Elasticsearch機器學習是一種利用機器學習技術對Elasticsearch資料進行智能檢測和預測的工具,可以自動識別資料模式和資料異常,產生新的特徵和彙總結果,為資料分析和應用提供支援。Elasticsearch機器學習可以提高資料的可用性和價值,還可以為使用者提供更加智能和高效的資料分析和應用解決方案。本文通過兩個樣本介紹無監督機器學習和監督機器學習的實踐。
背景資訊
Elasticsearch機器學習分為無監督機器學習Unsupervised和監督機器學習Supervised兩類:
無監督機器學習包括Single metric和Populartion等情境,對資料進行異常檢測。該模式不需要訓練機器學習什麼是異常,機器學習演算法將自動檢測資料中的異常或異常模式。
監督機器學習包括Regression和Classification等情境,使用分類和迴歸演算法解決非常複雜的問題。該模式需要一定的資料訓練預測任務,然後使用訓練出來的任務來對未來的資料進行分類、預測。
情境大類 | 情境 | 類別 | 說明 |
異常檢測Anomaly Detection | 單一指標檢測Single metric | unsupervised | 檢測單個時序中的異常,資料分析僅在一個索引欄位上執行。 |
多指標檢測Mutil metric | unsupervised | 使用一個或多個指標檢測異常,並根據需要拆分分析,資料分析在多個索引欄位上執行。 | |
填充Populartion | unsupervised | 通過與Population中的行為進行比較,檢測不尋常的行為。 Population是指某一研究領域內所有可能被研究的個體、事物或現象的總體。 | |
進階用法和功能 Advanced | unsupervised | 提供了更多的選項和設定,以便使用者可以更好地定製和最佳化機器學習任務,以適應不同的應用情境和資料類型,用於更進階用例的機器學習。 | |
歸類Categorization | unsupervised | 識別和分析日誌訊息中的特徵和模式,將日誌訊息分為不同的組別,並檢測其中的異常情況。 | |
資料分析Data Frame Analytics | 離群值檢測Outlier detection | unsupervised | 用群集和異常檢測演算法訓練任務,用於快速檢測資料中的異常點或異常行為。 |
迴歸Regression | supervised | 迴歸預測資料集中的數值。 | |
分類Classification | supervised | 分類預測資料集中資料點的類別。 |
準備工作
建立Elasticsearch執行個體,本文使用8.5版本Elasticsearch執行個體。具體操作,請參見建立Elasticsearch執行個體。
說明不同版本Elasticsearch機器學習的使用可能存在差異性。更多資訊,請參見Machine learning官方文檔。
登入Kibana控制台。具體操作,請參見登入Kibana控制台。
添加範例資料。
在Kibana首頁,通過添加整合開始使用地區單擊試用範例資料。
在範例資料頁簽,單擊其他範例資料集。
分別單擊Sample flight data和Sample web logs資料集下的添加資料。
待添加資料變為查看資料時,表示該資料集已添加完成。添加範例資料後,Kibana會自動建立kibana_sample_data_flights索引和kibana_sample_data_logs索引。
建立機器學習任務
本文通過以下兩個樣本介紹無監督機器學習和監督機器學習的實踐。
建立單指標機器學習任務
本操作通過單指標檢測構建一個無監督機器學習任務,使用Kibana內建的範例資料Sample web logs,該資料集為訪問Web伺服器的類比資料,通過分析範例資料瞭解使用者的訪問行為、最佳化網站效能和檢測異常訪問等。
下面是資料集Sample web logs中的一條資料資訊。
{
"_index": "kibana_sample_data_logs",
"_type": "_doc",
"_id": "n6GHI4gBmNQSVxOwNnPn",
"_version": 1,
"_score": null,
"_source": {
"agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24",
"bytes": 847,
"clientip": "122.62.233.59",
"extension": "",
"geo": {
"srcdest": "CN:CO",
"src": "CN",
"dest": "CO",
"coordinates": {
"lat": 31.24905556,
"lon": -82.39530556
}
},
"host": "www.elastic.co",
"index": "kibana_sample_data_logs",
"ip": "122.62.233.59",
"machine": {
"ram": 4294967296,
"os": "win xp"
},
"memory": null,
"message": "122.62.233.59 - - [2018-08-21T02:34:54.901Z] \"GET /logging HTTP/1.1\" 200 847 \"-\" \"Mozilla/5.0 (X11; Linux i686) AppleWebKit/534.24 (KHTML, like Gecko) Chrome/11.0.696.50 Safari/534.24\"",
"phpmemory": null,
"referer": "http://twitter.com/success/paul-w-richards",
"request": "/logging",
"response": 200,
"tags": [
"success",
"info"
],
"timestamp": "2023-06-06T02:34:54.901Z",
"url": "https://www.elastic.co/solutions/logging",
"utc_time": "2023-06-06T02:34:54.901Z",
"event": {
"dataset": "sample_web_logs"
}
},
"fields": {
"@timestamp": [
"2023-06-06T02:34:54.901Z"
],
"utc_time": [
"2023-06-06T02:34:54.901Z"
],
"hour_of_day": [
2
],
"timestamp": [
"2023-06-06T02:34:54.901Z"
]
},
"sort": [
1686018894901
]
}您還可以通過Transforms對匯入的資料進行彙總,將未經處理資料彙總為更進階別的指標或統計資料,並將彙總結果儲存到新的索引中,提高查詢效能和回應時間,並為後續的分析和機器學習提供基礎資料。
單擊Kibana頁面左上方的
 表徵圖,選擇Kibana > Machine Learning。
表徵圖,選擇Kibana > Machine Learning。在左側功能表列,單擊。
在異常檢測作業頁面,單擊建立作業。
選擇kibana_sample_data_logs索引。
在從 資料檢視 Kibana Sample Data Logs 建立作業頁面的使用嚮導地區,單擊單一指標,建立單指標任務。
配置單指標任務。
時間範圍選擇使用完整的資料,單擊下一步。
說明範例資料集裡資料較少,所以選擇使用完整的kibana_sample_data_logs資料。
選取欄位Count(Event rate),配置儲存桶跨度和稀疏資料後,單擊下一步。
說明Count(Event rate) 作為單指標視圖的指標可以很好地反映出伺服器在每秒內響應請求的次數,可以作為異常檢測的目標。
儲存桶跨度:用於將時間序列資料分成不同的塊,以便進行分析和預測。該參數定義了每個時間段的期間,您可以根據業務需求進行調整。
稀疏資料:選擇是否將欄位中的空值視為異常。在機器學習中,資料的稀疏性是指資料中存在大量的空值(缺失值)。
輸入作業ID和作業描述,單擊下一步。
時間範圍和任務記憶體限制的驗證沒問題後,單擊下一步。
在頁面底部,單擊建立作業。
Elasticsearch按照時序播放這些資料,並對資料進行分析學習建立任務,同時對後面的資料進行評估。
說明建立作業需要時間進行驗證,花費的時間受索引資料的大小影響。
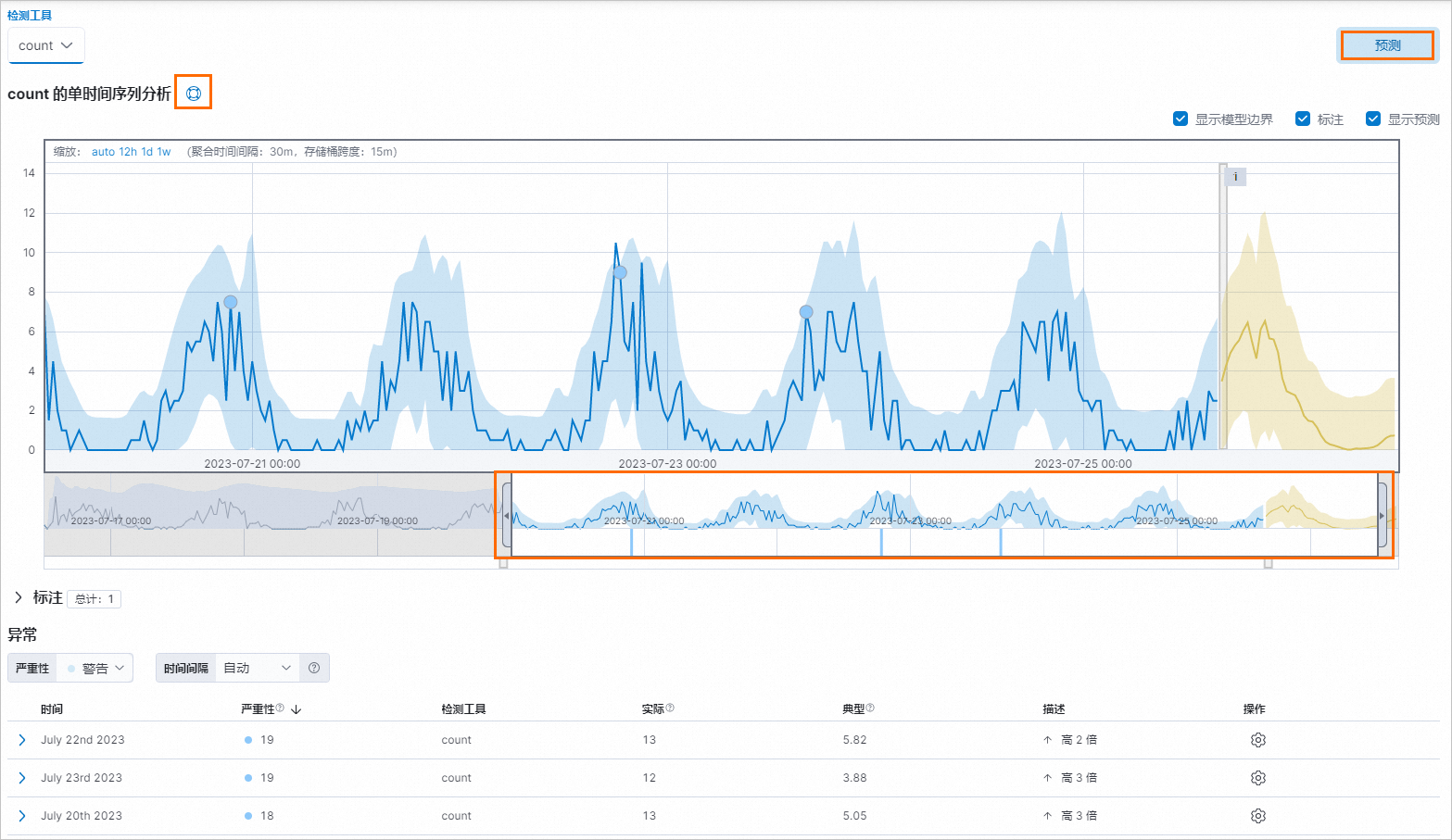
作業建立完成後,在頁面左下角單擊查看結果。
單擊count 的單時間序列分析右側的
 表徵圖,查看單時間序列分析說明。
表徵圖,查看單時間序列分析說明。用滑鼠左鍵拖動時間控制條的左右邊緣或移動時間控制條,選擇需要進行異常檢測的時間段。
在頁面右側單擊預測,對未來進行預測。
建立推理機器學習任務
訓練航班延誤預測任務
本操作通過迴歸演算法訓練一個監督機器學習任務,使用Kibana內建的範例資料Sample flight data,該資料集為虛構的航班資料,通過迴歸演算法根據歷史資料訓練航班延誤時間的任務。預測任務可以為航空公司和旅客提供重要的參考資訊,協助旅客更好地規划行程和航班安排。
下面是Sample flight data資料集中的一條資料資訊。
{
"_index": "kibana_sample_data_flights",
"_type": "_doc",
"_id": "7b0aeogBmNQSVxOwslB_",
"_version": 1,
"_score": null,
"_source": {
"FlightNum": "QYX9S3I",
"DestCountry": "CH",
"OriginWeather": "Cloudy",
"OriginCityName": "Chicago",
"AvgTicketPrice": 824.8516378170061,
"DistanceMiles": 4442.909325899777,
"FlightDelay": false,
"DestWeather": "Thunder & Lightning",
"Dest": "Zurich Airport",
"FlightDelayType": "No Delay",
"OriginCountry": "US",
"dayOfWeek": 4,
"DistanceKilometers": 7150.1694661808515,
"timestamp": "2023-06-02T07:28:15",
"DestLocation": {
"lat": "47.464699",
"lon": "8.54917"
},
"DestAirportID": "ZRH",
"Carrier": "Logstash Airways",
"Cancelled": false,
"FlightTimeMin": 420.59820389299125,
"Origin": "Chicago O'Hare International Airport",
"OriginLocation": {
"lat": "41.97859955",
"lon": "-87.90480042"
},
"DestRegion": "CH-ZH",
"OriginAirportID": "ORD",
"OriginRegion": "US-IL",
"DestCityName": "Zurich",
"FlightTimeHour": 7.009970064883188,
"FlightDelayMin": 0
}
}單擊Kibana頁面左上方的
 表徵圖,選擇Kibana>Machine Learning。
表徵圖,選擇Kibana>Machine Learning。在左側功能表列,單擊。
在資料幀分析作業頁面,單擊建立作業。
選擇kibana_sample_data_flights索引。
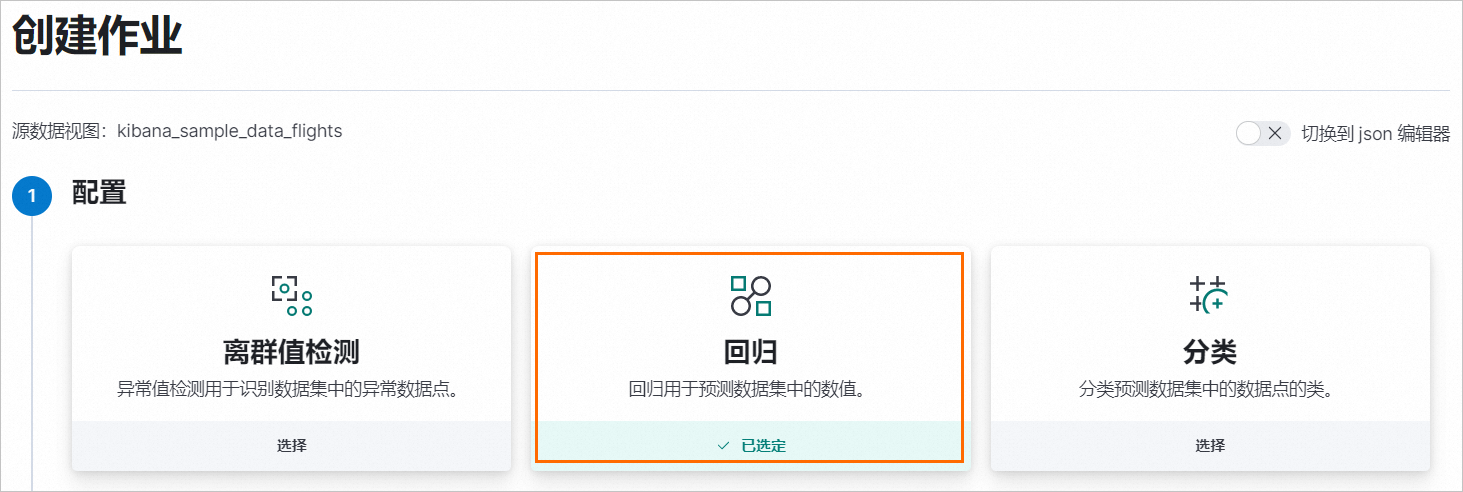
在建立作業的配置地區,配置作業基本參數。
選中迴歸任務。
因變數選擇FlightDelayMin,因變數即要預測的目標變數。
在已包括欄位中,取消選中Cancelled、FlightDelay和FlightDelayType欄位。
Cancelled、FlightDelay和FlightDelayType欄位對預測航班延誤時間沒有影響,排除多餘欄位可避免任務受到不必要的影響,提升預測準確性。
拖動圓點,調整訓練百分比。
您可以根據業務實際情況,調整參加訓練的資料量百分比,本文設定訓練百分比為90%。
說明如果資料量比較大,還需要考慮訓練的時間問題,訓練時間會隨著資料量的增加而增加。資料量比較大時建議選擇較小的比例進行訓練,例如50%或者更低的比例,然後不斷地進行矯正,直到得到合適的正確率。
單擊繼續,配置其他選項。
設定功能重要性值為5。計算5個對於預測結果重要的特徵,以便我們瞭解哪些特徵對於預測結果的貢獻最大,有助於進行特徵選取和任務最佳化。
設定預測欄位名稱為FlightDelayMin_prediction。指定要預測的目標變數的名稱。
取消選中使用估計的模型記憶體限制,設定模型記憶體限制為500MB。指定機器學習任務可以使用的記憶體上限。如果資料集比較大,任務較為複雜,可能會消耗大量記憶體,如果超出了限制,可能會導致任務訓練失敗或者效能下降,因此需要根據資料集的大小和任務的複雜度來設定適當的記憶體上限。
設定最大線程數為1。用於指定訓練任務的最大線程數,如果設定的線程數過多,可能會導致記憶體不足或者系統崩潰。
單擊繼續,設定作業ID為flightdelaymin_job。
單擊繼續,自動對任務進行驗證。
驗證通過後,單擊繼續。
在建立地區,單擊建立,建立任務。
產生任務需要時間,具體耗時由訓練的資料量大小決定。
任務建立完畢後,單擊查看結果,查看分析作業的結果。
在模型評估地區,查看任務的可靠性。
泛化誤差:衡量任務在新資料上表現的能力,反映了任務的泛化能力。泛化誤差越小,表示任務具有更好的泛化能力,能夠更準確地對未知資料進行預測。
訓練誤差:指任務在訓練資料集上的表現能力,反映了任務在學習過程中所做的誤差。訓練誤差越小,表示任務在訓練資料集上的表現越好。
評估指標說明:
均方誤差:評估迴歸任務效能的重要指標,數值越小表示任務的預測結果越精確。通過計算真實值與迴歸任務預測值之間的差值的平均平方和獲得。
R平方:評估迴歸任務效能的重要指標,數值越接近1表示任務的擬合程度越好。一般認為超過0.8的任務擬合優度比較高。
均方根對數誤差:數值越小,表示任務的預測效果越好。通過對預測值和真實值取對數後計算誤差平方和的平均值獲得。
說明比較多個迴歸任務時,需要同時考慮均方誤差和R平方,以找到最佳平衡任務或適合特定資料集的任務。
均方誤差為0或R平方值為1通常是不可能的,因為任務的預測結果受到多種因素的影響,而這些因素無法全部考慮到並完全消除誤差。
均方根對數誤差為NaN表示任務預測的結果或真實結果存在非正數或零的情況。
更多詳細資料請參見迴歸評估。
使用航班延誤預測任務
通過Kibana中的推理處理器使用上面訓練的航班延誤預測任務。
單擊Kibana頁面左上方的
表徵圖,選擇Management > 開發工具。在Kibana控制台中,執行以下命令查看並記錄model_id值。
GET _ml/inference/flightdelaymin_job*?human=true此命令表示查詢名為flightdelaymin_job的所有推理分析結果,並將結果以人類可讀的格式進行輸出。命令中flightdelaymin_job為建立迴歸推理任務中定義的作業ID。
基於上面建立的迴歸推理任務,建立一個基於推理處理器的pipeline管道。
說明將代碼中的model_id值替換為您擷取到的model_id值。
PUT _ingest/pipeline/flight_flightDelayMin_predict { "description": "Predict the number of minutes of delay for each flight", "processors": [ { "inference": { "model_id": "flightDelayMin_job-168609891****", "inference_config": { "regression": {} }, "field_map": {}, "tag": "flightDelayMin_prediction" } } ] }使用kibana_sample_data_flights索引中的資料,以航班延誤時間FlightDelayMin為目標變數,進行資料分析和預測。
POST _ingest/pipeline/flight_flightDelayMin_predict/_simulate { "docs": [ { "_source": { "FlightNum": "EDGSV3T", "DestCountry": "CN", "OriginWeather": "Damaging Wind", "OriginCityName": "Durban", "AvgTicketPrice": 1065.7037805199147, "DistanceMiles": 7273.460817641552, "FlightDelay": true, "DestWeather": "Rain", "Dest": "Shanghai Pudong International Airport", "FlightDelayType": "Carrier Delay", "OriginCountry": "ZA", "dayOfWeek": 5, "DistanceKilometers": 11705.500526106527, "timestamp": "2023-06-03T09:34:00", "DestLocation": { "lat": "31.14340019", "lon": "121.8050003" }, "DestAirportID": "PVG", "Carrier": "Kibana Airlines", "Cancelled": false, "FlightTimeMin": 881.1071804361806, "Origin": "King Shaka International Airport", "OriginLocation": { "lat": "-29.61444444", "lon": "31.11972222" }, "DestRegion": "SE-BD", "OriginAirportID": "DUR", "OriginRegion": "SE-BD", "DestCityName": "Shanghai", "FlightTimeHour": 14.685119673936343, "FlightDelayMin": 45 } } ] }得到的結果,如圖所示。
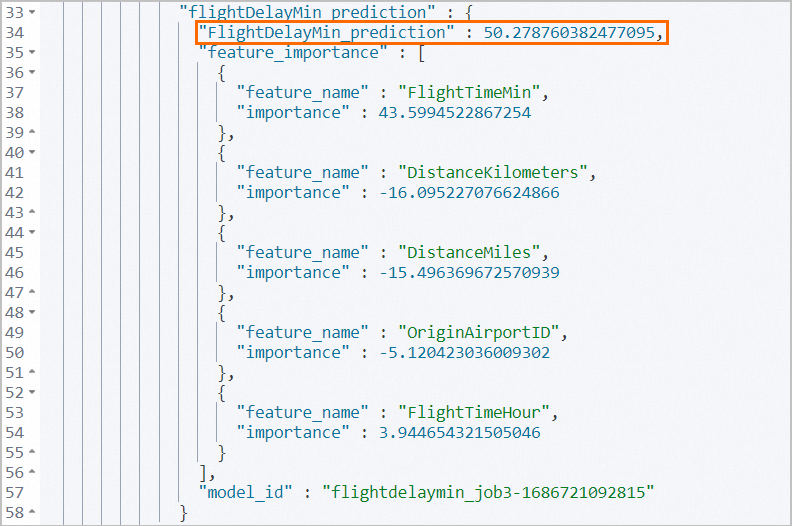
實際的航班延誤時間FlightDelayMin為45min,預測得到的航班延誤時間FlightDelayMin_prediction為50.28min,與實際相差不大。
feature_importance裡顯示了對估算航班延誤時間貢獻最大的5個影響因素:FlightTimeMin,DistanceKilometers,DistanceMiles,OriginAirportID和FlightTimeHour。您可以通過調整5個影響因素的值來調整任務預測結果,從而更為精確地估計未來每個航班的延誤時間。