EMR-2.4.0之前版本,所有叢集採用的是叢集本地的MySQL資料庫作為Hive中繼資料庫;EMR-2.4.0及後續版本,E-MapReduce(簡稱EMR)支援統一的高可靠的Hive中繼資料庫。
背景資訊
因為中繼資料庫需要使用公網IP來串連,所以叢集必須要有公網IP,同時請不要隨意的切換公網IP地址,防止對應的資料庫白名單失效。
如果是本地的中繼資料庫,您可以使用叢集上的Hue工具來管理。
- 總容量:200MiB。
- 小時query數量限制:720000/h。
- 小時update數量限制:144000/h。
注意事項
EMR Hive統一中繼資料將逐步下線,不再進行維護升級,需要遷移到新版統一中繼資料DLF中,遷移詳情請參見EMR中繼資料遷移公告。EMR新使用者請選擇資料湖構建(DLF)統一中繼資料。
介紹
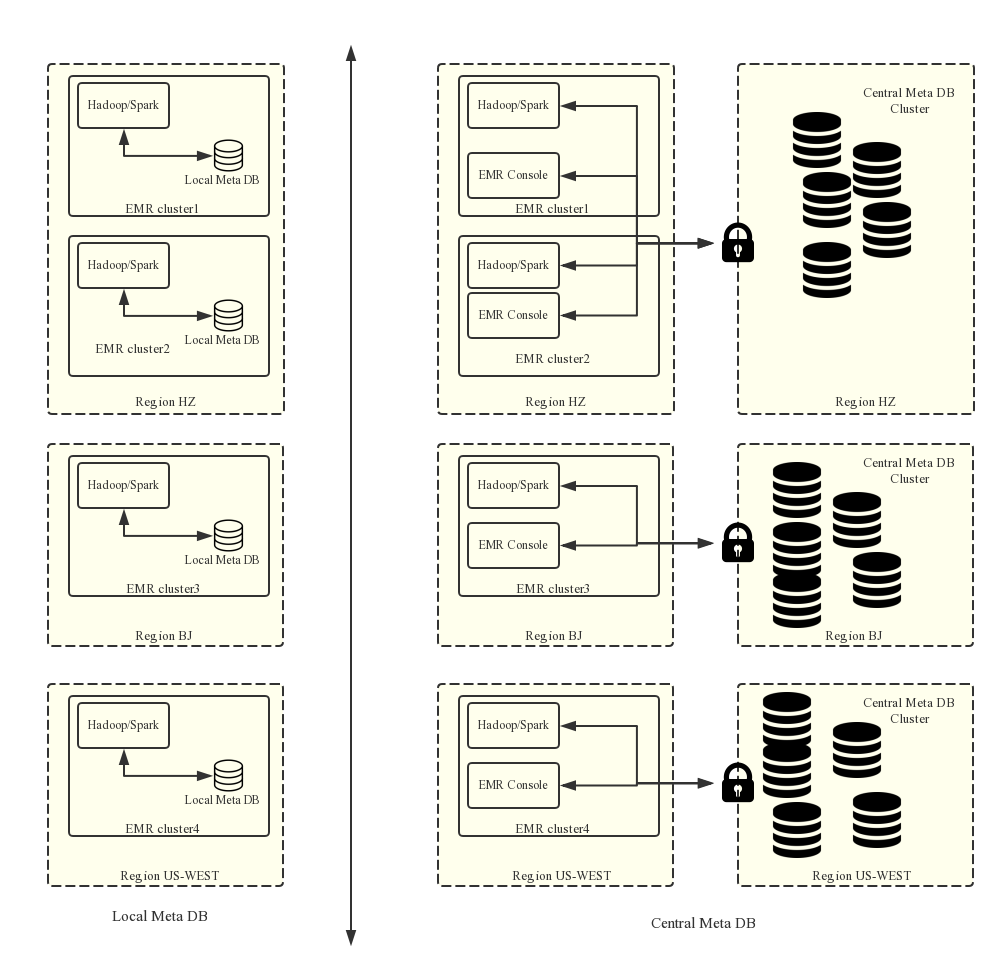
- 持久化的中繼資料存放區。
支援統一中繼資料之前,中繼資料都是在叢集內部的MySQL資料庫,中繼資料會隨著叢集的釋放而丟失,特別是EMR提供了靈活按量模式,叢集可以按需建立用完就釋放。如果您需要保留現有的中繼資料資訊,必須登入叢集手動將中繼資料資訊匯出。
支援統一中繼資料之後,釋放叢集不會清理中繼資料資訊。所以,在任何時候刪除OSS上或者叢集HDFS上資料(包括釋放叢集操作)的時候,需要先確認該資料對應的中繼資料已經刪除(即要刪掉資料對應的表和資料庫),否則中繼資料庫中可能出現一些髒資料。
- 計算儲存分離。
EMR上可以支援將資料存放在阿里雲OSS中,在巨量資料量的情況下將資料存放區在OSS上會大大降低使用的成本,EMR叢集主要用來作為計算資源,在計算完成之後可以隨時釋放,資料在OSS上,同時也不用再考慮中繼資料遷移的問題。
- 資料共用。
使用統一的中繼資料庫,如果您的所有資料都存放在OSS之上,則不需要做任何中繼資料的遷移和重建,所有叢集都是可以直接存取資料,這樣每個EMR叢集可以做不同的業務,但是可以很方便地實現資料的共用。
建立使用統一中繼資料的叢集
- 頁面方式。
建立叢集時,在基礎配置頁面,選中統一meta資料庫。
- API方式。 使用CreateClusterV2建立叢集,詳情請參見CreateClusterV2。說明 需指定參數:useLocalMetaDb=false。
表管理
詳細請參見Hive中繼資料基本操作。
查看中繼資料庫資訊
- 進入中繼資料管理頁面。
- 登入阿里雲E-MapReduce控制台。
- 在頂部功能表列處,根據實際情況選擇地區和資源群組。
- 單擊上方的中繼資料管理頁簽。
- 在左側導覽列,單擊中繼資料庫資訊。
您可以查看當前RDS的用量和使用限制。
