EMR Serverless Spark支援串連外部Hive Metastore服務,從而便捷地訪問儲存在Hive Metastore中的資料。本文將介紹如何在EMR Serverless Spark中配置和串連外部Hive Metastore服務,以便在工作環境中高效管理和利用資料資源。
前提條件
使用限制
使用Hive Metastore需要您重啟工作空間中現有的會話。
設定Hive Metastore為預設Catalog後,您的工作流程工作將預設依賴於Hive Metastore。
操作流程
步驟一:準備Hive Metastore服務
本文採用EMR on ECS的Hive Metastore作為外部服務,如果您的VPC內已經有Hive Metastore服務,則請忽略該步驟。
步驟二:新增網路連接
進入網路連接頁面。
在左側導覽列,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導覽列中的網路連接。
在網路連接頁面,單擊新增網路連接。
在新增網路連接對話方塊中,配置以下資訊,單擊確定。
參數
說明
串連名稱
輸入新增串連的名稱。
專用網路
選擇與EMR叢集相同的專用網路。
交換器
選擇與EMR叢集部署在同一專用網路下的相同交換器。
當狀態顯示為已成功時,表示新增網路連接成功。

步驟三:開放Hive Metastore服務連接埠
擷取已建立網路連接中指定交換器的網段。
您可以登入專用網路管理主控台,在交換器頁面擷取交換器的網段。

添加安全性群組規則。
在EMR on ECS頁面,單擊目的地組群的叢集ID。
在基礎資訊頁面,單擊叢集安全性群組後面的連結。
在安全性群組頁面,單擊增加規則,填寫訪問來源和連接埠,然後單擊確定。
參數
說明
連接埠
填寫9083連接埠。
訪問來源
填寫前一步驟中擷取的指定交換器的網段。
重要為防止被外部的使用者攻擊導致安全問題,訪問來源禁止填寫為0.0.0.0/0。
步驟四:串連Hive Metastore
在EMR Serverless Spark頁面,單擊左側導覽列中的資料目錄。
在資料目錄頁面,單擊添加資料目錄。
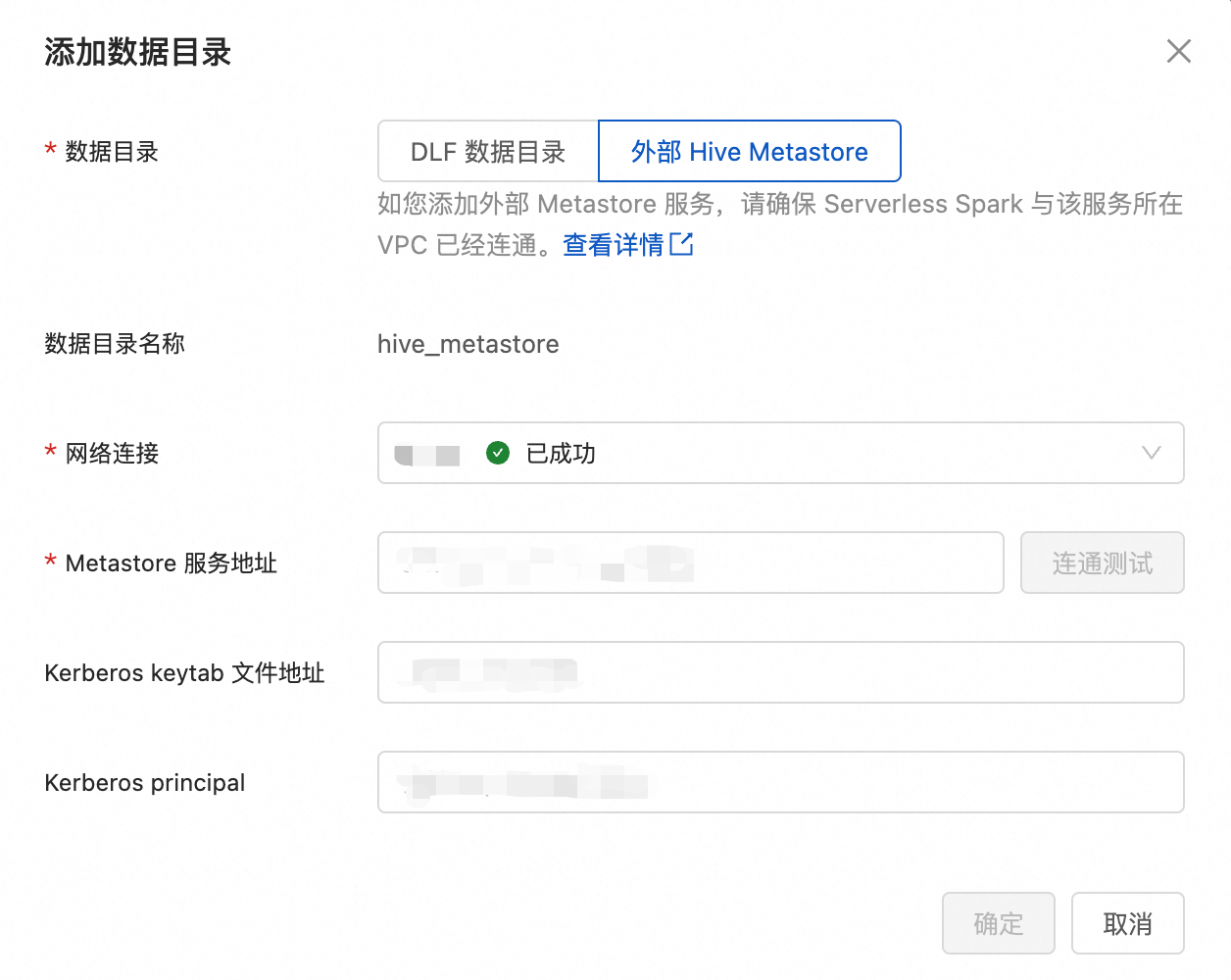
在彈出的對話方塊中,單擊外部Hive Metastore,配置以下資訊,單擊確定。
參數
說明
網路連接
選擇步驟二中新增的網路連接。
Metastore服務地址
Hive MetaStore的URI。格式為
thrift://<Hive metastore的IP地址>:9083。<Hive metastore的IP地址>為HMS服務的內網IP地址。本樣本為EMR叢集Master節點的內網IP,您可以在EMR叢集的節點管理頁面中查看。說明如果HMS開啟了高可用,支援填寫多個節點的HMS服務地址。多個URI之間應使用“,”分隔,例如:thrift://<Hive metastore的IP地址1>:9083,thrift://<Hive metastore的IP地址2>:9083。
Kerberos keytab 檔案地址
Kerberos keytab檔案路徑。
Kerberos principal
keytab檔案中包含的Principal的名稱,用於與Kerberos服務進行身分識別驗證。您可以使用
klist -kt <keytab檔案>命令查看目標keytab檔案中Principal的名稱。
步驟五:使用Hive Metastore
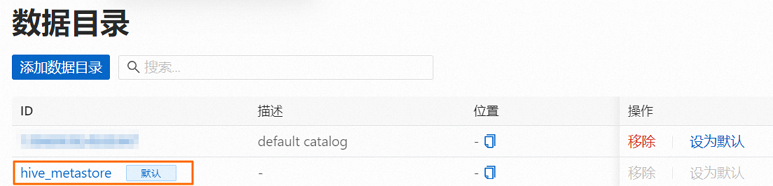
在資料目錄頁面,單擊hive_metastore操作列的設為預設,設定hive_metastore為工作空間的預設資料目錄。
重啟SQL會話。
如果您的工作空間中已有SQL會話,您需先停止SQL會話,然後再啟動SQL會話,以確保hive_metastore生效。
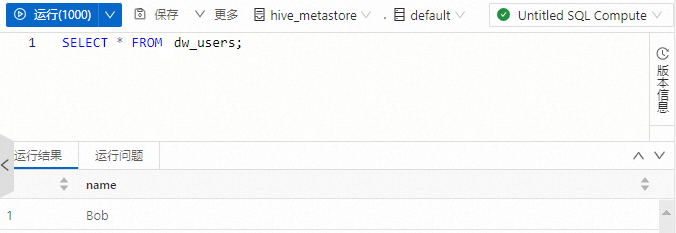
在SQL開發中查詢hive_metastore表的資料。
建立SQL開發,詳情請參見SparkSQL開發。
執行以下命令,查詢hive_metastore中的dw_users表。
SELECT * FROM dw_users;