您可以通過Kafka表引擎匯入資料至ClickHouse叢集。本文為您介紹如何將Kafka中的資料匯入至ClickHouse叢集。
前提條件
- 已建立DataFlow叢集,且選擇了Kafka服務,詳情請參見建立叢集。
- 已建立ClickHouse叢集,詳情請參見建立ClickHouse叢集。
使用限制
DataFlow叢集和ClickHouse叢集需要在同一VPC下。
文法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host1:port1,host2:port2',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format';| 參數 | 描述 |
db | 資料庫名。 |
table_name | 表名。 |
cluster | 叢集標識。 |
name1/name2 | 列名。 |
tyep1/type2 | 列的類型。 |
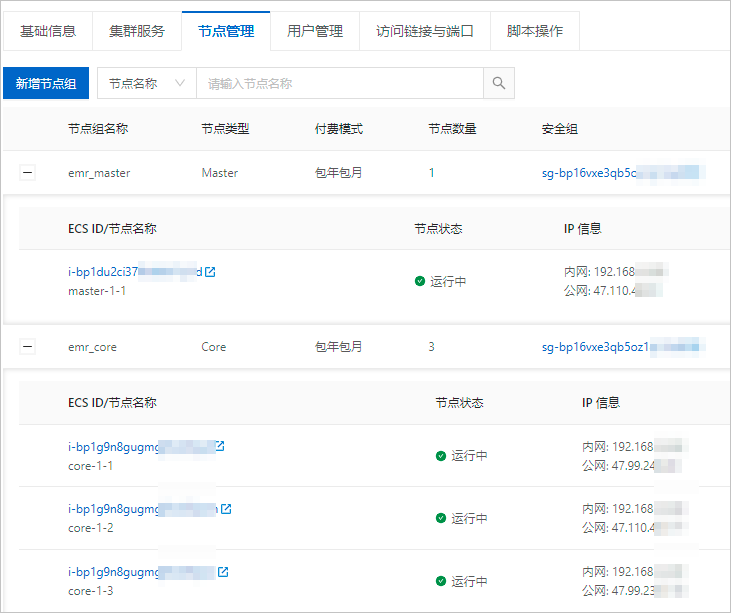
kafka_broker_list | Kafka Broker的地址及連接埠。 DataFlow叢集所有節點的內網IP地址及連接埠,您可以在EMR控制台的節點管理頁面查看。 |
kafka_topic_list | 訂閱的Topic名稱。 |
kafka_group_name | Kafka consumer的分組名稱。 |
kafka_format | 資料的類型。例如,CSV和JSONEachRow等,詳細資料請參見Formats for Input and Output Data。 |
樣本
- 在ClickHouse叢集中執行以下操作。
- 使用SSH方式登入ClickHouse叢集,詳情請參見登入叢集。
- 執行如下命令,進入ClickHouse用戶端。
clickhouse-client -h core-1-1 -m說明本樣本登入core-1-1節點,如果您有多個Core節點,可以登入任意一個節點。
- 執行如下命令,建立資料庫kafka。
CREATE DATABASE IF NOT EXISTS kafka ON CLUSTER cluster_emr;說明 資料庫名您可以自訂。本文樣本中的cluster_emr是叢集預設的標識,如果您修改過,請填寫正確的叢集標識,您也可以在EMR控制台ClickHouse服務的配置頁面,在搜尋地區搜尋clickhouse_remote_servers參數查看。 - 執行如下命令,建立Kafka表。
CREATE TABLE IF NOT EXISTS kafka.consumer ON CLUSTER cluster_emr ( `uid` UInt32, `date` DateTime, `skuId` UInt32, `order_revenue` UInt32 ) ENGINE = Kafka() SETTINGS kafka_broker_list = '192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092', kafka_topic_list = 'clickhouse_test', kafka_group_name = 'clickhouse_test', kafka_format = 'CSV'; - 執行如下命令,建立資料庫product。
CREATE DATABASE IF NOT EXISTS product ON CLUSTER cluster_emr; - 執行以下命令,建立本地表。
CREATE TABLE IF NOT EXISTS product.orders ON CLUSTER cluster_emr ( `uid` UInt32, `date` DateTime, `skuId` UInt32, `order_revenue` UInt32 ) Engine = ReplicatedMergeTree('/cluster_emr/product/orders/{shard}', '{replica}') PARTITION BY toYYYYMMDD(date) ORDER BY toYYYYMMDD(date); - 執行以下命令,建立分布式表。
CREATE TABLE IF NOT EXISTS product.orders_all ON CLUSTER cluster_emr ( `uid` UInt32, `date` DateTime, `skuId` UInt32, `order_revenue` UInt32 ) Engine = Distributed(cluster_emr, product, orders, rand()); - 執行以下命令,建立MATERIALIZED VIEW自動導資料。
CREATE MATERIALIZED VIEW IF NOT EXISTS product.kafka_load ON CLUSTER cluster_emr TO product.orders AS SELECT * FROM kafka.consumer;
- 在DataFlow叢集中執行以下操作。
- 使用SSH方式登入DataFlow叢集,詳情請參見登入叢集。
- 在DataFlow叢集的命令列視窗,執行如下命令運行Kafka的生產者。
/usr/lib/kafka-current/bin/kafka-console-producer.sh --broker-list 192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092 --topic clickhouse_test - 執行以下命令,輸入測試資料。
38826285,2021-08-03 10:47:29,25166907,27 10793515,2021-07-31 02:10:31,95584454,68 70246093,2021-08-01 00:00:08,82355887,97 70149691,2021-08-02 12:35:45,68748652,1 87307646,2021-08-03 19:45:23,16898681,71 61694574,2021-08-04 23:23:32,79494853,35 61337789,2021-08-02 07:10:42,23792355,55 66879038,2021-08-01 16:13:19,95820038,89
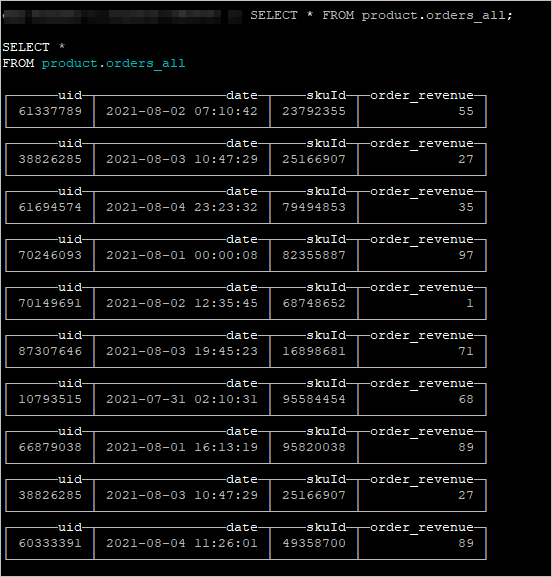
- 在ClickHouse命令視窗中,執行以下命令,可以查看從Kafka中匯入至ClickHouse叢集的資料。
您可以校正查詢到的資料與來源資料是否一致。
SELECT * FROM product.orders_all;