EMR Severless Spark 提供統一的外部模型服務註冊能力,支援對接百鍊、PAI-EAS及自建模型。無需編寫代碼,通過 SQL 即可實現批量情感分析、內容產生、智能標籤提取與向量化嵌入,讓 AI 推理無縫融入資料處理流程。
操作步驟
本文以阿里雲PAI為例,示範Qwen3-0.6B模型在PAI-EAS的部署與EMR中的註冊調用,完成AI推理的無縫整合。
步驟 | 目標 | 所屬平台 |
部署服務 | 在PAI-EAS中發布服務 | 阿里雲PAI控制台 |
擷取憑證 | 擷取 | 阿里雲PAI控制台 |
註冊服務 | 在 EMR Serverless Spark中註冊外部模型 | EMR Serverless Spark 控制台 |
調用模型 | 使用 SQL 執行ai_query() | EMR Serverless Spark 控制台 |
如果您已成功在PAI控制台部署服務,請直接跳轉至擷取憑證。
部署服務
以部署公用模型中的Qwen3.5-Plus為例。
公用模型是指已預置部署模板的模型,可一鍵部署,無需準備模型檔案。如選擇自訂模型,需通過Object Storage Service等方式掛載模型檔案。
登入PAI控制台,在頁面上方選擇目標地區,並在右側選擇目標工作空間,然後單擊進入EAS。
在推理服務頁簽,單擊部署服務,然後在情境化模型部署地區,單擊LLM大語言模型部署。
在部署LLM大語言模型頁面,配置以下關鍵參數。
模型配置:選擇公用模型,在列表中搜尋並選擇Qwen3-0.6B。
推理引擎:推薦使用SGLang/vLLM(高度相容OpenAI API標準)。本文以vLLM為例,更多說明,請參見選擇合適的推理引擎。
部署模板:選擇單機。系統將根據模板自動填滿推薦的執行個體規格、鏡像等參數。
單擊部署,服務部署耗時約5分鐘。當服務狀態變為運行中,表示部署成功。
說明若服務部署失敗,請參考服務部署與狀態異常解決。
擷取憑證
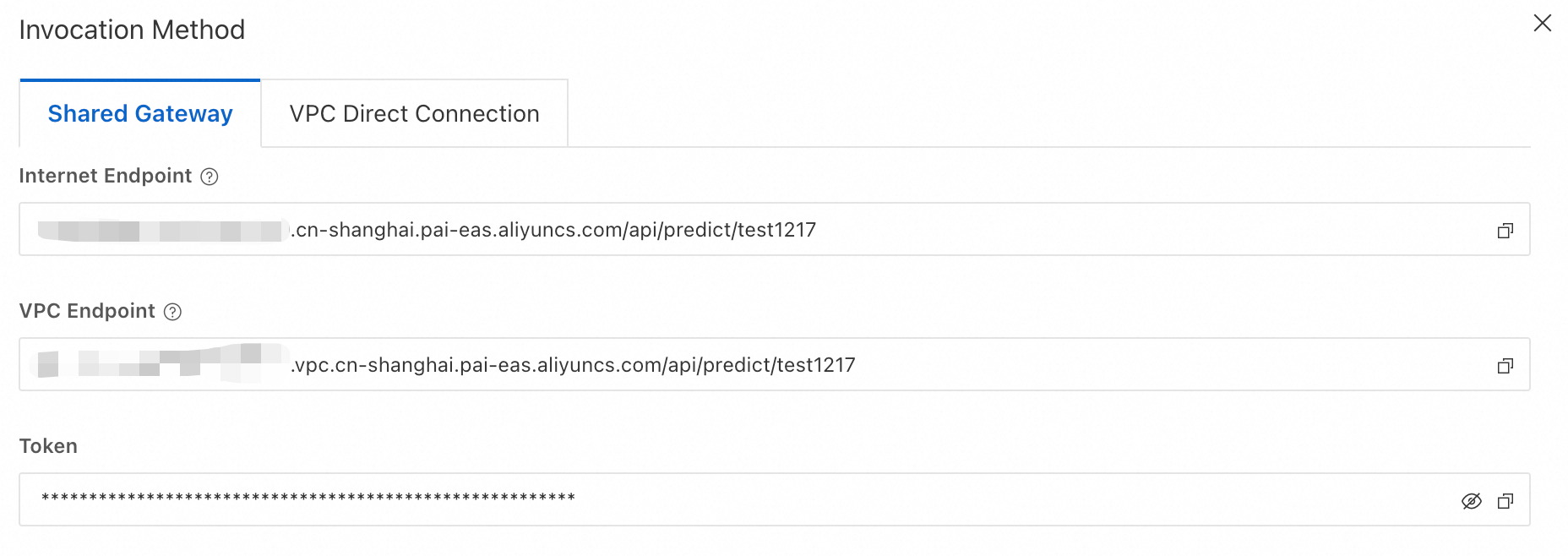
服務部署成功後,您需要擷取其VPC調用地址和Token,用於後續在 EMR Serverless Spark 中註冊該服務。
在推理服務頁簽,單擊您的服務名稱進入概覽頁面,在基本資料地區單擊查看調用資訊。
在調用資訊面板,可擷取VPC調用地址和Token。
註冊服務
將 PAI-EAS 服務註冊到 EMR Serverless Spark中,以便 Spark SQL 中的 ai_query() 函數能夠識別並調用它。
進入模型服務頁面。
在左側導覽列,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導覽列中的。
在模型服務頁簽,單擊建立外部模型服務,並配置以下資訊:
欄位
值樣本
說明
模型服務名稱
my_qwen_service該名稱用於後續
AI Function中endpointName入參的值,工作空間中唯一,不支援後續修改。Endpoint
http://12*******39.vpc.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/<ServiceName>/v1填寫上一步中擷取的VPC調用地址,並在其末尾手動添加
/v1。模型名稱
Qwen3.5-Plus實際調用時的model名稱。
模型類型
Chat根據部署的模型類型選擇
Chat還是Embedding。API KEY
nMzI**********************Zg==填寫上一步中擷取的
Token資訊。描述
千問最新多模態模型服務
填寫服務的簡要描述,便於識別。
確認所有配置項無誤後,單擊建立完成模型服務註冊。
調用模型
完成模型服務註冊後,您即可在 EMR Serverless Spark 中使用內建的 ai_query() 函數,通過標準 SQL 陳述式調用大模型服務,實現無需編寫代碼的 AI 脫敏能力整合。
Gateway類型任務(Livy、Kyuubi)當前暫不支援。
建立 Spark SQL 作業並啟用 AI 功能
在開發目錄頁簽下,單擊
 (建立)表徵圖。
(建立)表徵圖。在彈出的對話方塊中,輸入名稱,類型選擇SparkSQL,然後單擊確定。
在右上方下拉式清單中單擊建立SQL會話,並配置以下資訊:
配置項
設定說明
引擎版本
選擇以下版本。
esr-4.x:esr-4.6.0及之後版本。
esr-3.x:esr-3.5.0及之後版本。
esr-2.x:esr-2.9.0及之後版本。
進階配置
在自訂配置中,添加
spark.emr.serverless.ai.function.enable trueSpark配置啟用 AI 功能。
編寫 SQL 調用模型
在資料開發頁面,使用 ai_query() 函數編寫 SQL 陳述式來調用模型。
-- 第二個參數 'my_qwen_service' 是註冊模型服務時的模型服務名稱 select ai_query('請對下面文本進行資訊脫敏處理,規則如下: 1)中文姓名全部替換為“” 2)手機號保留前5位,其餘替換為“*” 3)完整地址全部替換為“*****” 4)其他文本保持不變 5)僅輸出脫敏後的文本,不要解釋 原文:我的名字叫張三,電話號碼是什麼12345678900,導航去深圳市龍崗區智慧家園', 'my_qwen_service');查看脫敏結果
執行成功後,返回結果如下所示。
我的名字叫,電話號碼是什麼12345*****,導航去*****
相關文檔
更多PAI-EAS模型自訂部署相關資訊,請參見模型線上服務 EAS 快速入門。
PAI-EAS提供了一站式LLM部署解決方案,請參見LLM大語言模型部署。