在使用阿里雲EMR Serverless Spark的Notebook時,您可以通過Hadoop命令直接存取OSS或OSS-HDFS資料來源。本文將詳細介紹如何通過Hadoop命令操作OSS/OSS-HDFS。
前提條件
EMR Serverless Spark環境準備:
已建立Notebook會話,本文引擎版本以esr-4.1.1版本為例,詳情請參見管理Notebook會話。
已建立Notebook開發,詳情請參見Notebook開發。
OSS服務準備:
如需使用OSS-HDFS服務,需先開通此服務,具體操作請參見開通OSS-HDFS服務。
許可權配置:
如需跨帳號訪問OSS/OSS-HDFS,必須配置相應的許可權,具體操作請參見如何跨帳號訪問阿里雲OSS。
說明本文樣本中,在OSS控制台配置的授權操作為讀/寫,您可以根據實際情況進行相應的授權操作。
使用限制
僅以下引擎版本支援本文操作:
esr-4.x:esr-4.1.1及之後版本。
esr-3.x:esr-3.1.1及之後版本。
esr-2.x:esr-2.5.1及之後版本。
支援的操作類型
在目前的版本中,您可以對OSS/OSS-HDFS進行以下操作,包括但不限於:
ls:列出指定OSS/OSS-HDFS路徑下的檔案和目錄。mv:移動檔案或目錄。cp:複製檔案或目錄。stat:擷取指定檔案或目錄的中繼資料。
您可以執行!hadoop fs -help命令,查看相關協助資訊。
目前,Jindo CLI支援的FS命令均可在Notebook中使用,相關命令、命令樣本及適用範圍詳見:Jindo CLI使用指南,其中命令樣本在Notebook中使用時,需要將jindo替換為!hadoop。
訪問路徑格式
OSS/OSS-HDFS的訪問路徑如下所示:
OSS路徑格式:
oss://<bucketName>/<object-path>OSS-HDFS路徑格式:
oss://<bucketName>.<region>.oss-dls.aliyuncs.com/<object-path>
其中,涉及參數說明如下:
<bucketName>:OSS Bucket名稱。例如:my-bucket。<region>:OSS Bucket所在的地區,例如:cn-hangzhou。<object-path>:OSS Bucket中的檔案路徑。例如:spark/file.txt或logs/。
使用方法
在Notebook開發中,您可以通過 !hadoop fs 命令直接執行以下操作。
列出OSS路徑內容(ls)
使用 -ls 參數列出指定路徑下的檔案和目錄。
!hadoop fs -ls oss://<bucketName>/<object-path>樣本1:列出spark路徑下的所有檔案和目錄。
!hadoop fs -ls oss://my-bucket/spark/返回資訊如下所示。
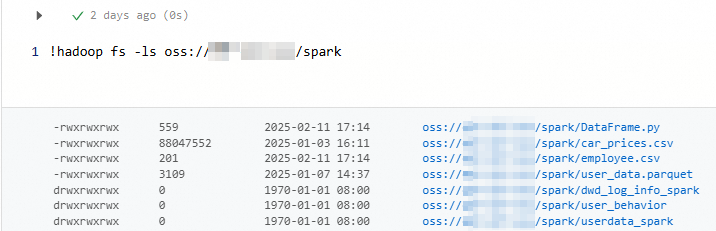
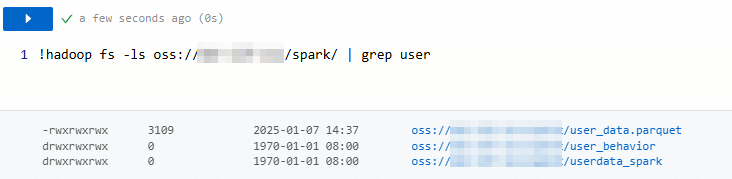
樣本2:結合
-ls和grep命令尋找所有包含 “user” 的檔案和目錄。!hadoop fs -ls oss://my-bucket/spark/ | grep user返回資訊如下所示。
移動檔案或目錄(mv)
使用 -mv 參數將檔案或目錄移動到目標路徑。
!hadoop fs -mv oss://<bucketName>/<object-path>/source oss://<bucketName>/<object-path>/destination例如,移動sr路徑下的file.txt到user路徑下。如果目標路徑已存在,檔案將被覆蓋。
!hadoop fs -mv oss://my-bucket/sr/file.txt oss://my-bucket/user/file.txt複製檔案或目錄(cp)
使用 -cp 參數將檔案或目錄從源路徑複製到目標路徑。
!hadoop fs -cp oss://<bucketName>/<object-path>/source oss://<bucketName>/<object-path>/destination例如,複製spark路徑下的file.txt到spark2路徑下。如果目標路徑已存在,檔案將被覆蓋。
!hadoop fs -cp oss://my-bucket/spark/file.txt oss://my-bucket/spark2/file.txt查看檔案或目錄的中繼資料(stat)
使用 -stat 和合適的參數查看指定檔案或目錄的詳細資料。
!hadoop fs -stat oss://<bucketName>/<object-path>/to/file例如,查看file.txt檔案的基本中繼資料。
!hadoop fs -stat oss://my-bucket/spark/file.txt