Airflow GUI 是 DMS 在社區版 Airflow 基礎上提供的可視化編排工具,協助你通過拖拉拽的方式快速建立和管理 Airflow DAG 任務,無需手寫 Python 代碼。本文介紹 Airflow GUI 的使用入口、全域配置、節點配置及任務發布流程。
前提條件
已完成搭建Airflow環境。
如需使用郵件警示功能,需提前在 Airflow 中完成郵件配置,使用自訂郵件服務。
快速入門
功能入口
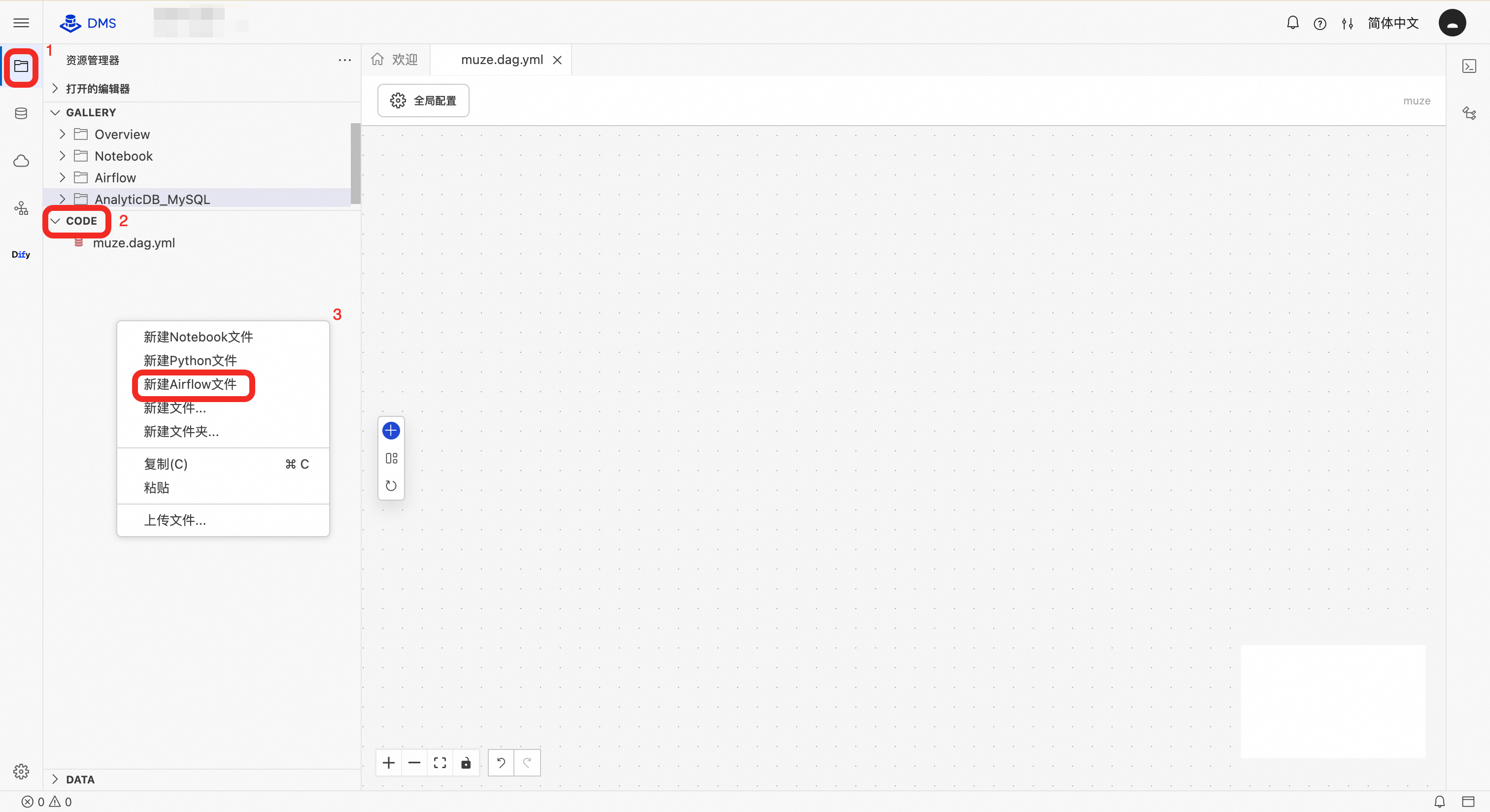
在頂部功能表列中,選擇Data + AI > 工作空間,或在極簡模式的控制台,點擊控制台左上方的
 表徵圖,選擇全部功能 > Data + AI > 工作空間。
表徵圖,選擇全部功能 > Data + AI > 工作空間。在空間列表頁,點擊目標空間ID,進入目標空間。
在左側導覽列,點擊資源管理員,在CODE模組空白部分,點擊滑鼠右鍵,建立Airflow檔案。
工作流程畫布概覽
進入 GUI 編輯器後,您會看到一個直觀的可視化畫布。
左側:是節點面板,點擊
 按鈕您可以在此選擇並添加不同類型的任務節點。
按鈕您可以在此選擇並添加不同類型的任務節點。中間:是主畫布,您可以在此拖拽節點、串連依賴關係,構建您的工作流程。
右側:是配置面板,當您選中某個節點或畫布空白處時,會顯示對應的配置項。
核心操作流程
全域配置:在右側面板中,完成 DAG 的全域配置,如名稱、調度策略、警示等。
添加與配置節點:從左側面板拖拽所需節點至畫布,並在右側面板中完成其基礎和進階配置。
設定依賴關係:通過拖拽節點之間的錨點,建立任務的上下遊依賴關係。
儲存與發布:完成工作流程設計後,儲存並將其發布至 Airflow 環境。
核心概念與配置詳解
全域配置
單擊頂部導覽列的全域配置按鈕,將顯示 DAG 的全域配置
基礎資訊:
名稱:即 Airflow 中的
DAG ID,必須在您的 Airflow 環境中唯一。
調度配置:
Cron 運算式:定義 DAG 的周期性調度策略。
開始/結束日期:定義 DAG 調度的有效時間範圍。
警示設定:
配置任務失敗、成功或重試時的郵件警示。多個郵箱地址請用逗號隔開。
前提條件:使用郵件警示前,需在 Airflow 中完成郵件服務的配置。
模板支援:警示標題和內容支援 Jinja 模板,可動態插入
dag、ti等內建變數。郵件內容支援 HTML 格式。
變數:
定義可在 DAG 內所有任務中使用的全域變數。變數值同樣支援 Jinja 模板。
重試設定:
配置任務失敗後的全域預設重試次數和稍候再試。
節點配置
從左側面板添加的每個節點都包含基礎配置和進階配置兩部分。進階配置為所有節點通用,基礎配置則因節點類型而異。
進階配置(通用)
警示配置:可覆蓋全域警示設定,為當前節點定義獨立的警示策略。
重試:可覆蓋全域重試設定,為當前節點定義獨立的重試策略。
資源集區配置:指定任務在 Airflow 的哪個資源集區(Pool)中運行,用於控制任務的並發度。
觸發規則(Trigger Rule):定義當前任務的執行條件,如“所有上遊任務成功”、“至少一個上遊任務成功”等。
基礎配置(按節點類型)
以下是部分常用節點的基礎配置說明:
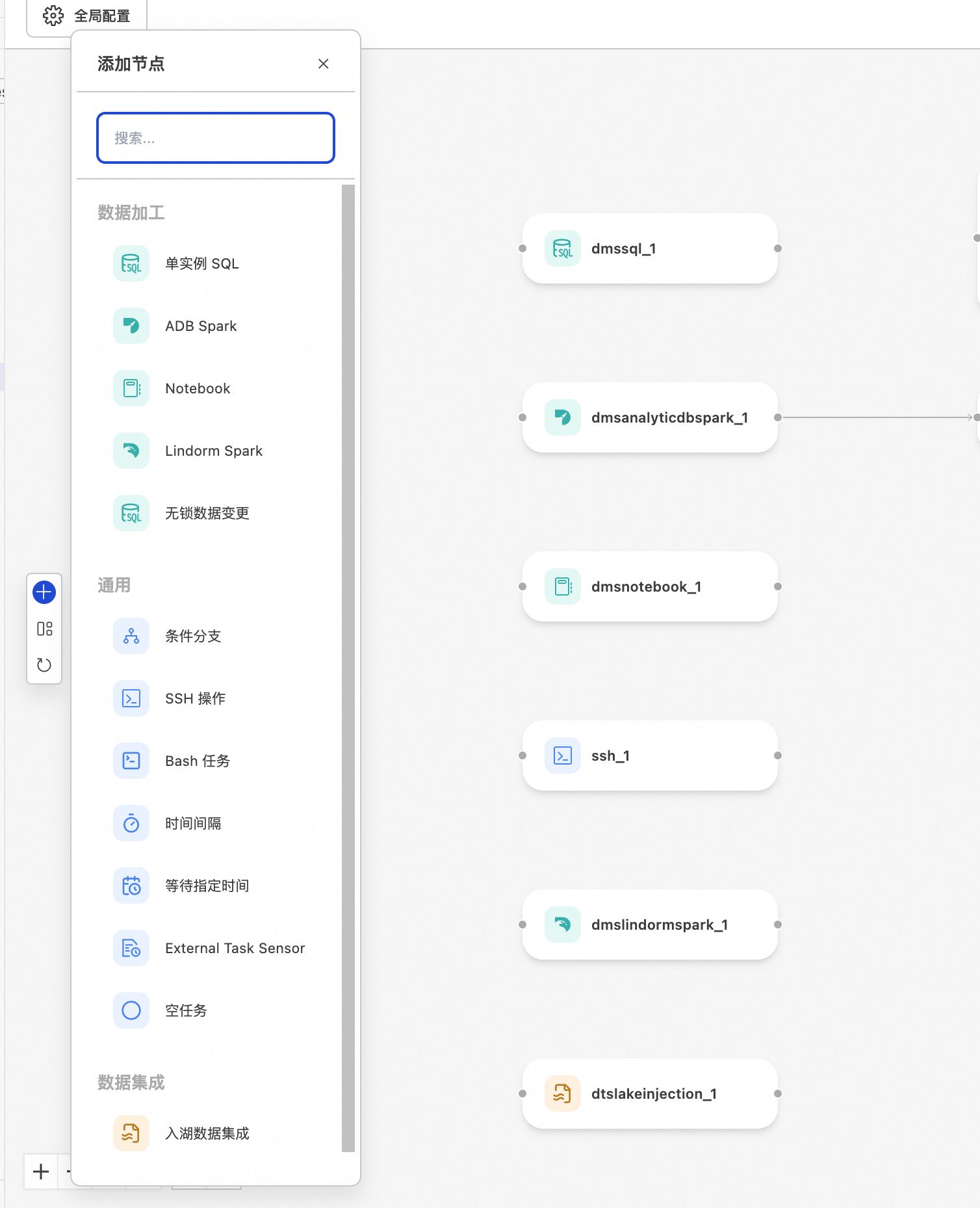
單一實例 SQL
功能:在指定的資料庫執行個體上執行單條 SQL 陳述式。
配置:選擇執行個體和資料庫,然後直接編寫 SQL 或選擇一個已存在於工作空間中的
.sql檔案。回調代碼(可選):一段 Python 代碼,在 SQL 執行成功後運行。主要用途:
傳遞資料(XCom):通過內建的
result變數(一個包含data鍵的字典)擷取 SQL 查詢結果,並將其傳遞給下遊任務。例如,result['data'][0]['co']表示擷取結果集第一行中名為co的列的值。結果校正:對 SQL 結果進行檢查,不滿足條件時可主動拋出異常使任務失敗。
if len(result["data"]) > 10: raise Exception("too many data")
ADB Spark
功能:在 AnalyticDB for MySQL 的 Spark 引擎上提交作業。
配置:選擇 ADB 執行個體和資源群組,然後根據任務類型(SQL 或 BATCH)進行配置。
SQL 任務:直接編寫 Spark SQL 或選擇
.sql檔案。BATCH 任務:提供一個 JSON 格式的 Spark 作業配置。
{ "args": [ "1000" ], "className": "org.apache.spark.examples.SparkPi", "comments": [ "-- Here is just an example of SparkPi. Modify the content and run your spark program." ], "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.instances": 2, "spark.executor.resourceSpec": "medium" }, "file": "local:///tmp/spark-examples.jar", "name": "SparkPi" }
Notebook
功能:運行工作空間中的 Notebook 檔案。
配置:
選擇 Notebook Session。
選擇 Notebook 檔案路徑。檔案必須在工作空間內已配置,路徑為工作空間的檔案路徑。
Lindorm Spark
功能:提交 Lindorm Spark 作業。
配置:
選擇 Lindorm 執行個體。
選擇作業類型並配置作業參數。
無鎖資料變更
功能:以無鎖方式在指定執行個體和資料庫上執行資料變更 SQL。配置方式與"單一實例 SQL"節點一致,同樣支援回調代碼處理執行結果。
條件分支
功能:根據不同的條件,決定工作流程的走向。
配置:可以添加多個分支條件,每個條件都是一個返回
True或False的 Python 運算式。運算式支援 Jinja 模板,可以引用 Airflow 變數。條件分支有多個下遊邊,可以拖拉拽設定。
SSH 操作
功能:通過 SSH 串連到遠程伺服器並執行命令。
配置:
在 Airflow 的
Connections中預先配置好 SSH 串連資訊,並擷取其Connection ID。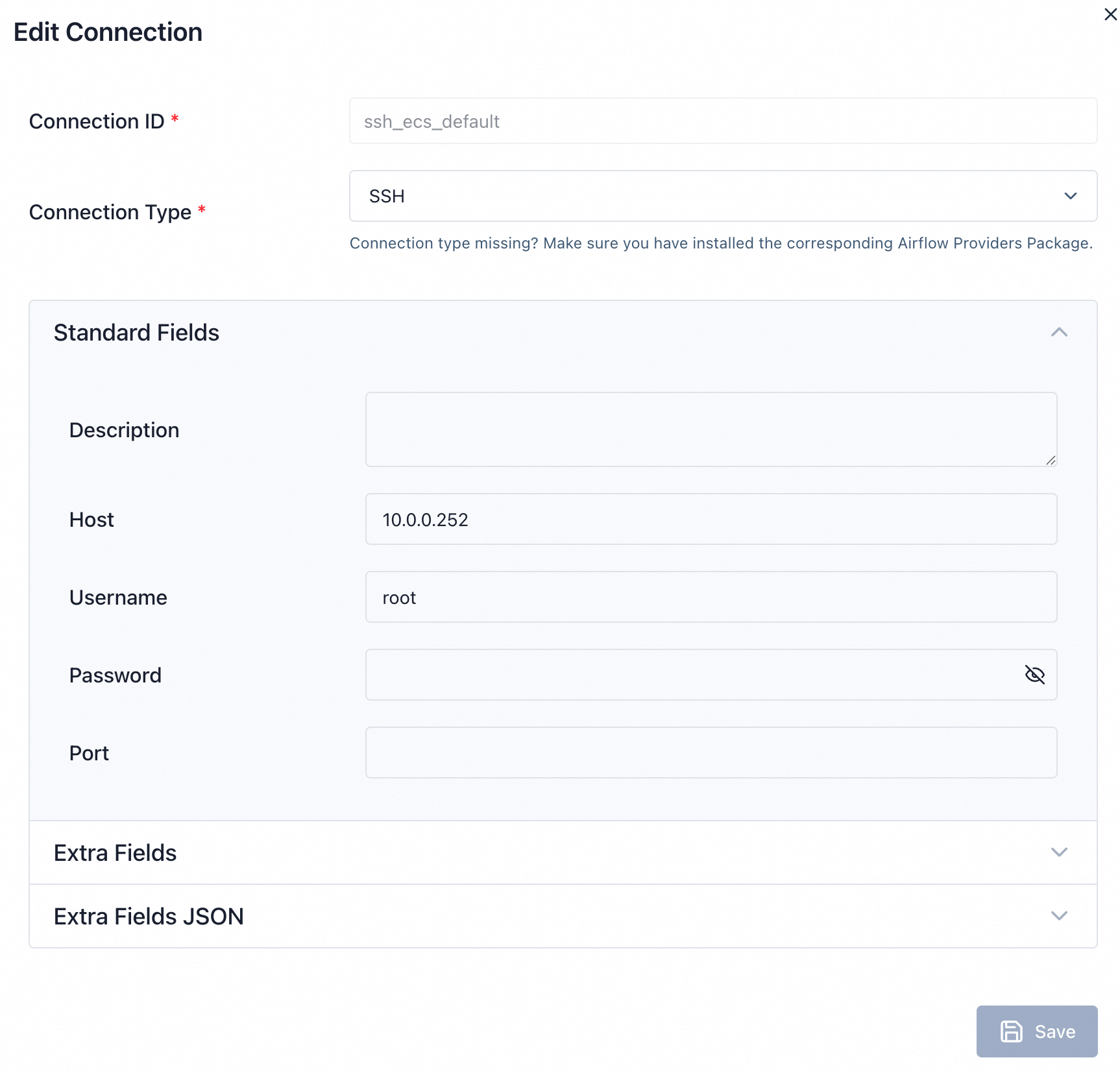
在節點配置中填入該
Connection ID和要執行的 Shell 命令。
Bash 任務
功能:在本地環境中執行 Bash 命令。
配置:
配置要執行的 Bash 命令。
配置命令執行時的環境變數。
時間間隔
功能:用於在任務流程中暫停等待一段指定的時間後再繼續執行後續節點。
等待指定時間
功能:等待到達指定的目標時間後再繼續執行後續節點。目標時間支援使用 Airflow Jinja 模板文法動態設定。
External Task Sensor
功能:配置外部任務依賴檢查,等待同一 Airflow 執行個體中的外部 DAG 或 Task 完成後再繼續執行。
配置:
上遊 DAG 名稱:被依賴的 DAG 的 ID。
上遊節點名稱(可選):被依賴的 Task 的 ID。如果留空,則表示等待整個上遊 DAG 完成。
空任務
功能:一個不做任何事情的“預留位置”節點,常用於彙總多個上遊分支,或作為邏輯起點/終點,使工作流程結構更清晰。
配置:無。
入湖Data Integration
功能:將資料從源庫整合到目標資料湖。
配置:
選擇源庫和目標庫。
配置Data Integration任務的其他參數。
設定依賴關係
添加依賴:將滑鼠移至上方在一個節點的邊緣,會出錨點。按住滑鼠左鍵從一個節點的錨點拖拽到另一個節點的錨點,即可建立一條表示依賴關係的邊。
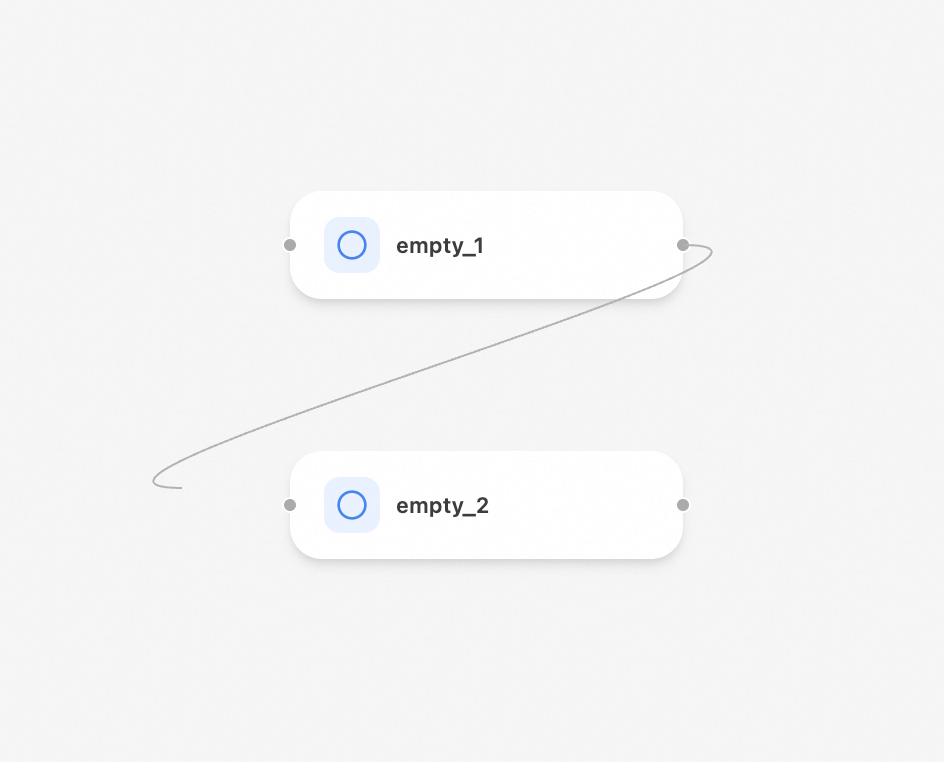
刪除依賴:單擊選中一條邊,然後按
Delete鍵即可刪除。
發布與驗證
Git 整合(可選)
如果您的工作空間與 Git 倉庫關聯,請在發布前先將代碼提交至 Git。
Commit:在 Git 面板中提交您的更改。
Push:將提交推送到遠程倉庫。
部署至 Airflow
單擊編輯器右上方的 部署 按鈕,系統會將您通過 GUI 設計的工作流程轉換為 Python 代碼,並發布到您的 Airflow 環境中。
在 Airflow 中驗證
部署成功後,登入您的 Airflow UI。您會看到一個新的 DAG,其 DAG ID 與您在 GUI 中配置的名稱一致,並且帶有一個 generated 標籤,表示它是由 GUI 產生的。您可以在此觸發、監控和管理這個 DAG 的運行。