Hadoop是由Apache基金會使用Java語言開發的分布式開源軟體架構,本文介紹如何在Linux作業系統的ECS執行個體上快速搭建Hadoop分布式和偽分布式環境。
背景資訊
Apache Hadoop軟體庫是一個架構,它允許通過簡單的編程模型在由多台電腦群組成的叢集上對大規模資料集進行分散式處理。該架構設計能夠從單個伺服器擴充到數千台機器,每台機器都提供本地計算和儲存能力。Hadoop並不依賴硬體來實現高可用性,而是將其自身設計為能夠在應用程式層檢測並處理故障,因此能在可能各自存在故障風險的電腦叢集之上,提供高度可用的服務。
Hadoop的核心組件是HDFS(Hadoop Distributed File System)和MapReduce:
HDFS:是一個Distributed File System,可用於應用程式資料的分布式儲存和讀取。
MapReduce:是一個分散式運算架構,MapReduce的核心思想是把計算任務分配給叢集內的伺服器執行。通過對計算任務的拆分(Map計算和Reduce計算),再根據任務調度器(JobTracker)對任務進行分散式運算。
特性 | 偽分布式模式 | 完全分布式模式 |
節點數量 | 單節點(所有服務在同一台機器上)。 | 多節點(服務分布在多台機器上)。 |
資源使用率 | 使用單台機器的資源。 | 充分利用多台機器的計算和儲存資源。 |
容錯性 | 容錯性低,單點故障會導致整個叢集不可用。 | 容錯性高,支援資料複製和高可用性配置。 |
應用情境 |
|
|
快速部署
您可以單擊一鍵運行進入Terraform Explorer查看並執行Terraform代碼,從而實現自動化地在ECS執行個體中搭建Hadoop環境。
前提條件
搭建Hadoop環境時,已有的ECS執行個體必須滿足以下條件:
環境 | 要求 | |
執行個體 | 偽分布式 | 1台執行個體 |
分布式 | 3台及以上執行個體 說明 建議您將執行個體加入到高可用策略的部署集中,可以提高應用的高可用性和容災能力,便於Hadoop叢集的管理。 | |
作業系統 | Linux | |
公網IP | 執行個體已指派公網IP地址或綁定Elastic IP Address(EIP)。 | |
執行個體安全性群組 | 允許存取22、443、8088(Hadoop YARN預設的Web UI連接埠)、9870(Hadoop NameNode預設的Web UI連接埠)。 說明 如果部署分布式環境,還需允許存取Hadoop Secondary Namenode的自訂Web UI連接埠,現定義連接埠為9868。 具體操作,請參見管理安全性群組規則。 | |
Java開發套件(JDK) 本文使用的版本為Hadoop 3.2.4和Java 8,如您使用其他版本,請參考Hadoop官網指南。更多資訊,請參見Hadoop Java Versions。 | Hadoop版本 | Java版本 |
Hadoop 3.3 | Java 8和Java 11 | |
Hadoop 3.0.x~3.2.x | Java 8 | |
Hadoop 2.7.x~2.10.x | Java 7和Java 8 | |
操作步驟
分布式
在部署Hadoop前需對節點進行規劃。以三台執行個體為例,hadoop001節點為master節點,hadoop002和hadoop003節點為worker節點。
功能組件 | hadoop001 | hadoop002 | hadoop003 |
HDFS |
| DataNode |
|
YARN | NodeManager |
| NodeManager |
步驟一:安裝JDK。
所有節點均需安裝JDK環境。
以普通使用者遠端連線已建立的ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
重要出於系統安全和穩定性考慮,Hadoop官方不推薦使用root使用者來啟動Hadoop服務,直接使用root使用者會因為許可權問題無法啟動Hadoop。您可以通過非root使用者身份啟動Hadoop服務,例如
ecs-user使用者等。執行以下命令,下載JDK 1.8安裝包。
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz執行以下命令,解壓下載的JDK 1.8安裝包。
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz執行以下命令,移動並重新命名JDK安裝包。
本樣本中將JDK安裝包重新命名為
java8,您可以根據需要使用其他名稱。sudo mv java-se-8u41-ri/ /usr/java8執行以下命令,配置Java環境變數。
如果您將JDK安裝包重新命名為其他名稱,需將以下命令中的
java8替換為實際的名稱。sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile執行以下命令,查看JDK是否成功安裝。
java -version返回如下資訊,表示JDK已安裝成功。
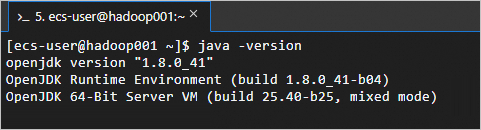
步驟二:配置SSH免密登入。
所有執行個體均需執行此操作。
通過設定SSH免密登入,可以讓這些節點之間實現無縫串連,無需每次都輸入密碼驗證身份,從而使得Hadoop叢集的管理和維護變得更加便捷高效。
配置主機名稱和通訊。
sudo vim /etc/hosts添加所有執行個體的資訊
<主私網IP 主機名稱>到/etc/hosts檔案中。如下:主私網IP hadoop001 主私網IP hadoop002 主私網IP hadoop003執行以下命令,建立公開金鑰和私密金鑰。
ssh-keygen -t rsa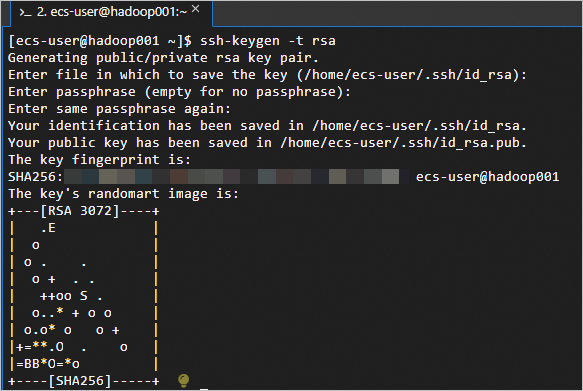
執行
ssh-copy-id <主機名稱>,替換主機名稱為正確的名稱。如下:hadoop001上依次執行ssh-copy-id hadoop001、ssh-copy-id hadoop002、ssh-copy-id hadoop003。執行每一個命令後需要輸入yes和對應ECS執行個體的ID密碼。ssh-copy-id hadoop001 ssh-copy-id hadoop002 ssh-copy-id hadoop003返回如下資訊,表示免密登入配置成功。
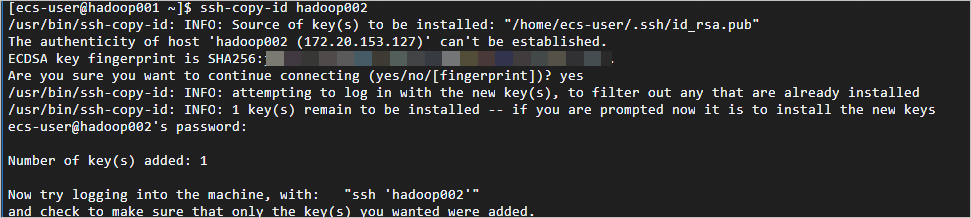
步驟三:安裝Hadoop。
以下命令需在所有執行個體中執行。
執行以下命令,下載Hadoop安裝包。
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz執行以下命令,將Hadoop安裝包解壓至
/opt/hadoop。sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop執行以下命令,配置Hadoop環境變數。
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile執行以下命令,修改設定檔
yarn-env.sh和hadoop-env.sh。sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh'執行以下命令,測試Hadoop是否安裝成功。
hadoop version返回如下資訊,表示Hadoop已安裝成功。
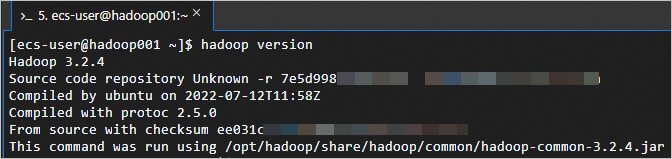
步驟四:配置Hadoop。
在所有節點上修改Hadoop的設定檔。
修改Hadoop設定檔
core-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/core-site.xml在
<configuration></configuration>節點內,插入如下內容。<!--指定namenode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:8020</value> </property> <!--用來指定使用hadoop時產生檔案的存放目錄--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/data</value> </property> <!--配置HDFS網頁登入使用的靜態使用者為hadoop--> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property>
修改Hadoop設定檔
hdfs-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml在
<configuration></configuration>節點內,插入如下內容。<!-- namenode web 端訪問地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop001:9870</value> </property> <!-- secondary namenode web 端訪問地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop003:9868</value> </property>
修改Hadoop設定檔
yarn-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/yarn-site.xml在
<configuration></configuration>節點內,插入如下內容。<!--NodeManager擷取資料的方式是shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定Yarn(ResourceManager)的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop002</value> </property> <!--指定NodeManager允許傳遞給容器的環境變數白名單--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
修改Hadoop設定檔
mapred-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/mapred-site.xml在
<configuration></configuration>節點內,插入如下內容。<!--告訴hadoop將MR(Map/Reduce)運行在YARN上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改Hadoop設定檔
workers。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/workers在檔案
workers內,插入執行個體資訊。hadoop001 hadoop002 hadoop003
步驟五:啟動Hadoop。
執行以下命令,初始化
namenode。警告僅在第一次啟動時需要初始化
namenode。三台執行個體均需執行。hadoop namenode -format啟動Hadoop。
重要出於系統安全和穩定性考慮,Hadoop官方不推薦使用root使用者來啟動Hadoop服務,直接使用root使用者會因為許可權問題無法啟動Hadoop。您可以通過非root使用者身份啟動Hadoop服務,例如
ecs-user使用者等。如果您一定要使用root使用者啟動Hadoop服務,請在瞭解Hadoop許可權控制及相應風險之後,修改以下設定檔。
請注意:使用root使用者啟動Hadoop服務會帶來嚴重的安全風險,包括但不限於資料泄露、惡意軟體更容易獲得系統最高許可權、意料之外的許可權問題或行為。更多許可權說明,請參見Hadoop官方文檔。
一般情況下,以下設定檔位於
/opt/hadoop/sbin目錄下。在
start-dfs.sh和stop-dfs.sh兩個檔案中添加以下參數。HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root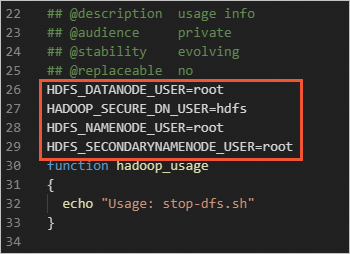
在
start-yarn.sh和stop-yarn.sh兩個檔案中添加以下參數。YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root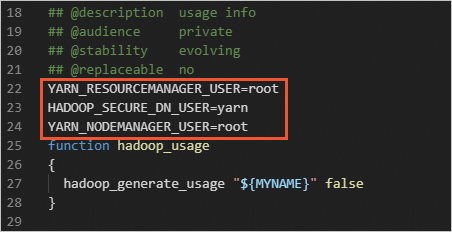
在
hadoop001上執行start-dfs.sh指令碼,啟動HDFS服務。這個指令碼會啟動NameNode、SecondaryNameNode和DataNode等組件,從而啟動HDFS服務。
start-dfs.sh執行命令
jps回顯資訊如下所示時,表示HDFS服務已啟動。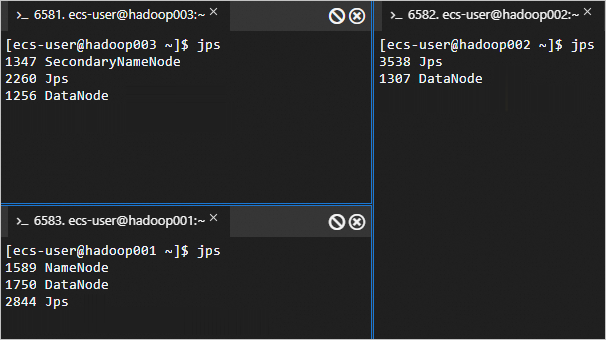
在
hadoop002上執行start-yarn.sh指令碼,啟動YARN服務。這個指令碼會啟動ResourceManager、NodeManager等組件,從而啟動YARN服務。
start-yarn.sh回顯資訊如下所示時,表示YARN服務已啟動。
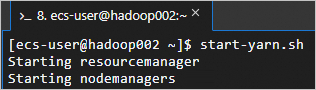
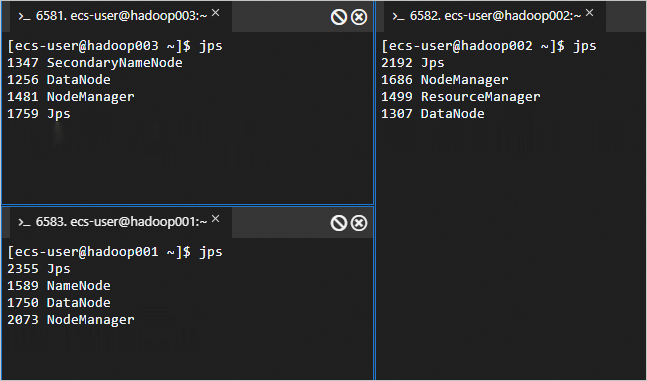
在三台節點上執行以下命令,可以查看成功啟動的進程。
jps成功啟動的進程如下所示。
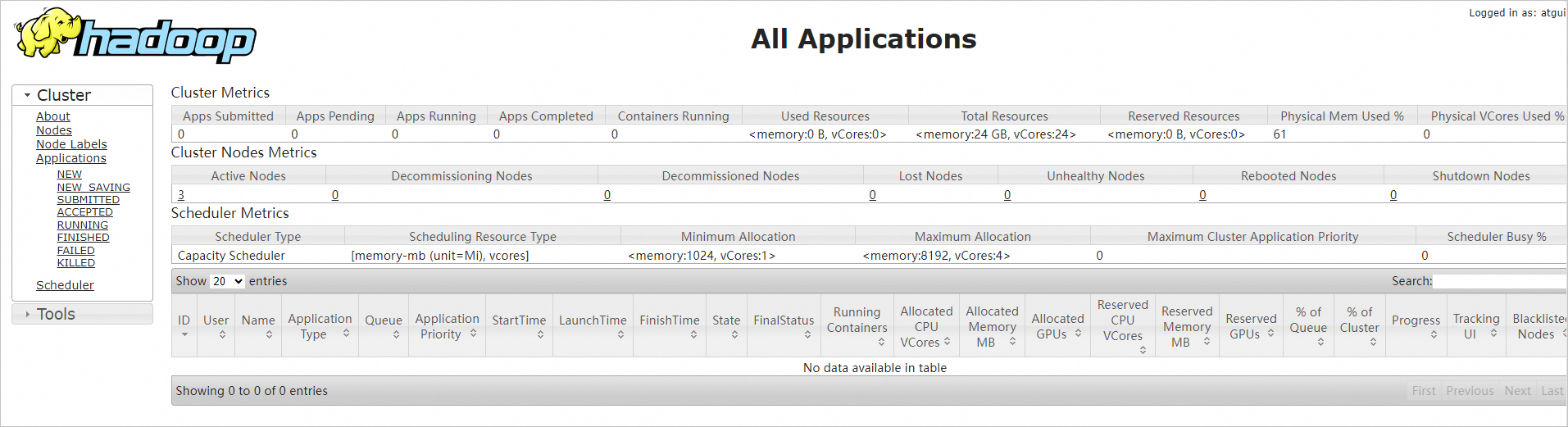
在本地瀏覽器地址欄輸入
http://<hadoop002 ECS公網IP>:8088,訪問YARN的Web UI介面。通過該介面可以查看整個叢集的資源使用方式、應用程式狀態(比如MapReduce作業)、隊列資訊等。
重要需確保在ECS執行個體所在安全性群組的入方向中允許存取Hadoop YARN所需的8088連接埠,否則無法訪問。具體操作,請參見添加安全性群組規則。
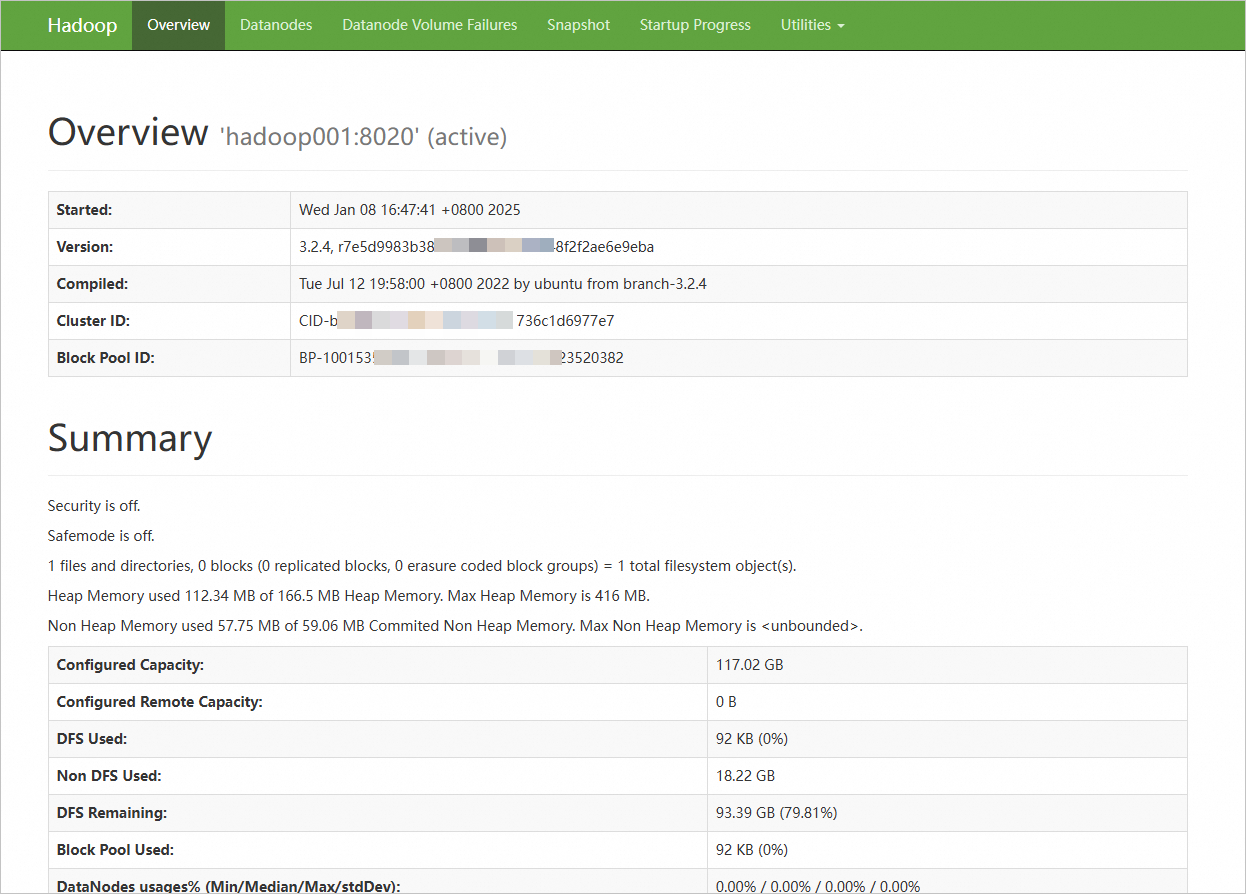
在本地瀏覽器地址欄輸入
http://<hadoop001 ECS公網IP>:9870,訪問NameNode的Web UI介面;輸入http://<hadoop003 ECS公網IP>:9868,訪問SecondaryNameNode的Web UI介面。該介面提供了有關HDFS檔案系統狀態、叢集健康情況、活動節點列表、NameNode日誌等資訊。
顯示如下介面,則表示Hadoop分布式環境已搭建完成。
重要需確保在ECS執行個體所在安全性群組的入方向中允許存取Hadoop NameNode所需9870連接埠,否則無法訪問。具體操作,請參見添加安全性群組規則。
偽分布式
步驟一:安裝JDK。
以普通使用者遠端連線已建立的ECS執行個體。
具體操作,請參見使用Workbench工具以SSH協議登入Linux執行個體。
重要出於系統安全和穩定性考慮,Hadoop官方不推薦使用root使用者來啟動Hadoop服務,直接使用root使用者會因為許可權問題無法啟動Hadoop。您可以通過非root使用者身份啟動Hadoop服務,例如
ecs-user使用者等。執行以下命令,下載JDK 1.8安裝包。
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz執行以下命令,解壓下載的JDK 1.8安裝包。
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz執行以下命令,移動並重新命名JDK安裝包。
本樣本中將JDK安裝包重新命名為
java8,您可以根據需要使用其他名稱。sudo mv java-se-8u41-ri/ /usr/java8執行以下命令,配置Java環境變數。
如果您將JDK安裝包重新命名為其他名稱,需將以下命令中的
java8替換為實際的名稱。sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile" sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile' source /etc/profile執行以下命令,查看JDK是否成功安裝。
java -version返回如下資訊,表示JDK已安裝成功。
步驟二:配置SSH免密登入。
單節點也需要配置SSH免密登入;否則,在嘗試啟動NameNode和DataNode時,會出現許可權拒絕錯誤。
執行以下命令,建立公開金鑰和私密金鑰。
ssh-keygen -t rsa執行以下命令,將公開金鑰添加到
authorized_keys檔案中。cd .ssh cat id_rsa.pub >> authorized_keys
步驟三:安裝Hadoop。
執行以下命令,下載Hadoop安裝包。
wget http://mirrors.cloud.aliyuncs.com/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz執行以下命令,將Hadoop安裝包解壓至
/opt/hadoop。sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/ sudo mv /opt/hadoop-3.2.4 /opt/hadoop執行以下命令,配置Hadoop環境變數。
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile" sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile" source /etc/profile執行以下命令,修改設定檔
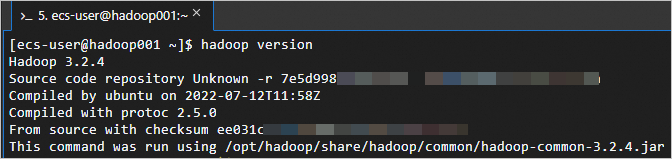
yarn-env.sh和hadoop-env.sh。sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh' sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh'執行以下命令,測試Hadoop是否安裝成功。
hadoop version返回如下資訊,表示Hadoop已安裝成功。
步驟四:配置Hadoop
修改Hadoop設定檔
core-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/core-site.xml在
<configuration></configuration>節點內,插入如下內容。<property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/tmp</value> <description>location to store temporary files</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
修改Hadoop設定檔
hdfs-site.xml。執行以下命令,進入編輯頁面。
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml在
<configuration></configuration>節點內,插入如下內容。<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/tmp/dfs/data</value> </property>
步驟五:啟動Hadoop
執行以下命令,初始化
namenode。hadoop namenode -format啟動Hadoop。
重要出於系統安全和穩定性考慮,Hadoop官方不推薦使用root使用者來啟動Hadoop服務,直接使用root使用者會因為許可權問題無法啟動Hadoop。您可以通過非root使用者身份啟動Hadoop服務,例如
ecs-user使用者等。如果您一定要使用root使用者啟動Hadoop服務,請在瞭解Hadoop許可權控制及相應風險之後,修改以下設定檔。
請注意:使用root使用者啟動Hadoop服務會帶來嚴重的安全風險,包括但不限於資料泄露、惡意軟體更容易獲得系統最高許可權、意料之外的許可權問題或行為。更多許可權說明,請參見Hadoop官方文檔。
一般情況下,以下設定檔位於
/opt/hadoop/sbin目錄下。在
start-dfs.sh和stop-dfs.sh兩個檔案中添加以下參數。HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root在
start-yarn.sh和stop-yarn.sh兩個檔案中添加以下參數。YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
執行以下命令,啟動HDFS服務。
這個指令碼會啟動NameNode、SecondaryNameNode和DataNode等組件,從而啟動HDFS服務。
start-dfs.sh回顯資訊如下所示時,表示HDFS服務已啟動。
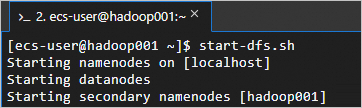
執行以下命令,啟動YARN服務。
這個指令碼會啟動ResourceManager、NodeManager和ApplicationHistoryServer等組件,從而啟動YARN服務。
start-yarn.sh回顯資訊如下所示時,表示YARN服務已啟動。
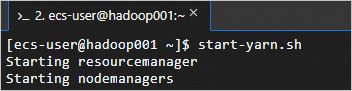
執行以下命令,可以查看成功啟動的進程。
jps成功啟動的進程如下所示。
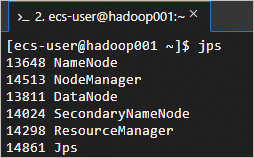
在本地瀏覽器地址欄輸入
http://<ECS公網IP>:8088,訪問YARN的Web UI介面。通過該介面可以查看整個叢集的資源使用方式、應用程式狀態(比如MapReduce作業)、隊列資訊等。
重要需確保在ECS執行個體所在安全性群組的入方向中允許存取Hadoop YARN所需的8088連接埠,否則無法訪問。具體操作,請參見添加安全性群組規則。
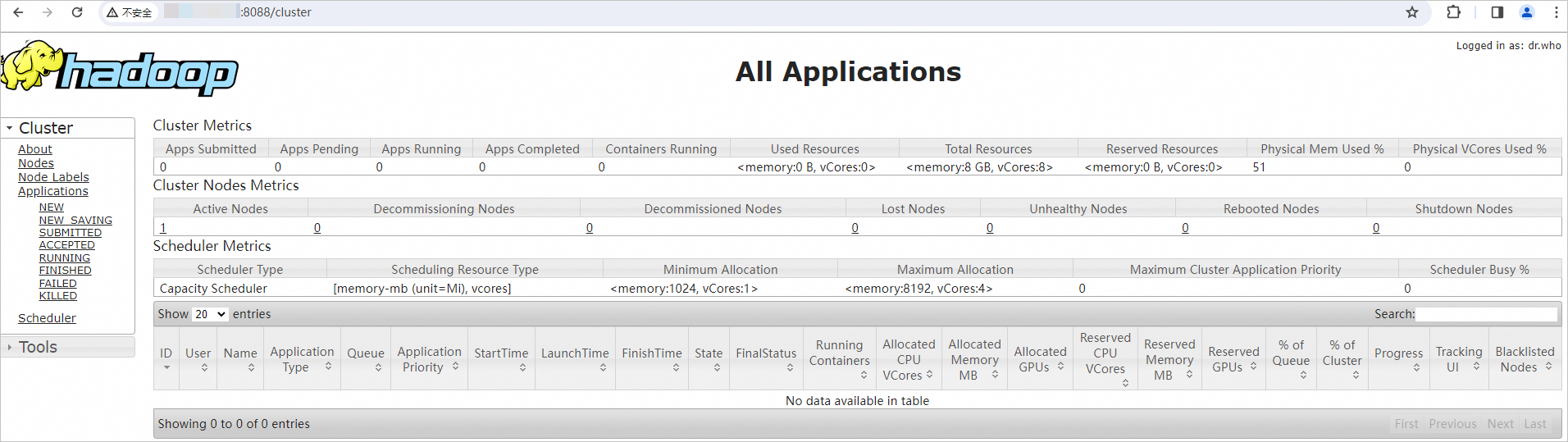
在本地瀏覽器地址欄輸入
http://<ECS公網IP>:9870,訪問NameNode的Web UI介面。該介面提供了有關HDFS檔案系統狀態、叢集健康情況、活動節點列表、NameNode日誌等資訊。
顯示如下介面,則表示Hadoop分布式環境已搭建完成。
重要需確保在ECS執行個體所在安全性群組的入方向中允許存取Hadoop NameNode所需9870連接埠,否則無法訪問。具體操作,請參見添加安全性群組規則。

相關操作
建立快照一致性組
如果使用分布式Hadoop,建議您使用快照一致性組,可以確保Hadoop叢集資料的一致性和可靠性,為後續的資料處理和分析提供穩定的環境支援。具體操作,請參見建立快照一致性組。
Hadoop相關操作
HDFS組件操作,請參見HDFS常用命令。
相關文檔
如果您希望使用,在ECS上阿里雲已經整合的巨量資料環境,具體操作,請參見E-MapReduce快速入門。
如果您想要使用資料湖開發和治理的環境,具體操作,請參見DataWorks快速入門。