使用變數可以有效降低重複編寫相同值的工作量,從而提升組態管理的效率。通過變數的複用,可以在SQL開發、批任務開發及工作流程等情境中簡化代碼的維護和調整,進而提高開發效率。本文將為您詳細介紹如何建立變數及其在不同情境下的具體使用方法。
背景資訊
變數由變數名和變數值組成。其中,變數名是您自訂的名稱,用於代替真實資料;變數值則是變數名所對應的具體內容。在運行時,您可以通過${變數名}的方式引用變數,系統會自動將其替換為對應的真實值。以下情境支援自訂變數的使用:
資料開發變數
新增自訂變數
SparkSQL開發
建立SparkSQL資料開發的具體操作,請參見SparkSQL開發快速入門。
拷貝如下代碼到新增的SparkSQL開發頁簽中。
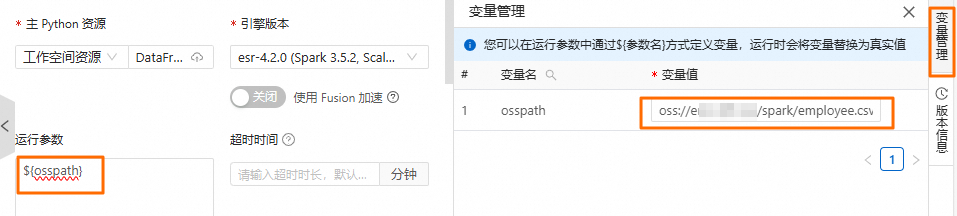
CREATE TABLE IF NOT EXISTS students_info ( name VARCHAR(64), address VARCHAR(64) ) USING PARQUET PARTITIONED BY (data_date STRING); INSERT OVERWRITE TABLE students_info PARTITION (data_date = '${my_date}') VALUES ('Ashua Hill', '456 Erica Ct, Cupertino'), ('Brian Reed', '723 Kern Ave, Palo Alto');單擊右側的變數管理,設定變數值(例如,2025-04-15)。

在新增的頁簽中,再輸入並運行以下命令,查詢表資料。
SELECT * FROM students_info;返回以下資訊,確認變數是否被正確解析。

批任務開發
建立批任務資料開發的具體操作,請參見批任務或流任務開發。
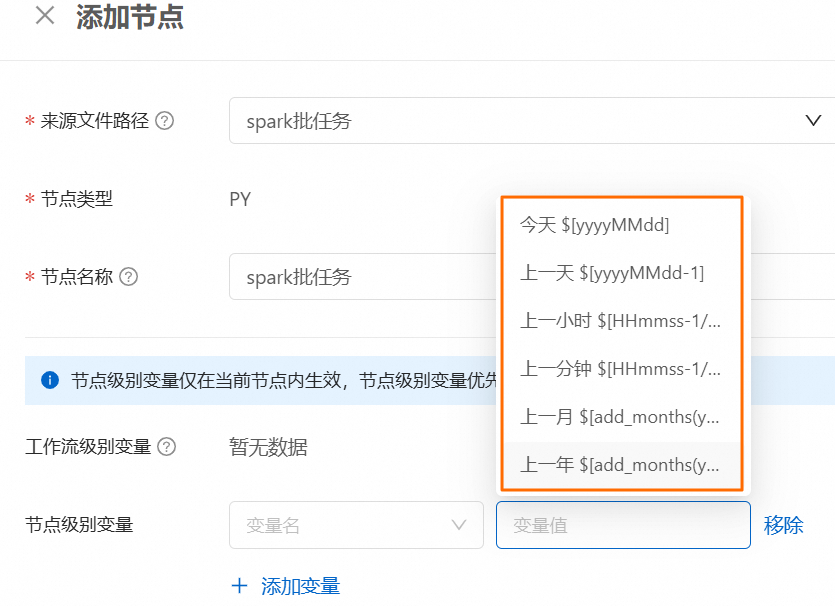
在新增的批任務開發頁簽的運行參數中,設定變數名(例如,
${osspath})。單擊右側的變數管理,設定變數值。
使用內建變數
建立SparkSQL資料開發的具體操作,請參見SparkSQL開發快速入門。
拷貝如下代碼到新增的頁簽中並運行。
CREATE TABLE IF NOT EXISTS students_address (
name VARCHAR(64),
address VARCHAR(64)
)
USING PARQUET
PARTITIONED BY (data_date STRING);
INSERT OVERWRITE TABLE students_address PARTITION (data_date = '${ts}') VALUES
('Ashua Hill', '456 Erica Ct, Cupertino'),
('Brian Reed', '723 Kern Ave, Palo Alto');
SELECT * FROM students_address;返回以下資訊。

使用內建變數時,其值預設基於系統時區(UTC+8)的前一日產生,且不支援自訂修改。目前支援以下基礎日期變數。
變數 | 資料類型 | 說明 |
{data_date} | str | 表示日期資訊的變數,格式為 例如,2023-09-18。 |
{ds} | str | |
{dt} | str | |
{data_date_nodash} | str | 表示日期資訊的變數,格式為 例如,20230918。 |
{ds_nodash} | str | |
{dt_nodash} | str | |
{ts} | str | 表示時間戳記,格式為 例如,2023-09-18T16:07:43。 |
{ts_nodash} | str | 表示時間戳記,格式為 例如,20230918160743。 |
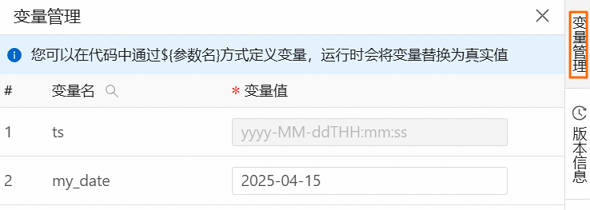
查看或修改變數值
單擊您已有資料開發頁簽右側的變數管理。
在變數管理地區,會為您展示當前資料開發的所有變數資訊。
您可以在該地區查看或修改自訂變數的值。
任務編排變數
任務編排支援設定工作流程和節點層級的變數。遵循就近優先原則:節點層級變數的定義將覆蓋工作流程層級的同名變數。
使用內建變數,不支援設定變數名。
新增工作流程層級的變數
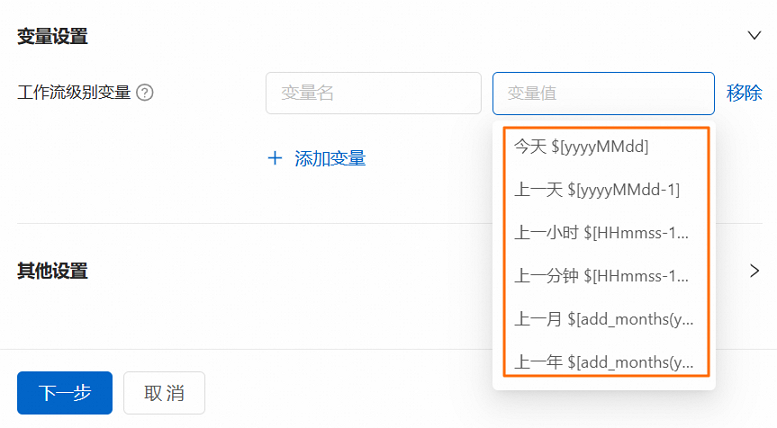
在建立工作流程面板的變數設定地區,可以直接自訂變數,後續工作流程調度時將自動對任務中的變數進行替換。

您可以在變數值的下拉式清單中選擇常用的時間變數,並且支援對時間變數進行自訂修改。
新增節點層級的變數
在添加節點面板,選擇來源檔案路徑後,單擊節點層級變數後的添加變數,新增節點層級的變數。
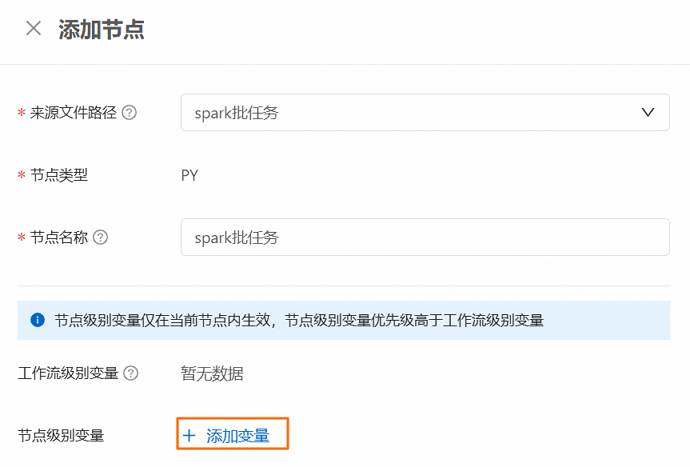
您可以在變數值的下拉式清單中選擇常用的時間變數,並且支援對時間變數進行自訂修改。