通過StarRocks非同步物化視圖進行資料建模,能夠通過聲明式的建模語言,簡化流水線的管理,提升資料建模的效率與靈活性。本文為您介紹如何使用StarRocks的非同步物化視圖來進行資料建模。
背景介紹
資料建模是通過合理的方法進行資料清洗、分層、彙總和關聯的過程。當未經處理資料品質過低,指標過多過於複雜,或未經彙總導致查詢成本過高時,您可以通過對未經處理資料進行建模得到易於理解的、可供使用的資料結果。
然而,在現實資料建模中常見的矛盾在於建模過程難以跟上業務發展的步伐,並且很難衡量資料建模工作的投資回報。建模手段雖然簡單,但需要業務專家在資料群組織和治理方面有紮實的背景,對資料整理加工,這是個複雜的過程。在業務的早期階段,決策者通常不會在資料建模方面投入足夠資源,並且很難看到資料建模能夠帶來的價值。此外,由於業務模式可能會迅速變化,而建模方法本身也需要不斷迭代和演化。因此,許多資料分析師傾向於不使用資料建模,直接使用未經處理資料,從而不可避免地導致資料品質和查詢效能的問題。當建模的需求出現時,又遇到資料使用方式已經成型,難以重構的問題。
使用StarRocks物化視圖進行資料建模可以有效解決以上問題。StarRocks非同步物化視圖具備以下能力:
簡化數倉架構:由於StarRocks可以提供一站式資料治理體驗,您無需維護其他資料處理系統或組件,節省了用於維護這些系統的人力和實體資源。
簡化建模體驗:任何只具備基本SQL知識的資料分析師都可以使用StarRocks進行資料建模,無需專業資料工程師。
簡化系統維護:StarRocks的非同步物化視圖可以自動管理資料之間的層級和依賴關係,無需整個資料平台來處理此任務。
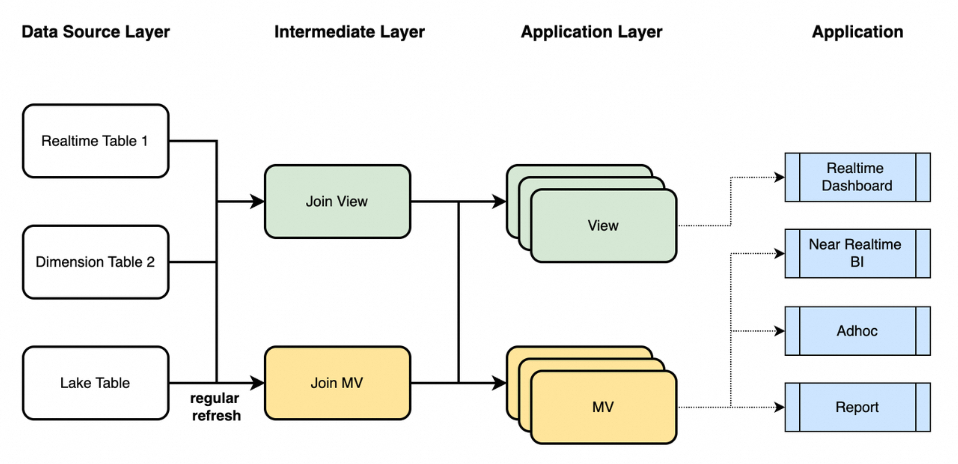
在實際情況中,您可以通過結合使用StarRocks的邏輯視圖和非同步物化視圖來進行資料建模,如下所示:
使用視圖將即時資料與維度資料關聯,並使用物化視圖將資料湖中的歷史資料與維度資料關聯。同時進行必要的資料清洗和業務語義映射,以得到反映業務語義詳細資料的中介層(Intermediate Layer)。
在應用程式層(Application Layer)中,面向不同的業務情境,進行資料的Join、Agg、Union、Window計算,產生用於即時鏈路的視圖和用於近即時鏈路的物化視圖。
在應用側(Application),根據您的時效性和效能要求選擇適當的分析資料儲存(ADS)進行查詢分析,服務於即時大屏、近即時BI、Ad hoc查詢和定時報告等需求。
非同步物化視圖的能力
StarRocks的非同步物化視圖具備以下原子能力,可助力資料建模:
自動重新整理:在資料匯入至基表後,物化視圖可以自動重新整理。您無需在外部維護調度任務。
分區重新整理:通過有時序屬性的報表,可以通過分區重新整理實現近Realtime Compute。
與視圖協同使用:通過協同使用物化視圖和邏輯視圖,您可以實現多層建模,從而實現中介層的重複使用和資料模型的簡化。
Schema Change:您可以通過簡單的SQL語句更改計算結果,無需修改複雜的資料流水線。
藉助以上功能,您可以設計全面且靈活的資料模型,以滿足各種業務需求和情境。
自動重新整理
建立非同步物化視圖時,您可以使用REFRESH子句指定重新整理策略。目前,StarRocks非同步物化視圖支援以下重新整理策略:
自動重新整理(
REFRESH ASYNC):每當基表中的資料發生變化時,都會觸發重新整理任務。資料依賴關係由物化視圖自動管理。定時重新整理(
REFRESH ASYNC EVERY (INTERVAL <refresh_interval>)):定期觸發重新整理任務,例如,每分鐘、每天或每月。如果基表中沒有資料更改,將不會觸發重新整理任務。手動重新整理(
REFRESH MANUAL):您只能通過手動執行REFRESH MATERIALIZED VIEW觸發重新整理任務。如果您通過外部調度架構觸發重新整理任務,可以使用此重新整理策略。
文法如下。
CREATE MATERIALIZED VIEW <db_name>.<mv_name>
REFRESH
[ ASYNC |
ASYNC [START <time>] EVERY(<interval>) |
MANUAL
]
AS <query>分區重新整理
建立非同步物化視圖時,您可以使用PARTITION BY子句將基表的分區與物化視圖的分區關聯起來,從而實現分區粒度的重新整理。
PARTITION BY <column>:您可以為物化視圖引用與基表相同的分區列,從而使基表和物化視圖採用相同的分區粒度。PARTITION BY date_trunc(<column>):您可以使用date_trunc函數在基表分區列的基礎上上卷,從而為物化視圖制定不同粒度的分區策略。PARTITION BY { time_slice | date_slice }(<column>):與date_trunc相比,time_slice和date_slice提供更靈活的時間粒紋調整,允許更精細地控制時間分區粒度。
文法如下。
CREATE MATERIALIZED VIEW <db_name>.<mv_name>
REFRESH ASYNC
PARTITION BY
[
<base_table_column> |
date_trunc(<granularity>, <base_table_column>) |
time_slice(<base_table_column>, <granularity>) |
date_slice(<base_table_column>, <granularity>)
]
AS <query>與視圖協同使用
可以基於視圖建立物化視圖。此時,當視圖引用的基表發生資料更改時,物化視圖可以自動重新整理。
可以基於其他物化視圖建立物化視圖,實現多層級聯式重新整理。
可以基於物化視圖建立視圖,等同於基於常規表建立。
Schema Change
非同步物化視圖可以通過ALTER MATERIALIZED VIEW SWAP語句進行原子替換。您可以建立一個新物化視圖,並增加新列或更改列類型,然後用新物化視圖替換舊物化視圖。
視圖可以通過ALTER VIEW語句直接修改定義。
StarRocks中的常規表可以使用SWAP或ALTER操作進行修改。
基表(可以是物化視圖、視圖或常規表)發生更改時,將會觸發相應物化視圖中的級聯更改。
分層建模
在實際業務情境中,存在各種形式的資料來源,包括即時詳細資料、維度資料以及資料湖的歸檔資料。另一方面,業務需求需要多樣化的分析方法,如即時大屏、近即時BI查詢、分析師Ad hoc查詢和定時報表等。不同的情境有不同的需求,有些需要靈活性,有些優先考慮效能,而其他一些則強調成本效益。
顯然,單一解決方案無法充分滿足如此多樣化的需求。StarRocks可以通過結合使用視圖和物化視圖高效地滿足這些需求。因為視圖不維護物理資料,每次查詢檢視時,查詢會根據視圖的定義進行解析和執行。相比之下,物化視圖儲存了預計算的結果,可以避免重複執行的開銷。視圖適合表達業務語義並簡化SQL複雜性,但無法降低查詢執行的開銷。另一方面,物化視圖通過預先計算並儲存查詢結果最佳化查詢效能,適用於簡化ETL Pipeline的情境。
視圖與物化視圖的差異
對比項 | 視圖 | 物化視圖 |
使用情境 | 業務建模、資料治理 | 資料建模、透明加速、湖倉一體 |
儲存開銷 | 不儲存資料,無儲存開銷 | 儲存預計算結果,有額外儲存成本 |
更新開銷 | 無更新開銷 | 基表資料更新時,有更新開銷 |
效能收益 | 不做預計算,無效能收益 | 預計算結果,加速查詢 |
資料即時性 | 查詢檢視時返回最新資料 | 結果為預計算,可能存在資料延遲 |
依賴關係 | 基於表名引用基表,基表名變更將導致視圖失效 | 基於 ID 引用基表,基表名變更不影響物化視圖可用性。 |
建立文法 | CREATE VIEW | CREATE MATERIALIZED VIEW |
修改文法 | ALTER VIEW | ALTER MATERIALIZED VIEW |
修改視圖與基表
您可以使用以下語句來修改您的視圖、物化視圖和基表。
-- 修改基表。
ALTER TABLE <db_name>.<table_name> ADD COLUMN <column_desc>;
-- 原子替換基表。
ALTER TABLE <db_name>.<table1> SWAP WITH <table2>;
-- 修改視圖定義。
ALTER VIEW <db_name>.<view_name> AS <query>;
-- 原子替換物化視圖(替換兩個物化視圖的名字,並不修改其中資料)。
ALTER MATERIALIZED VIEW <db_name>.<mv1> SWAP WITH <mv2>;
-- 重新啟用物化視圖。
ALTER MATERIALIZED VIEW <db_name>.<mv_name> ACTIVE;Schema Change遵循以下原則:
表的重新命名以及原子替換操作將導致依賴其的物化視圖變為Inactive狀態。對於Schema Change操作,僅當物化視圖依賴的基表列發生Schema Change時,才會導致物化視圖變為Inactive狀態。
視圖的定義變更將導致依賴其的物化視圖變為Inactive狀態。
物化視圖的原子替換操作將導致依賴其的嵌套物化視圖變為Inactive狀態。
Inactive狀態會級聯向上傳播,直到沒有物化視圖依賴關係為止。
Inactive狀態的物化視圖無法重新整理或用於自動查詢改寫。
Inactive狀態的物化視圖仍然可以直接查詢,但在它們被變為Active之前,資料一致性不能得到保證。
由於Inactive狀態的物化視圖其資料一致性無法保證,您可以使用以下方法修複:
手動修複:您可以通過執行
ALTER MATERIALIZED VIEW <mv_name> ACTIVE手動修複Inactive狀態的物化視圖。此語句將根據物化視圖原始SQL定義嘗試重建。需要注意的是,重建時需保證在底層Schema Change之後,SQL定義仍然有效,否則操作將失敗。重新整理時修複:StarRocks將會在重新整理物化視圖時嘗試自動執行以上的修複命令,重建物化視圖再重新整理。
自動修複:StarRocks將會嘗試自動修複Inactive的物化視圖,您可以通過
ADMIN SET FRONTEND CONFIG('enable_mv_automatic_active_check'='false')關閉此功能。
分區建模
除分層建模外,分區建模也是資料建模的一個重要方面。資料建模往往涉及根據業務語義關聯資料,並根據時效性要求設定資料的存留時間(TTL)。分區建模在此過程中起著重要作用。不同的資料關聯方式會產生不同的建模方法,如星型模式和雪花模式。這些模型有一個共同點,它們都使用事實表和維度資料表。一些業務情境需要多個大型事實表,而其他情境涉及複雜的維度資料表及關聯關係。StarRocks的物化視圖支援事實表的分區關聯,即事實表進行分區,而物化視圖的Join結果按照同樣的方式進行分區。
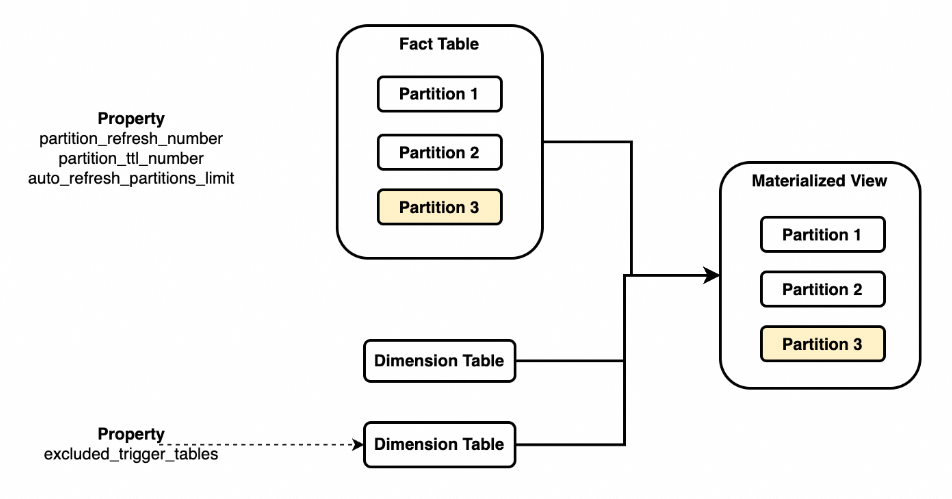
以上圖為例,通過物化視圖將事實表和多個維度資料表進行關聯:
您需要在物化視圖的分區鍵中指定特定基表(通常是事實表)的分區鍵來實現物化視圖的分區關聯(
PARTITION BY fact_tbl.col)。一個物化視圖僅能與一個基表做分區關聯。當被關聯基表的某個分區中的資料發生變化時,物化視圖中相應的分區將被重新整理,但不影響其他分區。
當其他未被關聯的基表發生變化時,預設情況下會重新整理整個物化視圖。然而,您可以選擇忽略某些未關聯表中的資料變化,以便在這些表中的資料發生變化時不重新整理物化視圖。
業務情境
分區關聯可以支援多種業務情境:
事實表更新:您可以將事實表分區到細粒度層級,例如按日或按小時。在事實表更新後,物化視圖中相應的分區將自動重新整理。
維度資料表更新:通常,維度資料表中的資料更新將導致所有關連接果的重新整理,重新整理代價較大。您可以選擇忽略某些維度資料表中的資料更新,以避免重新整理整個物化視圖,或者您可以指定一個時間範圍,從而只有在該時間範圍內的分區才能被重新整理。
外部表格的自動重新整理:在類似於Apache Hive或Apache Iceberg這樣的外部資料源中,資料往往以分區的粒度進行變更。StarRocks的物化視圖可以訂閱外表分區層級的資料更新,只重新整理物化視圖的相應分區。
TTL:在為物化視圖設定分區策略時,您可以設定要保留的最近分區的數量,從而僅保留最新的資料。其對應的業務情境對資料時效性有較高要求,例如,分析師僅需要查詢某個時間視窗內的最新資料,而無需保留所有歷史資料。
您可以使用多個參數來控制重新整理行為:
partition_refresh_number:每次重新整理操作中要重新整理的分區數。partition_ttl_number:要保留的最近分區的數量。excluded_trigger_tables:為避免觸發自動重新整理而需要忽略的表。auto_refresh_partitions_limit:每次自動重新整理操作中要重新整理的分區數。
使用限制
分區物化視圖存在如下限制:
僅支援基於分區表建立分區物化視圖。
僅支援DATE和DATETIME類型的分區列,不支援STRING類型。
僅支援使用date_trunc、time_slice和date_slice做分區上卷。
僅支援單個列作為分區列,不支援多分區列。