在LangStudio中搭建應用流使用知識庫節點,必須先建立一個LangStudio知識庫(僅需一次建立,即可在多個應用流中複用)。知識庫作為RAG(檢索增強產生)架構中的外部私人資料來源,需要從OSS讀取文檔來源資料,經過預先處理、分塊和向量化後,將索引儲存到向量資料庫中。本文將介紹知識庫的建立、配置和使用全流程。
工作原理
LangStudio知識庫的主要作用是將OSS資料來源中的檔案轉化為可供大模型檢索的格式,工作流程包含三個核心步驟:
資料讀取與分塊:系統從使用者指定的Object Storage Service中讀取源檔案。
非結構化文檔:被解析並切分成更小的、包含完整語義的文字區塊(Chunk)。
結構化資料:按行分塊。
圖片:不進行分塊,作為整體處理。
向量化(Embedding):調用Embedding模型,將每個資料區塊或圖片轉換為能夠表達其語義的數字向量。
入庫與索引:將產生的向量資料存入向量資料庫,並建立索引,以便於後續的高效檢索。
快速開始:建立並使用知識庫
本節快速建立一個文件類型的知識庫,並在工作流程中使用。
建立知識庫。進入LangStudio,選擇工作空間後,在知识库頁簽單擊新建知识库。配置如下關鍵參數,其餘保持預設,然後單擊確定。
參數
說明
基础配置
知识库名称
自訂知識庫名稱,如
test_kg。数据源OSS路径
知識庫源檔案儲存體的位置。例如:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/original/。输出OSS路径
儲存文檔解析產生的中間結果和索引資訊,最終輸出內容與所選向量資料庫類型相關。例如:
oss://examplebucket.oss-cn-hangzhou-internal.aliyuncs.com/test/output/。重要若運行時設定的執行個體RAM角色為PAI預設角色,建議將此參數配置為當前工作空間預設儲存路徑所在的OSS Bucket下的任一目錄。
知识库类型
選擇文檔。
Embedding模型和数据库
Embedding类型
選擇百炼大模型服务(需提前建立串連,參見串連配置),然後選擇建立好的串連和模型。
向量数据库类型
選擇FAISS以便快速測試。
上傳檔案。
在知识库頁簽,單擊剛剛建立的知識庫,進入概览頁面,切換到文檔頁簽。這裡會顯示知識庫設定的資料來源OSS路徑下的文檔。
通過頁面的上传按鈕可以新增或更新檔案,也可以將檔案直接上傳到資料來源OSS路徑。例如,通過頁面上傳rag_test_doc.txt。更多支援的檔案格式參見知識庫類型。
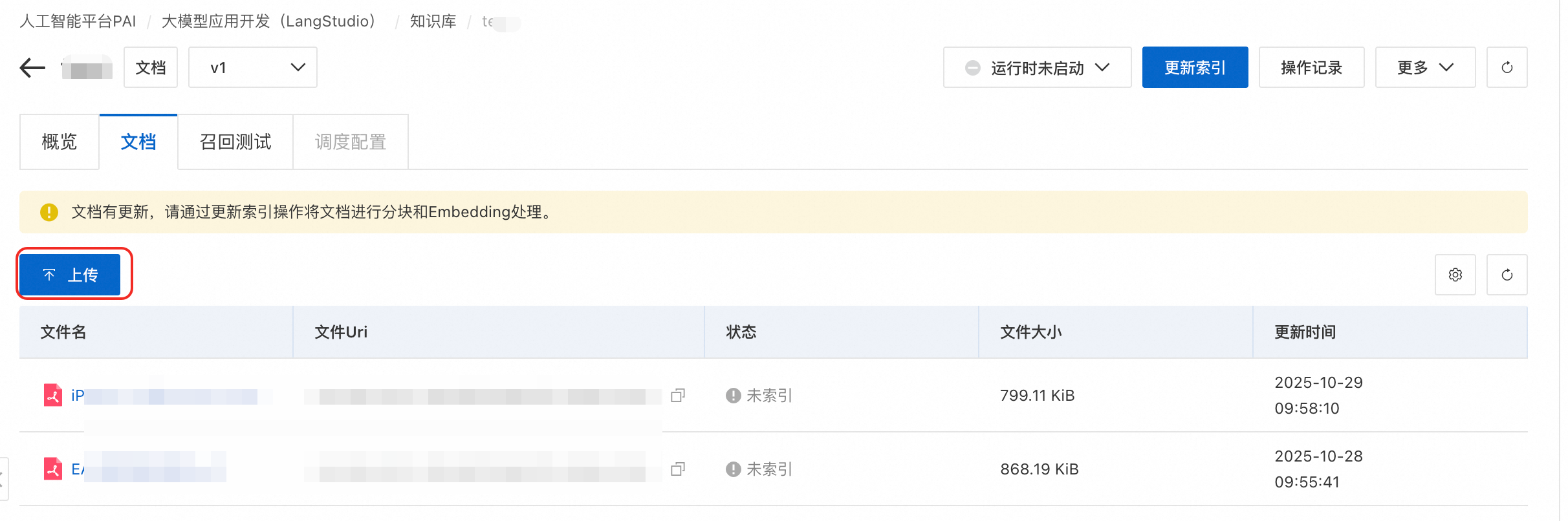
更新索引。檔案上傳後,單擊右上方更新索引,在彈出的頁面中配置計算資源和網路。更新索引任務執行成功之後,檔案狀態會變為已索引,單擊檔案可預覽文檔分塊(圖片知識庫將返回圖片列表)。
說明對於已存入Milvus的文檔分塊,可以單獨設定其狀態為啟用或禁用。被禁用的分塊將不會被檢索到。
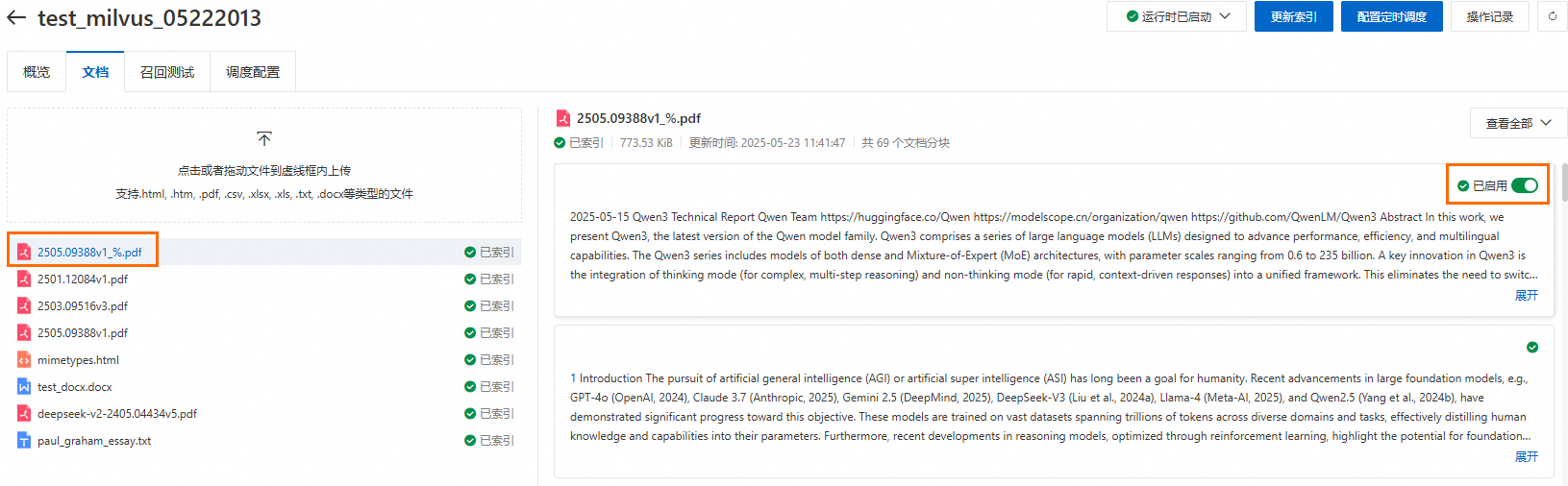
召回測試。更新索引成功後,切換到召回测试頁簽,輸入問題並調整檢索參數,可測試召回效果。
在應用流中使用。完成測試之後,可以在應用流中通過知識庫來檢索資訊。在知識庫節點中可開啟查詢重寫和結果重排功能,並能在鏈路中查看重寫後的問題。
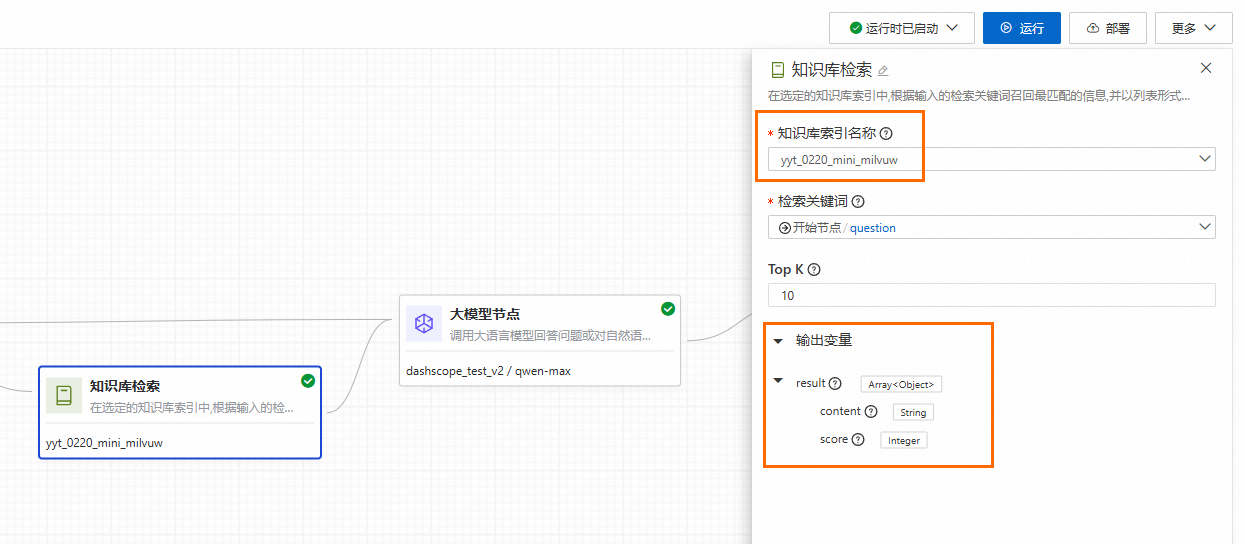
返回結果為List[Dict],其中Dict的Key包含
content和score,分別對應文檔分區與輸入查詢的內容和相似性得分。[ { "score": 0.8057173490524292, "content": "受疫情帶來的不確定性影響,xx銀行根據經濟走勢及中國或中國內地環境預判,主動\n加大了貸款和墊款、非信貸資產減值損失的計提力度,加大\n不良資產核銷處置力度,提升撥備覆蓋率,2020 年實現淨利\n潤289.28億元,同比增長 2.6%,盈利能力逐步改善。\n(人民幣百萬元) 2020年 2019年 變動(%)\n經營成果與盈利\n營業收入 153,542 137,958 11.3\n減值損失前營業利潤 107,327 95,816 12.0\n淨利潤 28,928 28,195 2.6\n成本收入比(1)(%) 29.11 29.61下降 0.50個\n百分點\n平均總資產收益率 (%) 0.69 0.77下降 0.08個\n百分點\n加權平均淨資產收益率 (%) 9.58 11.30下降 1.72個\n百分點\n淨息差(2)(%) 2.53 2.62下降 0.09個\n百分點\n註: (1) 成本收入比 =業務及管理費/營業收入。", "id": "49f04c4cb1d48cbad130647bd0d75f***1cf07c4aeb7a5d9a1f3bda950a6b86e", "metadata": { "page_label": "40", "file_name": "2021-02-04_中國xx保險集團股份有限公司_xx_中國xx_2020年__年度報告.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__中國xx保險集團股份有限公司__601318__中國xx__2020年__年度報告.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } }, { "score": 0.7708036303520203, "content": "72億元,同比增長 5.2%。\n2020年\n(人民幣百萬元)壽險及\n健康險業務財產保險\n業務 銀行業務 信託業務 證券業務其他資產\n管理業務 科技業務其他業務\n及合并抵消 集團合并\n歸屬於母公司股東的淨利潤 95,018 16,083 16,766 2,476 2,959 5,737 7,936 (3,876) 143,099\n少數股東損益 1,054 76 12,162 3 143 974 1,567 281 16,260\n淨利潤 (A) 96,072 16,159 28,928 2,479 3,102 6,711 9,503 (3,595) 159,359\n剔除專案 :\n 短期投資波動(1)(B) 10,308 – – – – – – – 10,308\n 折現率變動影響 (C) (7,902) – – – – – – – (7,902)\n 管 理層認為不屬於 \n日常營運收支而剔除的 \n一次性重大專案及其他 (D) – – – – – – 1,282 – 1,282\n營運利潤 (E=A-B-C-D) 93,666 16,159 28,928 2,479 3,102 6,711 8,221 (3,595) 155,670\n歸屬於母公司股東的營運利潤 92,672 16,", "id": "8066c16048bd722d030a85ee8b1***36d5f31624b28f1c0c15943855c5ae5c9f", "metadata": { "page_label": "19", "file_name": "2021-02-04_中國xx保險集團股份有限公司_xxx_中國xx__2020年__年度報告.pdf", "file_path": "oss://my-bucket-name/datasets/chatglm-fintech/2021-02-04__中國xx保險集團股份有限公司__601318__中國xx__2020年__年度報告.pdf", "file_type": "application/pdf", "file_size": 7982999, "creation_date": "2024-10-10", "last_modified_date": "2024-10-10" } } ]
功能詳解
知識庫類型
知識庫分為文檔、結構化資料、圖片三種類型,請根據檔案類型選擇建立不同類型的知識庫。
文檔:支援
.html、.htm、.pdf、.txt、.docx、.md和.pptx。結構化資料:支援
.jsonl、.csv、.xlsx和.xls。圖片:支援
.jpg、.jpeg、.png、.bmp。
特殊配置:
文件類型知識庫需進行文档解析分块配置,所需配置欄位如下,關於如何合理設定分塊參數,請參見分塊參數調優。
文本分块大小:設定每個文字區塊的最大字元數,預設為 1024(字元)。
文本分块重叠大小:為確保檢索資訊連貫性,設定相鄰文字區塊重疊的字元數,預設為200(字元)。
結構化資料類型知識庫需進行字段配置。直接上傳檔案(如animal.csv)或手動添加欄位,可以分別指定參與索引和召回的資料欄位。
向量資料庫選擇
生產環境:建議使用Milvus和Elasticsearch,支援處理大規模的向量資料。
測試環境:建議使用FAISS,無需額外建立資料庫(知識庫檔案及產生的索引檔案將存放於输出OSS路径中)。適合功能測試或處理小規模檔案,檔案量過大時會顯著影響檢索和處理效能。
說明圖片類型知識庫不支援使用FAISS。
索引更新策略
更新方式 | 描述 | 注意事項 |
手動更新 | 在控制台手動單擊更新索引。適用於檔案不頻繁變更的情境。 | 每次更新都會全量或增量處理資料來源中的檔案。 |
自動更新 | 在控制台啟動自動更新後,系統會自動在事件匯流排建立事件規則並轉寄OSS檔案變更訊息,從而自動建立索引任務。 | 重要 自動更新服務過程中會產生相應的訊息費用。
|
定時更新 | 通過配置 DataWorks 周期任務,按指定頻率(如每天)更新索引。 | 該功能依賴 DataWorks 服務。DataWorks 的周期任務通常是 T+1 生效,即當天的配置將在次日首次執行。 |
配置方式如下:
手動更新
檔案上傳後,單擊右上方更新索引,系統會提交一個PAI工作流程工作,對OSS資料來源中的檔案進行預先處理、分塊和向量化並構建索引。任務參數配置說明如下:
參數 | 描述 |
計算資源 | 執行工作流程節點任務所需的計算資源,可使用公用資源或者通過資源配額使用靈駿智算資源和通用計算資源。
|
專用網路配置 | 若通過內網訪問向量資料庫或 Embedding 服務,請確保所選 VPC 與這些服務的 VPC 相同或可互連。 |
Embedding配置 |
|
自動更新
前往EventBridge控制台,開通事件匯流排EventBridge。
配置索引自動更新。進入知識庫詳情頁,在概览頁簽右下角的文件索引自动更新地區,單擊編輯。
配置計算資源和專用網路,填寫完成後點擊確定按鈕即可。此後檔案變更會自動觸發索引任務,使用者無需再手動調用。
重要此處配置的計算資源僅在檔案更新後使用,檔案不發生更新的情況下不會產生資源費用。
OSS檔案變更。
檔案自動更新配置完成後,規則生效有分鐘級的延時,建議等待3分鐘後再操作檔案。
通過OSS API 刪除檔案時,必須指定版本,否則無法觸發變更訊息。
在控制台上刪除,需要選擇檔案後點擊下方的徹底刪除。
查看索引任務。檔案變更後,等待3分鐘左右,即可在操作記錄列表中看到自動觸發的索引構建任務。
定時更新
定時調度功能依賴於DataWorks,請確保您已開通該服務。若未開通,請前往開通DataWorks服務。
在知識庫詳情頁,單擊右上方的,完成相關配置後提交。
查看調度配置/周期任務
提交表單後,系統會自動在DataWorks資料開發中心建立知識庫定時調度的Workflow,並發布到DataWorks資料營運中心的周期任務(目前周期任務是T+1生效),DataWorks周期任務會按您配置的定時調度時間執行更新知識庫的操作。您可以在知識庫詳情的調度配置頁面,查看調度配置和周期任務。
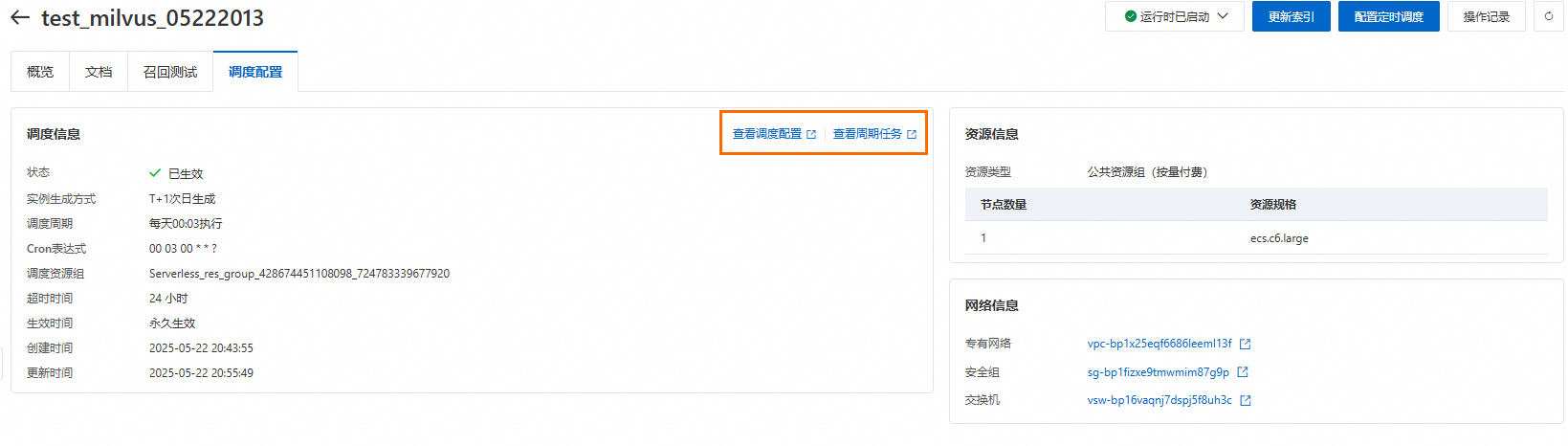
定時調度配置參數說明:
調度周期:用於定義節點在生產環境中的運行頻率(組建循環執行個體個數及執行個體啟動並執行時間)。
調度時間:用於定義節點具體啟動並執行時間。
逾時定義:用於定義節點運行超過多長時間會失敗退出。
生效日期:用於定義節點正常自動調度啟動並執行時間範圍,該時間範圍外,節點將不再自動調度。
調度資源群組:用於DataWorks定時調度功能。如果尚未建立DataWorks資源群組,可單擊下拉框中的立即建立跳轉至建立頁面。建立完成後,需將資源群組綁定到當前工作空間。
更多調度參數說明,請參見時間屬性配置說明。
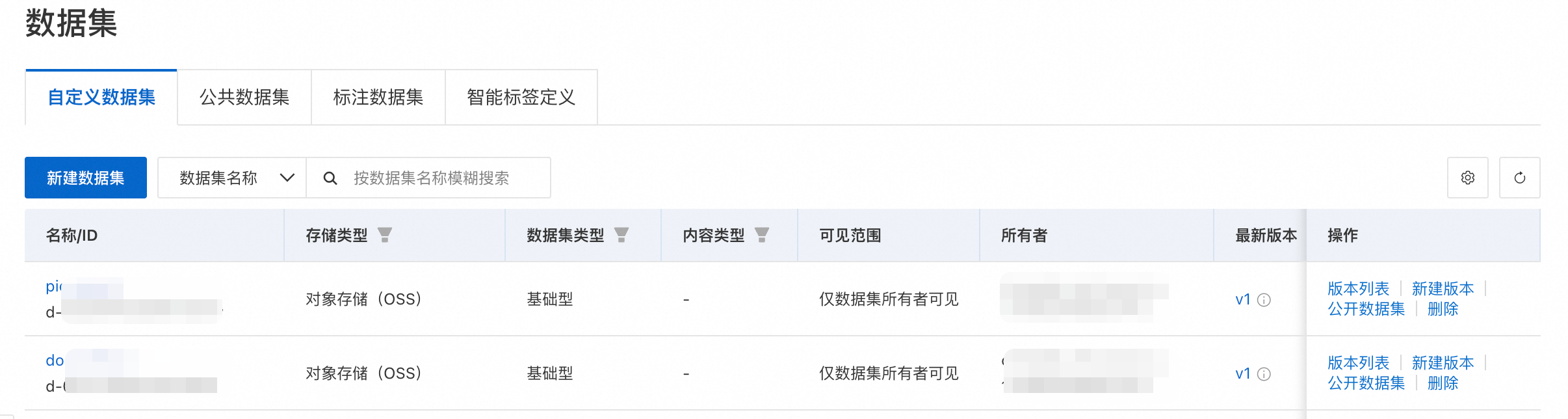
查看資料集
更新索引任務成功之後,系統會自動將输出OSS路径註冊為資料集。可以在AI資產管理-資料集中查看。這個資料集與知識庫同名,記錄了索引構建過程的輸出資訊。
設定運行時
選擇一個運行時,用於執行文檔分塊預覽、召回測試(即檢索效果測試)等操作(需訪問向量資料庫和Embedding服務)。
請注意運行時的設定:
若通過內網地址訪問向量資料庫或 Embedding 服務,請確保運行時的 VPC 網路與它們保持一致或可互連。
若執行個體RAM角色選擇自訂角色,請務必為該角色授予 OSS 存取權限(建議授予AliyunOSSFullAccess許可權),詳情請參見管理RAM角色的許可權。
如果您的運行時版本過舊(低於 2.1.4),可能無法在下拉框中選擇。請重新建立一個運行時即可。
多版本管理
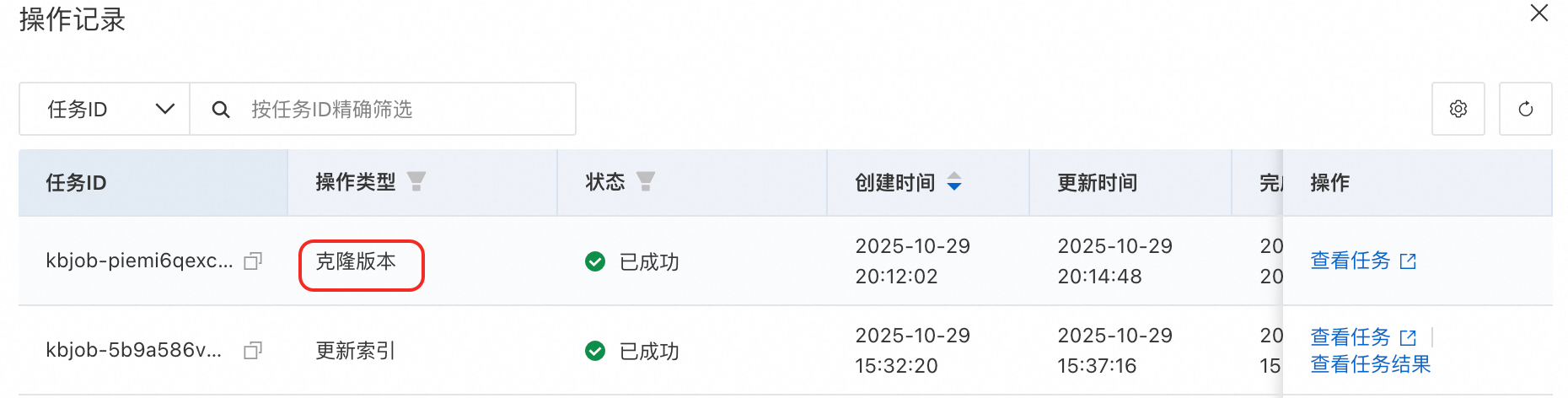
通過版本複製功能,可以將測實驗證好的知識庫(v1版本)發布為一個新的正式版本,從而實現開發環境與生產環境的隔離。
複製版本成功後,可以在知識庫詳情頁的類型旁切換和管理不同版本,同時在應用流的知識庫檢索節點中選擇需要使用的版本。

複製版本和更新索引類似,會提交一個工作流程工作,可在操作記錄中查看任務。
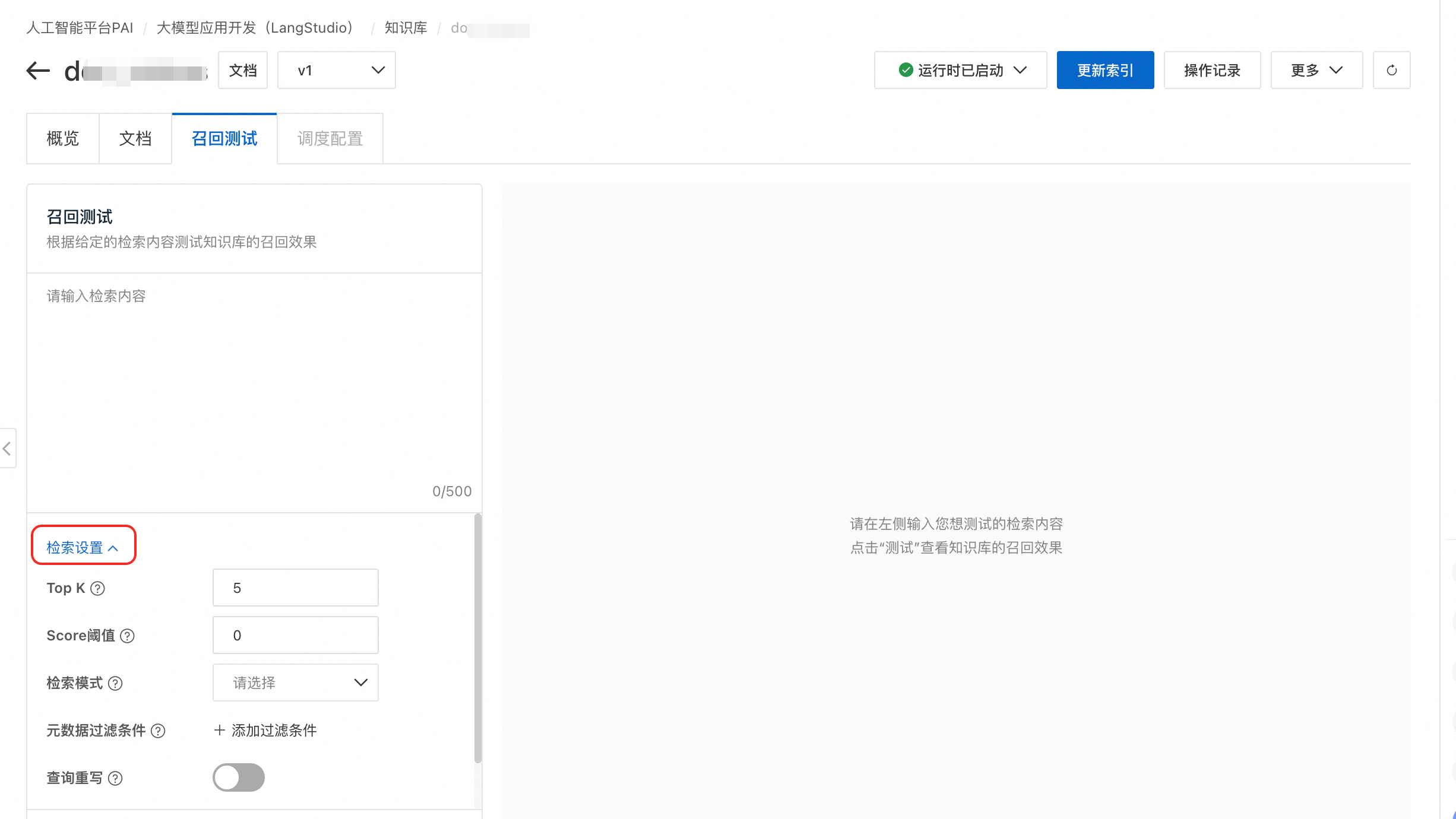
檢索參數設定
Top K:控制從知識庫中最多檢索多少個相關的文本片段,取值範圍 1~100。
Score閾值:設定相似性分數門檻(0~1),只有高於此分數的片段才會被返回。數值越高說明對文本與檢索內容要求的相似性越高。
檢索模式:預設Dense(向量檢索)。如果需要使用 Hybrid 混合檢索(向量+關鍵字),向量資料庫需為 Milvus 2.4.x 以上 或 Elasticsearch。檢索模式選擇請參見選擇檢索模式。
中繼資料過濾條件:通過中繼資料對檢索範圍進行精確過濾,提升準確性。詳情參見使用中繼資料。
查詢重寫:利用大語言模型最佳化使用者模糊、口語化或依賴內容相關的原始查詢,使其更清晰完整、意圖更明確,以提升檢索準確率。使用情境請參見查詢重寫。
結果重排:使用重排模型對初步檢索到的結果進行二次排序,將最相關的結果排在最前。使用情境請參見結果重排。
說明結果重排需要使用重排模型。支援的模型服務連線類型有:百鍊大模型服務、AI搜尋開放平台模型服務、通用Reranker模型服務。
故障排查
當索引更新或複製版本任務失敗時,請按以下步驟排查:
查看操作記錄:在知識庫詳情頁的操作记录中,找到失敗的任務,單擊查看任務。

檢查任務日誌:系統會跳轉到 PAI 工作流程頁面。檢查失敗節點的日誌。
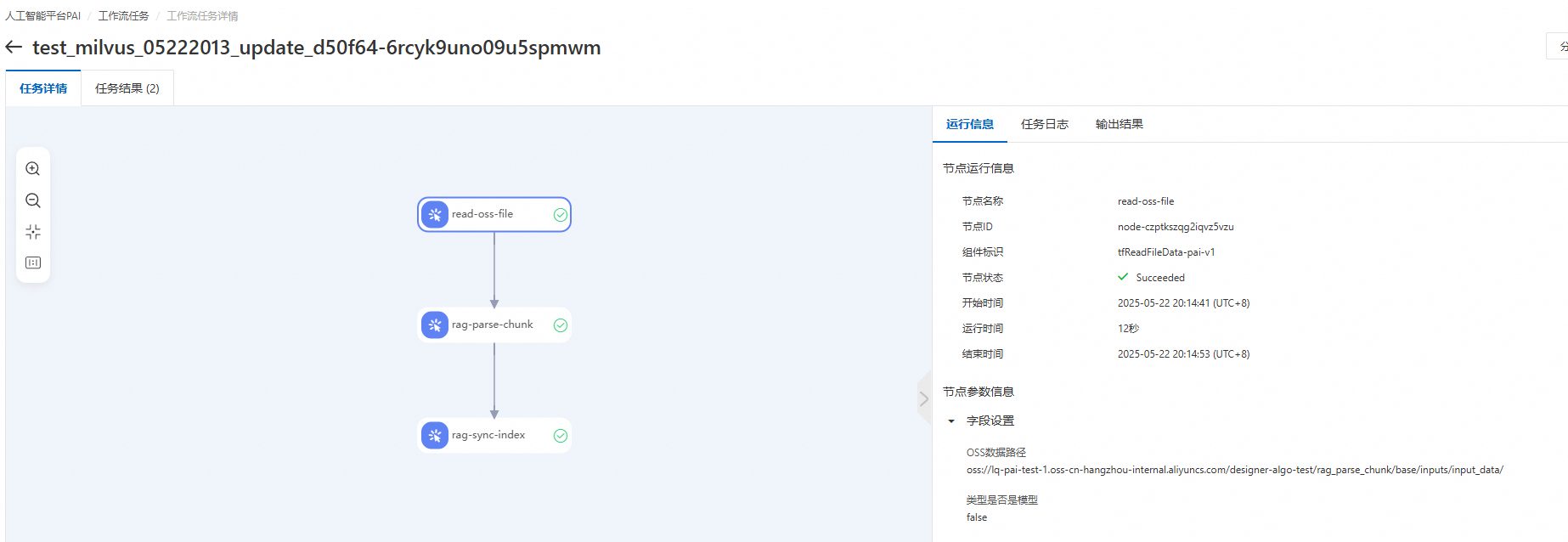 例如,文件類型知識庫更新索引的工作流程工作包括以下三個節點,除read-oss-file節點外,每個節點會建立一個PAI-DLC任務。還可以通過日誌中的Job URL來查看DLC任務詳情。
例如,文件類型知識庫更新索引的工作流程工作包括以下三個節點,除read-oss-file節點外,每個節點會建立一個PAI-DLC任務。還可以通過日誌中的Job URL來查看DLC任務詳情。read-oss-file:讀取OSS檔案。
rag-parse-chunk:負責文檔的預先處理和分塊。
rag-sync-index:負責對文字區塊進行 Embedding 處理,並將其同步至向量資料庫。
檢索最佳化
分塊參數調優:奠定召回基礎
設定原則
模型上下文限制:確保分塊大小不超過 Embedding 模型處理的 token 上限,避免資訊被截斷。
資訊完整性:分塊應足夠大以包含完整語義,但也要避免因包含過多資訊而影響相似性計算的精度。如果常值內容是按段落組織的,可以選擇讓每個塊包含完整的段落,而不是生硬地切割。
保持連續性:設定適當的重疊大小(建議為分塊大小的10%-20%),可以有效避免因分塊邊界切割關鍵資訊而導致的上下文丟失。
避免重複幹擾:過多的重疊會引入重複資訊,影響檢索效率。需要在“資訊完整性”和“資訊冗餘”之間找到平衡。
調試建議
迭代最佳化:從一個初始值(如分塊大小300,重疊大小50)開始,根據實際的檢索和問答效果不斷調整、嘗試,找到最適合資料特性的設定。
自然語言邊界:如果文本結構清晰(如按章節、段落劃分),可優先考慮基於自然語言邊界進行切分,以最大程度保持語義完整性。
快速最佳化指南
問題現象 | 最佳化建議 |
檢索結果不相關 | 增大分塊大小,減少分塊重疊大小。 |
結果上下文不連貫 | 增大分塊重疊大小。 |
找不到合適的匹配(召回率低) | 適當增加分塊大小。 |
計算或儲存開銷過高 | 降低分塊大小,減少分塊重疊大小。 |
以下是基於以往經驗推薦的各類文本對應的分塊大小和重疊大小:
文本類型 | 推薦分塊大小(chunk_size) | 推薦重疊大小(chunk_overlap) |
短文本(FAQ、摘要) | 100~300 | 20~50 |
普通文本(新聞、部落格) | 300~600 | 50~100 |
技術文檔(API、論文) | 600~1024 | 100~200 |
長篇文檔(法律、書籍) | 1024~2048 | 200~400 |
選擇檢索模式:平衡語義與關鍵詞
檢索模式決定了系統如何匹配您的問題和知識庫中的內容。不同的模式各有優劣,適用於不同情境。
Dense(向量)檢索:擅長理解語義。將問題和文檔都轉換為向量,通過計算向量間的相似性來判斷語義相關性。
Sparse(關鍵詞)檢索:擅長精確匹配。基於傳統的詞頻統計模型(如 BM25),通過關鍵詞在文檔中的出現頻率和位置計算相關性。
Hybrid (混合)檢索:兼顧兩者。結合向量檢索和關鍵詞檢索的結果,通過 RRF(Reciprocal Rank Fusion) 或加權融合演算法(如線性加權、模型整合)重新排序。
檢索模式 | 優缺點 | 適用情境 |
Dense(向量)檢索 |
|
|
Sparse(關鍵詞)檢索 |
|
|
Hybrid (混合)檢索 |
|
|
使用中繼資料:過濾檢索
中繼資料過濾的價值
精準檢索,減少雜訊幹擾:中繼資料可作為檢索時的過濾條件或排序依據,通過中繼資料過濾,可排除不相關的文檔,避免將無關內容引入產生模型。例如:使用者提問“尋找劉慈欣寫的科幻小說”時,系統可以通過
作者=劉慈欣和類別=科幻兩個中繼資料條件,直接定位到最相關的文檔。提升使用者體驗
支援個人化推薦:可根據使用者的歷史偏好(如喜歡“科幻類”文檔),利用中繼資料進行個人化推薦。
增強結果解釋性:在結果中附上文檔的元資訊(如作者、來源、時間),協助使用者判斷內容的可信度和相關性。
支援多語言或多模態擴充:通過“語言”、“媒體類型”等中繼資料,可以輕鬆管理組件含多語言、圖文混合的複雜知識庫。
使用方式
功能限制:
運行時鏡像版本:需為 2.1.8 或更高版本。
向量資料庫:僅支援Milvus和Elasticsearch。
知識庫類型:支援文檔或結構化資料,不支援圖片。
配置中繼資料變數。僅使用Milvus的知識庫在概览頁簽可以找到元数据地區,單擊編輯進行配置(如變數名稱為
author),請注意不要使用系統預留欄位。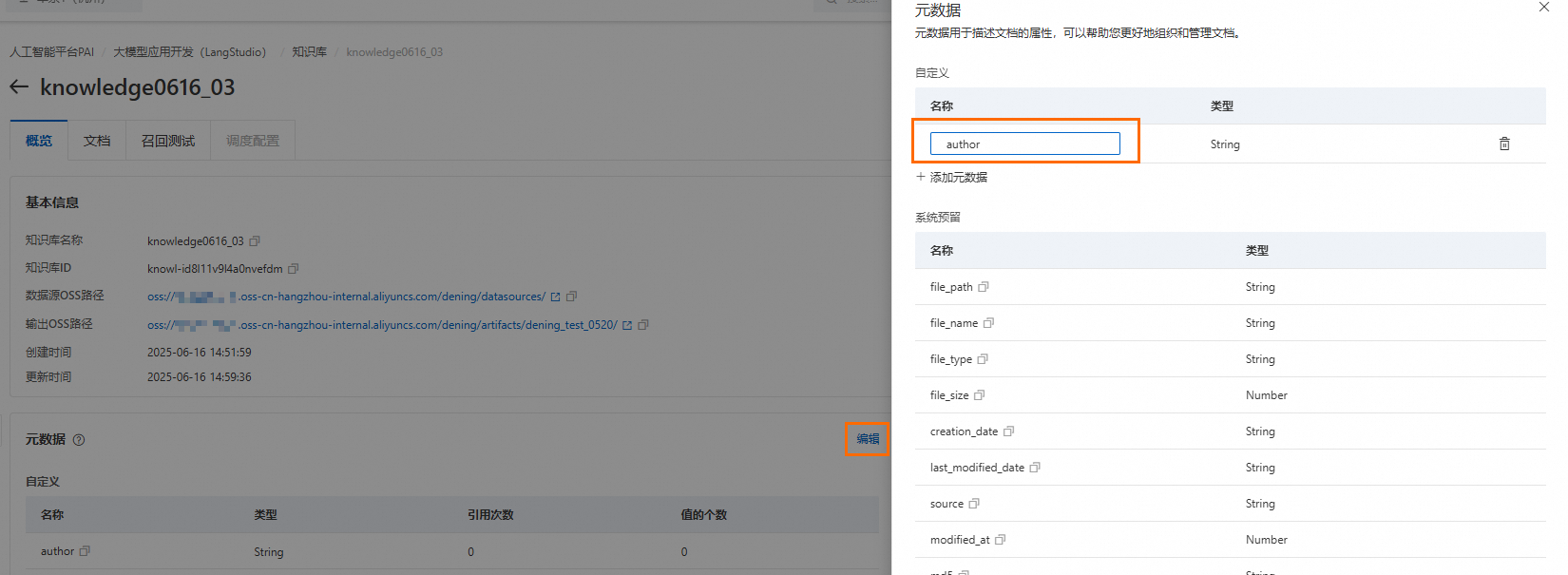
為文檔打標。進入文檔分塊詳情頁面,單擊编辑元数据,添加中繼資料變數和值(如
author=Alex)。回到概覽頁可以看到中繼資料的引用情況及值的個數。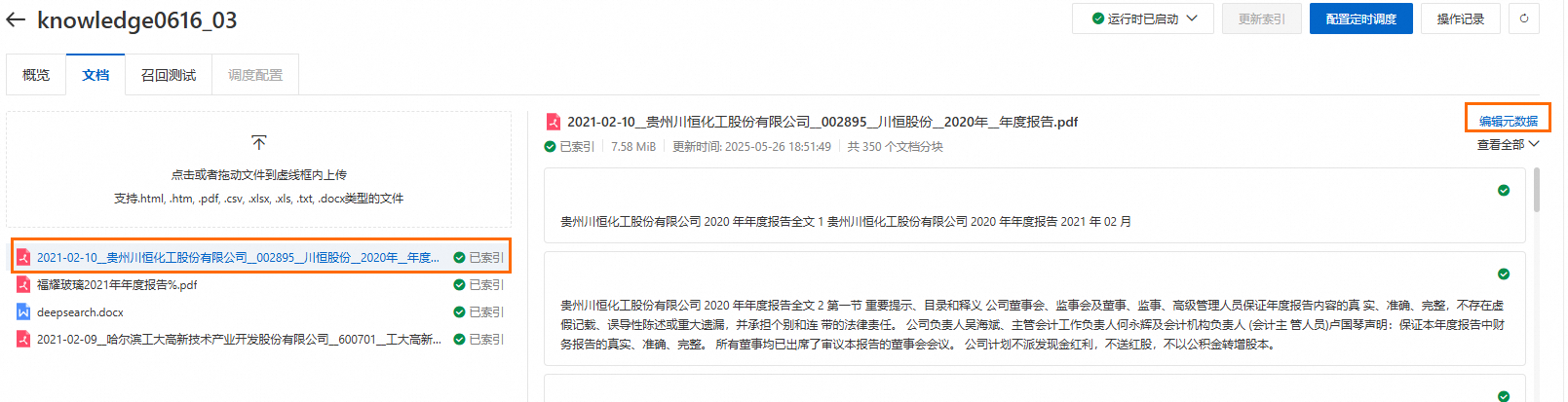
測試過濾效果。在召回测试頁簽,添加中繼資料過濾條件並進行測試。
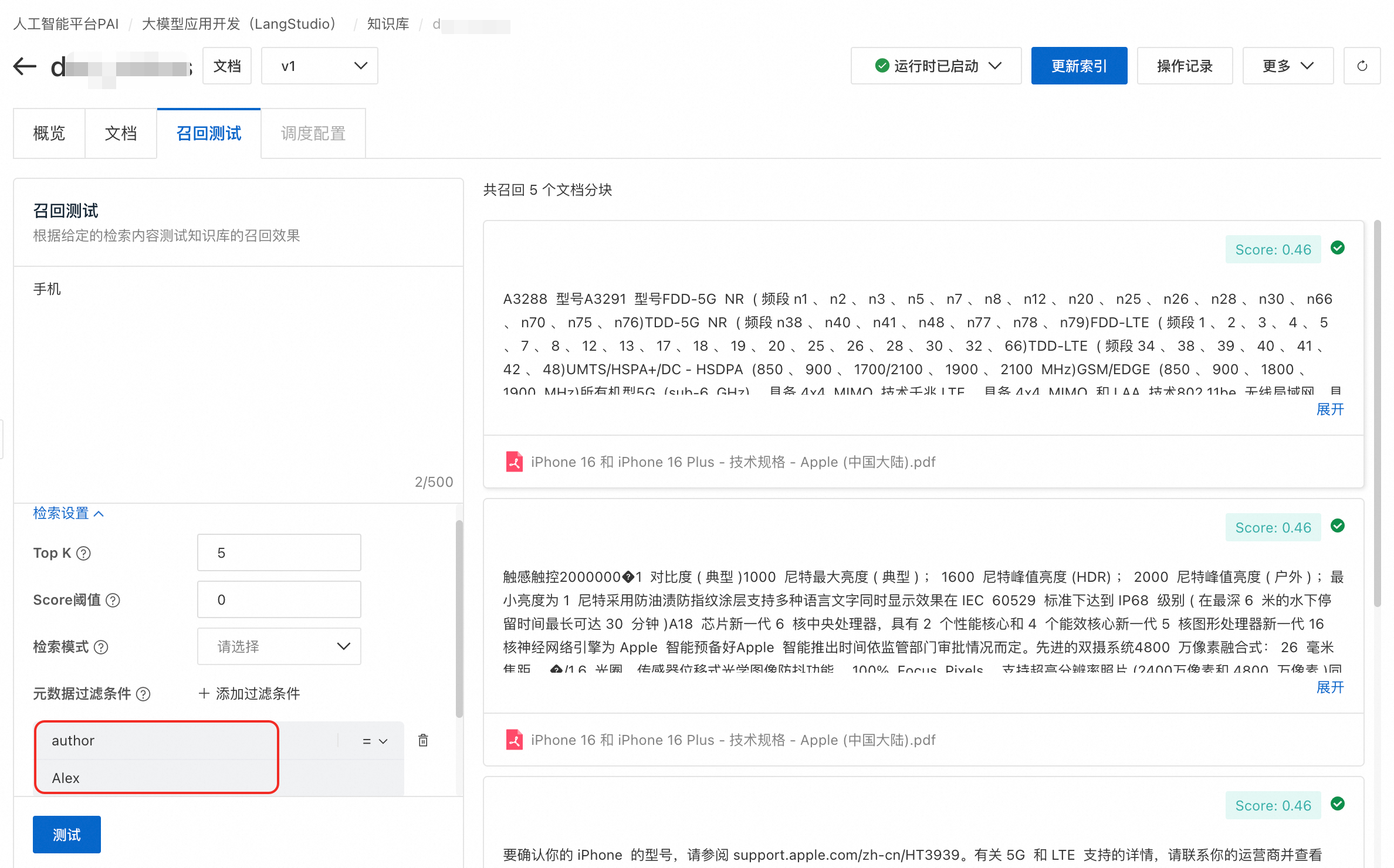
註:圖中召回的文檔均為步驟2中打標的文檔。
在應用流中使用。在知識庫節點中配置中繼資料過濾條件。
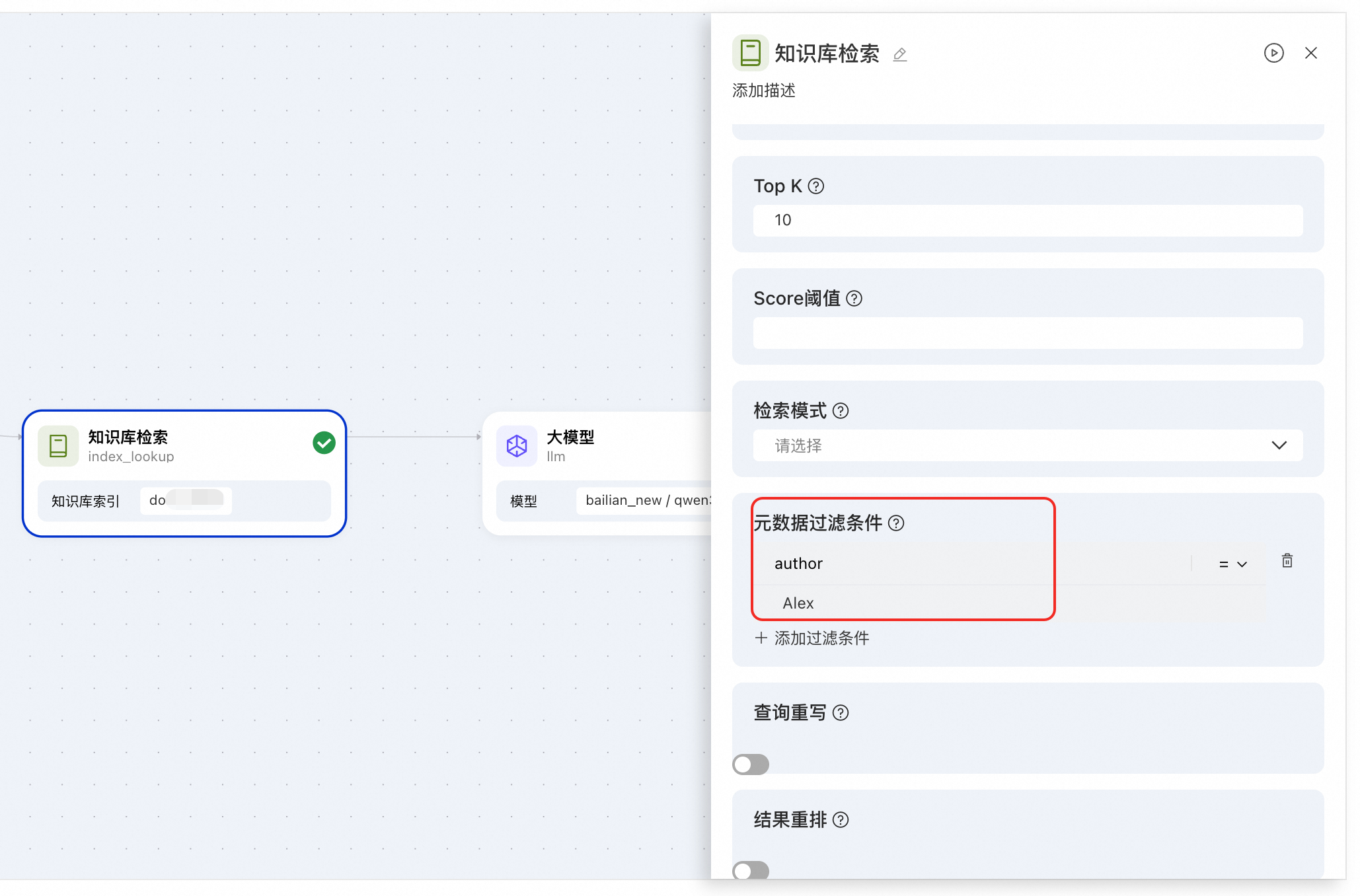
查詢重寫與結果重排:最佳化檢索鏈路
查詢重寫
利用大語言模型將使用者模糊、口語化或依賴內容相關的問題,改寫成一個更清晰、更完整的獨立問題,從而提升後續的檢索準確率。
建議使用情境:
使用者問題模糊、不完整(如“他什麼時候出生的?”但沒有上下文)。
多輪對話中,問題依賴上下文(如“那他後來做了什嗎?”)。
檢索器或LLM 效能較弱,對原始問題理解不準確時。
使用的是傳統倒排索引檢索(如BM25)而非語義檢索時。
不建議使用的情境:
使用者問題已經非常清晰明確。
LLM 效能非常好,對原始問題理解能力強。
系統要求低延遲,無法接受重寫帶來的額外延遲。
結果重排
對檢索器返回的初始結果進行重新排序,優先展示最相關的文檔,提升排序品質。
建議使用情境:
初步檢索器(如BM25或DPR)返回的結果品質不穩定。
對檢索結果的排序要求高(如搜尋、問答系統中要求Top 1準確率)。
不建議使用的情境:
系統資源受限,無法承受額外的推理開銷。
初步檢索器的效能已足夠強大,重排帶來的提升有限。
對回應時間要求極高,如即時搜尋情境。