阿里雲DataWorks支援在E-MapReduce上建立Hive、Spark SQL、Spark等節點,實現任務工作流程的配置、調度,同時具備中繼資料管理和資料品質監控警示功能,協助使用者高效開發、治理資料。本文將介紹如何通過阿里雲DataWorks提交作業。
支援的叢集類型
DataWorks目前支援註冊的叢集類型如下:
DataLake叢集(新版資料湖)
Custom叢集(自訂叢集)
Hadoop叢集(舊版資料湖)
支援在DataWorks使用以下EMR版本的Hadoop叢集(舊版資料湖):
EMR-3.38.2、EMR-3.38.3、EMR-4.9.0、EMR-5.6.0、EMR-3.26.3、EMR-3.27.2、EMR-3.29.0、EMR-3.32.0、EMR-3.35.0、EMR-4.3.0、EMR-4.4.1、EMR-4.5.0、EMR-4.5.1、EMR-4.6.0、EMR-4.8.0、EMR-5.2.1、EMR-5.4.3
Hadoop叢集(舊版資料湖)已不建議使用,請儘快遷移至DataLake叢集,詳情請參見Hadoop叢集遷移至DataLake叢集。
使用限制
任務類型:DataWorks暫不支援執行EMR的Flink任務。
任務執行:DataWorks支援使用Serverless資源群組(推薦)或舊版獨享調度資源群組進行EMR任務執行。
任務治理:
僅EMR Hive、EMR Spark及EMR Spark SQL節點中SQL任務支援產出血緣關係。當叢集版本為5.9.1或3.43.1及以上版本時,以上節點均支援查看錶級血緣與欄位級血緣。
說明對於Spark類型節點,當EMR叢集版本為5.8.0和3.42.0及以上版本時,支援查看錶級血緣與欄位級血緣,當EMR叢集版本低於5.8.0和3.42.0版本時,僅Spark 2.x支援查看錶級血緣。
DataLake或自訂叢集若要在DataWorks管理中繼資料,需先在叢集側配置EMR-HOOK。若未配置,則在DataWorks中無法即時展示中繼資料、產生審計日誌、展示血緣關係,EMR相關治理任務將無法開展。目前僅EMR Hive、EMR Spark SQL服務支援配置EMR-HOOK,配置詳情請參見配置Hive的EMR-HOOK、配置Spark SQL的EMR-HOOK。
地區限制:目前僅華東1(杭州)、華東2(上海)、華北2(北京)、華北3(張家口)、華南1(深圳)、新加坡、德國(法蘭克福)、美國(維吉尼亞)地區支援使用EMR Serverless Spark。
開啟Kerberos認證的EMR叢集的安全性群組需要對資源群組綁定的交換器網段放開UDP協議連接埠的入許可權。
說明您需單擊EMR叢集基礎資訊中叢集安全性群組的
 表徵圖,進入安全性群組詳情頁簽,單擊訪問規則的入方向,選擇手動添加,協議類型選擇自訂UDP,連接埠範圍配置詳情請查看EMR叢集中的
表徵圖,進入安全性群組詳情頁簽,單擊訪問規則的入方向,選擇手動添加,協議類型選擇自訂UDP,連接埠範圍配置詳情請查看EMR叢集中的/etc/krb5.conf檔案中對應的kdc連接埠,授權對象設定為資源群組綁定的交換器網段。
前提條件
注意事項
若要實現DataWorks標準模式工作空間的開發環境與生產環境隔離機制,您需要為開發環境和生產環境註冊兩個不同的EMR叢集。且這兩個叢集的中繼資料需要使用如下儲存方式:
方式一(資料湖方案推薦):儲存在資料湖構建DLF(Data Lake Formation)的兩個不同資料目錄Catalog。詳情請參見切換中繼資料存放區類型。
方式二:儲存在阿里雲關係型資料庫RDS(Relational Database Service)的兩個不同資料庫Database。詳情請參見配置自建RDS。
一個EMR叢集可以註冊在同一個阿里雲帳號的多個工作空間,但無法跨帳號註冊至多個工作空間。例如,某叢集登入至當前阿里雲帳號的工作空間,則該叢集將無法跨帳號再次被註冊至其他阿里雲帳號的工作空間。
為確保DataWorks資源群組正常訪問EMR叢集,若DataWorks資源群組綁定與EMR同一個專用網路和交換器後仍無法串連,請檢查EMR叢集安全性群組規則,添加對應交換器網段及常用開源組件的連接埠的入規則。具體操作請參見管理EMR叢集安全性群組。
DataWorks環境準備
在DataWorks上開發前需要已開通DataWorks服務,詳情請參見DataWorks準備工作。
一、建立工作空間
如果在華東2(上海)地區已有工作空間,可以忽略該步驟,使用已有工作空間。
登入DataWorks控制台,在左上方切換地區至華東2(上海)。
單擊左側導覽列中的工作空間,進入空間列表頁面,單擊建立工作空間,建立標準模式空間(生產、開發環境隔離),詳情請參見建立工作空間。
二、建立Serverless資源群組
本教程在資料同步與調度時,需要使用DataWorks的Serverless資源群組,因此您需要先購買Serverless資源群組,並完成前期的準備工作。
購買Serverless資源群組。
登入DataWorks控制台,在頂部切換地區至華東2(上海),單擊左側導覽列的資源群組,進入資源群組列表頁面。
單擊建立資源群組,在資源群組購買頁面,選擇地區和可用性區域為華東2(上海)、設定資源群組名稱,其他參數可根據介面提示進行配置,完成後根據介面提示完成付款。Serverless資源群組的計費說明請參見Serverless資源群組計費。
說明如當前地區沒有可用的VPC和交換器,請單擊參數說明中對應的控制台連結前往建立。VPC和交換器的更多資訊,請參見什麼是專用網路。
將資源群組綁定至DataWorks工作空間。
新購買的Serverless資源群組需要綁定至工作空間,才能在後續操作中使用。
登入DataWorks控制台,在頂部切換地區至華東2(上海),找到購買的Serverless資源群組,單擊操作列的綁定工作空間,然後單擊已建立的DataWorks工作空間後的綁定。
為資源群組配置公網訪問能力。
由於本教程使用的測試資料需要通過公網擷取,資源群組預設不具備公網訪問能力,因此需要為資源群組綁定的VPC配置公網NAT Gateway,添加EIP,使其與公開資料網路打通,從而擷取資料。
登入專用網路-公網NAT Gateway控制台,在頂部功能表列切換至華東2(上海)地區。
單擊建立公網NAT Gateway,配置相關參數。以下為本樣本所需配置的關鍵參數,未說明參數保持預設即可。
參數
取值
所屬地區
華東2(上海)。
所屬專用網路
選擇資源群組綁定的VPC和交換器。
您可以前往DataWorks管理主控台,切換地區後,在左側導覽列單擊資源群組列表,找到已建立的資源群組,然後單擊操作列的網路設定,在資料調度 & Data Integration地區查看綁定專用網路和交換器。VPC和交換器的更多資訊,請參見什麼是專用網路。
關聯交換器
訪問模式
專用網路全通模式(SNAT)。
Elastic IP Address執行個體
新購Elastic IP Address。
關聯角色建立
首次建立NAT Gateway時,需要建立服務關聯角色,請單擊建立關聯角色。
單擊立即購買,勾選服務合約後,單擊立即開通,完成購買。
更多新增和使用Serverless資源群組的操作指導請參見新增和使用Serverless資源群組。
三、註冊EMR叢集並完成資源群組初始化
只有將叢集註冊至DataWorks,才可以在DataWorks上使用EMR叢集。
進入EMR叢集註冊頁面。
進入管理中心頁面。
登入DataWorks控制台,切換地區至華東2(上海)後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入管理中心。
單擊左側導覽列的叢集管理,進入叢集管理頁面 ,單擊註冊叢集按鈕,選擇註冊叢集類型為E-MapReduce。進入註冊E-MapReduce叢集頁面。
註冊EMR叢集。
在註冊E-MapReduce叢集頁面配置叢集資訊,關鍵參數配置資訊如下。
參數
取值
叢集所屬雲帳號
當前阿里雲主帳號。
叢集類型
資料湖(DataLake)。
預設訪問身份
叢集帳號:hadoop。
傳遞proxy user資訊
傳遞。
資源群組初始化。
在叢集管理頁面,找到登入的EMR叢集,單擊右上方的資源群組初始化。
在需要初始化的資源群組後面單擊初始化。
完成後單擊確認。
重要初始化資源群組時,請務必確保初始化成功,否則可能導致任務運行失敗。如果初始化失敗,請根據介面提示查看失敗原因並進行連通性診斷。
註冊EMR叢集的詳細操作,請參見舊版資料開發:綁定EMR計算資源。
提交EMR作業
提交EMR Hive作業
步驟一:建立EMR Hive節點
進入資料開發頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
建立EMR Hive節點。
按右鍵目標商務程序,選擇。
說明您也可以滑鼠移至上方至建立,選擇。
在建立節點對話方塊中,輸入名稱,並選擇引擎執行個體、節點類型及路徑。單擊確認,進入EMR Hive節點編輯頁面。
說明節點名稱支援大小寫字母、中文、數字、底線(_)和小數點(.)。
步驟二:開發EMR Hive任務
在EMR Hive節點編輯頁面雙擊已建立的節點,進入任務開發頁面,執行如下開發操作。
開發SQL代碼
在SQL編輯地區開發工作單位代碼,您可在代碼中使用${變數名}的方式定義變數,並在節點編輯頁面右側導覽列的調度配置>調度參數中為該變數賦值。實現調度情境下代碼的動態傳參,調度參數使用詳情,請參考調度參數支援的格式,樣本如下。
show tables;
select '${var}'; --可以結合調度參數使用。
select * from userinfo ;SQL語句最大不能超過130KB。
如果您工作空間的資料開發中綁定多個EMR計算資源,則需要根據業務需求選擇合適的計算資源。如果僅綁定一個EMR,則無需選擇。
如果您需要修改代碼中的參數賦值,請單擊介面上方工具列的進階運行。參數賦值邏輯詳情請參見運行,進階運行和開發環境煙霧測試 (Smoke Test)賦值邏輯有什麼區別。
執行SQL任務
在工具列單擊
 表徵圖,在參數對話方塊選擇已建立的調度資源群組,單擊運行。說明
表徵圖,在參數對話方塊選擇已建立的調度資源群組,單擊運行。說明訪問公用網路或VPC網路環境的計算資源需要使用與計算資源測試連通性成功的調度資源群組。詳情請參見網路連通方案。
如果您後續執行任務需要修改使用的資源群組,您可單擊帶參運行
表徵圖,選擇需要更換的調度資源群組。使用EMR Hive節點查詢資料時,返回的查詢結果最大支援10000條資料,並且資料總量不能超過10M。
單擊
 表徵圖,儲存編寫的SQL語句。
表徵圖,儲存編寫的SQL語句。(可選)煙霧測試 (Smoke Test)。
如果您希望在開發環境進行煙霧測試 (Smoke Test),可在執行節點提交或節點提交後執行煙霧測試 (Smoke Test),操作詳情請參見執行煙霧測試 (Smoke Test)。
如果您想修改提交作業的隊列,請參見配置進階參數。
步驟三:配置節點調度
如您需要周期性執行建立的節點任務,可單擊節點編輯頁面右側的調度配置,根據業務需求配置該節點任務的調度資訊。配置詳情請參見任務調度屬性配置概述。
您需要設定節點的重跑屬性和依賴的上遊節點,才可以提交節點。
步驟四:發布節點任務
節點任務配置完成後,需執行提交發佈動作,提交發布後節點即會根據調度配置內容進行周期性運行。
單擊工具列中的
 表徵圖,儲存節點。
表徵圖,儲存節點。單擊工具列中的
 表徵圖,提交節點任務。
表徵圖,提交節點任務。提交時需在提交對話方塊中輸入變更描述,並根據需要選擇是否在節點提交後執行程式碼檢閱。
說明您需設定節點的重跑屬性和依賴的上遊節點,才可提交節點。
程式碼檢閱可對任務的代碼品質進行把控,防止由於任務代碼有誤,未經審核直接發布上線後出現任務報錯。如進行程式碼檢閱,則提交的節點代碼必須通過評審人員的審核才可發布,詳情請參見程式碼檢閱。
如您使用的是標準模式的工作空間,任務提交成功後,需單擊節點編輯頁面右上方的發布,將該任務發布至生產環境執行,操作請參見發布任務。
提交EMR Spark SQL作業
一、建立EMR Spark SQL節點
進入資料開發頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
建立EMR Spark SQL節點。
按右鍵目標商務程序,選擇。
說明您也可以滑鼠移至上方至建立,選擇。
在建立節點對話方塊中,輸入名稱,並選擇引擎執行個體、節點類型及路徑。單擊確認,進入EMR Spark SQL節點編輯頁面。
說明節點名稱支援大小寫字母、中文、數字、底線(_)和小數點(.)。
二、開發EMR Spark SQL任務
在EMR Spark SQL節點編輯頁面雙擊已建立的節點,進入任務開發頁面,執行如下開發操作。
開發SQL代碼
在SQL編輯地區開發工作單位代碼,您可在代碼中使用${變數名}的方式定義變數,並在節點編輯頁面右側導覽列的調度配置>調度參數中為該變數賦值。實現調度情境下代碼的動態傳參,調度參數使用詳情,請參考調度參數支援的格式,樣本如下。
SHOW TABLES;
-- 通過${var}定義名為var的變數,若將該變數賦值${yyyymmdd},可實現建立以業務日期作為尾碼的表。
CREATE TABLE IF NOT EXISTS userinfo_new_${var} (
ip STRING COMMENT'IP地址',
uid STRING COMMENT'使用者ID'
)PARTITIONED BY(
dt STRING
); --可以結合調度參數使用。SQL語句最大不能超過130KB。
如果您工作空間的資料開發中綁定多個EMR計算資源,則需要根據業務需求選擇合適的計算資源。如果僅綁定一個EMR,則無需選擇。
執行SQL任務
在工具列單擊
表徵圖,在參數對話方塊選擇已建立的調度資源群組,單擊運行。說明訪問公用網路或VPC網路環境的計算資源需要使用與計算資源測試連通性成功的調度資源群組。詳情請參見網路連通方案。
如果您後續執行任務需要修改使用的資源群組,您可單擊帶參運行
表徵圖,選擇需要更換的調度資源群組。使用EMR Spark SQL節點查詢資料時,返回的查詢結果最大支援10000條資料,並且資料總量不能超過10MB。
單擊
表徵圖,儲存編寫的SQL語句。(可選)煙霧測試 (Smoke Test)。
如果您希望在開發環境進行煙霧測試 (Smoke Test),可在執行節點提交或節點提交後執行煙霧測試 (Smoke Test),操作詳情請參見執行煙霧測試 (Smoke Test)。
如果您想修改提交作業的隊列,請參見配置進階參數。
步驟三:配置節點調度
如您需要周期性執行建立的節點任務,可單擊節點編輯頁面右側的調度配置,根據業務需求配置該節點任務的調度資訊。配置詳情請參見任務調度屬性配置概述。
您需要設定節點的重跑屬性和依賴的上遊節點,才可以提交節點。
步驟四:發布節點任務
節點任務配置完成後,需執行提交發佈動作,提交發布後節點即會根據調度配置內容進行周期性運行。
單擊工具列中的
表徵圖,儲存節點。單擊工具列中的
表徵圖,提交節點任務。提交時需在提交對話方塊中輸入變更描述,並根據需要選擇是否在節點提交後執行程式碼檢閱。
說明您需設定節點的重跑屬性和依賴的上遊節點,才可提交節點。
程式碼檢閱可對任務的代碼品質進行把控,防止由於任務代碼有誤,未經審核直接發布上線後出現任務報錯。如進行程式碼檢閱,則提交的節點代碼必須通過評審人員的審核才可發布,詳情請參見程式碼檢閱。
如您使用的是標準模式的工作空間,任務提交成功後,需單擊節點編輯頁面右上方的發布,將該任務發布至生產環境執行,操作請參見發布任務。
提交EMR Spark作業
一、建立EMR Spark節點
進入資料開發頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
建立EMR Spark節點。
按右鍵目標商務程序,選擇。
說明您也可以滑鼠移至上方至建立,選擇。
在建立節點對話方塊中,輸入名稱,並選擇引擎執行個體、節點類型及路徑。單擊確認,進入EMR Spark節點編輯頁面。
說明節點名稱支援大小寫字母、中文、數字、底線(_)和小數點(.)。
二、開發Spark任務
在EMR Spark節點編輯頁面雙擊已建立的節點,進入任務開發頁面,您可以根據不同情境需求選擇適合您的操作方案:
(推薦)先從本地上傳資源至DataStudio,再引用資源。詳情請參見方案一:先上傳資源後引用EMR JAR資源。
使用OSS REF方式引用OSS資源,詳情請參見方案二:直接引用OSS資源。
方案一:先上傳資源後引用EMR JAR資源
DataWorks也支援您從本地先上傳資源至DataStudio,再引用資源。EMR Spark任務編譯完成後,您需擷取編譯後的JAR包,建議根據JAR包大小選擇不同方式儲存JAR包資源。
上傳JAR包資源,建立為DataWorks的EMR資源並提交,或直接儲存在EMR的HDFS儲存中(EMR on ACK 類型的Spark叢集及EMR Serverless Spark叢集不支援上傳資源到HDFS)。
JAR包小於200MB時
建立EMR JAR資源。
JAR包小於200MB時,可將JAR包通過本地上傳的方式上傳為DataWorks的EMR JAR資源,便於後續在DataWorks控制台進行可視化管理,建立完成資源後需進行提交,操作詳情請參見建立和使用EMR資源。
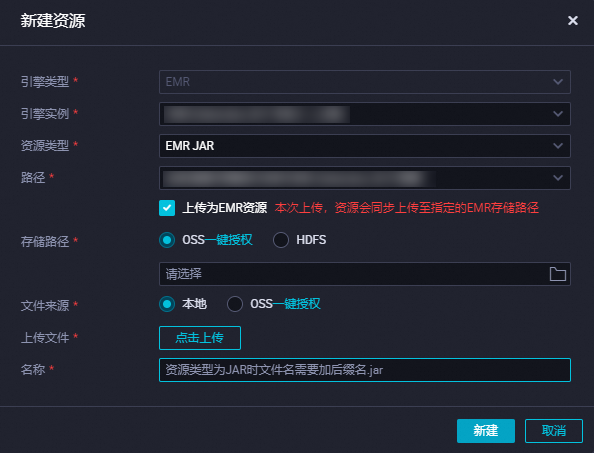 說明
說明首次建立EMR資源時,如果您希望JAR包上傳後儲存在OSS中,您需要先參考介面提示進行授權操作。
引用EMR JAR資源。
雙擊建立的EMR Spark節點,開啟EMR Spark 節點的代碼編輯頁面。
在節點下,找到上述步驟中已上傳的EMR JAR資源,右鍵選擇引用資源。
選擇引用資源後,當前開啟的EMR Spark節點的編輯頁面會自動添加資源引用代碼,引用程式碼範例如下。
##@resource_reference{"spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar"} spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar如果成功自動添加上述引用代碼,表明資源引用成功。其中,spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar為您實際上傳的EMR JAR資源名稱。
改寫EMR Spark節點代碼,補充spark submit命令,改寫後的樣本如下。
說明EMR Spark節點編輯代碼時不支援備註陳述式,請務必參考如下樣本改寫任務代碼,不要隨意添加註釋,否則後續運行節點時會報錯。
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100其中:
org.apache.spark.examples.SparkPi:為您實際編譯的JAR包中的任務主Class。
spark-examples_2.11-2.4.0.jar:為您實際上傳的EMR JAR資源名稱。
其他參數可參考以上樣本不做修改,您也可執行以下命令查看
spark submit的使用協助,根據需要修改spark submit命令。說明若您需要在Spark節點中使用
spark submit命令簡化的參數,您需要在代碼中自行添加,例如,--executor-memory 2G。Spark節點僅支援使用Yarn的Cluster提交作業。
spark submit方式提交的任務,deploy-mode推薦使用cluster模式,不建議使用client模式。
spark-submit --help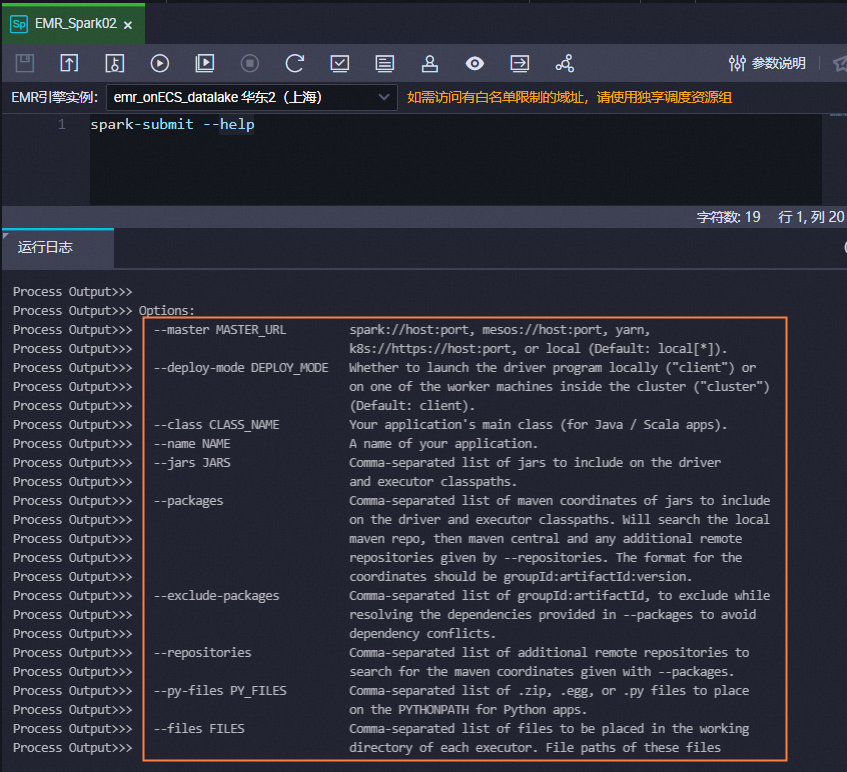
JAR包大於等於200MB時
建立EMR JAR資源。
JAR包大於等於200MB時,無法通過本地上傳的方式直接上傳為DataWorks的資源,建議直接將JAR包儲存在EMR的HDFS中,並記錄下JAR包的儲存路徑,以便後續在DataWorks調度Spark任務時引用該路徑。
引用EMR JAR資源。
JAR包儲存在HDFS時,您可以直接在EMR Spark節點中通過代碼指定JAR包路徑的方式引用JAR包。
雙擊建立的EMR Spark節點,開啟EMR Spark 節點的代碼編輯頁面。
編寫spark submit命令,樣本如下。
spark-submit --master yarn --deploy-mode cluster --name SparkPi --driver-memory 4G --driver-cores 1 --num-executors 5 --executor-memory 4G --executor-cores 1 --class org.apache.spark.examples.JavaSparkPi hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar 100其中:
hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar:為JAR包實際在HDFS中的路徑。
org.apache.spark.examples.JavaSparkPi:為您實際編譯的JAR包中的任務主class。
其他參數為實際EMR叢集的參數,需根據實際情況進行修改配置。您也可以執行以下命令查看spark submit的使用協助,根據需要修改spark submit命令。
重要若您需要在Spark節點中使用Spark-submit命令簡化的參數,您需要在代碼中自行添加,例如,
--executor-memory 2G。Spark節點僅支援使用Yarn的Cluster提交作業。
spark-submit方式提交的任務,deploy-mode推薦使用cluster模式,不建議使用client模式。
spark-submit --help
方案二:直接引用OSS資源
當前節點可直接通過OSS REF的方式引用OSS資源,在運行EMR節點時,DataWorks會自動載入代碼中的OSS資源至本地使用。該方式常用於“需要在EMR任務中運行JAR依賴”、“EMR任務需依賴指令碼”等情境。
開發JAR資源。
代碼依賴準備。
您可前往EMR叢集,在叢集master節點的
/usr/lib/emr/spark-current/jars/路徑下查看您所需的代碼依賴。下面以Spark3.4.2版本為例,您需在開啟已建立的IDEA專案添加pom依賴並引用相關外掛程式。添加pom依賴
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.4.2</version> </dependency> <!-- Apache Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.4.2</version> </dependency> </dependencies>引用相關外掛程式
<build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <configuration> <recompileMode>incremental</recompileMode> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> </plugins> </build>編寫程式碼範例。
package com.aliyun.emr.example.spark import org.apache.spark.sql.SparkSession object SparkMaxComputeDemo { def main(args: Array[String]): Unit = { // 建立 SparkSession val spark = SparkSession.builder() .appName("HelloDataWorks") .getOrCreate() // 列印Spark版本 println(s"Spark version: ${spark.version}") } }將代碼打包成JAR檔案。
編輯儲存Scala代碼後,將Scala代碼打包成JAR檔案。樣本產生的JAR包為
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar。
上傳JAR資源。
完成代碼開發後,您需登入OSS管理主控台,單擊所在地區左側導覽列的Bucket列表。
單擊目標Bucket名稱,進入檔案管理頁面。
本文樣本使用的Bucket為
onaliyun-bucket-2。單擊建立目錄,建立JAR資源的存放目錄。
配置目錄名為
emr/jars,建立JAR資源的存放目錄。上傳JAR資源至JAR資源的存放目錄。
進入存放目錄,單擊上傳檔案,在待上傳檔案地區單擊掃描檔案,添加
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar檔案至Bucket,單擊上傳檔案。
引用JAR資源。
編輯引用JAR資原始碼。
在已建立的EMR Spark節點編輯頁面,編輯引用JAR資原始碼。
spark-submit --class com.aliyun.emr.example.spark.SparkMaxComputeDemo --master yarn ossref://onaliyun-bucket-2/emr/jars/SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar引用參數說明:
參數
參數說明
class啟動並執行主類全名稱。
masterSpark應用程式的運行模式。
ossref檔案路徑格式為
ossref://{endpoint}/{bucket}/{object}endpoint:OSS對外服務的訪問網域名稱。Endpoint為空白時,僅支援使用與當前訪問的EMR叢集同地區的OSS,即OSS的Bucket需要與EMR叢集所在地區相同。
Bucket:OSS用於儲存物件的容器,每一個Bucket有唯一的名稱,登入OSS管理主控台,可查看當前登入帳號下所有Bucket。
object:儲存在Bucket中的一個具體的對象(檔案名稱或路徑)。
運行EMR Spark節點任務。
編輯完成後您可單擊
 表徵圖,選擇您所建立的Serverless資源群組運行EMR Spark節點。待任務執行完成後,記錄控制台列印的
表徵圖,選擇您所建立的Serverless資源群組運行EMR Spark節點。待任務執行完成後,記錄控制台列印的applicationIds,例如application_1730367929285_xxxx。結果查看。
建立EMR Shell節點並在EMR Shell節點執行
yarn logs -applicationId application_1730367929285_xxxx命令查看運行結果:
(可選)配置進階參數
您可在節點進階設定處配置Spark特有屬性參數。更多Spark屬性參數設定,請參考Spark Configuration。不同類型EMR叢集可配置的進階參數存在部分差異,具體如下表。
DataLake叢集/自訂叢集:EMR on ECS
進階參數 | 配置說明 |
queue | 提交作業的調度隊列,預設為default隊列。 如果您在註冊EMR叢集至DataWorks工作空間時,配置了工作空間級的YARN資源隊列:
關於EMR YARN說明,詳情請參見隊列基礎配置,註冊EMR叢集時的隊列配置詳情請參見設定全域YARN資源隊列。 |
priority | 優先順序,預設為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支援用於資料開發環境測試回合流程。 |
其他 |
|
Hadoop叢集:EMR on ECS
進階參數 | 配置說明 |
queue | 提交作業的調度隊列,預設為default隊列。 如果您在註冊EMR叢集至DataWorks工作空間時,配置了工作空間級的YARN資源隊列:
關於EMR YARN說明,詳情請參見隊列基礎配置,註冊EMR叢集時的隊列配置詳情請參見設定全域YARN資源隊列。 |
priority | 優先順序,預設為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支援用於資料開發環境測試回合流程。 |
USE_GATEWAY | 設定本節點提交作業時,是否通過Gateway叢集提交。取值如下:
說明 如果本節點所在的叢集未關聯Gateway叢集,此處手動設定參數取值為 |
其他 |
|
Spark叢集:EMR ON ACK
進階參數 | 配置說明 |
queue | 不支援。 |
priority | 不支援。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支援用於資料開發環境測試回合流程。 |
其他 |
|
EMR Serverless Spark叢集
相關參數設定請參見提交Spark任務參數設定。
進階參數 | 配置說明 |
queue | 提交作業的調度隊列,預設為dev_queue隊列。 |
priority | 優先順序,預設為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支援用於資料開發環境測試回合流程。 |
SERVERLESS_RELEASE_VERSION | Spark引擎版本,預設使用管理中心的叢集管理中叢集配置的預設引擎版本。如需為不同任務設定不同的引擎版本,您可在此進行設定。 |
SERVERLESS_QUEUE_NAME | 指定資源隊列,預設使用管理中心的叢集管理中叢集配置的預設資源隊列。如有資源隔離和管理需求,可通過添加隊列實現。詳情請參見管理資源隊列。 |
其他 |
|
執行SQL任務
在工具列單擊
表徵圖,在參數對話方塊選擇已建立的調度資源群組,單擊運行。說明訪問公用網路或VPC網路環境的計算資源需要使用與計算資源測試連通性成功的調度資源群組。詳情請參見網路連通方案。
如果您後續執行任務需要修改使用的資源群組,您可單擊帶參運行
表徵圖,選擇需要更換的調度資源群組。使用EMR Spark節點查詢資料時,返回的查詢結果最大支援10000條資料,並且資料總量不能超過10MB。
單擊
表徵圖,儲存編寫的SQL語句。(可選)煙霧測試 (Smoke Test)。
如果您希望在開發環境進行煙霧測試 (Smoke Test),可在執行節點提交,或節點提交後執行,煙霧測試 (Smoke Test),操作詳情請參見執行煙霧測試 (Smoke Test)。
步驟三:配置節點調度
如您需要周期性執行建立的節點任務,可單擊節點編輯頁面右側的調度配置,根據業務需求配置該節點任務的調度資訊。配置詳情請參見任務調度屬性配置概述。
您需要設定節點的重跑屬性和依賴的上遊節點,才可以提交節點。
步驟四:發布節點任務
節點任務配置完成後,需執行提交發佈動作,提交發布後節點即會根據調度配置內容進行周期性運行。
單擊工具列中的
表徵圖,儲存節點。單擊工具列中的
表徵圖,提交節點任務。提交時需在提交對話方塊中輸入變更描述,並根據需要選擇是否在節點提交後執行程式碼檢閱。
說明您需設定節點的重跑屬性和依賴的上遊節點,才可提交節點。
程式碼檢閱可對任務的代碼品質進行把控,防止由於任務代碼有誤,未經審核直接發布上線後出現任務報錯。如進行程式碼檢閱,則提交的節點代碼必須通過評審人員的審核才可發布,詳情請參見程式碼檢閱。
如您使用的是標準模式的工作空間,任務提交成功後,需單擊節點編輯頁面右上方的發布,將該任務發布至生產環境執行,操作請參見發布任務。
後續操作
任務發布後將自動進入營運中心,您可在營運中心查看任務運行情況,或手動觸發任務執行。詳情請參見:營運中心。