本文介紹在使用Function Compute部署AI推理應用時,模型儲存的常用方法,並對這些方法的優缺點和適用情境進行比較分析。
背景資訊
函數的儲存類型請參見函數儲存選型。其中,適合用作GPU儲存模型的包括以下兩種。
除此之外,GPU函數使用自訂容器鏡像部署業務,因此還可以將模型檔案直接放置到容器鏡像中。
每種方法都有其獨特的應用情境和技術特點,選擇模型儲存方式時應當考慮具體需求、執行環境以及團隊的工作流程,以達到模型儲存在效率和成本上的平衡。
模型隨容器鏡像分發
將訓練好的模型和相關應用代碼一起打包在容器鏡像中,模型檔案隨容器鏡像分發,這是最直接的方法之一。
優缺點
優點:
便利性:建立好鏡像後,可以直接運行它進行推理而無需額外配置。
一致性:確保每個環境中的模型版本都是一致的,減少了由於不同環境中模型版本差異導致的問題。
缺點:
鏡像體積:鏡像可能會非常大,特別是對於大尺寸模型。
更新耗時:每次模型更新時都需要重新構建和分發鏡像,這可能是一個耗時的過程。
說明
為了提升函數執行個體的冷啟動速度,平台會對容器鏡像進行預先處理。如果鏡像尺寸過大,一方面可能會超出平台對鏡像大小的限制,另一方面也會導致鏡像加速預先處理所需時間的延長。關於平台鏡像大小限制,請參見GPU鏡像大小限制是多少?。
使用情境
模型尺寸相對較小,例如百MB左右。
模型變更頻率較低,可以考慮將模型打包在容器鏡像中。
如果您的模型檔案較大、迭代頻繁或隨鏡像發布時超過平台鏡像大小限制,建議模型與鏡像分離。
模型放在NAS檔案儲存體
Function Compute平台支援將NAS檔案系統掛載到函數執行個體的指定目錄,將模型儲存在NAS檔案系統,應用程式通過訪問NAS掛載點目錄實現模型檔案的載入。
優缺點
優點:
相容性:相比
FUSE類檔案系統,NAS提供的POSIX檔案介面較為完整和成熟,因此在應用相容性方面表現較好。容量:NAS能夠提供PiB級的儲存容量。
缺點:
依賴VPC網路:一方面,需要為函數配置VPC訪問通道才能訪問NAS掛載點,在配置時涉及的雲產品許可權點相對較多;另一方面,函數執行個體冷啟動時,平台為執行個體建立VPC訪問通道會產生秒級的耗時。
內容管理方式比較單一:NAS檔案系統需要掛載才能使用,相對單一,需要建立相應的商務程序將模型檔案分發到NAS執行個體上。
不支援雙活和多AZ,詳情請參見NAS常見問題。
說明
在大量容器同時啟動載入模型的情境下,容易觸及NAS的頻寬瓶頸,導致執行個體啟動耗時增加,甚至因逾時而失敗。例如,定時HPA大量啟動預留GPU執行個體、突發流量觸發大量按需GPU執行個體的建立。
可以從控制台查看NAS效能監控(讀吞吐)。
可以通過向NAS增加資料量的方式來提升NAS讀寫輸送量。
採用NAS來儲存模型檔案,建議選用通用型NAS中的“效能型”,其主要原因在於該類型NAS可以提供較高的初始讀頻寬,約600MB/s,詳情請參見通用型NAS。
使用情境
在按量GPU使用情境下,需要極速的啟動效能。
模型放在OSSObject Storage Service
Function Compute平台支援將Object Storage Service Bucket掛載到函數執行個體的指定目錄,應用程式可以直接從OSS掛載點載入模型。
優點
頻寬:OSS的頻寬上限較高,相比NAS不易出現函數執行個體間頻寬爭搶現象,詳情請見OSS使用限制及效能指標。與此同時,還可以通過開通OSS加速器獲得更高的吞吐能力。
管理方法多樣:
配置簡單:相比NAS檔案系統,函數執行個體掛載OSS Bucket無需打通VPC,即配即用。
成本:相比NAS,一般來說OSS成本更優。
說明
從實現原理上,OSS掛載使用FUSE使用者態檔案系統機制實現。應用訪問OSS掛載點上的檔案時,平台最終將其轉換為OSS API調用實現對資料的訪問。因此OSS掛載還有以下特徵:
其工作在使用者態,會佔用函數執行個體的資源配額,如CPU、記憶體、臨時儲存等,因此建議在較大規格的GPU執行個體上使用。
資料的訪問使用OSS API,其輸送量和時延最終受限於OSS API服務,因此更適合訪問數量較少的大檔案(如模型載入情境),不宜用於訪問大量小檔案。
當前的實現還無法使能系統的PageCache,相比NAS檔案系統,這意味著單個執行個體內應用如果需要多次訪問同一個模型檔案,無法利用PageCache加速效果。
使用情境
大量執行個體並行載入模型,需要更高儲存吞吐能力避免執行個體間頻寬不足的情況。
需要本地冗餘,或者多地區部署的情境。
訪問數量較少的大檔案(比如模型載入情境)。
總結對比
對比項 | 隨鏡像分發 | NAS掛載 | OSS掛載 |
模型尺寸 |
| 無 | 無 |
吞吐 | 較快 |
|
|
相容性 | 好 | 好 |
|
管理方法 | 容器鏡像 | VPC內掛載後使用 |
|
多AZ | 支援 | 不支援 | 支援 |
PageCache使能 | 有 | 有 | 無 |
成本 | 不產生額外費用 | 一般來說NAS比OSS略高,請以各產品當前計費規則為準
| |
基於以上對比,根據FC GPU不同使用模式、不同容器並發啟動數量、不同模型管理需求等維度,FC GPU模型託管的最佳實務如下:
測試資料
通過對Stable Diffusion模型切換耗時的測量,對比不同模型儲存方法的效能差異。本次測試的選取的模型和模型尺寸大小如下表。
模型 | 尺寸(GB) |
Anything-v4.5-pruned-mergedVae.safetensors | 3.97 |
Anything-v5.0-PRT-RE.safetensors | 1.99 |
CounterfeitV30_v30.safetensors | 3.95 |
Deliberate_v2.safetensors | 1.99 |
DreamShaper_6_NoVae.safetensors | 5.55 |
cetusMix_Coda2.safetensors | 3.59 |
chilloutmix_NiPrunedFp32Fix.safetensors | 3.97 |
pastelmix-fp32.ckpt | 3.97 |
revAnimated_v122.safetensors | 5.13 |
sd_xl_base_1.0.safetensors | 6.46 |
第一次模型切換耗時(單位:秒) | 第二次模型切換耗時(單位:秒) |
|
|
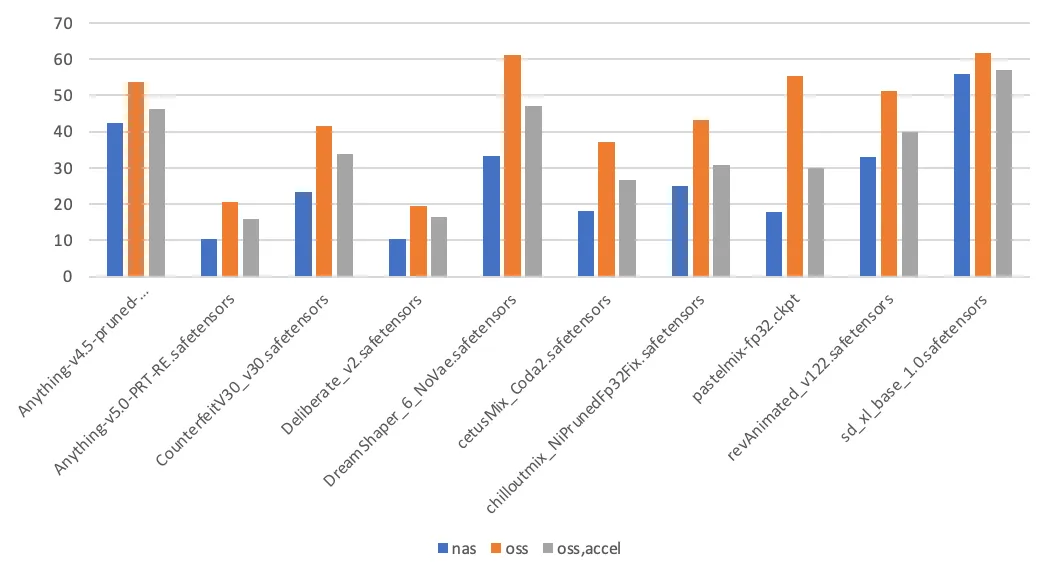
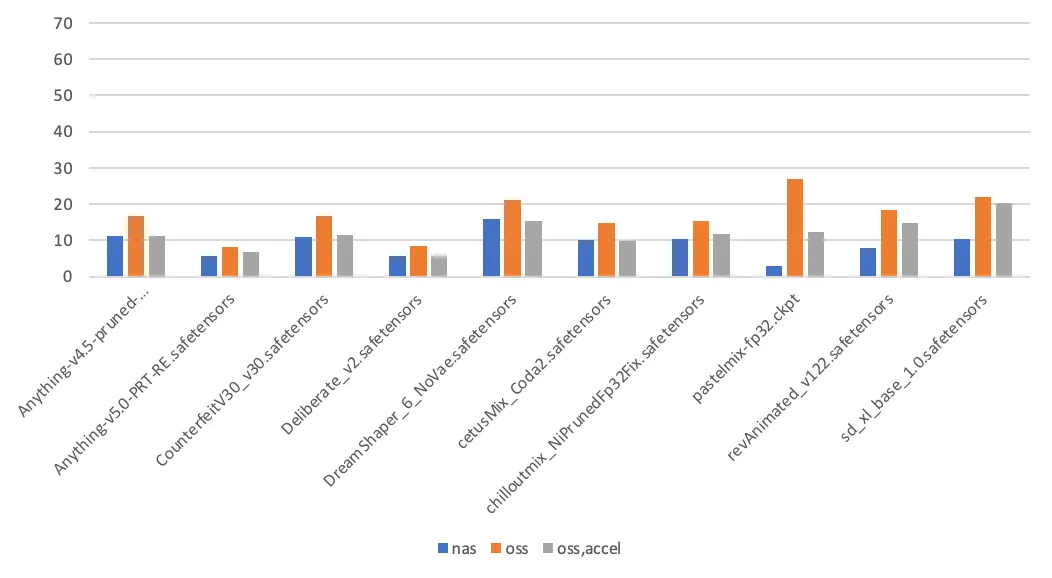
測試結論如下:
PageCache使能。在這個情境中,Stable Diffusion第一次載入模型時,會讀模數型檔案兩次,其中一次用於計算模型檔案的雜湊值。後續觸發模型載入時,則唯讀模數型檔案一次。第一次訪問NAS掛載點上的檔案時,會在核心填充相應的PageCache,從而加速第二次訪問。訪問OSS掛載點不具備使能PageCache的特性。
影響耗時的其他因素。除了儲存介質本身,模型載入耗時還與應用本身的實現細節相關,如應用本身的吞吐能力,以及讀模數型檔案時的IO模式(順序讀取、隨機讀取)。