本文介紹了從叢集建立到作業調度的全過程,適用於需要在SLURM叢集中運行容器化任務的使用者。
步驟一:建立叢集
本文使用的叢集配置樣本如下,未提及的參數請根據需要填寫。
配置項
配置
叢集配置
系列
標準版
部署模式
公用雲叢集
叢集類型
SLURM
管理節點
執行個體規格:採用ecs.r7.xlarge執行個體規格,該規格配置為4 vCPU,32 GiB記憶體。
鏡像:centos_7_6_x64_20G_alibase_20211130.vhd
計算節點與隊列
隊列節點數
初始節點
1。節點間互聯
VPC網路
執行個體規格組
執行個體規格:採用ecs.gn7i-c56g1.14xlarge執行個體規格,該規格配置為56 vCPU、346 GiB記憶體。
重要需使用支援GPU的執行個體規格。更多內容,請參見執行個體規格類型系列。
鏡像:centos_7_6_x64_20G_alibase_20211130.vhd
共用檔案儲存體
/home 叢集掛載目錄
預設情況下,管理節點的
/home和/opt將掛載檔案系統,作為共用儲存目錄。/opt 叢集掛載目錄
軟體與服務元件
待安裝軟體
選擇docker。
可安裝服務元件
登入節點:
執行個體規格:採用ecs.r7.xlarge執行個體規格,該規格配置為4 vCPU,32 GiB記憶體。
鏡像:centos_7_6_x64_20G_alibase_20211130.vhd。
本文中以usertest使用者為例。
步驟二:搭建基礎軟體環境
為計算節點綁定Elastic IP Address。具體操作,請參見Elastic IP Address。
下載並安裝CUDA。
下載CUDA安裝包。
cd /opt wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run安裝CUDA。
yum install -y git sh /opt/cuda_12.4.1_550.54.15_linux.run顯示如下圖所示時,說明CUDA已安裝。
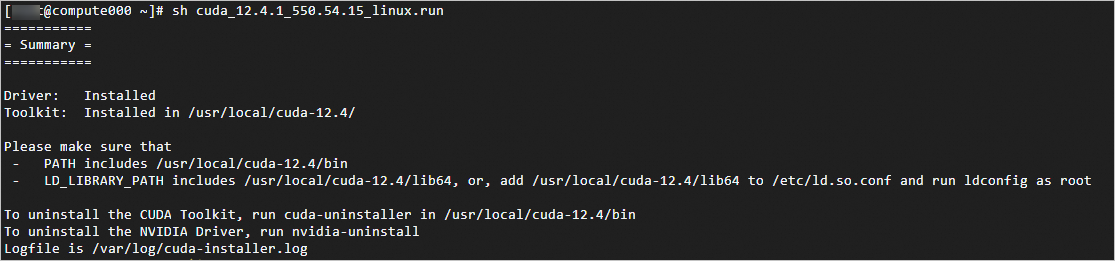
配置環境變數。
echo 'export PATH=/usr/local/cuda-12.4/bin:$PATH' >> ~/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc source ~/.bashrc查看NVIDIA CUDA工具包和GPU驅動的安裝狀態及版本資訊。
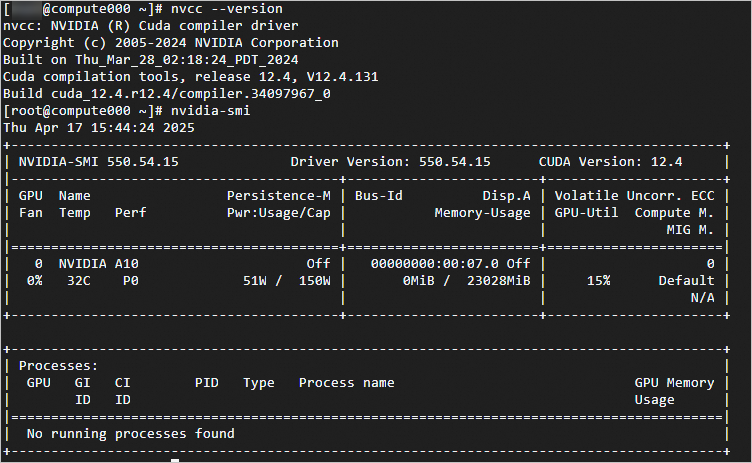
# NVIDIA CUDA編譯驅動程式的版本資訊 nvcc --version # GPU的詳細狀態資訊 nvidia-smi顯示如下圖所示時,說明CUDA和GPU驅動正常。
安裝並配置 NVIDIA Container Toolkit。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo sudo yum install -y nvidia-container-toolkit sudo systemctl restart docker下載並安裝Singularity。
Singularity是一個容器化工具,它允許在不改變使用者環境的情況下運行容器,常用於HPC環境。
cd /opt wget https://public-ehs.oss-cn-hangzhou.aliyuncs.com/softwares/packages/CentOS_7.2_64/singularity-3.8.3-1.el7.x86_64.rpm yum install -y /opt/singularity-3.8.3-1.el7.x86_64.rpm建立作業依賴資料。
拉取PyTorch容器鏡像。
docker pull ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/pytorch:2.4.0-cuda12.1.1-py310-alinux3.2104使用
usertest使用者,建立main.py檔案 。vim /home/usertest/main.pymain.py檔案指令碼內容如下。# -*- coding: utf-8 -*- import torch import torchvision import torchvision.transforms as transforms from torch import nn from torch.utils.data import DataLoader from torch.optim import SGD class SimpleNet(nn.Module): def __init__(self): super(SimpleNet, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) self.fc1 = nn.Linear(64 * 8 * 8, 128) self.fc2 = nn.Linear(128, 10) self.pool = nn.MaxPool2d(2, 2) self.relu = nn.ReLU() self.dropout = nn.Dropout(0.5) def forward(self, x): x = self.pool(self.relu(self.conv1(x))) x = self.pool(self.relu(self.conv2(x))) x = x.view(-1, 64 * 8 * 8) x = self.relu(self.fc1(x)) x = self.dropout(x) x = self.fc2(x) return x device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}") transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False) model = SimpleNet().to(device) criterion = nn.CrossEntropyLoss() optimizer = SGD(model.parameters(), lr=0.001, momentum=0.9) num_epochs = 10 for epoch in range(num_epochs): model.train() running_loss = 0.0 for i, data in enumerate(train_loader, 0): inputs, labels = data inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 100 == 99: print(f"[{epoch + 1}, {i + 1}] loss: {running_loss / 100:.3f}") running_loss = 0.0 model.eval() correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy on test set: {100 * correct / total:.2f}%") print("Training finished.")
步驟三:調度作業
調度Docker作業
通過E-HPC Portal提交作業
提交NCCL作業。
在頂部導覽列,選擇任務管理,在頁面上方,單擊submitter,在建立作業頁面,填寫作業計算節點數為
1,任務數為2,Gpu數為1。作業指令碼內容如下。
使用命令
docker images擷取鏡像名稱和版本號碼,替換第三行your_image。#!/bin/bash image="your_image" run_cmd="python main.py" share_dir="/home/usertest/:/root" # cleanup docker handle function cleanup { echo "Caught signal, stopping Docker container: " $SLURM_JOB_NAME docker ps -q --filter label=$SLURM_JOB_NAME | xargs -r docker stop docker ps -qa --filter label=$SLURM_JOB_NAME | xargs -r docker rm } trap cleanup SIGINT SIGTERM cleanup # start docker # docker pull $image docker run \ --label $SLURM_JOB_NAME \ --gpus "device=0" \ -v $share_dir \ $image \ /bin/bash -c "$run_cmd" & # wait to complete wait cleanup
查詢作業。
進入任務管理頁面,可以查詢作業列表,包含作業狀態,作業操作等。更多內容,請參見查詢作業。
通過命令列提交作業
通過命令列提交作業。具體操作,請參見SLURM。
作業指令碼內容如下。
使用命令
docker images擷取鏡像名稱和版本號碼,替換第十三行your_image。#!/bin/bash #SBATCH --job-name=tf_sample_job #SBATCH --nodes=1 #SBATCH --ntasks=2 #SBATCH --gpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --partition=comp #SBATCH --output=tf_sample_job_%j.out #SBATCH --error=tf_sample_job_%j.err # 定義變數 image="your_image" run_cmd="python main.py" share_dir="/home/usertest/:/root" # 清理 Docker 進程 function cleanup { echo "Caught signal, stopping Docker container: " $SLURM_JOB_NAME docker ps -q --filter label=$SLURM_JOB_NAME | xargs -r docker stop docker ps -qa --filter label=$SLURM_JOB_NAME | xargs -r docker rm } trap cleanup SIGINT SIGTERM cleanup # 啟動 Docker 容器 docker pull $image docker run \ --label $SLURM_JOB_NAME \ --gpus "device=$CUDA_VISIBLE_DEVICES" \ -v $share_dir \ $image \ /bin/bash -c "$run_cmd" & # 等待任務完成 wait cleanup通過slurm查詢作業。
使用
squeue命令可以查詢當前正在運行和排隊中的作業列表。squeue使用
sacct命令可以查詢作業的記錄,包括已完成的作業。sacct
調度Singularity作業
Docker2Singularity。
為了簡化Singularity鏡像管理,可以複用雲上Docker鏡像倉庫,根據以下操作步驟,對鏡像進行格式轉換。
# 方案1:通過local docker package轉換sif鏡像 [root@compute006 opt]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/pytorch 2.4.0-cuda12.1.1-py310-alinux3.2104 19301a07d7fd 4 months ago 6.33GB [root@compute006 opt]# docker save -o docker.tar 19301a07d7fd [root@compute006 opt]# ll docker.tar -rw------- 1 root root 3021202432 2月 12 15:03 docker.tar [root@compute006 opt]# singularity build pytorch.sif docker-archive:///opt/docker.tar # 方案2:通過docker容器倉庫build sif鏡像 singularity build xx.sif docker://ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/pytorch:2.4.0-cuda12.1.1-py310-alinux3.2104
通過E-HPC Portal提交作業
提交NCCL作業。
在頂部導覽列,選擇任務管理,在頁面上方,單擊submitter,在建立作業頁面,填寫作業計算節點數為
1,任務數為2,Gpu數為1。作業指令碼內容如下。
image=/opt/pytorch.sif run_cmd="python main.py" share_dir="/home/usertest/:/root" singularity exec --nv --bind $share_dir $image $run_cmd
查詢作業。
進入任務管理頁面,可以查詢作業列表,包含作業狀態,作業操作等。更多內容,請參見查詢作業。
通過命令列提交作業
通過命令列提交作業。具體操作,請參見SLURM。
作業指令碼內容如下。
#!/bin/bash #SBATCH --job-name=singularity_TF #SBATCH --output=output.log #SBATCH --nodes=1 #SBATCH --gres=gpu:1 #SBATCH --partition=container #SBATCH --ntasks=2 image=/opt/pytorch.sif run_cmd="python main.py" share_dir="/home/usertest/:/root" singularity exec --nv --bind $share_dir $image $run_cmd通過slurm查詢作業。
使用
squeue命令可以查詢當前正在運行和排隊中的作業列表。squeue使用
sacct命令可以查詢作業的記錄,包括已完成的作業。sacct