當您需要將Azure Event Hubs事件中心中的資料同步到Elasticsearch中時,可使用阿里雲Logstash的管道配置功能實現。本文介紹具體的實現方法。
操作流程
步驟一:準備環境與執行個體
- 建立Elasticsearch執行個體,並開啟自動建立索引功能。本文使用7.10版本的執行個體。
具體操作請參見建立Elasticsearch執行個體和配置YML參數。
- 建立阿里雲Logstash執行個體並配置NAT公網資料轉送。本文使用7.4版本的執行個體。
具體操作請參見建立阿里雲Logstash執行個體。由於阿里雲Logstash執行個體部署在Virtual Private Cloud下,但在資料同步過程中,Logstash需要串連公網才能與Azure Event Hubs事件中心互連,因此需要通過配置NAT Gateway實現與公網連通,詳情請參見配置NAT公網資料轉送。說明 對於自建的Logstash,需要購買與Elasticsearch在同一VPC下的ECS執行個體(已合格ECS不需要重複購買,需要綁定Elastic IP Address)。
- 準備Azure Event Hubs事件中心的自建環境。
具體操作請參見Azure Event Hubs官方文檔。
步驟二:建立並配置Logstash管道
進入目標執行個體。
在頂部功能表列處,選擇地區。
在LogStash執行個體中單擊目標執行個體ID。
-
在左側導覽列,單擊管道管理。
-
單擊建立管道。
- 在建立管道任務頁面,輸入管道ID並配置管道。
本文使用的管道配置如下。
input { azure_event_hubs { event_hub_connections => ["Endpoint=sb://abc-****.****.cn/;SharedAccessKeyName=gem-****-es-consumer;SharedAccessKey=******;EntityPath=xxxxxx"] initial_position => "beginning" threads => 2 decorate_events => true consumer_group => "group-kl" storage_connection => "DefaultEndpointsProtocol=https;AccountName=xxxxx;AccountKey=*******;EndpointSuffix=core.****.cn" storage_container => "lettie_container" } } filter { } output { elasticsearch { hosts => ["es-cn-tl****5r50005adob.elasticsearch.aliyuncs.com:9200"] index => "test-log" password => "xxxxxx" user => "elastic" } }表 1. input參數說明 參數 說明 event_hub_connections 標識要讀取的事件中心的連接字串列表。連接字串包括事件中心的EntityPath。更多詳細說明,請參見event_hub_connections。 說明 每一個事件中心都會定義一個event_hub_connections參數,其他參數在各事件中心之間共用。initial_position 從事件中心讀取資料的位置,可選值:beginning(預設)、end和look_back。更多詳細說明,請參見initial position 。 threads 處理事件的線程總數。更多詳細說明,請參見threads。 decorate_events 是否同步事件中心的中繼資料,包括事件中心名稱、consumer_group、processor_host、分區、位移量、序列、時間戳記和event_size。更多詳細說明,請參見decorate events。 consumer_group 用於讀取事件中心資料的消費者組。您需要專門為Logstash建立一個消費者組,並確保Logstash的所有節點都使用該消費者組,以便它們可以正常協同工作。更多詳細說明,請參見consumer group。 storage_connection Blob賬戶儲存的連接字串。Blob賬戶儲存會保留重啟之間的位移量,並確保Logstash的多個節點處理不同的分區。設定此值後,重啟將在處理中斷的地方開始。如果未設定此值,重啟將從initial_position設定的值的地方開始。更多詳細說明,請參見storage connection。 storage_container 用於持久儲存位移量並允許多個Logstash節點一起工作的儲存容器的名稱。更多詳細說明,請參見storage container。 說明 為避免覆蓋位移量,建議使用不同的storage_container名稱。如果同一份資料分別寫入到不同的服務中,此參數需設定為不同的名稱。表 2. output參數說明 參數 說明 hosts Elasticsearch服務的訪問地址,需要設定為 http://<Elasticsearch執行個體ID>.elasticsearch.aliyuncs.com:9200。index 遷移後的索引名。 user 訪問Elasticsearch服務的使用者名稱,預設為elastic。 password 對應使用者的密碼。對於Elasticsearch,elastic使用者的密碼在建立執行個體時設定,如果忘記可進行重設,重設密碼的注意事項和操作步驟請參見重設執行個體訪問密碼。 更多Config配置詳情請參見Logstash設定檔說明。
-
單擊下一步,配置管道參數。

參數
說明
Pipeline Workers
並存執行管道的Filter和Output的背景工作執行緒數量。當事件出現積壓或CPU未飽和時,請考慮增大線程數,更好地使用CPU處理能力。預設值:執行個體的CPU核心數。
Pipeline Batch Size
單個背景工作執行緒在嘗試執行Filter和Output前,可以從Input收集的最大事件數目。較大的管道批大小可能會帶來較大的記憶體開銷。您可以設定LS_HEAP_SIZE變數,來增大JVM堆大小,從而有效使用該值。預設值:125。
Pipeline Batch Delay
建立管道事件批時,將過小的批指派給管道背景工作執行緒之前,要等候每個事件的時間長度,單位為毫秒。預設值:50ms。
Queue Type
用於事件緩衝的內部排隊模型。可選值:
-
MEMORY:預設值。基於記憶體的傳統隊列。
-
PERSISTED:基於磁碟的ACKed隊列(持久隊列)。
Queue Max Bytes
隊列允許儲存的最巨量資料量,單位為
MB。取值範圍為:1~253-1的整數,預設值為1024MB。說明請確保該值小於您的磁碟總容量。
Queue Checkpoint Writes
啟用持久性隊列時,在強制執行檢查點之前已寫入事件的最大數目。設定為0,表示無限制。預設值:1024。
警告配置完成後,需要儲存並部署才會生效。儲存並部署操作會觸發執行個體重啟,請在不影響業務的前提下,繼續執行以下步驟。
-
-
單擊保存或者儲存並部署。
-
保存:將管道資訊儲存在Logstash裡並觸發執行個體變更,配置不會生效。儲存後,系統會返回管道管理頁面。可在管道列表地區,單擊操作列下的立即部署,觸發執行個體重啟,使配置生效。
-
儲存並部署:儲存並且部署後,會觸發執行個體重啟,使配置生效。
-
步驟三:驗證結果
登入目標Elasticsearch執行個體的Kibana控制台,根據頁面提示進入Kibana首頁。
登入Kibana控制台的具體操作,請參見登入Kibana控制台。
說明本文以Elasticsearch 7.10.0版本為例,其他版本操作可能略有差別,請以實際介面為準。
單擊右上方的Dev tools。
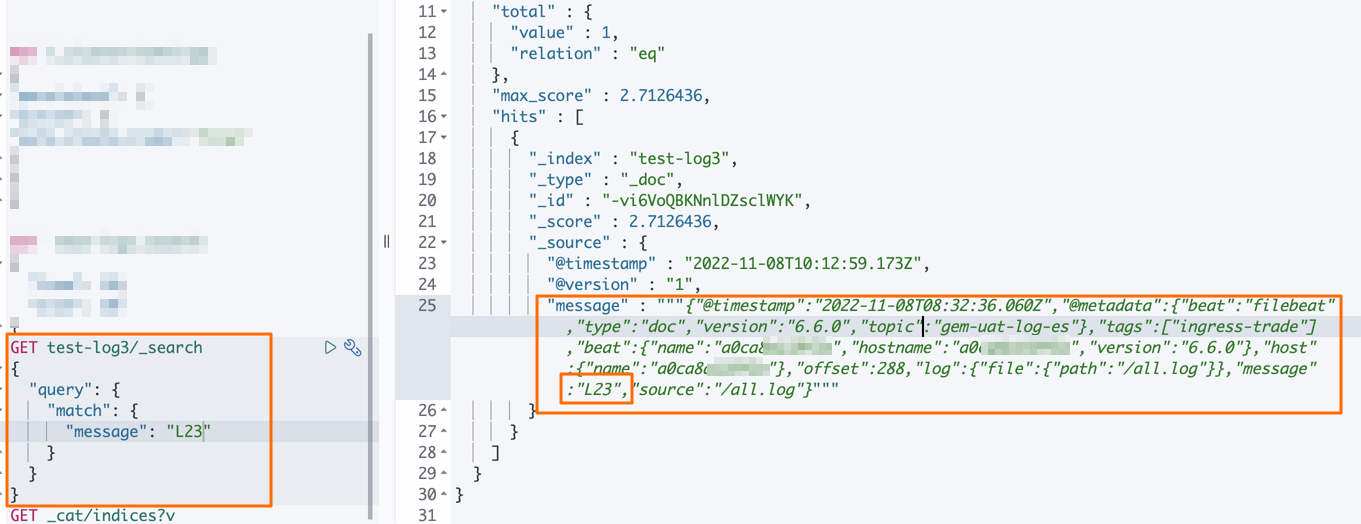
- 在Console中,執行如下命令,查看同步後資料。
GET test-log3/_search { "query":{ "match":{ "message":"L23" } } }預期結果如下。