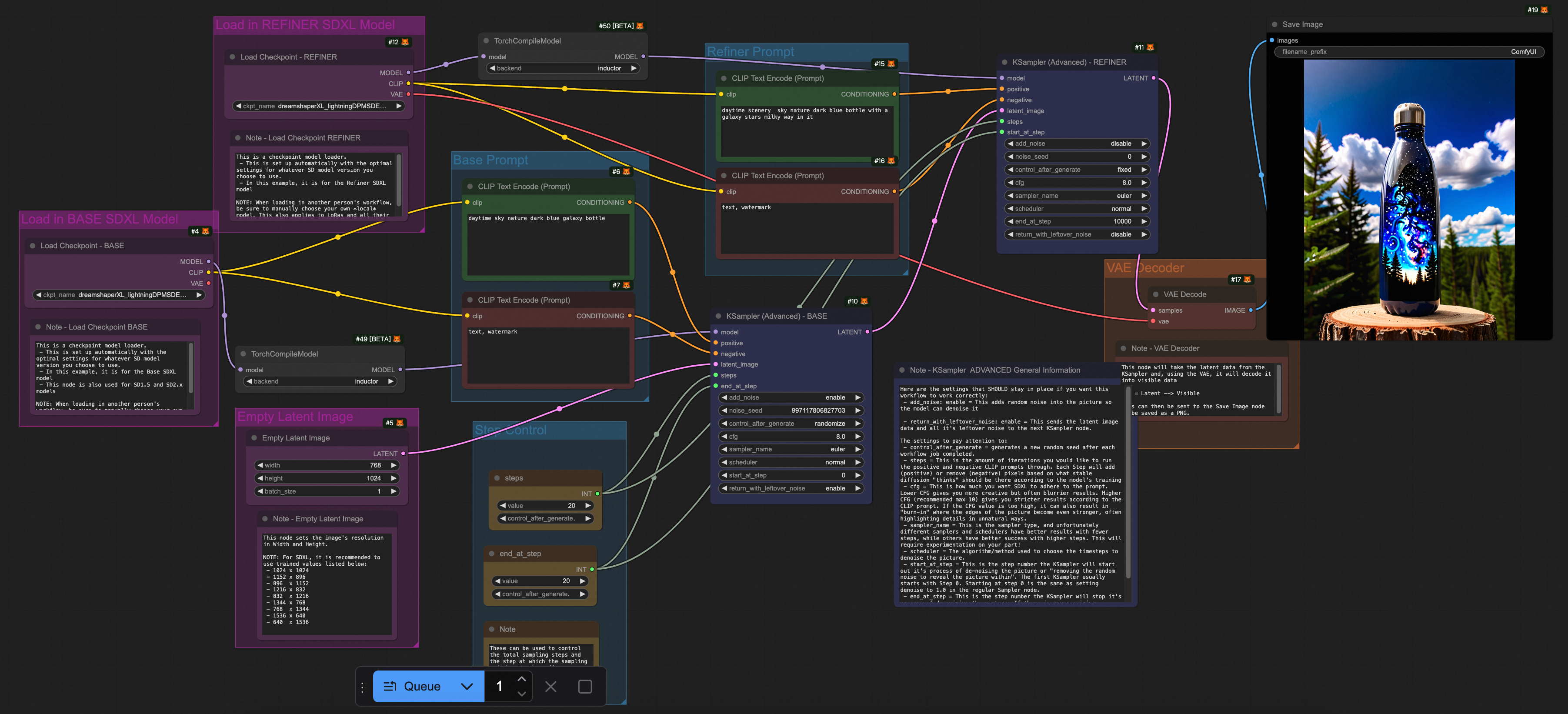
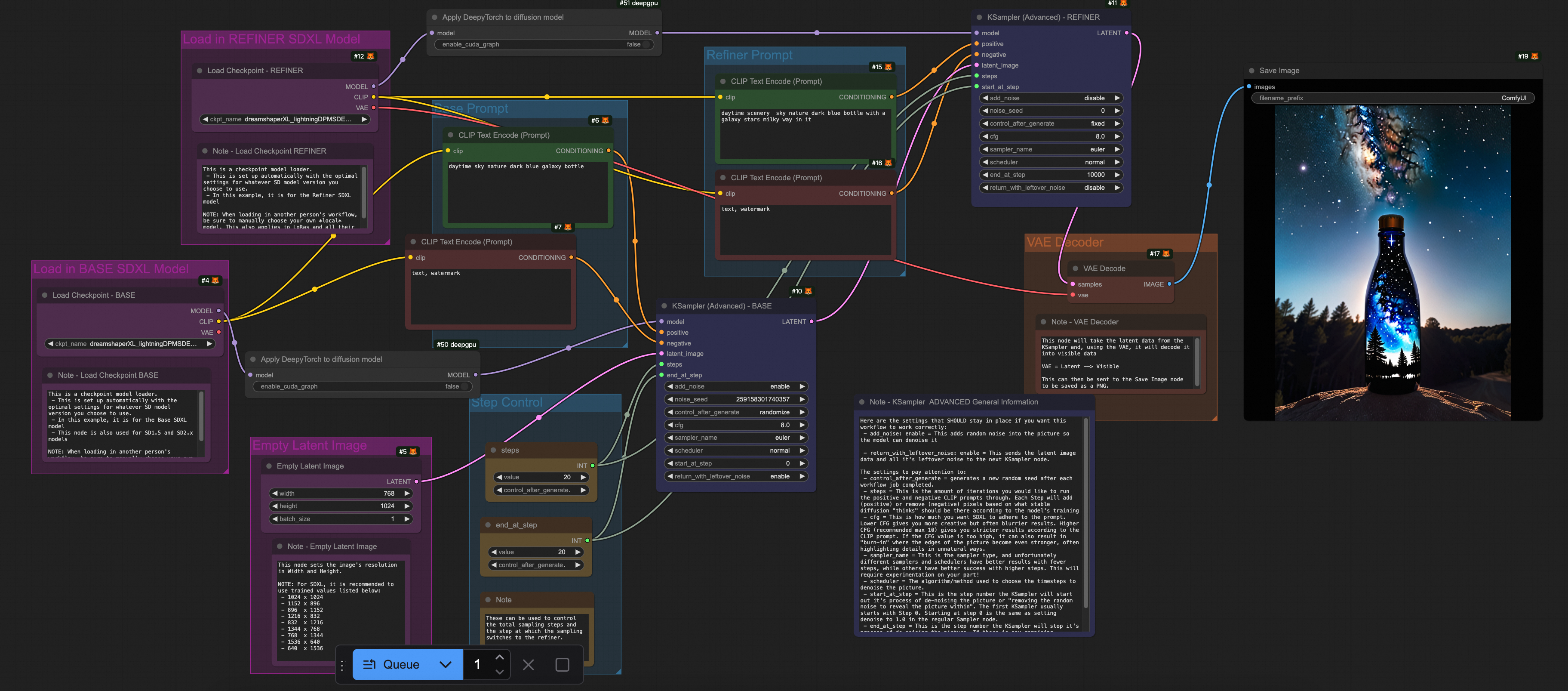
測試結果顯示,無論是TorchCompile系列節點,還是DeepGPU,均能覆蓋ComfyUI + SD/FLUX的大部分使用情境,並在Flux相關情境下實現約20%-30%的推理加速。
測試Workflows
以下提供不同模型使用的推理加速的Workflows.json檔案。
情境 | Workflow |
FLUX only |
|
FLUX + Lora |
|
FLUX + ComfyUI Lora |
|
SDXL |
|
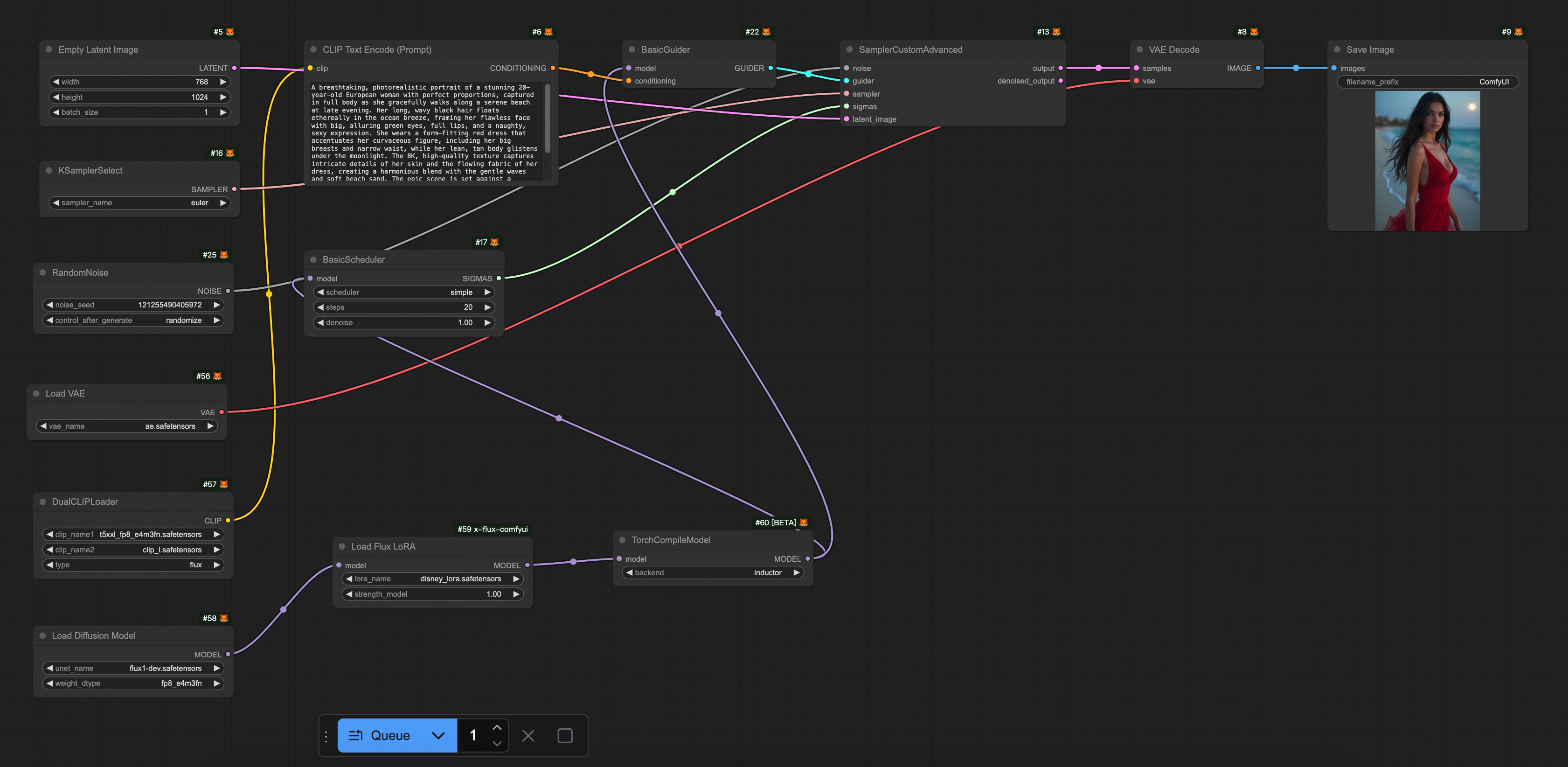
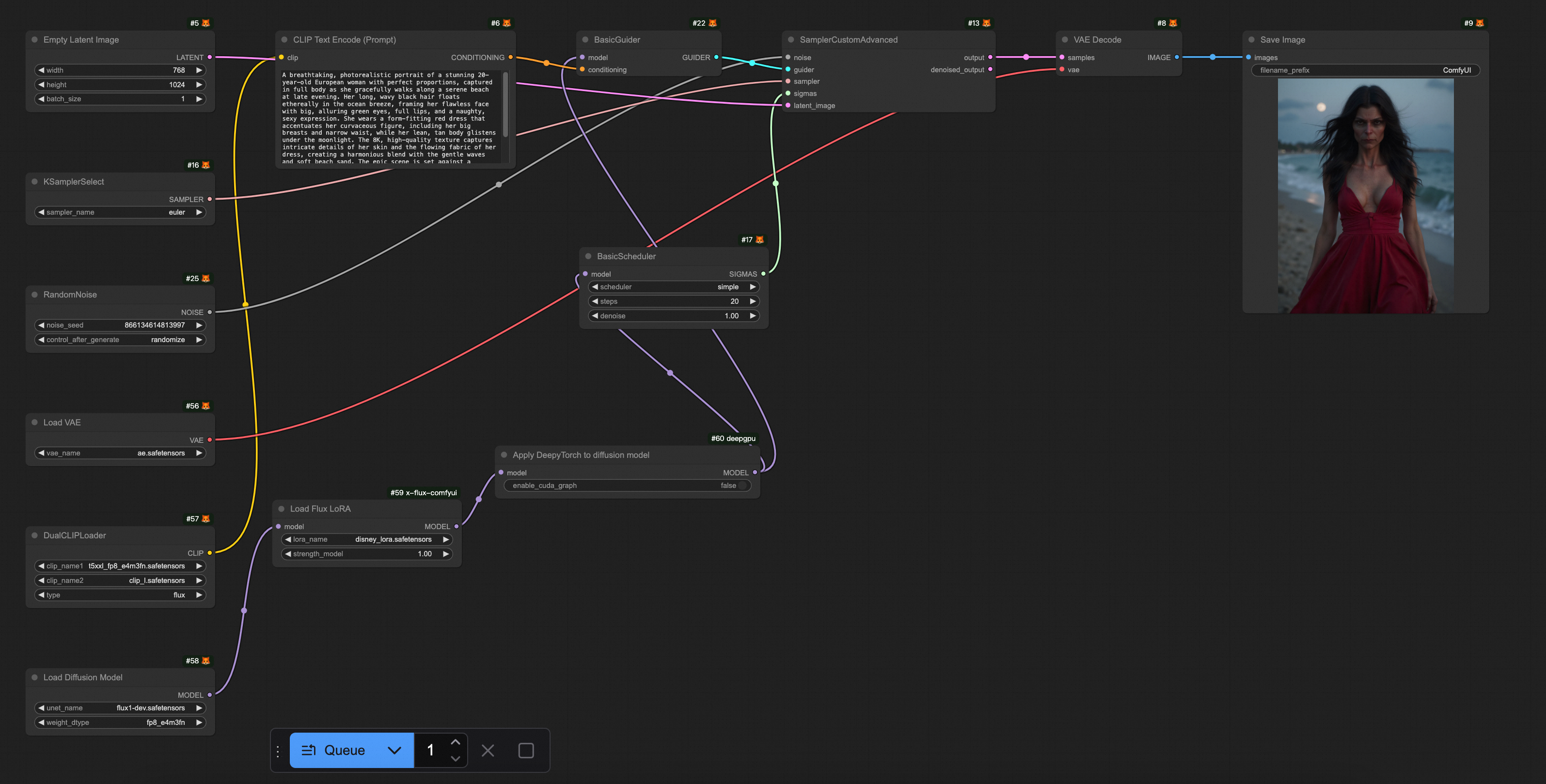
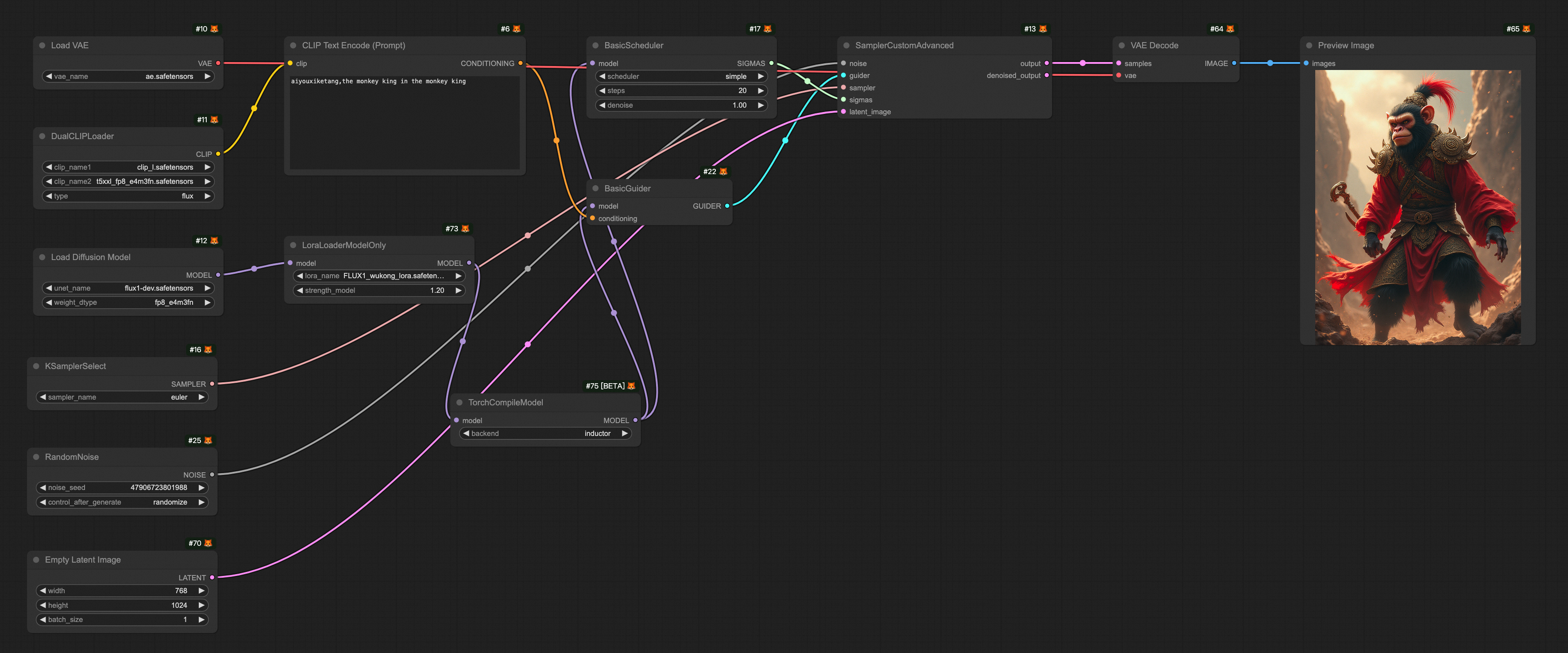
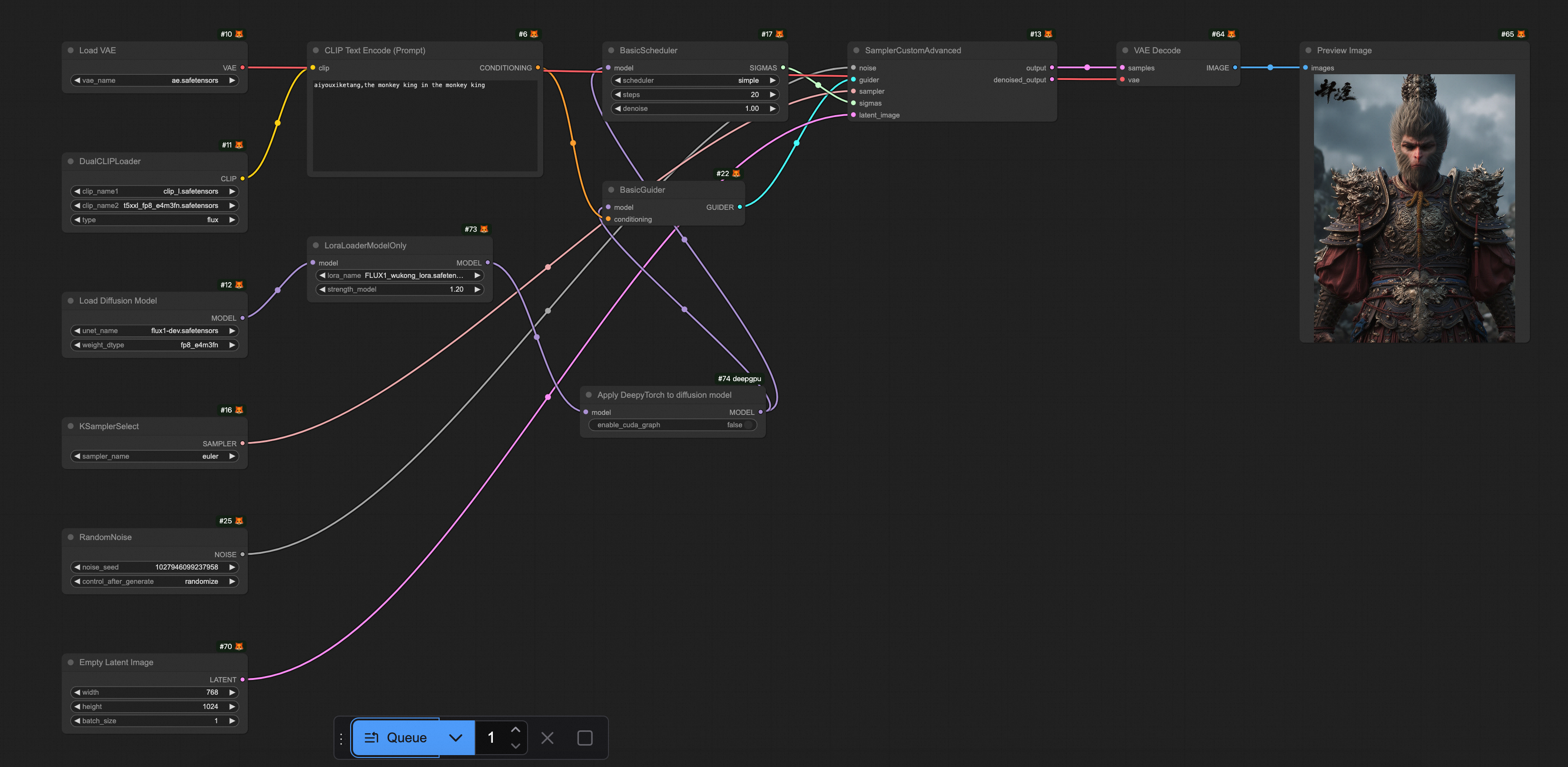
相關文檔
長時間啟動並執行GPU執行個體可能出現故障,FC提供預設的基於請求的健全狀態檢查機制,並支援使用者自訂配置執行個體健全狀態檢查邏輯。
FC預設提供函數和執行個體的監控報表,使用者無需額外配置即可查看。如果需要採集函數日誌以便問題排查,可以配置日誌採集。