業務資料隨著時間在不斷變化,如果您要對資料進行分析,則需要考慮如何儲存和管理資料。其中資料中隨著時間變更維度被稱為Slowly Changing Dimension(SCD)。E-MapReduce根據實際的數倉情境定義了基於固定粒度的緩慢變化維(G-SCD)。本文為您介紹G-SCD的具體解決方案及如何通過G-SCD處理維度資料。
背景資訊
SCD簡介
Slowly Changing Dimension(SCD)即緩慢變化維,是隨著時間變更維度。在資料倉儲中儲存和管理當前和歷史的資料,就需要考慮如何處理緩慢變化維,因此SCD被認為是跟蹤維度變化的關鍵ETL任務之一。
| 類型 | 描述 |
| 直接覆蓋(Type 1) | 直接覆蓋原值,不保留記錄。該方式無法分析歷史變化的資訊。 |
| 添加維度行(Type 2) | 保留所有歷史值。當屬性值有變化時,都會新增一條記錄,並且需要標記目前記錄有效,同時修改前一個有效記錄的有效性欄位。通常可以通過起始時間、截止時間標識記錄的有效性。 |
| 添加屬性列(Type 3) | 通過額外的欄位僅保留前一個版本的值。針對需要分析歷史資訊的屬性添加一列,記錄該屬性變化前的值,而本屬性欄位則記錄最新的值。 |
G-SCD概念和解決方案
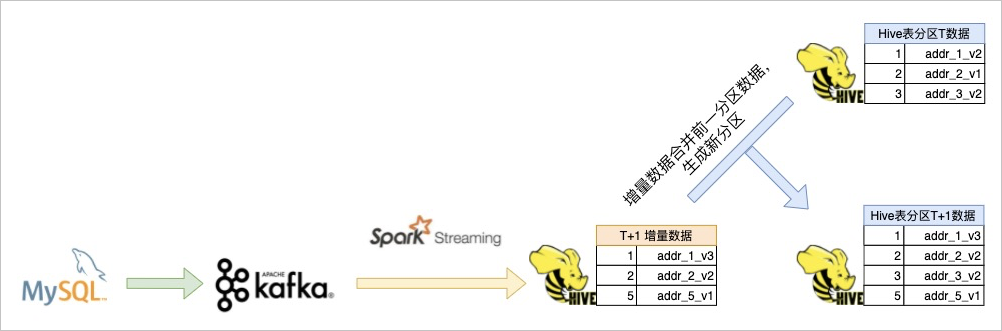
SCD處理維度新值的三種方式不能覆蓋業務的實際情境,所以E-MapReduce根據業務實際數倉情境提出了G-SCD(Based-Granularity Slowly Changing Dimension),即基於固定粒度(或者業務快照)的緩慢變化維。G-SCD按照固定的時間粒紋產生一份業務快照資料,其中時間粒紋可以是天、小時或者分鐘等,同時支援按照時間粒紋查詢對應時間段的資料。
| 解決方案 | 存在的問題 |
| 流式構建T+1時刻的增量資料表,和離線表的T時刻分區資料做合并,產生離線表T+1分區。 | 儲存資源浪費。 |
| 儲存離線的基礎資料表,每個業務時刻的增量資料獨立儲存,在查詢資料時合并基礎資料表和增量表。 | 查詢效能差。 |
| 方案 | 相同點 | 不同點 |
| SCD的Type 2方案 | 保留歷史所有資訊。 | 每次屬性值有變化,都會新增一條記錄。 |
| G-SCD on Delta Lake方案 | GSCD on Delta Lake在具體實現上不是通過新增記錄的形式保留資訊,而是藉助Delta Lake本身的Versioning特性,通過Time-Travel的能力追溯具體的快照資料。 |
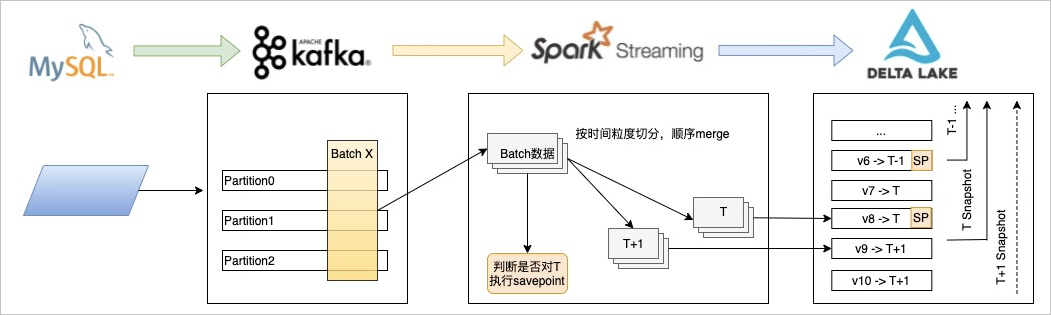
- 流批一體:不需要增量表和基礎資料表兩張表。
- 儲存資源節省:不需要按時間粒紋保留歷史全量資料。
- 查詢效能高:藉助Delta Lake的Optimize、Zorder和DataSkipping的能力,提升查詢效能。
- SQL使用相容性高:保留原來實現的SQL語句,和利用分區實現快照的方式一樣,可以使用類似的分區欄位查詢對應時間粒紋內的快照資料。
前提條件
已建立叢集,詳情請參見建立叢集。
使用限制
- 需要保證Kafka內同一個Partition內的資料嚴格有序。
- 資料按Key分區,保證同一Key必須落到同一個Kafka的Partition。
操作流程
- 步驟一:建立G-SCD表建立G-SCD表,按照要求配置需要的參數。
- 步驟二:處理資料您可以根據業務資料的情況,選擇使用流式寫入或者批量寫入的方式進行資料的處理。樣本中通過兩次批量寫入代替流式寫入的方式類比G-SCD on Delta Lake的資料處理。
- 步驟三:驗證資料寫入結果通過查詢語句,驗證資料是否寫入成功。
步驟一:建立G-SCD表
CREATE TABLE target (id Int, body String, dt string)
USING delta
TBLPROPERTIES (
"delta.gscdTypeTable" = "true",
"delta.gscdGranularity" = "1 day",
"delta.gscdColumnFormat" = "yyyy-MM-dd",
"delta.gscdColumn" = "dt"
);| 參數 | 說明 |
| delta.gscdTypeTable | 定義當前表是否為G-SCD Delta Lake表,本文樣本需要設定為true。當該值設定為false時則表示該表為普通表,無法使用G-SCD的相關功能。 |
| delta.gscdGranularity | 業務快照粒度,例如:1 day、1 hour、30 minutes等。 |
| delta.gscdColumnFormat | 業務快照粒度的格式,支援格式如下:
|
| delta.gscdColumn | 定義查詢時,表示業務快照版本的欄位。當前欄位也需要在Schema內定義,並且必須為String類型。 |
步驟二:處理資料
您可以根據業務資料的情況,選擇使用流式寫入或者批量寫入的方式進行資料的處理。
- 流式寫入
CREATE TABLE IF NOT EXISTS gscd_kafka_table USING kafka OPTIONS( kafka.bootstrap.servers = 'localhost:9092', subscribe = 'xxxxxx' ); CREATE SCAN gscd_stream ON gscd_kafka_table USING STREAM OPTIONS ( `watermark.time` = 'floor(ts/1000)' --- 定義源頭watermark時間運算式,單位為秒。 ); CREATE STREAM delta_job OPTIONS ( triggerType = 'ProcessingTime', checkpointLocation = '/path/to/checkpoint' ) MERGE INTO gscd_target_table AS target USING ( SELECT *, from_unixtime(ts/1000, 'yyyy-MM-dd') AS dt FROM gscd_stream ) AS source ON source.id = target.id AND target.dt = source.dt WHEN MATCHED THEN update set * WHEN NOT MATCHED THEN insert *;重要 在上述SQL語句中,watermark的使用原理及注意事項如下:- 為了在流作業中自動觸發Savepoint,需要在
CREATE SCAN語句中指定watermark時間運算式。 - watermark表示流作業源頭的時間值,單位為秒。
- watermark時間會產生作為delta.gscdColumn欄位的值,當watermark時間達到delta.gscdGranularity邊界時(樣本中定義的為1 day),會自動觸發Savepoint。
- watermark時間要求在同一個Partition內遞增有序。
- 為了在流作業中自動觸發Savepoint,需要在
- 批量寫入
一般情境下,通過流式寫入已經可以滿足。但當資料異常時,G-SCD on Delta Lake的方案同時提供了復原Rollback的能力,並可以使用批量離線寫入修複資料。修複完成後,執行Savepoint,持續保留當前Version。
MERGE INTO GSCD("2021-01-01") gscd_target_table USING gscd_source_table ON source.id = target.id WHEN MATCHED THEN UPDATE SET body = source.body WHEN NOT MATCHED THEN INSERT(id, body) VALUES(source.id, source.body);在上述SQL語句中,
GSCD ("2021-01-01")的文法表示要寫入的資料所屬的業務粒度值。重要 批量寫入不支援同一個作業寫入多個業務粒度資料。如果存在這種情況,需要提前進行拆分。
為了協助您快速使用G-SCD處理維度資料,本文給出詳細的樣本,具體操作步驟如下。
- 類比來源資料。
CREATE TABLE s1 (id Int, body String) USING delta; CREATE TABLE s2 (id Int, body String) USING delta; INSERT INTO s1 VALUES (1, "addr_1_v1"), (2, "addr_2_v1"), (3, "addr_3_v1"); INSERT INTO s2 VALUES (2, "addr_2_v2"), (4, "addr_1_v1"); - 通過使用兩次批量寫入,代替流式寫入的方式類比G-SCD on Delta Lake的資料處理。
- 第一次批量寫入,然後建立對應時間粒紋的Savepoint。
-- 第一次批量寫入。 MERGE INTO GSCD ("2021-01-01") target as target USING s1 as source ON source.id = target.id WHEN MATCHED THEN UPDATE SET body = source.body WHEN NOT MATCHED THEN INSERT(id, body) VALUES(source.id, source.body); -- 建立2021-01-01的Savepoint。 CREATE SAVEPOINT target GSCD('2021-01-01'); - 第二次批量寫入,然後建立對應時間粒紋的Savepoint。
-- 第二次批量寫入。 MERGE INTO GSCD ("2021-01-02") target as target USING s2 as source ON source.id = target.id WHEN MATCHED THEN UPDATE SET body = source.body WHEN NOT MATCHED THEN INSERT(id, body) VALUES(source.id, source.body); -- 建立2021-01-02的Savepoint。 CREATE SAVEPOINT target GSCD('2021-01-02');
- 第一次批量寫入,然後建立對應時間粒紋的Savepoint。
步驟三:驗證資料寫入結果
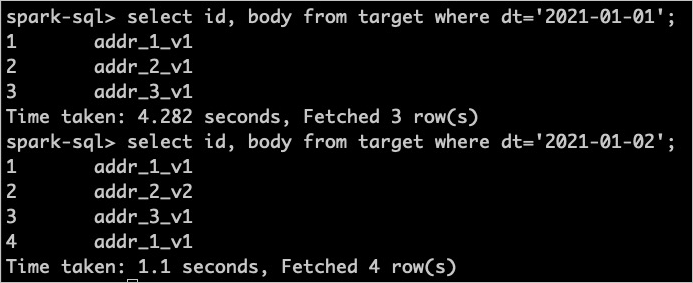
通過查詢語句,驗證資料是否寫入成功。查詢在步驟二:處理資料樣本中兩次批量寫入的資料,具體操作如下。
- 執行以下命令,查詢第一次批量寫入的資料。
select id, body from target where dt = '2021-01-01';重要- 查詢資料時,可以使用正常的SQL文法。
- 查詢資料時,必須指定gscdColumn欄位作為查詢條件,並且必須為
=運算式,例如dt = '2021-01-01'。
- 執行以下命令,查詢第二次批量寫入的資料。
select id, body from target where dt = '2021-01-02';如果能夠查詢到寫入的資料,則表明資料寫入成功。執行上述查詢命令後,返回結果如下圖所示。