本文以部署DeepSeek-R1-Distill-Qwen-7B模型為例,示範如何使用資料緩衝快速部署DeepSeek-R1系列模型。通過資料緩衝提前拉取DeepSeek相關模型資料,然後在部署DeepSeek模型推理服務時直接掛載模型資料,可以免去在執行個體中拉模數型資料的等待時間,加速DeepSeek部署。
為什麼使用ECI部署DeepSeek
前提條件
您使用的VPC已綁定公網NAT Gateway,並配置SNAT條目允許該VPC或下屬交換器的資源可以訪問公網。
如果VPC沒有綁定公網NAT Gateway,您需要在建立資料緩衝和部署應用時綁定EIP,以便可以拉取公網資料。
準備運行環境
不同的DeepSeek模型對於運行環境的要求不同,本文以DeepSeek-R1-Distill-Qwen-7B模型為例。
規格推薦
需使用的GPU規格要求如下。ECI支援的GPU規格,請參見規格說明。
CPU:無嚴格限制
記憶體:>16 GiB
GPU:≥1
顯存:≥20 GB,例如A10(顯存過低可能會出現OOM)
軟體環境
大模型部署依賴的庫和配置較多,vLLM是目前一個主流的大模型推理引擎,本文使用vLLM進行推理服務的部署。ECI已經製作好了一個公用容器鏡像,您可以直接使用該鏡像或者將其作為基礎鏡像進行二次開發,鏡像地址為
registry.cn-hangzhou.aliyuncs.com/eci_open/vllm-openai:v0.7.2,鏡像大小約為16.5 GB。
步驟一:建立資料緩衝
首次使用時,需要提前建立資料緩衝,以免去在執行個體中拉模數型資料的等待時間,加速部署DeepSeek。
控制台
訪問HuggingFace,擷取模型ID。
本樣本使用DeepSeek-R1-Distill-Qwen-7B模型的main版本。在HuggingFace找到目標模型後,在模型詳情頁面頂部可以複製模型ID。
在頂部功能表列左上方處選擇地區。
在左側導覽列,單擊資料緩衝。
建立DeepSeek-R1-Distill-Qwen-7B的資料緩衝。
單擊建立資料緩衝。
完成資料緩衝參數配置。
本文使用的參數樣本如下,其中快取資料源為拉取DeepSeek-R1-Distill-Qwen-7B模型的固定配置,其他參數可自訂配置,更多資訊,請參見建立資料緩衝。
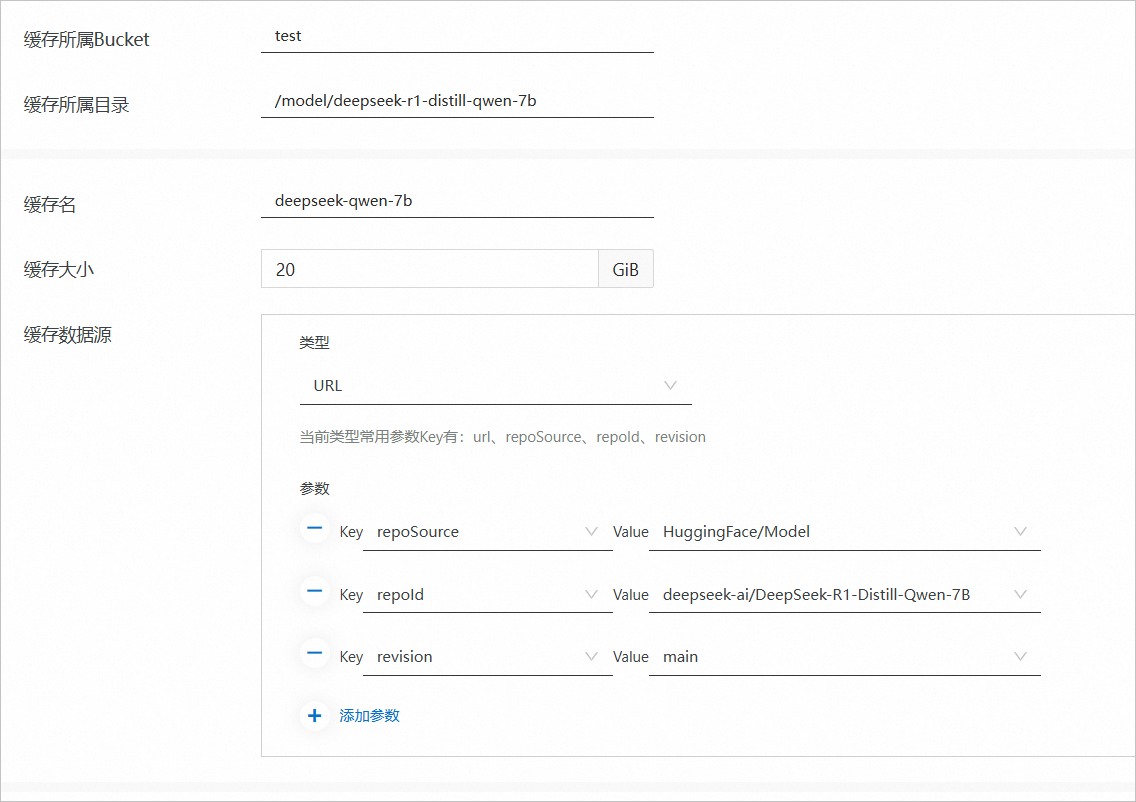
配置項
樣本值
緩衝所屬Bucket
test
緩衝所屬目錄
/model/deepseek-r1-distill-qwen-7b
緩衝名
deepseek-qwen-7b
緩衝大小
20 GiB
快取資料源
類型:URL
參數
repoSource:HuggingFace/Model
repoId:deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
revision:main
單擊確定。
查看資料緩衝狀態。
在資料緩衝頁面重新整理查看資料緩衝狀態,當狀態為Available時,表示可以使用該資料緩衝。阿里雲為DeepSeek-R1系列模型提供了熱載入能力,能實現資料緩衝秒級製作完成。
OpenAPI
訪問HuggingFace,擷取模型ID。
本樣本使用DeepSeek-R1-Distill-Qwen-7B模型的main版本。在HuggingFace找到目標模型後,在模型詳情頁面頂部可以複製模型ID。
建立DeepSeek-R1-Distill-Qwen-7B的資料緩衝。
調用CreateDataCache介面建立資料緩衝。建議您使用SDK,關於如何使用SDK,請參見SDK概覽。
Java SDK樣本如下,表示從HuggingFace拉取指定模型資料,儲存到名為
test的Bucket的/model/deepseek-r1-distill-qwen-7b目錄。CreateDataCacheRequest request = new CreateDataCacheRequest(); request.setName("deepseek-qwen-7b"); request.setBucket("test"); request.setPath("/model/deepseek-r1-distill-qwen-7b"); request.setVSwitchId("vsw-bp1*********"); request.setSecurityGroupId("sg-bp1*********"); CreateDataCacheRequest.DataSource dataSource = new CreateDataCacheRequest.DataSource(); dataSource.setType("URL"); HashMap<String, String> options = new HashMap<>(); options.put("repoId", "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"); options.put("repoSource", "HuggingFace/Model"); options.put("revision", "main"); dataSource.setOptions(options); request.setDataSource(dataSource);查詢資料緩衝狀態。
根據返回的資料緩衝ID調用DescribeDataCaches介面查詢資料緩衝資訊,當資料緩衝的狀態(DataCaches.Status)為Available時,表示可以使用該資料緩衝。
步驟二:部署DeepSeek模型推理服務
控制台
在Elastic Container Instance控制台的容器組頁面,單擊建立彈性容器組。
填寫執行個體相關配置資訊,然後單擊配置確認。
本文使用的參數樣本如下,執行個體使用GPU規格,並掛載了DeepSeek-R1-Distill-Qwen-7B模型。容器啟動後會運行
vllm serve /deepseek-r1-7b --tensor-parallel-size 1 --max-model-len 24384 --enforce-eager啟動vLLM推理引擎。重要當VPC已綁定公網NAT Gateway時,建立ECI執行個體時可以不綁定EIP。在執行個體建立完成後,您可以配置DNAT條目實現外部存取ECI執行個體。
設定精靈頁
配置地區
配置項
樣本值
基礎配置
容器組配置
指定規格
ecs.gn7i-c16g1.4xlarge
名稱
deepseek-r1-7b-server
20 GiB
說明由於啟動依賴的架構較大,因此需要配置額外的臨時儲存空間並為其付費。
容器配置
容器名稱
vllm
鏡像
鏡像:registry.cn-hangzhou.aliyuncs.com/eci_open/vllm-openai
鏡像版本:v0.7.2
可執行命令
/bin/sh
參數
-c
vllm serve /deepseek-r1-7b --tensor-parallel-size 1 --max-model-len 24384 --enforce-eager
資料緩衝
緩衝Bucket
test
單擊添加,掛載DeepSeek-R1-Distill-Qwen-7B的資料緩衝
緩衝目錄:/model/deepseek-r1-distill-qwen-7b
目標容器:vllm
容器掛載目錄:/deepseek-r1-7b
開啟Burst
開啟(按需開啟,開啟後會提升模型載入速度但會有效能突發費用)
其他設定(選填)
Elastic IP Address
Elastic IP Address
自動建立
頻寬峰值:5 Mbps
確認執行個體配置資訊,閱讀並選中服務合約,單擊確認訂單。
返回容器組頁面,確認應用部署狀態並查看執行個體的EIP地址。
在容器組頁面可以查看執行個體狀態,單擊執行個體ID進入執行個體詳情頁可以查看容器狀態。當執行個體狀態和容器狀態均為運行中時,表示應用部署成功。您可以在IP地址列擷取執行個體的EIP地址。

OpenAPI
使用資料緩衝建立ECI執行個體,部署DeepSeek。
調用CreateContainerGroup介面建立ECI執行個體所採用的參數樣本如下,執行個體使用GPU規格,並掛載了DeepSeek-R1-Distill-Qwen-7B模型。容器啟動後會運行
vllm serve /deepseek-r1-7b --tensor-parallel-size 1 --max-model-len 24384 --enforce-eager啟動vLLM推理引擎。說明以下樣本中,系統會自動建立並為ECI執行個體綁定一個EIP。當VPC已綁定公網NAT Gateway時,建立ECI執行個體時可以不綁定EIP。在執行個體建立完成後,您可以配置DNAT條目實現外部存取ECI執行個體。
{ "RegionId": "cn-hangzhou", "SecurityGroupId": "sg-bp18***********", "VSwitchId": "vsw-bp14***********", "ContainerGroupName": "deepseek-r1-7b-server", "InstanceType": "ecs.gn7i-c16g1.4xlarge", "DataCacheBucket": "default", "Container": [ { "Arg": [ "-c", "vllm serve /deepseek-r1-7b --tensor-parallel-size 1 --max-model-len 24384 --enforce-eager" ], "Command": [ "/bin/sh" ], "Gpu": 1, "Name": "vllm", "Image": "registry-vpc.cn-hangzhou.aliyuncs.com/eci_open/vllm-openai:v0.7.2", "VolumeMount": [ { "Name": "llm-model", "MountPath": "/deepseek-r1-7b" } ] } ], "Volume": [ { "Type": "HostPathVolume", "HostPathVolume.Path": "/model/deepseek-r1-distill-qwen-7b", "Name": "llm-model" } ], "DataCacheProvisionedIops": 15000, "DataCacheBurstingEnabled": true, "AutoCreateEip": true }確認應用部署狀態。
根據返回的執行個體ID調用DescribeContainerGroupStatus查詢執行個體和容器狀態。當執行個體狀態(Status)和容器狀態(ContainerStatuses.State)為Running,表示執行個體已經建立成功,容器正在運行。
查詢執行個體的EIP地址。
根據返回的執行個體ID調用DescribeContainerGroups查詢執行個體詳情,在InternetIp中可以擷取執行個體的EIP地址。
步驟三:測試模型推理服務效果
在ECI執行個體所屬安全性群組中添加入方向規則,開放8000連接埠。
向模型推理服務發送一條模型推理請求。
本文樣本部署的DeepSeek已綁定一個EIP,請根據實際的EIP地址替換範例程式碼中的
XX.XX.XX.XX。curl POST http://XX.XX.XX.XX:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/deepseek-r1-7b", "messages": [ { "role": "user", "content": "用一句話簡單介紹一下雲端運算" } ], "temperature": 0.6, "max_tokens": 3000 }' \ --verbose預期返回:
{"id":"chatcmpl-2d3419bd63f24251a8ea1244851312e5","object":"chat.completion","created":1739179460,"model":"/deepseek-r1-7b","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"<think>\n好的,使用者讓我用一句話簡單介紹一下雲端運算。首先,我需要理解雲端運算的基本概念。雲端運算是指通過網路提供計算資源,如伺服器、儲存和資料分析,按需使用,而不是預先配置和維護。它通過互連網提供彈性計算資源,減少硬體成本。\n\n接下來,我應該考慮使用者的需求。他們可能想快速瞭解雲端運算是什麼,或者想在某個領域應用它。使用者可能對技術術語不太熟悉,所以要用簡單明了的語言。\n\n我還需要確保句子簡潔,涵蓋主要點:互連網、計算資源、彈性、按需使用、降低成本和資源管理。可能需要提到雲端運算如何協助使用者節省成本和提高效率。\n\n最後,組織這些資訊成一句話,確保流暢自然同時準確傳達雲端運算的核心價值。\n</think>\n\n雲端運算是通過互連網提供彈性計算資源,按需使用以降低硬體成本和提高資源管理效率的技術。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":8,"total_tokens":189,"completion_tokens":181,"prompt_tokens_details":null},"prompt_logprobs":null}其中
<think></think>中的內容表示的是模型在產生最終答案之前進行的內部思考過程或中間推理步驟。這些標記並不是最終輸出的一部分,而是模型在產生答案時的一種自我提示或邏輯推理的記錄。提取最終答案如下:
雲端運算是通過互連網提供彈性計算資源,按需使用以降低硬體成本和提高資源管理效率的技術。