本文為您介紹如何使用Flume同步EMR Kafka叢集的資料至EMR DataServing叢集的HBase。
前提條件
操作步驟
- 建立HBase表。
- 通過SSH方式串連DataServing叢集,詳情請參見登入叢集。
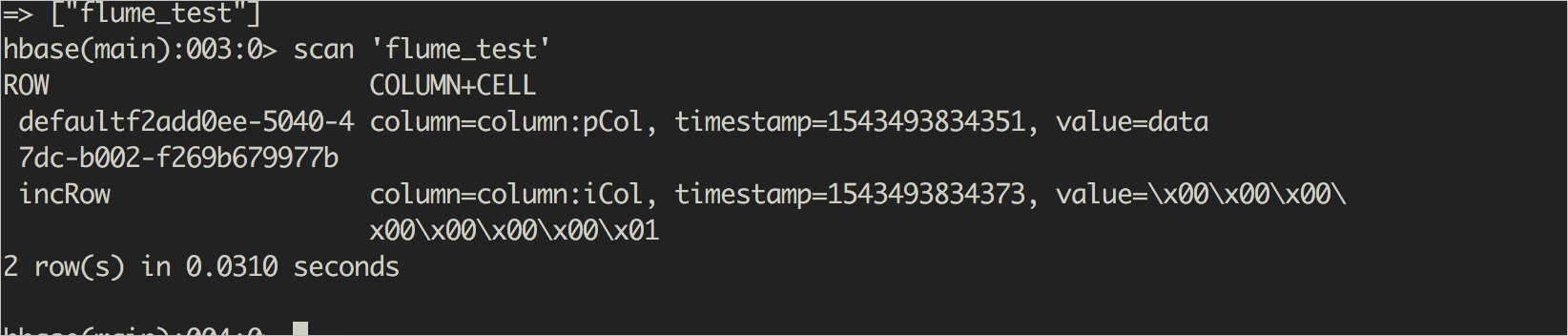
- 執行以下命令,串連HBase。
hbase shell - 建立名為flume_test的HBase表,表中包含一個列簇column。
create 'flume_test','column'
- 配置Flume。
- 進入Flume的配置頁面。
- 在頂部功能表列處,根據實際情況選擇地區和資源群組。
- 在叢集管理頁面,單擊目的地組群操作列的叢集服務。
- 在叢集服務頁面,單擊FLUME服務地區的配置。
- 單擊flume-conf.properties頁簽。本文樣本採用的是全域配置方式,如果您想按照節點配置,可以在FLUME服務配置頁面的下拉式清單中選擇獨立節點配置。
- 在flume-conf.properties的參數值中,添加以下內容。說明 程式碼範例中的
default-agent,請與FLUME服務配置頁面的agent_name參數的參數值保持一致。default-agent.sources = source1 default-agent.sinks = k1 default-agent.channels = c1 default-agent.sources.source1.type = org.apache.flume.source.kafka.KafkaSource default-agent.sources.source1.channels = c1 default-agent.sources.source1.kafka.bootstrap.servers = <kafka-host1:port1,kafka-host2:port2...> default-agent.sources.source1.kafka.topics = flume-test default-agent.sources.source1.kafka.consumer.group.id = flume-test-group default-agent.sinks.k1.type = hbase default-agent.sinks.k1.table = flume_test default-agent.sinks.k1.columnFamily = column # Use a channel which buffers events in memory default-agent.channels.c1.type = memory default-agent.channels.c1.capacity = 100 default-agent.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel default-agent.sources.source1.channels = c1 default-agent.sinks.k1.channel = c1參數 描述 default-agent.sources.source1.kafka.bootstrap.servers Kafka叢集Broker的Host和連接埠號碼。 default-agent.sinks.k1.table HBase表名。 default-agent.sinks.k1.columnFamily 列簇名。 default-agent.channels.c1.capacity 通道中儲存的最大事件數目。請根據實際環境修改該參數值。 default-agent.channels.c1.transactionCapacity 每個事務通道將從源接收或提供給接收器的最大事件數目。請根據實際環境修改該參數值。
- 進入Flume的配置頁面。
- 啟動服務。
- 在FLUME服務頁面,選擇。
- 在彈出的對話方塊中,輸入執行原因,單擊確定。
- 在確認對話方塊中,單擊確定。
- 測試資料寫入情況。登入DataFlow叢集,使用
kafka-console-producer.sh命令產生資料後,在DataServing叢集串連HBase即可查看資料。