本文為您介紹如何使用DTS RAGFlow構建雲原生資料倉儲AnalyticDB PostgreSQL版GraphRAG。通過該方案,可以為知識庫構建知識圖譜,實現對複雜關聯問題的深度理解和精準檢索,超越傳統向量檢索的局限。
當前功能目前正處於邀測階段。如您有相關需求,請提交工單與我們聯絡,以便為您開啟該功能。
業務情境說明
在處理包含複雜實體關聯和深層邏輯的知識庫(例如,金融風控報告、多產品技術手冊、企業組織架構文檔)時,傳統的基於向量相似性的RAG(檢索增強產生)方案常常難以準確回答涉及多步推理或關係挖掘的查詢。例如,“對比A產品和B產品在C情境下的優缺點”或“查詢與專案X相關的所有團隊成員及其負責模組”,這類問題需要理解實體間的內在聯絡,而非僅僅是文本表面的相似性。
GraphRAG通過在傳統向量檢索的基礎上引入知識圖譜,將非結構化文本中隱含的實體和關係顯式化、結構化。這使得系統能夠通過圖檢索定位到與問題相關的結構化子圖,為大型語言模型(LLM)提供更豐富、更具上下文邏輯的背景資訊,從而顯著提升對複雜、多跳查詢的回答品質。
方案架構
本方案整合了DTS RAGFlow的資料處理能力和雲原生資料倉儲AnalyticDB PostgreSQL版的圖分析引擎,構建一個從文檔到知識圖譜再到智能問答的完整鏈路。
工作流程說明:
資料注入與處理:將非結構化文檔上傳至DTS RAGFlow知識庫。
知識抽取與儲存:
RAGFlow自動對文檔進行解析、分區(Chunking)和向量化(Embedding)。
啟用GraphRAG後,RAGFlow會調用知識抽取運算元,從文本中提取實體-關係-實體(S-P-O)三元組。
向量化的文本Chunk和提取出的知識圖譜資料(實體與邊)被一同寫入指定的雲原生資料倉儲AnalyticDB PostgreSQL版執行個體中進行統一儲存。
混合檢索:
在檢索測試或通過API發起查詢時,系統會執行混合檢索。
查詢首先進行向量檢索,找到相關的文本Chunk。
同時,查詢在雲原生資料倉儲AnalyticDB PostgreSQL版的圖分析引擎中進行圖檢索,找到與問題相關的實體和關聯子圖。
上下文增強與產生:系統將向量檢索到的文本Chunk和圖檢索到的關聯子圖一併作為上下文(Context)提交給LLM,由LLM基於這些豐富的資訊產生最終回答。
實施步驟
步驟一:環境準備
建立雲原生資料倉儲AnalyticDB PostgreSQL版執行個體。
核心版本需為7.3及以上版本。
開通GraphRAG服務,完成安裝對應外掛程式即可。
在DTS中建立RAGFlow知識庫並設定IP白名單。
步驟二:配置知識庫並啟用GraphRAG
此步驟將DTS RAGFlow知識庫與AnalyticDB for PostgreSQL執行個體進行關聯。
進入目標地區的RAGFlow知識庫列表頁面。
在左側導覽列,單擊數據準備。
在頁面左上方,選擇資料準備執行個體所屬地區。
單擊RAGFlow 知識庫頁簽。
登入RAGFlow。
在目標RAGFlow知識庫的操作列,單擊管理。
說明您也可以單擊操作列的登入知識庫,選擇內網或外網進行登入。
在串連地址地區,單擊登入外網地址或登入內網地址。
說明若您需要通過外網地址訪問RAGFlow知識庫,需為該執行個體開通外網地址。
在登入頁面,填入賬戶的郵箱和密碼,並單擊登入。
在RAGFlow頁面,進行管理知識庫等操作。
說明操作方法,請參見RAGFlow官方文檔。
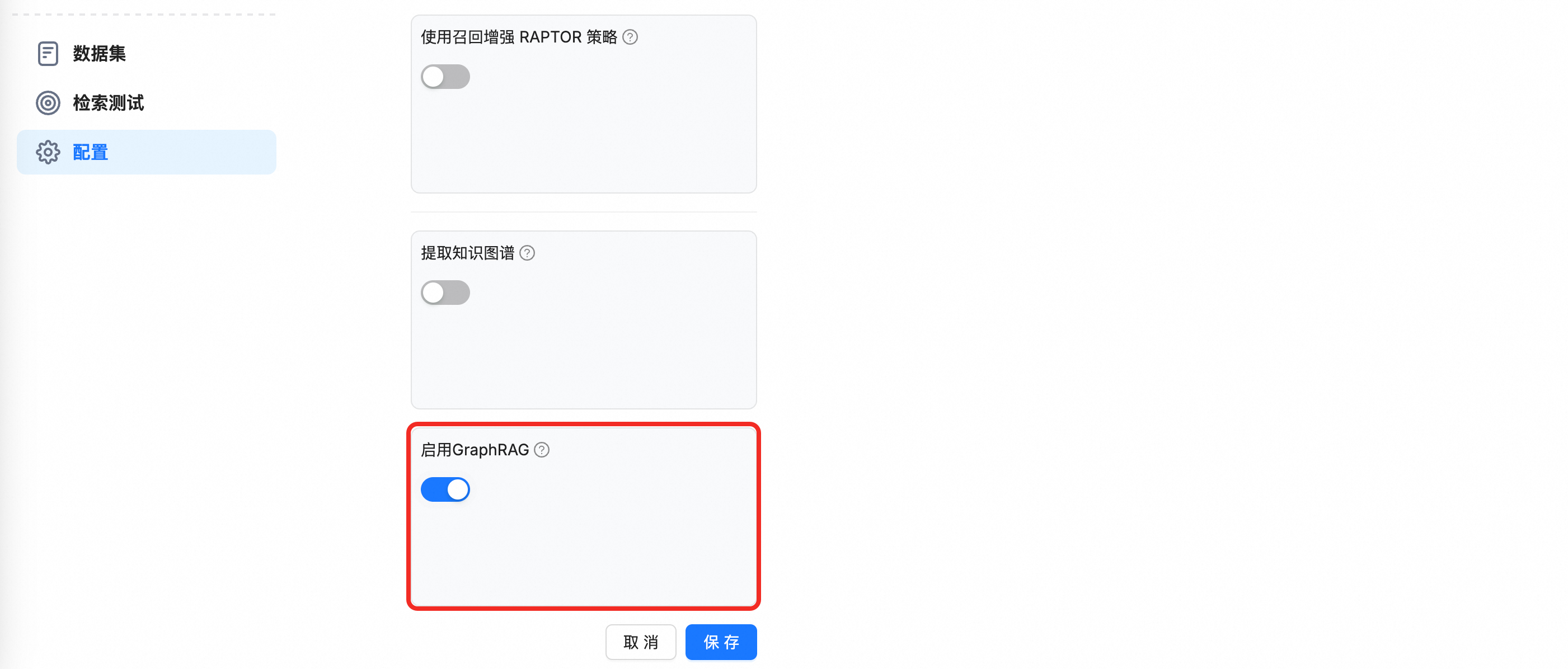
單擊建立知識庫,在知識庫建立頁面,輸入知識庫名稱,然後找到並啟用GraphRAG開關。
 說明
說明建立知識庫時,需先在模型供應商中添加嵌入模型和LLM,然後在中設定它們。
若您需要在DTS RAGFlow知識庫中嵌入外部模型和LLM,則DTS RAGFlow知識庫所在的Virtual Private Cloud配置NAT Gateway,以便允許其訪問外部網路。
建立公網NAT Gateway:請前往NAT Gateway - 公網 NAT Gateway購買頁進行建立。在建立過程中,請確保選擇與DTS RAGFlow知識庫相同的VPC和交換器。
配置SNAT條目:前往公網 NAT Gateway頁面。單擊目標網關操作列的設定SNAT,單擊建立SNAT條目。參數請按如下配置:
SNAT條目粒度:VPC粒度。
選擇Elastic IP Address地址:在下拉式清單中選擇提供公網訪問的EIP。
步驟三:上傳文檔並構建知識圖譜
在新建立的知識庫中,單擊資料集中新增檔案,選擇一個本地檔案進行上傳。
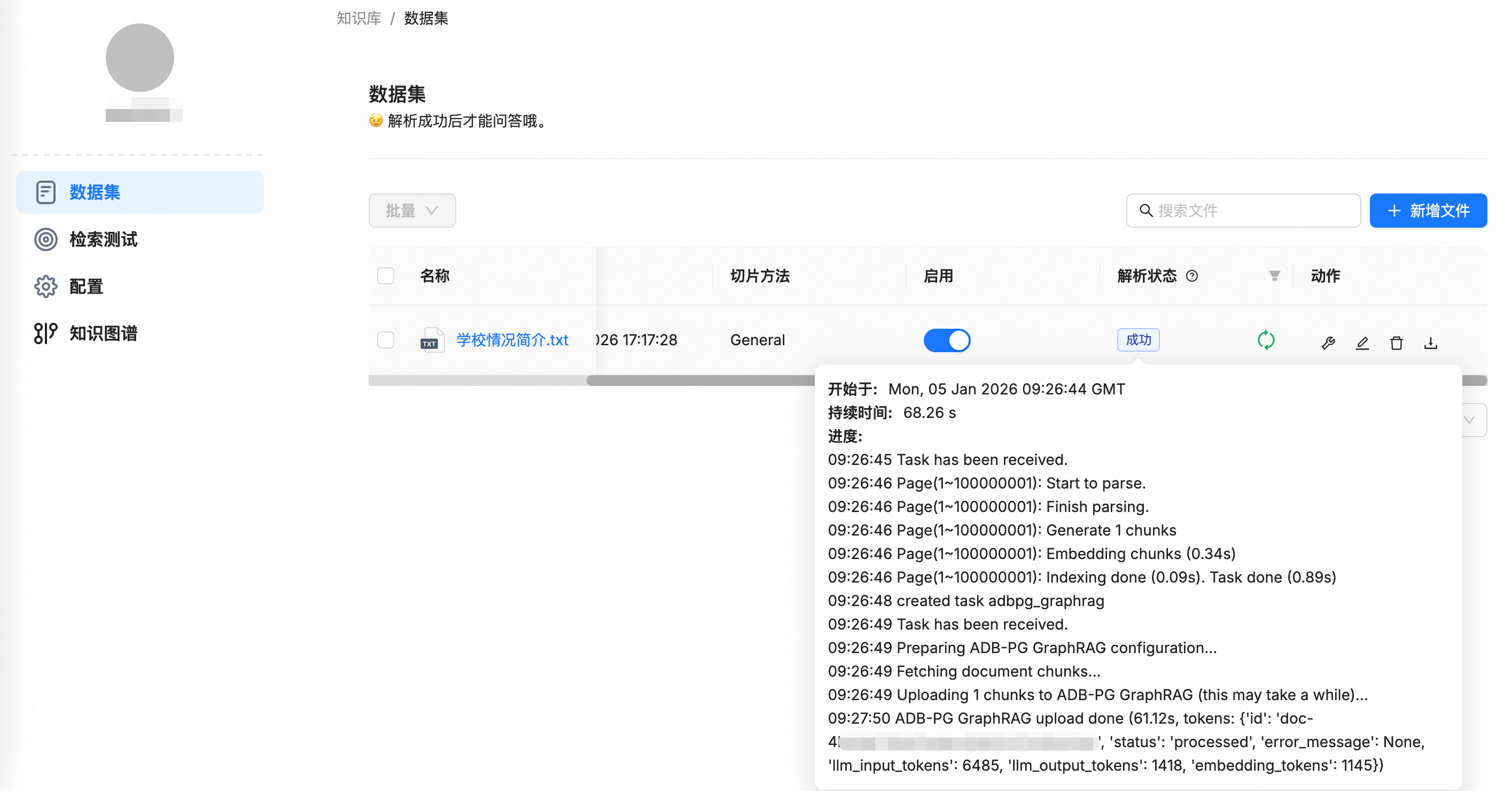
檔案上傳後,RAGFlow會自動執行解析、Chunk、Embedding等一系列處理流程。由於已啟用GraphRAG,系統還會額外進行知識抽取,並將產生的實體和邊資料寫入已配置的雲原生資料倉儲AnalyticDB PostgreSQL版中,完成知識圖譜的構建。
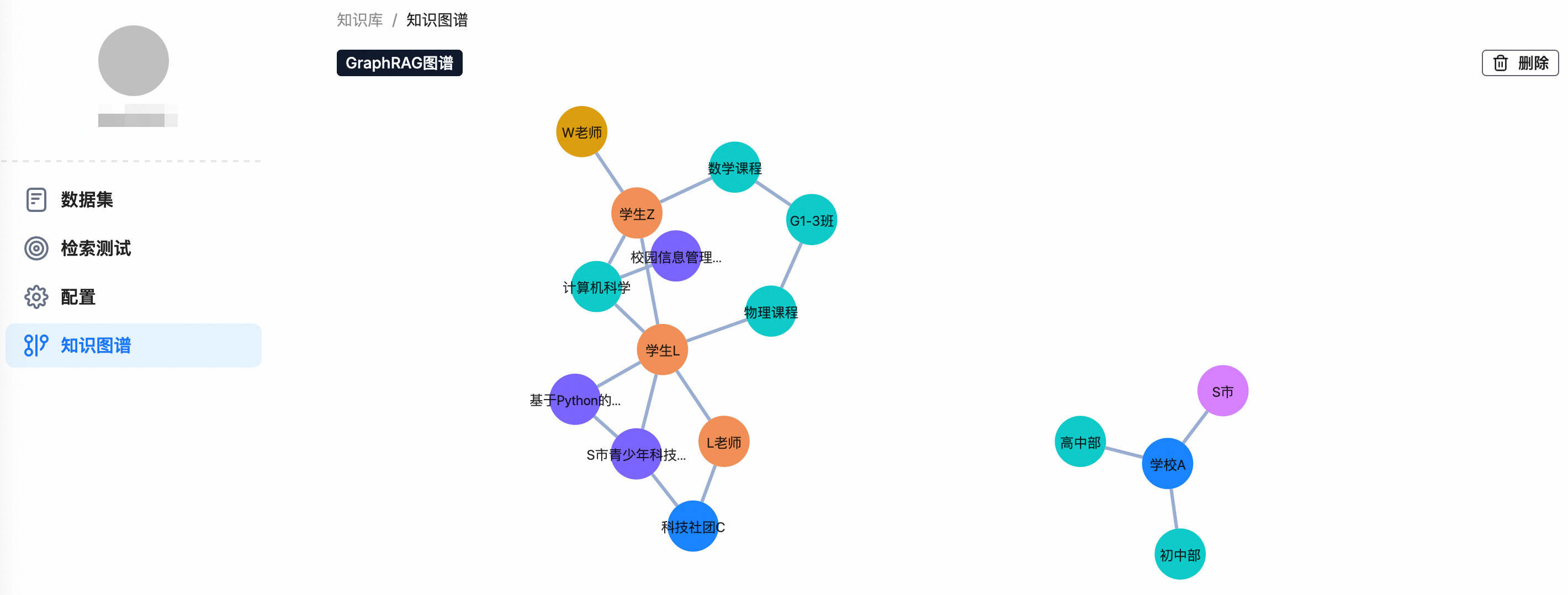
處理完成後,在知識庫的左側導覽列中會出現知識圖譜組件,可用於可視化地瀏覽和驗證已抽取的實體與關係。
步驟四:檢索測試
通過對比測試,可以驗證GraphRAG在處理不同類型查詢時的效果。
進入知識庫的檢索測試頁面。
情境一:常規查詢
對於事實性的簡單查詢(例如“什麼是RAG”),無論是否使用GraphRAG,系統主要依賴向量檢索返回最相關的文本Chunk。
情境二:複雜查詢
對於需要理解實體間關係的複雜查詢(例如“對比RAG和GraphRAG的優缺點”),勾選使用GraphRAG。
此時,檢索結果不僅會包含相關的文本Chunk,還會額外返回一個結構化的關聯子圖。該子圖以Markdown表格形式呈現,清晰地列出查詢涉及的核心實體及其關係,為LLM提供結構化的上下文,從而產生更具邏輯和深度的回答。
返回的關聯子圖格式如下:
---- Entities ---- ,Entity,Description 0,entity1,description1 1,entity2,description2 ---- Relations ---- ,From Entity,To Entity,Description 0,source_entity1,target_entity1,description1 1,source_entity2,target_entity2,description2樣本:
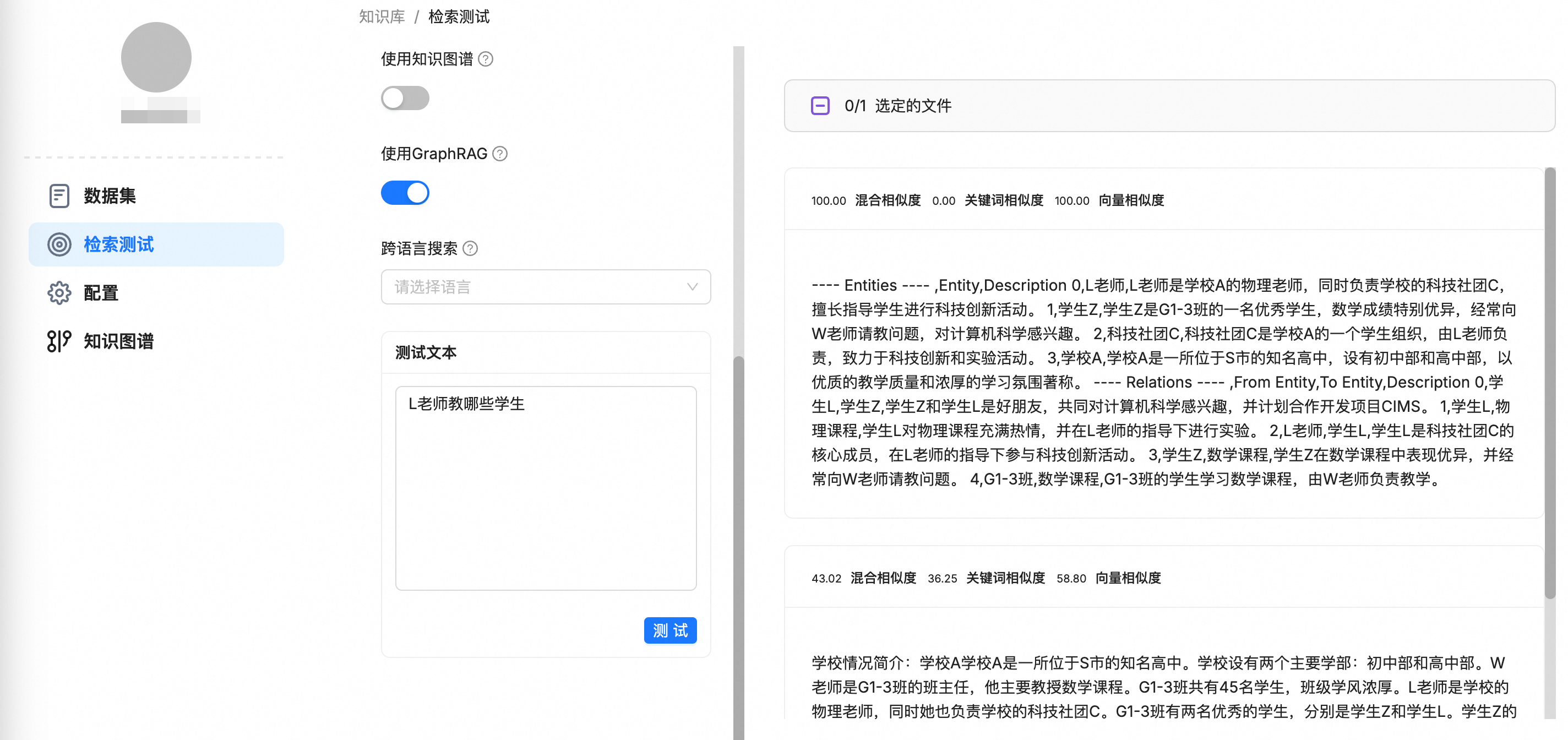
若不勾選使用GraphRAG,則檢索結果僅包含文本Chunk,LLM可能因缺乏結構化關係資訊而無法準確回答。