本文檔提供Realtime Compute Flink 的關鍵警示指標、警示配置建議及營運實踐樣本,協助您更好地監控系統效能並進行故障診斷。
前提條件
請參見配置監控警示,根據您工作空間使用的監控服務類型,選擇相應配置方式。
ARMS的多指標監控只能通過自訂PromQL支援,如果需要簡易化配置,仍可以通過CloudMonitor進行警示配置。
推薦警示規則配置
情境 | 組合指標/事件名稱 | 規則配置 | 層級 | 處理動作 |
作業運行狀態事件 | = FAILED(事件警示) | P0 | ①檢查重啟策略是否配置不當(建議使用預設配置)。 ②定位是重啟策略導致,還是 JobManager/TaskManager 異常導致。 ③從最近的快照/成功的Checkpoint 恢複生產。 | |
Overview/作業每分鐘錯誤恢複次數 | ≥ 1 連續 1 個周期 | P0 | ①定位問題
②從最近的快照/成功的Checkpoint 恢複生產。 | |
Checkpoint 成功次數(5 min 累計) | ≤ 0 連續 1 周期 | P0 | ①參閱系統檢查點排查checkpoint失敗根本原因。 ②定位問題
③動態更新配置或從最近成功的Checkpoint恢複生產。 | |
Overview/業務延時 && 每秒Source端輸入記錄數 | 最大值延時≥180000 輸入記錄數≥0 連續 3 個周期 | P1 | ①參閱監控指標說明排查延遲原因。
②根據具體原因調整
| |
Overview/每秒Source端輸入記錄數 && 源端未處理資料時間 | 輸入記錄數≤0(業務而定) 最大值未處理時間≥60000 持續 5 個周期 | P1 | ①可查看taskmanager.log、火焰圖、上遊服務指標等。確認問題是上遊無資料/限流/異常,還是線程棧卡死。 ②根據具體原因調整
| |
Overview/每秒輸出到Sink端記錄數 | ≤ 0 連續 5 個周期 | P1 | ①確認資料是否抵達 Sink 運算元
②確認 Sink 是否能寫入外部系統
③臨時雙寫降級,將資料寫入備用儲存。 | |
CPU/ 單個TM 的CPU利用率 | ≥ 85 % 連續 10 周期 | P2 | ①看火焰圖或Flink UI定位熱點運算元。
②適當增加瓶頸運算元的並行度,或為TaskManager分配更多CPU Core。 | |
TM的堆記憶體已使用 | ≥ 90 % 連續 10 周期 | P2 | ①查看 GC 日誌定位問題。
②根據具體原因調整:增加Heap或調大並行度降低單槽資料量。 |
作業可用性
作業失敗警示
開發控制台(ARMS)
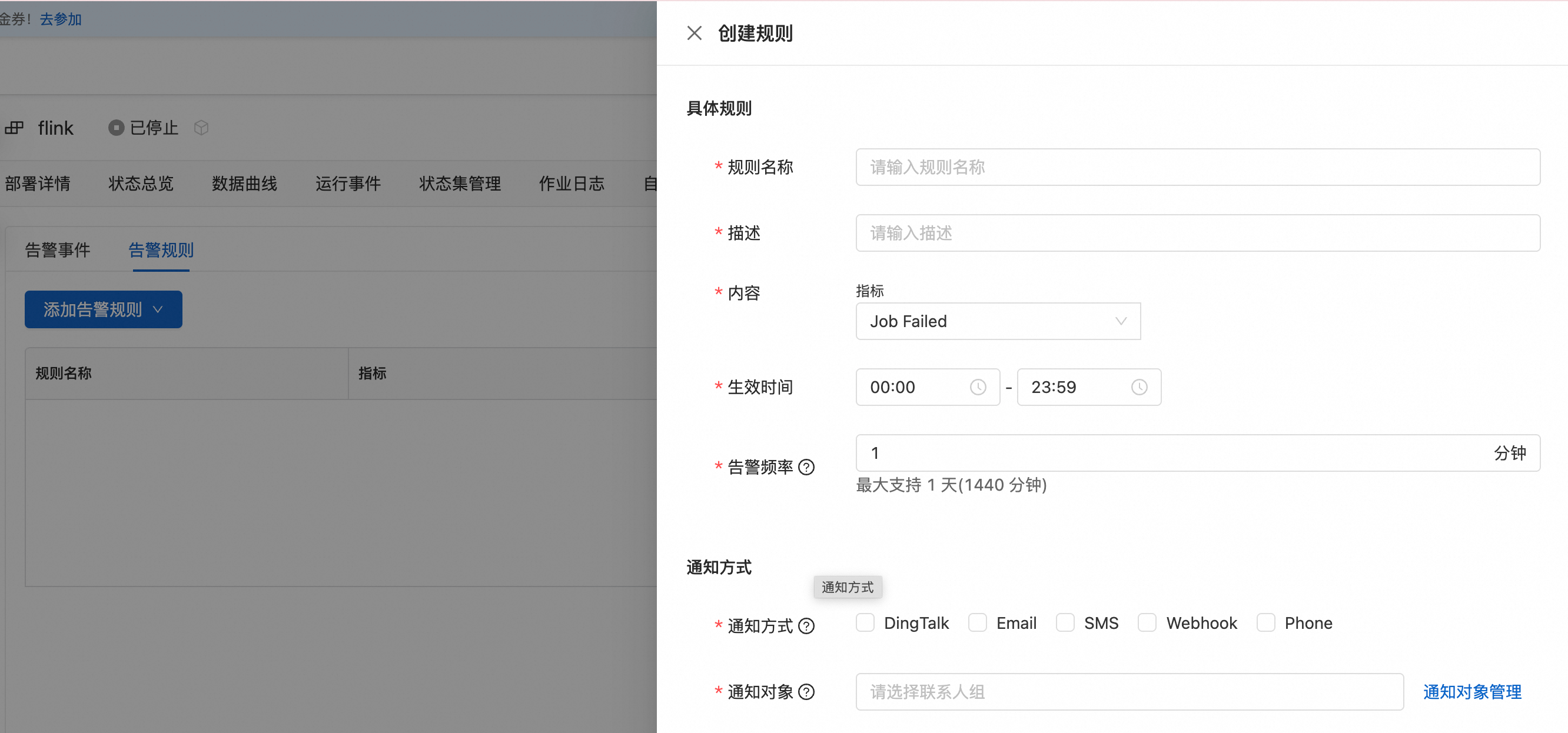
登入Realtime Compute控制台,單擊目標工作空間操作列下的控制台。
在頁面,單擊目標作業名稱。
單擊警示配置頁簽。
CloudMonitor
在左側導覽列,選擇。
在訂閱策略頁簽,單擊建立訂閱策略。
在建立訂閱策略頁面,配置相關參數,參數詳情請參見管理事件訂閱(推薦)。

作業穩定性
防止 JobManager 頻繁重啟
指標:
作業每分鐘錯誤恢複次數規則:1 分鐘內作業重啟警示
配置建議:
作業每分鐘錯誤恢複次數監控值 >= 1
時間周期:1分鐘
通知:電話+簡訊+郵件+WebHook(Critical)
Checkpoint 成功率保障
指標:
每分鐘完成checkpoint數量規則:Checkpoint5分鐘無成功警示
配置建議:
每分鐘完成checkpoint數量監控值 <= 0
時間周期:5分鐘
通知:電話+簡訊+郵件+WebHook(Critical)
資料即時性
保障 SLA 延遲
指標:
業務延時每秒Source端輸入記錄數
規則:有資料流入且業務延時超過5分鐘則警示(閾值和警示層級可根據業務調整)
配置建議:
業務延時最大值 >= 300000
每秒Source端輸入記錄數監控值 > 0
時間周期:5分鐘
上遊資料流中斷檢測
指標:
每秒Source端輸入記錄數源端未處理資料的時間
規則:有資料流入且業務延時超過5分鐘則警示(閾值和警示層級可根據業務調整)
配置建議:
每秒Source端輸入記錄數監控值 <= 0
源端未處理資料的時間最大值 > 60000
時間周期:5分鐘
下遊資料無輸出檢測
指標:
每秒輸出到Sink端記錄數規則:無資料輸出超過5分鐘則警示(閾值和警示層級可根據業務調整)
配置建議:
每秒輸出到Sink端記錄數監控值 <= 0
時間周期:5分鐘
資源效能瓶頸
CPU效能瓶頸
指標:
單個TM CPU的利用率規則:CPU使用率大於85%超過10分鐘則警示
配置建議:
單個TM CPU的利用率最大值 >= 85
時間周期:10分鐘
記憶體效能瓶頸
指標:TM的堆記憶體已使用
規則:堆記憶體使用量率大於90%超過10分鐘則警示
配置建議:
TM的堆記憶體已使用最大值 >= 閾值(90%)
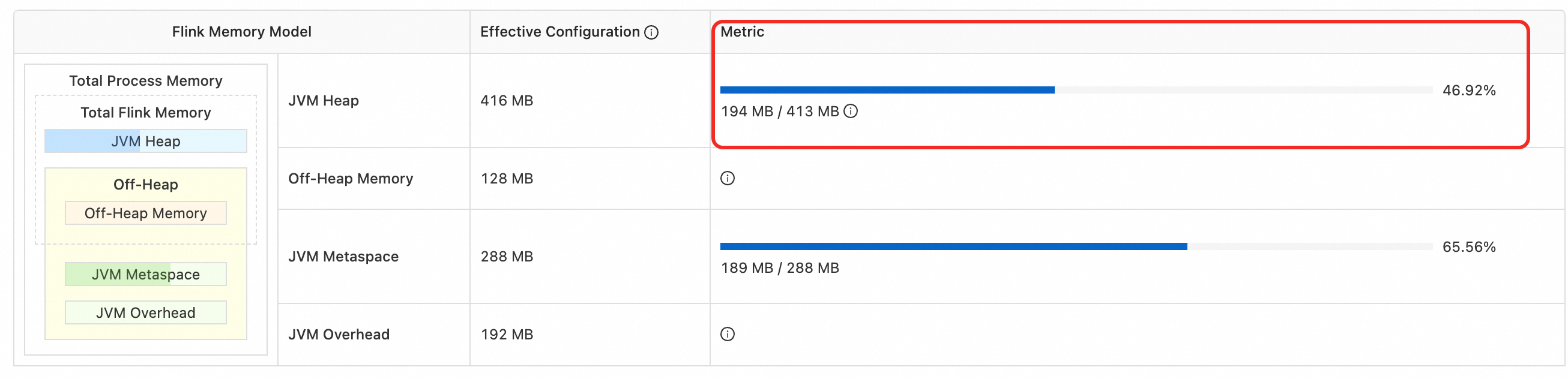
該閾值可在中查看,如圖 194 MB / 413 MB。可以設定閾值為372 MB。
時間周期:10分鐘