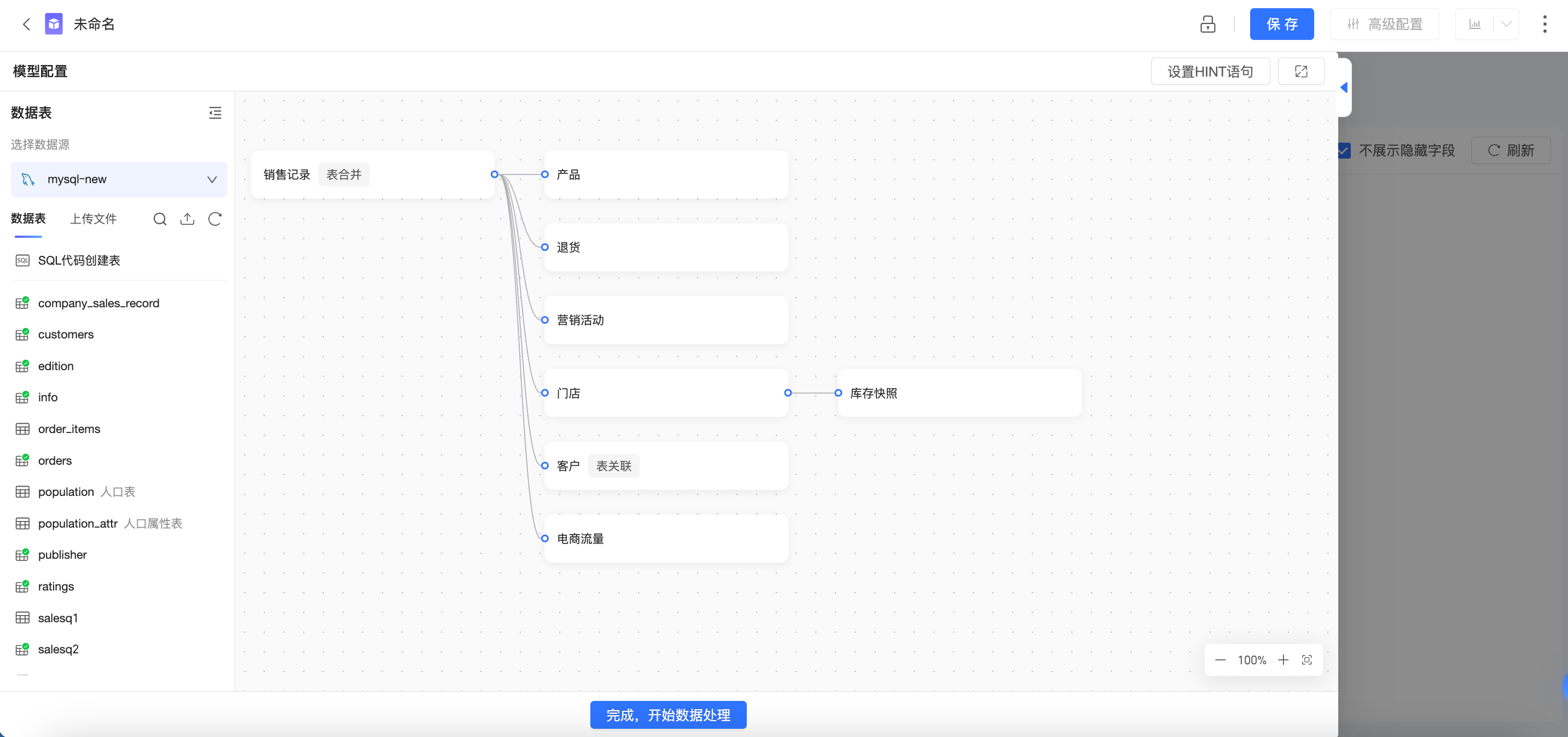
什麼是關聯式模式?
關聯式模式簡介
Quick BI關聯式模式是一套用於多表關聯與分析的資料建模體系,旨在解決傳統物理建模中效率低、準確性不足、分析靈活性差等問題,適用於複雜業務情境下的多維資料分析需求。
在關聯式模式中,您無需關注資料細節,無需指定明確的關聯方式,只需要將有關係的表統一放置在畫布中,並配置關聯鍵,即可輕鬆完成建模。
在大力提高建模效率的同時,關聯式模式的資料正確性也可以得到有力保障。Quick BI會根據查詢時用到的具體欄位,以及關係的配置,靈活調整查詢SQL,保證資料準確性。具體處理邏輯可參考關聯式模式如何工作?
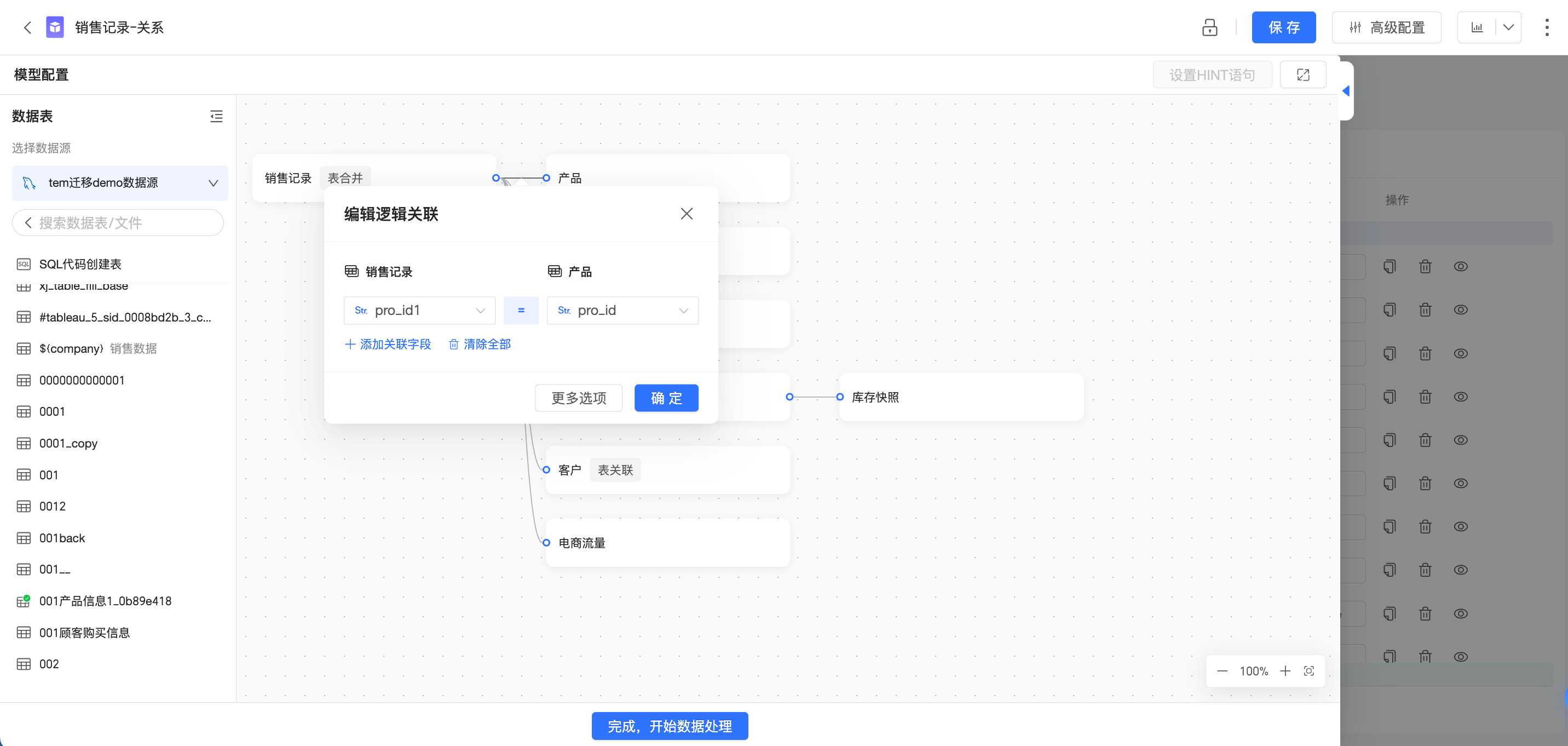
關聯式模式核心價值
背景及痛點問題
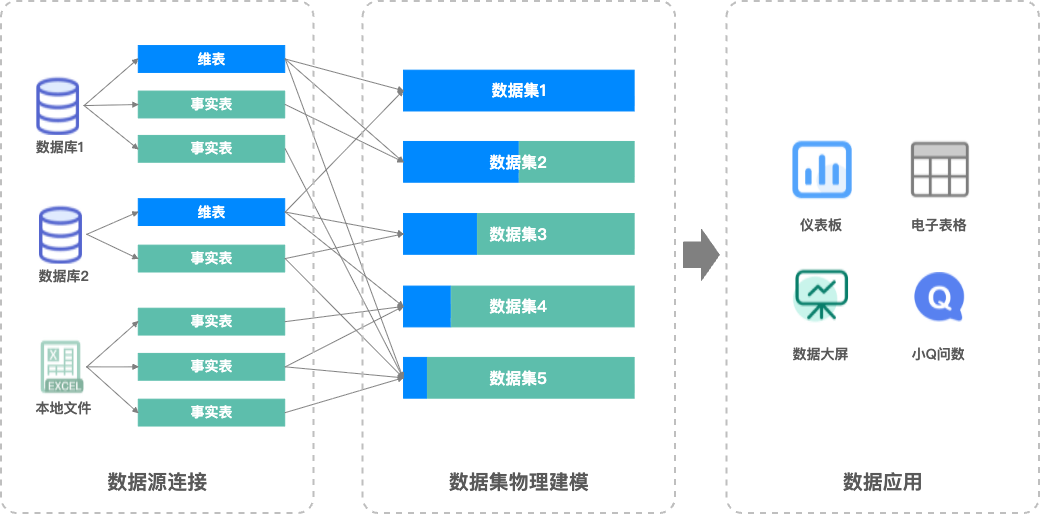
在Quick BI之前的資料集建模中,表與表之間的關聯方式是普通的物理關聯,即Left Join、Full Join等,關聯完成後將會形成一張完整大寬表。由於普通物理關聯可能存在資料膨脹的問題,為保證資料正確性,通常需要使用者提前對資料情況有清晰的掌控,包括資料完整性、唯一性等。有時甚至需要對資料來源表進行預先處理,來避免資料膨脹的出現(如:對資料提前進行彙總)。綜上,物理建模往往存在比較高的門檻和操作成本,也容易因資料膨脹導致資料錯誤。
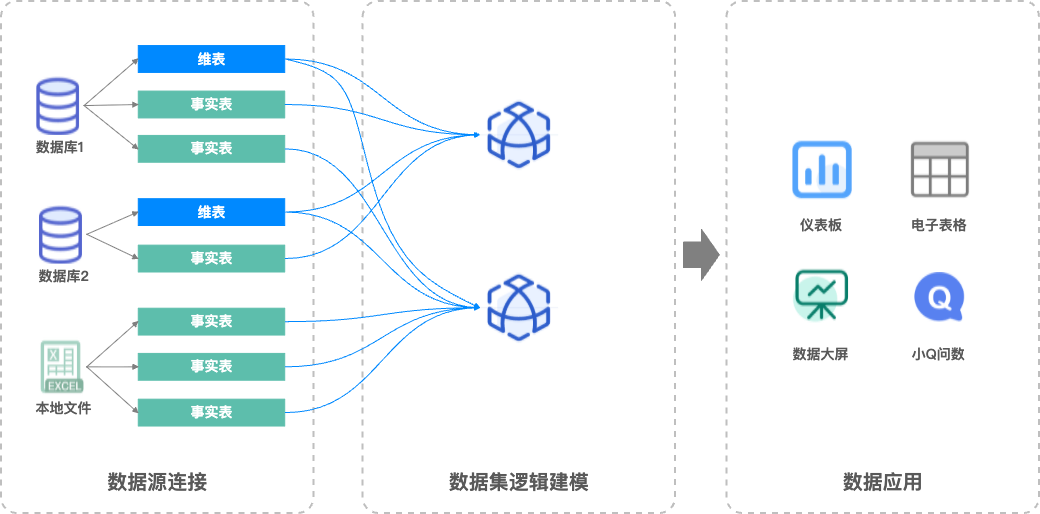
為此,Quick BI推出了全新的“關聯式模式”,在“物理建模”的基礎上引入了“關係建模”的能力。關聯式模式可以極大地提高使用者在處理複雜資料模型時的效率和靈活性。
關聯式模式價值
資料建模更簡單:無需關注關聯方式,只需要指定關聯欄位即可完成資料建模,關聯式模式將自動處理以保證資料完整性。
解決資料膨脹問題:當資料粒度無法匹配時,無需在建模時進行資料預先處理,關聯式模式可自動解決資料膨脹問題,保證資料計算的正確性。
模型可支撐更多分析情境,無需進行多次建模:關聯式模式的可複用性強,無需根據獨立的分析情境分別建模,可有效減少建模的數量,便於後續的維護和管理。
更多內容可參考:關聯式模式的優勢。
物理模型和關聯式模式對比
物理模型 | 關聯式模式 |
|
|
存在問題:
| 解決方案:
|
關鍵概念
事實表和維表
事實表(Fact Table)和維表(Dimension Table)是資料建模中常用的術語,用於描述兩種不同類型的表格。
事實表:儲存可被量化的業務指標,包含了與業務過程相關的事實(Facts)資料。比如線上教育平台中的課程完成人數、測驗平均分、學習時間長度等。
維表:儲存描述性屬性,包含了與業務過程相關的維度(Dimensions)資料。比如課程類型、學員年級、教師姓名、學習日期等。
事實表和維表之間通過某些共同的欄位建立關聯關係,這樣可以在查詢和分析資料時將維度和指標進行關聯,實現多維分析。
舉例說明
事實表
訂單表
訂單ID | 日期 | 產品ID | 數量 | 金額 |
1 | 2025-12-01 | A | 1 | 50 |
2 | 2025-12-01 | A | 2 | 100 |
3 | 2025-12-01 | B | 3 | 60 |
4 | 2025-12-02 | C | 1 | 10 |
庫存記錄
日期 | 產品ID | 庫存數量 |
2025-12-01 | A | 10 |
2025-12-01 | B | 20 |
2025-12-01 | C | 5 |
2025-12-02 | C | 4 |
維度資料表
產品ID | 產品名稱 | 類別 | 品牌 |
A | 清風牌面巾紙(一箱) | 生活用品 | 清風 |
B | 晨光檔案夾(一套) | 文具用品 | 晨光 |
C | 上好佳鮮蝦片(大包) | 食品 | 上好佳 |
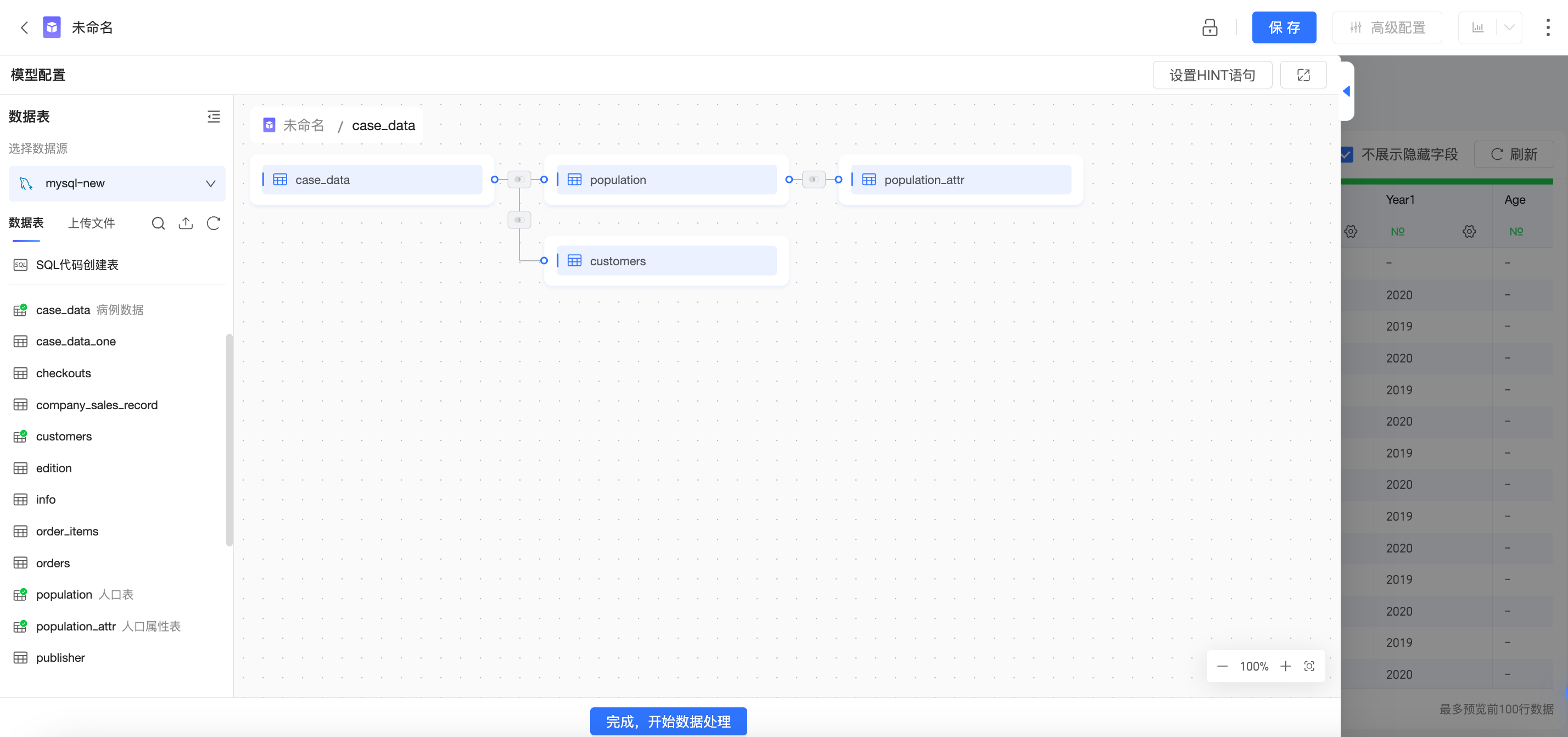
資料建模的層
您在Quick BI中建立的每個資料集都有一個資料模型,可以將資料模型簡單理解為一個資料表的關係圖,告知Quick BI應該如何查詢資料庫表中的資料。
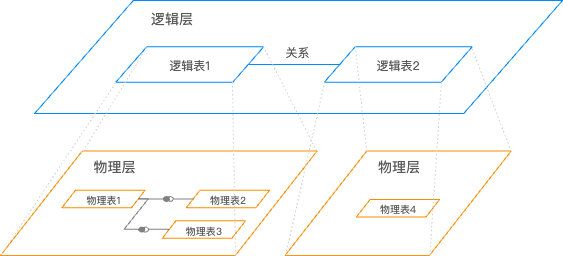
邏輯層和物理層
Quick BI的資料模型有2層:
邏輯層:
進入資料集的資料建模畫布中,首先看到的是邏輯層,通常情況下,您只需要在邏輯層進行建模即可。
使用關係(關係線)來定義邏輯層中不同節點之間的關係,每個節點為一個邏輯表(每個邏輯表可以由單獨的表、單獨的自訂SQL構成,也可以是由多個表、自訂SQL進行物理關聯、物理合并後的寬表構成)。
邏輯層的建模將構造出完整的資料模型。
物理層:
從邏輯層中任意一個邏輯表,可進入該邏輯表的物理畫布中,也就是物理層。
物理層使用傳統的物理關聯、物理合并來定義多張物理表之間的關係,每一個節點是一張資料庫表,或一段自訂SQL。
物理層的建模將形成一張固定的大寬表,並形成邏輯層中的一個邏輯節點。
邏輯層 | 物理層 |
關係線 | 維恩圖 |
|
|
邏輯層和物理層之間的關係
邏輯層中,每個邏輯表之間通過“關係”進行建模,最終形成的是“關聯式模式”。邏輯層建模時不需要為關係指定具體的關聯方式,最終也不會形成一張固定的大寬表。
每個邏輯表都對應一個單獨的“物理建模”,您可以通過雙擊邏輯表,或者從右側![]() 表徵圖→“進入物理畫布”進入物理層。物理層中,每個物理表之間可通過“關聯”或“合并”進行建模,需要指定具體的關聯方式,最終會形成一張完整的大寬表。
表徵圖→“進入物理畫布”進入物理層。物理層中,每個物理表之間可通過“關聯”或“合并”進行建模,需要指定具體的關聯方式,最終會形成一張完整的大寬表。
邏輯層中的每個邏輯表,在物理層中都有對應的物理建模(單表或多表的物理建模)。
在之前的Quick BI版本中,資料模型僅有一個物理層;在V6.1及更高版本中,資料模型具有邏輯層和物理層,也就是新增了“關聯式模式”的能力。
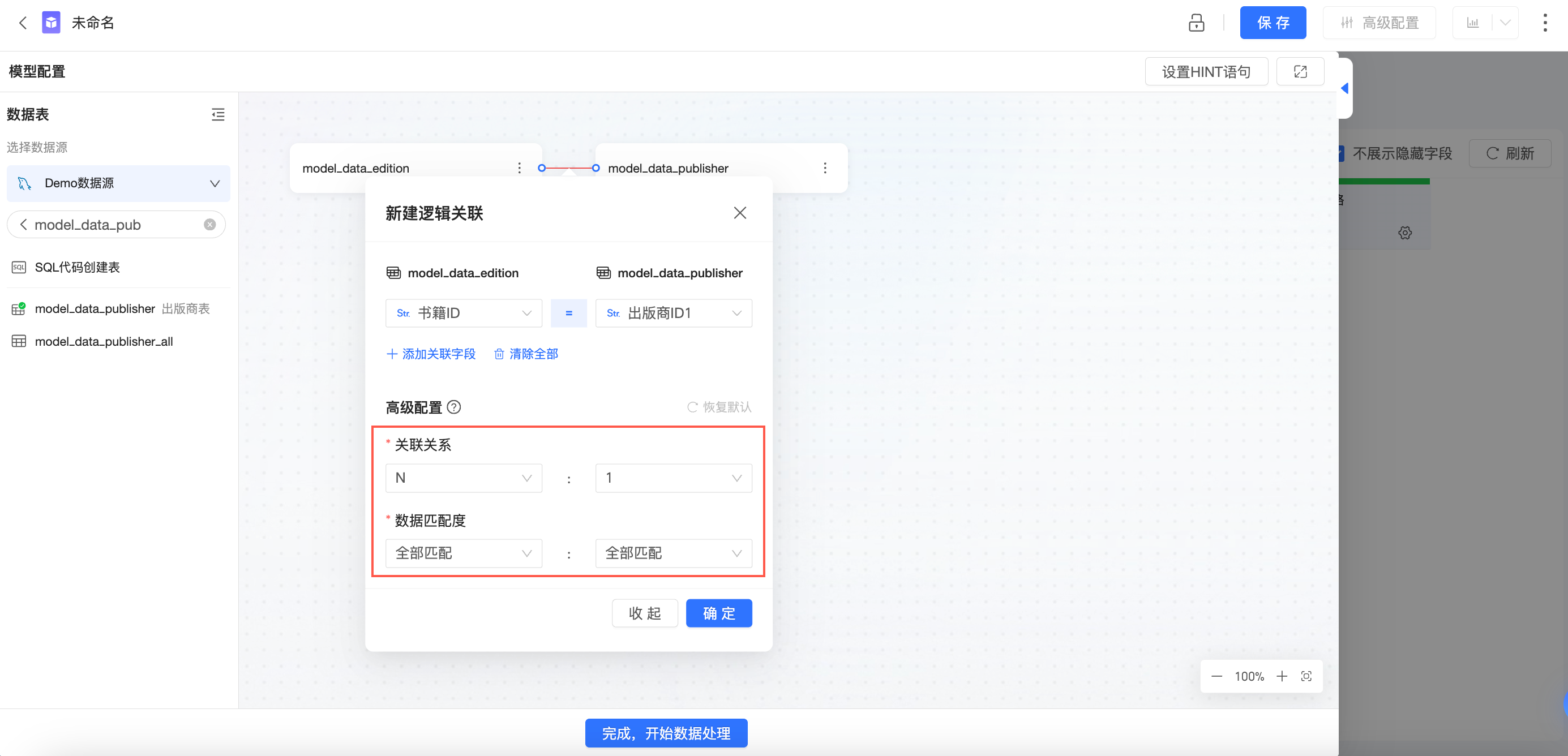
關聯關係和資料匹配度
在配置關係時,點擊“更多選項”,可配置資料的“關聯關係”和“資料匹配度”。Quick BI會根據您的配置選擇最合適的關聯方式進行查詢。若您能選擇準確的配置,Quick BI在查詢時將具有更好的效能。
當您不瞭解資料的具體分布,或者對“關聯關係”、“資料匹配度”的概念不熟悉時,請不要修改預設配置,否則有可能會導致資料膨脹、資料丟失等錯誤。
只有當您對資料分布有清晰的把控,並且確定未來也不會有所變動時,您可以通過調整“關聯關係”、“資料匹配度”的配置來最佳化關聯式模式的查詢效能。
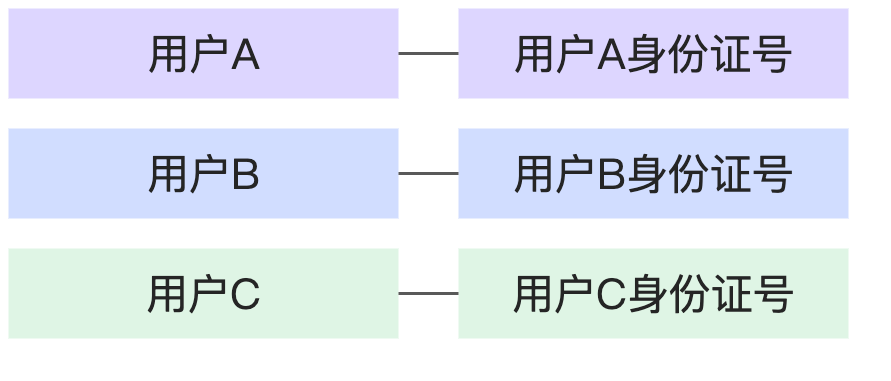
關聯關係
關聯關係表示1個表中的關聯鍵欄位值是否是唯一的,以及2個表中的關聯索引值是否能唯一對應
1:欄位值唯一
N:欄位值不唯一
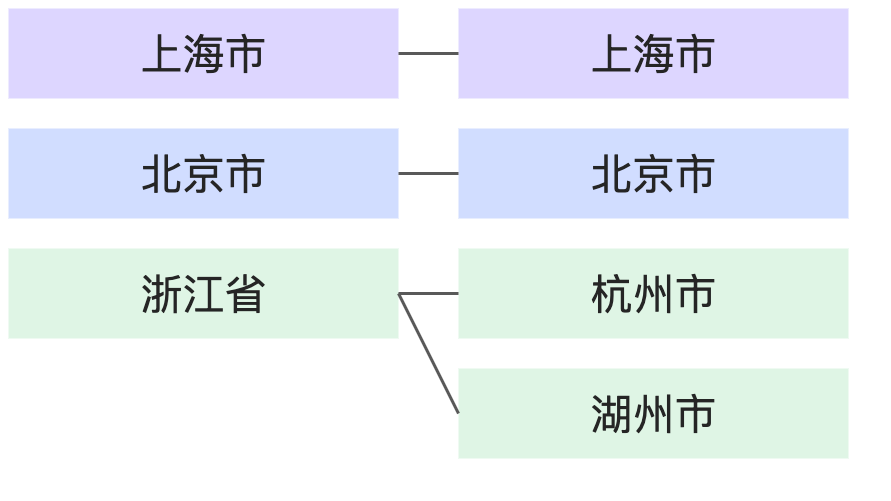
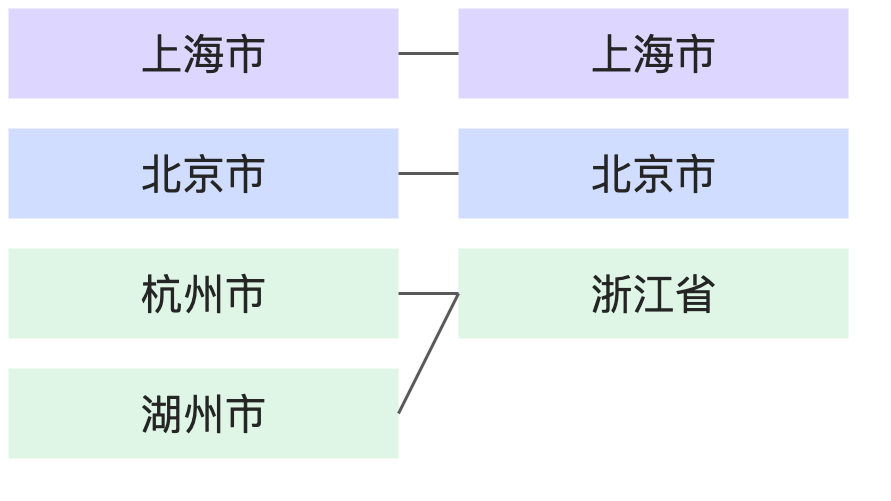
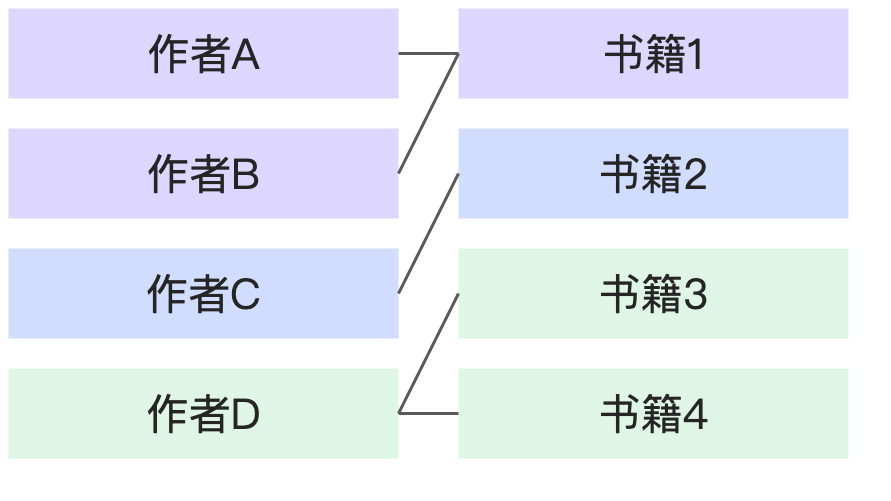
關聯關係 | 舉例 | 示意圖 |
1:1 | 每個人都只有1個社會安全號碼,每個社會安全號碼也僅對應1個人。 |
|
1:N | 每個省份對應N個城市,但每個城市只對應1個省份。 |
|
N:1 |
| |
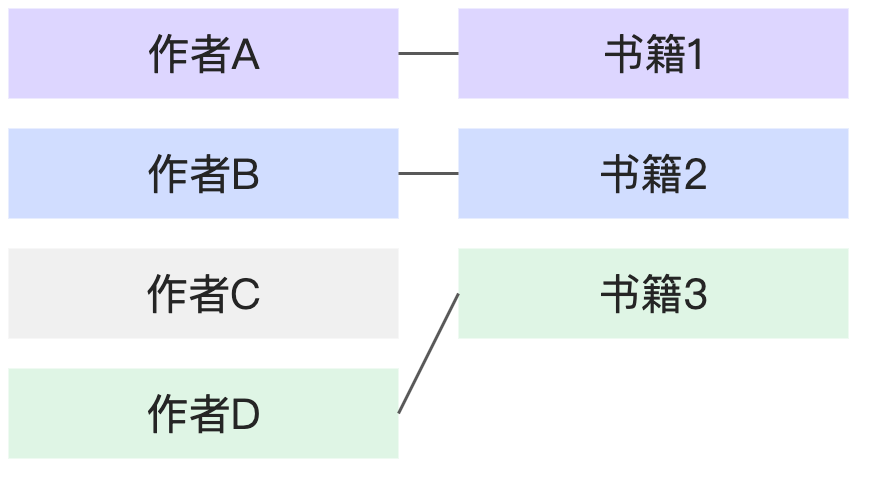
N:N | 1本書對應多個作者,1個作者也對應多本書。 |
|
資料匹配度
資料匹配度表示1個表中的關聯索引值是否能完整匹配到另一張表中,即:用於描述資料是否完整
部分匹配:存在欄位值無法與另一張表匹配
完全符合:所有欄位值都能與另一張表匹配
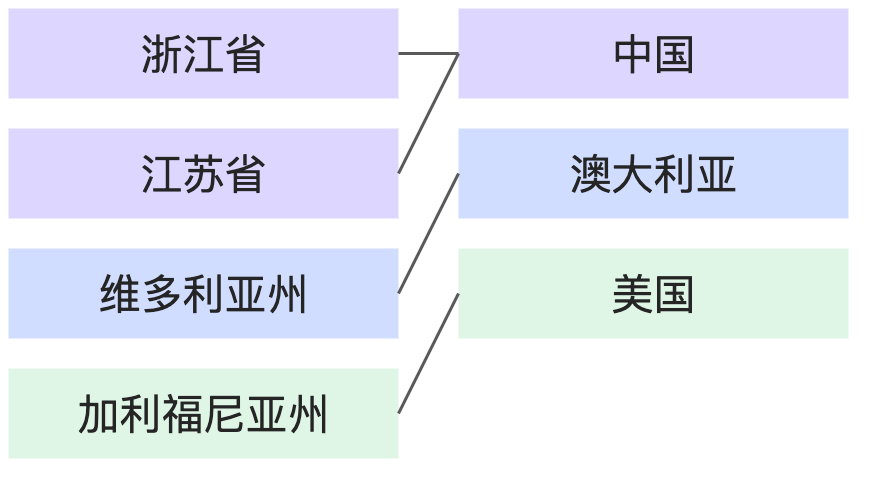
資料匹配度 | 舉例 | 示意圖 |
全部匹配:全部匹配 | 每個國家都有對應的省份,每個省份也都有對應的國家。 |
|
部分匹配:全部匹配 | 每本書都有對應的作者,但有的作者可能沒有對應的書(還未發表作品)。 |
|
全部匹配:部分匹配 | ||
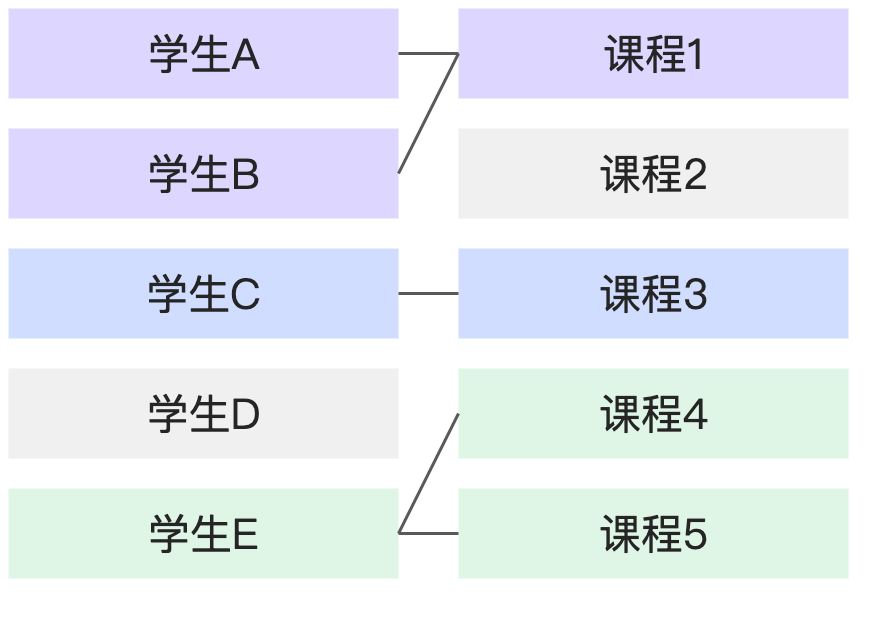
部分匹配:部分匹配 | 有的學生沒有對應的課程(還未選課),有的課程也沒有對應的學生(無人選課)。 |
|
關聯式模式適用情境
關聯式模式適用情境
情境一:業務使用者簡單資料建模
當使用者對於SQL、資料庫瞭解程度較淺時,推薦使用關聯式模式進行建模。
關聯式模式的配置比物理建模更簡單,只需要指定兩表之間的關聯鍵(無需修改“進階配置”,建議直接使用預設值)。並且關聯式模式可以有效避免資料膨脹,無需業務使用者關注資料完整性、唯一性等問題,有效降低建模門檻,提高建模準確性。
舉例說明
HR部門為鼓勵公司員工積极參与培訓、課程等活動,制定了積分機制,可通過參加活動擷取積分,積分可用來兌換禮品。資料庫底層有2張表,分別為:
積分擷取表:日期、員工ID、所在部門、參與活動名稱、擷取積分
積分兌換表:日期、員工ID、所在部門、兌換禮品名稱、消耗積分
積分擷取表和積分兌換表存在以下資料關係:
積分擷取表 - 積分兌換表 | ||
關聯關係 | N:N | 小王可以參與多個活動擷取積分,也可以多次兌換禮品;在2張表中,“員工ID”都是不唯一的。 |
資料匹配度 | 部分:全部 | 小王擷取了積分,但從未兌換禮品,因此“積分擷取表”裡有小王,“積分兌換表”裡沒有; 若某個員工從未擷取過積分,自然也無法兌換禮品,因此不會出現“積分兌換表”有,但“積分擷取表”裡沒有的情況。 |
當前,HR需要進行自助分析,查看每個員工的剩餘積分有多少。很自然地,HR直接通過“員工ID”欄位將2張表進行了物理關聯。但由於“員工ID”欄位在2張表中都不唯一,直接關聯會出現資料膨脹的問題。物理建模的正確做法是將2張表分別按照“員工ID”彙總,再進行關聯,但這需要一定的資料預先處理能力。
如果HR直接使用“關聯式模式”進行建模,則可以直接使用“員工ID”進行關聯,在實際計算中,Quick BI會自動進行資料的彙總處理,保證資料的正確性。
更多計算細節可參考:關聯式模式如何工作?
情境二:多分析情境下,關聯式模式提升資料集可複用性
當底層資料表數量相對較多時,IT使用者可以直接將所有有關係的表拖入邏輯畫布中,構造一份完整的關聯式模式。業務使用者在使用時,只需要選擇需要的欄位即可。通過這種方式,可以有效避免IT針對不同分析情境構造不同關聯大寬表,導致資料集數量堆積,難以維護和管理的問題。
在該情境下,建議IT使用者根據資料特性,對“關聯關係”、“資料匹配度”進行準確調整,從而提升資料查詢的效能,降低複雜建模對效能造成的影響。
舉例說明
還是以HR部門的積分擷取、積分兌換情境舉例:
積分擷取表:日期、員工ID、所在部門、參與活動名稱、擷取積分
積分兌換表:日期、員工ID、所在部門、兌換禮品名稱、消耗積分
與上一個例子不同的是,該公司要求中心化的IT團隊為所有分析師準備好資料集,因此HR同學向IT提出以下3個情境的資料需求;若IT同學通過物理建模的方式構造資料集,則必須為3個情境準備3個資料集。
情境 | 具體分析描述 | 物理建模處理 |
情境1 | 分析每場活動的參與人數、積分獲得情況 | 積分擷取表(單表建模) |
情境2 | 分析每種禮品的兌換人數、兌換次數等 | 積分兌換表(單表建模) |
情境3 | 分析每個員工的剩餘積分,展示剩餘積分熱門排行榜 | 積分擷取表和積分兌換表,分別根據“員工ID”彙總後,再進行關聯 |
由於“積分擷取表”和“積分兌換表”的資料粒度不一致,直接進行物理關聯會導致資料膨脹,無法保證資料正確性。但是在根據“員工ID”欄位彙總後,又會丟失“參與活動名稱”、“兌換禮品名稱”等資訊,無法實現“情境1”、“情境2”的分析。因此,在使用物理建模時,IT必須為HR準備3份資料集,以完成3個情境的分析。
但如果IT使用的是關聯式模式,則直接準備1份資料集即可,Quick BI會根據具體分析的欄位自動選擇合適的計算方式,以保證資料的正確性。
情境 | 具體分析描述 | 關係建模處理 | 拖入欄位 | 關聯式模式處理 |
情境1 | 分析每場活動的參與人數、積分獲得情況 | 關聯鍵:員工ID N:N 部分:全部 | 維度:參與活動名稱 度量:員工ID(去重計數)、擷取積分(求和) | 單表查詢 |
情境2 | 分析每種禮品的兌換人數、兌換次數等 | 維度:兌換禮品名稱 度量:員工ID(去重計數)、消耗積分(求和) | 單表查詢 | |
情境3 | 分析每個員工的剩餘積分,展示剩餘積分熱門排行榜 | 維度:員工ID 度量:SUM(擷取積分) - SUM(消耗積分) | 彙總後關聯 |
更多計算細節可參考:關聯式模式如何工作?
關聯式模式使用限制
效能限制
關聯式模式為避免資料膨脹,會對查詢SQL進行特殊的處理,這會使SQL更加複雜。相比於傳統的物理關聯,關聯式模式產生的查詢SQL會有更多的子查詢和嵌套層數,一定程度上將會降低查詢效能。並且,效能的表現與資料量和模型複雜程度有較大關係,隨著資料量變大以及模型複雜度變高,關聯式模式與物理模型之間的效能差距也會更加明顯。
若您對資料分布情況十分瞭解,可通過最佳化“關聯關係”和“資料匹配度”來最佳化查詢效能。一般情況下,各個配置的效能表現如下:
關聯關係:1:1 > 1:N = N:1 > N:N
資料匹配度:全部:全部 > 全部:部分 = 部分:全部 > 部分:部分
當您不瞭解資料的具體分布,或者對“關聯關係”、“資料匹配度”的概念不熟悉時,請不要修改預設配置,否則有可能會導致資料膨脹、資料丟失等錯誤。
只有當您對資料分布有清晰的把控,並且確定未來也不會有所變動時,您可以通過調整“關聯關係”、“資料匹配度”的配置來最佳化關聯式模式的查詢效能。
儘管如此,若您具有較好的資料處理能力,並且對查詢效能要求非常高時,我們仍然建議您繼續使用傳統的物理建模方式,從而避免因關聯式模式複雜邏輯引入的額外計算。
資料量限制
當度量來自於多個邏輯表時,QBI將以邏輯表為單位分別進行查詢計算,之後再將多個結果關聯,取得最終的結果。為保障查詢效率和Quick BI整體服務的穩定性,每次查詢將有1萬行的資料量限制。具體細節可參考關聯式模式如何工作?
此處的1萬行限制可以簡單理解為:彙總後的資料限制1萬行。比如:關聯欄位為“地區”,查詢維度為“產品類型”,則在對邏輯表進行查詢時,會按照“地區”和“產品類型”欄位進行彙總,彙總後的結果取前1萬行。
受關聯式模式計算複雜度的影響,無法通過分頁的方式取到1萬行之後的資料。若您需要執行更加“明細”粒度的資料查詢,或者您的查詢維度枚舉值過多時,關聯式模式的處理可能會導致資料不完整。該情境下,我們建議您繼續使用傳統的物理關聯進行建模。
功能限制
關聯式模式推出之後,資料集底層的處理和計算將有非常大的改造和最佳化,以下能力將無法相容老版本:
資源套件不支援將高版本資料集匯入到低版本中,否則將報錯。建議您先將目標環境升級到V6.1及之後版本,再進行資源套件的匯入。
舊版資料集詳情查詢介面“QueryDatasetDetailInfo”將無法繼續相容關聯式模式資料集,建議您切換為新版介面:QueryDatasetInfo
Quick BI在V6.1推出關聯式模式初版,以下功能僅支援單邏輯表資料集,對於多邏輯表資料集的支援將在後續版本中逐步補充:
抽取加速
LOD函數
資料準備
複雜過濾條件不允許選擇來自於多個邏輯表的欄位,以下功能點將受到限制:
行級許可權:包括條件組合授權、使用者標籤關聯授權
儀表板 - 複合查詢控制項
監控警示 - 警示規則