本文為您介紹資料正確性有關的常見問題。
報錯:doesn't support consuming update and delete changes which is produced by node TableSourceScan
Lindorm Connector預設啟用的upsert materialize運算元因毫秒級時間戳記精度導致資料被覆蓋或錯誤刪除,如何解決?
為什麼作業沒有輸出?
情境描述
上線運行作業後,下遊結果表中沒有資料。
排錯流程圖
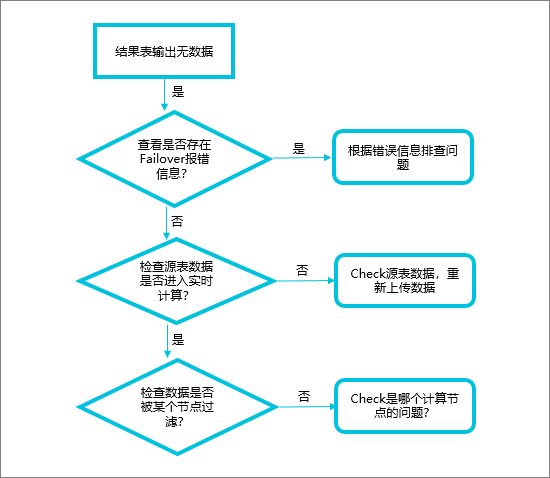
檢查作業中是否存在Failover
排錯指引
查看Failover報錯資訊,分析作業運行異常原因。
解決方案
解決Failover問題,使作業正常運行。
檢查源表資料是否進入Realtime ComputeFlink版
排錯指引
這種情況下沒有Failover,但資料延時會很大,請查看監控警示頁面numRecordsInOfSource,檢查各Source輸入是否有資料。
解決方案
檢查源表,保證上遊有資料進入Realtime ComputeFlink版。
檢查資料是否被某個節點過濾
在其他配置中添加
pipeline.operator-chaining: 'false',具體操作請參見如何配置自訂的作業運行參數?。將節點拆分,然後觀察每個節點的Bytes Received(輸入)和Bytes Sent(輸出),確定資料在哪個節點被過濾,如果某個節點輸出為0,輸入不為0,說明資料被這個節點過濾了。常見的導致資料無輸出的運算元包括join、window或where。檢查下遊是否由於預設緩衝機制緩衝了資料
解決方案:排除作業的商務邏輯異常後,調整下遊儲存的batchsize的大小。
重要如果batchsize參數設定得過小,則可能會造成下遊資料庫I/O壓力過大、存在效能瓶頸的風險。例如,如果將batchsize設定為1,說明處理完一條資料,就會請求一次資料庫,巨量資料情境下會導致資料庫壓力增大。
檢查下遊RDS,是否存在死結
您可以使用print結果表,將計算結果列印到日誌中,對日誌進行分析,判斷無輸出結果的原因。詳情請參見如何在控制台查看print資料結果?
如何定位Flink無法讀取來源資料的問題?
當Flink無法讀取來源資料時,建議從以下幾個方面進行排查並處理:
檢查上遊儲存和Realtime ComputeFlink版之間網路是否連通。
Realtime ComputeFlink版僅支援訪問相同地區、相同VPC下的儲存。如果您有訪問跨VPC儲存資源或者通過公網訪問Realtime ComputeFlink版的特殊需求,請查看以下文檔:
如果您需要跨VPC訪問儲存資源,則可以通過5種方式解決,詳情請參見如何訪問跨VPC的其他服務?。
如果您需要通過公網訪問Realtime ComputeFlink版,則可以使用阿里雲提供的NAT Gateway實現VPC網路和公網的連通。詳情請參見Realtime ComputeFlink版如何訪問公網?
檢查上遊儲存中是否已配置了白名單。
上遊儲存中需要配置的產品有Kafka和ES。您可以按照以下步驟配置白名單:
擷取Realtime ComputeFlink版虛擬交換器的網段。
擷取方法請參見設定白名單。
在上遊儲存中配置Realtime ComputeFlink版白名單。
上遊儲存中配置白名單的方法,請參見對應DDL文檔的前提條件中的文檔連結,例如Kafka源表前提條件。
檢查DDL中定義的欄位類型、欄位順序和欄位大小寫是否和物理表一致。
為了確保一致性,您可以按照物理表的欄位類型和順序,以及使用相同的大小寫規範來編寫DDL。上遊儲存支援的欄位類型和Realtime ComputeFlink版支援的欄位類型可能不完全一致,但存在一定的映射關係。您需要按照DDL定義的欄位類型映射關係一對一匹配,詳情請參見對應DDL文件類型映射文檔,例如Log ServiceSLS源表類型映射。
查看源表Taskmanager.log日誌中是否有異常資訊。
如果有異常報錯,請先按照報錯提示處理問題。查看源表Taskmanager.log日誌的操作如下:
在頁面,單擊目標作業名稱。
在狀態總覽頁簽,單擊Source節點。
在SubTasks頁簽操作列,單擊Open TaskManager Log Page。
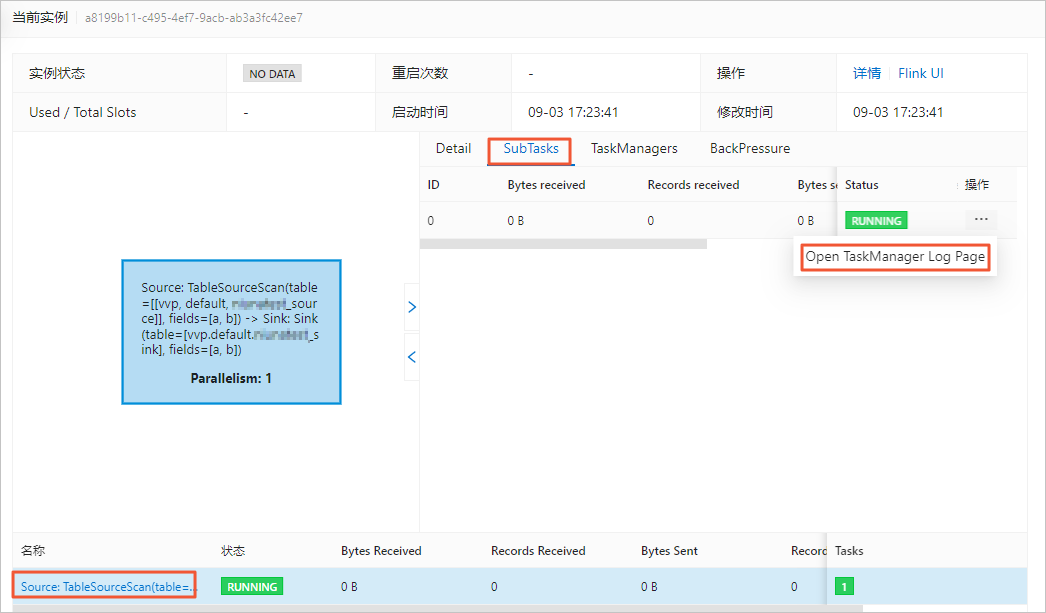
在logs頁簽,查看日誌資訊。
在當前頁面尋找最後一個Caused by資訊,即第一個Failover中的Caused by資訊,往往是導致作業異常的根因,根據該根因的提示資訊,可以快速定位作業異常的原因。
如何定位Flink無法將資料寫入到結果表的問題?
當Flink無法將資料寫入到結果表時,建議從以下幾個方面進行排查並處理:
確認下遊儲存和Realtime ComputeFlink版之間網路是否連通。
Realtime ComputeFlink版僅支援訪問相同地區、相同VPC下的儲存。如果您有訪問跨VPC儲存資源或者通過公網訪問Realtime ComputeFlink版的特殊需求,請查看以下文檔:
如果您需要跨VPC訪問儲存資源,則可以通過5種方式解決,詳情請參見如何訪問跨VPC的其他服務?。
如果您需要通過公網訪問Realtime ComputeFlink版,則可以使用阿里雲提供的NAT Gateway實現VPC網路和公網的連通。詳情請參見Realtime ComputeFlink版如何訪問公網?
確認下遊儲存中是否已配置了白名單。
下遊儲存中需要配置白名單的產品包括RDS MySQL、Kafka、ES、雲原生資料倉儲AnalyticDB MySQL版3.0、HBase、Redis和ClickHouse。您可以按照以下步驟配置白名單:
擷取Realtime ComputeFlink版虛擬交換器的網段。
擷取方法請參見設定白名單。
在下遊儲存中配置Realtime ComputeFlink版白名單。
下遊儲存中配置白名單的方法,請參見對應DDL文檔的前提條件中的文檔連結,例如RDS MySQL結果表前提條件。
確認DDL中定義的欄位類型、欄位順序和欄位大小寫是否和物理表一致。
為了確保一致性,您可以按照物理表的欄位類型和順序,以及使用相同的大小寫規範來編寫DDL。下遊儲存支援的欄位類型和Realtime ComputeFlink版支援的欄位類型可能不完全一致,但存在一定的映射關係。您需要按照DDL定義的欄位類型映射關係一對一匹配,詳情請參見對應DDL文件類型映射,例如Log ServiceSLS結果表類型映射。
確認資料是否被中間節點過濾了,例如WHERE、JOIN和視窗等。
具體請查看Vertex拓撲圖上每個計算節點資料輸入和輸出情況。例如WHERE節點輸入為5,輸出為0,則代表被WHERE節點過濾了,因此下遊儲存中無資料寫入。
確認下遊儲存中設定的輸出條件相關參數的預設值是否合適。
如果您的資料來源的資料量較小,但結果表DDL定製中設定的輸出條件的預設值較大,會導致一直達不到輸出條件,而無法下發資料至下遊儲存。此時,您需要將輸出條件相關參數的預設值改小。常見的下遊儲存中的輸出條件參數情況如下表所示。
輸出條件
參數
涉及的下遊儲存
一次批量寫入的條數。
batchSize
每次批量寫入資料的最巨量資料條數。
batchCount
Odps tunnel writer緩衝區Flush間隔。
flushIntervalMs
寫入HBase前,記憶體中緩衝的資料量(位元組)大小。
sink.buffer-flush.max-size
寫入HBase前,記憶體中緩衝的資料條數。
sink.buffer-flush.max-rows
將快取資料周期性寫入到HBase的間隔,可以控制寫入HBase的延遲。
sink.buffer-flush.interval
Hologres Sink節點資料攢批的最大值。
jdbcWriteBatchSize
確認視窗是否因為亂序而導致資料無法輸出。
假如,Realtime ComputeFlink版一開始就流入一條2100年的未來資料,它的Watermark為2100年,系統會預設2100年前的資料已被處理完,只會處理比2100年大的資料。而後續流入的2021年的正常資料因為Watermark小於2100年而被丟棄。直到出現大於2100年的資料流入Realtime ComputeFlink版,則會觸發視窗關閉而輸出資料,否則就會導致結果表一直沒有資料輸出。
您可以通過Print Sink或者Log4j的方式確認資料來源中是否存在亂序的資料,詳情請參見print結果表和配置作業日誌輸出。找到亂序資料後,您可以過濾或者採取延遲觸發視窗計算的方式處理亂序的資料。
確認是否因為個別並發沒有資料而導致資料無法輸出。
如果作業為多並發,但個別並發沒有資料流入Realtime ComputeFlink版,則它的Watermark就為1970年0點0分,而多個並發的Watermark取最小值,因此就永遠沒有滿足視窗結束的Watermark,無法觸發視窗結束而輸出資料。
此時,您需要檢查您上遊的Vertex拓撲圖的Subtask每個並發是不是都有資料流入。如果有個別並發無資料,建議調整作業並發數小於等於源表Shard數,從而保證所有並發都有資料。
確認Kafka的某個分區是否無資料,從而導致資料無法輸出。
如果Kafka某個分區沒有資料,則會影響Watermark的產生,從而導致Kafka源表資料基於Event Time的視窗後,不能輸出資料。解決方案請參見為什麼Kafka源表資料基於Event Time的視窗後,不能輸出資料?。
如何定位元據丟失的問題?
資料經過JOIN、WHERE或視窗等節點時,資料量減少是正常現象,這是因條件限制被過濾或JOIN不上。但如果您的資料丟失異常,建議從以下幾個方面進行排查並處理:
確認維表Cache緩衝策略是否有問題。
如果維表DDL中Cache緩衝原則設定的有問題,則會導致維表的資料沒有被拉取到,從而導致資料丟失。此時建議檢查並修改作業Cache策略。作業Cache策略詳情請參見各維表的Cache策略,例如HBase維表Cache參數。
確認函數使用方法是否不正確。
如果您在作業中使用了to_timestamp_tz、date_format等函數,而函數的使用方法不正確,導致資料轉換出問題,資料被丟失。
此時,您可以通過Print Sink或者Log4j的方式,單獨將使用的函數的資訊列印到日誌中,確認函數的使用方法是否正確。詳情請參見print結果表或配置作業日誌輸出。
確認資料是否亂序。
如果作業中存在亂序的資料,這些亂序的資料的Watermark不在新視窗的開窗和關窗時間範圍內,導致這些資料被丟棄。例如下圖中11秒的資料在16秒進入15~20秒的視窗,而它的Watermark為11,會被系統認為是遲到資料,從而導致被丟棄。
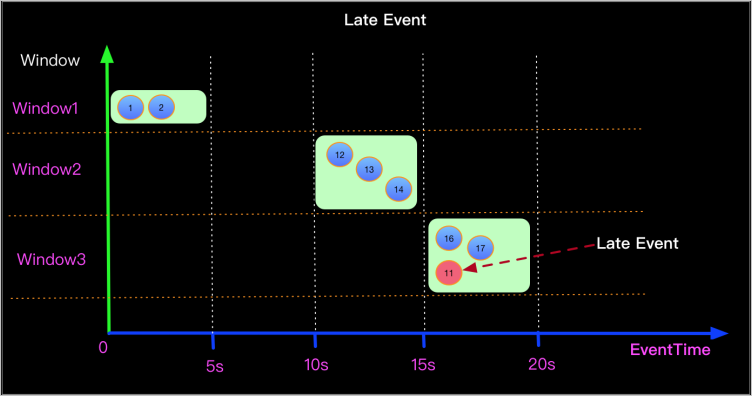
通常丟失的資料都是一個視窗的,您可以通過Print Sink或者Log4j的方式確認資料來源中是否存在亂序的資料。詳情請參見print結果表或配置作業日誌輸出。
找到亂序資料後,可以根據亂序的程度,合理地設定Watermark,採取延遲觸發視窗計算的方式處理亂序的資料。例如該樣本中,可以定義Watermark建置原則為Watermark = Event time -5s,從而讓亂序的資料可以被正確地處理。建議以整天整時整分開視窗求彙總,否則資料亂序嚴重,增加offset後還是會有資料丟失問題。
CDC模式消費Hologres時row_number去重結果異常
異常結果
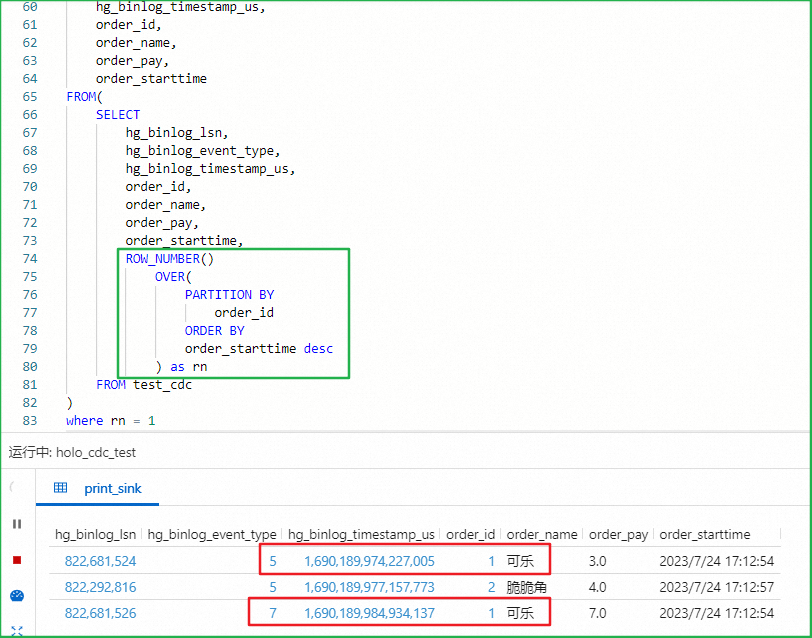
異常原因
在CDC模式下,如果下遊包含回撤運算元(例如使用ROW_NUMBER OVER WINDOW去重),就需要設定Hologres源表WITH參數中upsertSource為true,此時源表會以Upsert方式從Hologres中讀取資料。
解決方案
在Hologres源表WITH參數中添加配置
'upsertSource' = 'true',可以避免資料重複。
作業資料不準確,該如何排查?
調整記錄層級
將作業的記錄層級調至INFO,確保能夠捕獲列印的日誌資訊。詳情請參見修改運行作業記錄層級。
開啟運算元探查功能
可以在不修改作業的情況下看到中間結果的輸出,操作詳情請參見運算元探查(公測)。
分析作業記錄
在狀態總覽頁簽的DAG圖中複製運算元名稱,在日誌列表中Log Name為inspect-taskmanager_0.out的頁面搜尋查看具體運算元的輸出。
最佳化與驗證
根據日誌定位問題後,修複異常運算元的邏輯,重新提交作業並驗證資料準確性。
報錯:doesn't support consuming update and delete changes which is produced by node TableSourceScan
報錯詳情
Table sink 'vvp.default.***' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[vvp, default, ***]], fields=[id,b, content]) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:286) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:741) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834)報錯原因
Append類型Sink無法接收上遊update記錄。
解決方案
使用支援寫入update記錄的Sink,例如Upsert Kafka等。詳情請參見Upsert Kafka結果表。
Lindorm Connector預設啟用的upsert materialize運算元因毫秒級時間戳記精度導致資料被覆蓋或錯誤刪除,如何解決?
問題背景
預設情況下,Lindorm Connector在寫入資料前會自動啟用 upsert materialize 運算元(預設值:AUTO)。該運算元可能產生相同主鍵下的 DELETE + INSERT 組合操作記錄。由於Lindorm以毫秒級時間戳記(Timestamp)管理資料版本,若同一主鍵的資料在同一毫秒內被多次寫入,系統將無法區分寫入順序,從而可能導致資料意外覆蓋或錯誤刪除。
技術原理
時間戳記精度限制:Lindorm以毫秒為粒度管理資料版本。若同一主鍵的多條記錄在同一毫秒內寫入,系統無法區分寫入順序,可能引發版本衝突。
寫入語義差異:Lindorm僅支援
UPSERT語義(覆蓋寫入),而缺乏對完整的CHANGELOG語義(如DELETE標記的精確復原)的支援。因此,upsert materialize運算元的保序邏輯在Lindorm情境下無實際意義,反而可能因DELETE + INSERT組合操作引發資料異常。
風險影響
同一毫秒內的並發寫入可能觸發非預期的 DELETE + INSERT 邏輯,造成資料丟失或狀態錯誤。
解決方案
建議顯式關閉 upsert materialize 運算元,以規避潛在風險。
適用情境:所有通過Flink寫入Lindorm的任務。
生效方式:可在作業運行參數或SQL語句中全域設定,通過以下配置實現:
SET 'table.exec.sink.upsert-materialize' = 'NONE';注意事項:關閉後需確保商務邏輯能容忍最終一致性(如通過唯一主鍵保證資料等冪性)。