使用DataWorks資料地圖查看錶或資料服務API時,可在對應的詳情頁面查看詳細的血緣資訊,這對於資料溯源及管理有很大協助。當前控制台按EMR Hive、Data Lake Formation(DLF)與資料湖構建(DLF-Legacy)等類型納管計算與中繼資料,本文與您在資料地圖、資料開發中看到的分類保持一致,並說明各類型下的血緣查看方式。
錶血緣
查看入口
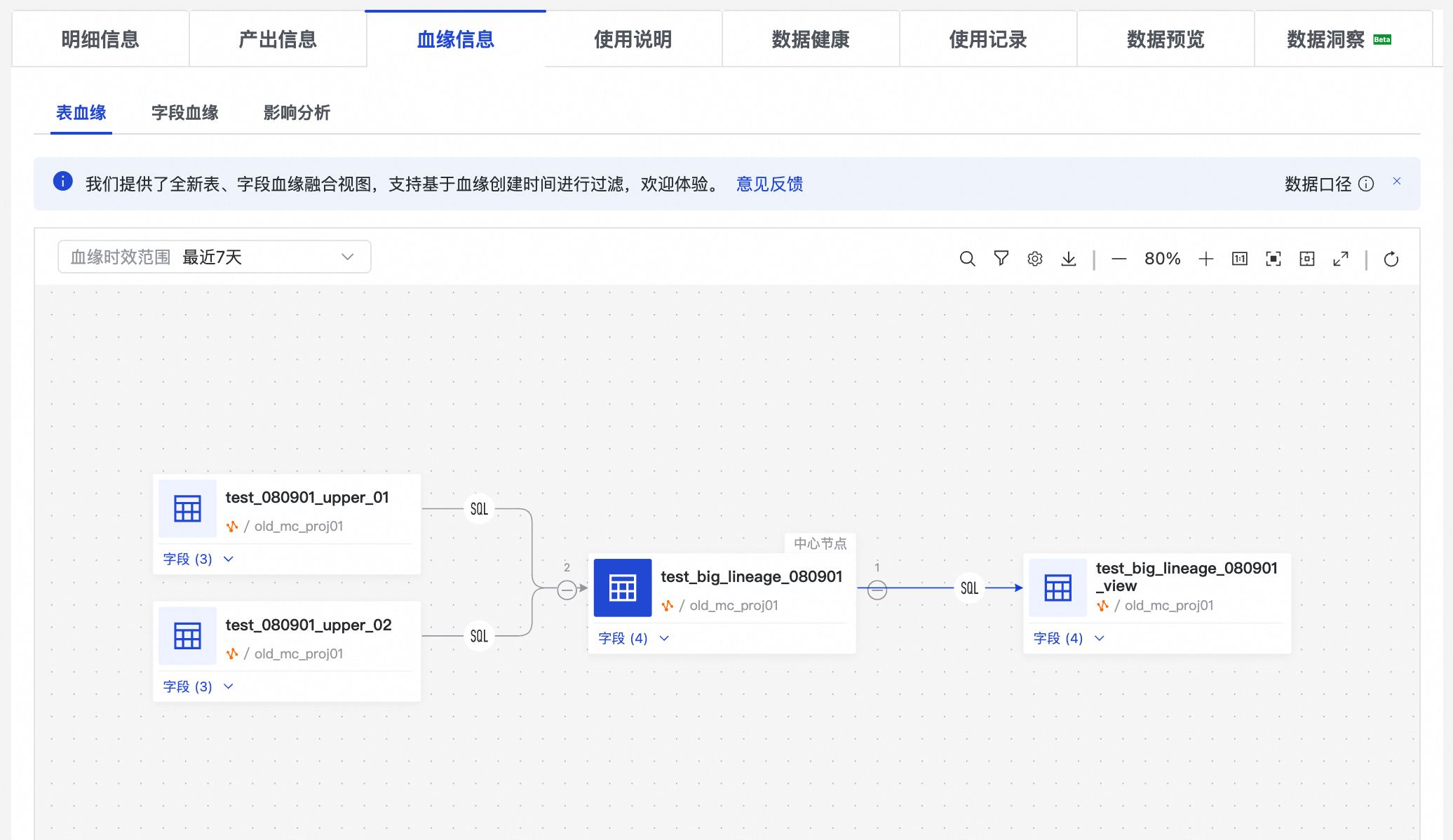
在資料地圖模組,尋找某張表並進入表詳情頁面後,單擊血緣信息頁簽查看表級和欄位級的血緣詳情。同時,您也可以進行影響分析,擷取當前表的下遊表列表,支援將下遊表列表下載為本地檔案或通過郵件進行變更通知。
資料地圖支援展示基於調度作業、資料流轉資訊解析得出的表和表、欄位和欄位之間的血緣關係;暫不包含臨時查詢等手動操作產生的血緣關係。離線資料T+1更新其血緣關係。
如需更大的視圖地區查看複雜多級血緣,可在血緣圖右上方工具列單擊新頁面開啟按鈕(表徵圖為全屏樣式),在獨立的血緣頁面中瀏覽。該按鈕在表、資料集、資料服務API、AI資產的血緣頁簽上均可使用。
若您所在的工作空間或租戶未開通資料血緣相關能力,進入血緣頁簽時會展示商業化引導頁面,按頁面提示購買或開通後即可使用。
各資料來源使用限制
EMR Hive、DLF 與 DLF-Legacy
-
EMR Hive:EMR叢集若要在DataWorks管理中繼資料, 需先在叢集側配置EMR-HOOK 。若未配置,則在DataWorks中無法展示血緣關係。配置EMR-HOOK,詳情請參見配置Hive的EMR-HOOK。
-
DLF 與 DLF-Legacy:Data Lake Formation(DLF)及資料湖構建(DLF-Legacy)中的表,在通過中繼資料採集納入資料地圖後,當計算任務基於Serverless Spark、 Serverless StarRocks 或 Serverless Flink 引擎使用相應 DLF 中繼資料時,支援在資料地圖中展示血緣;其他引擎或情境是否展示血緣,取決於對應中繼資料採集與解析能力。詳情請參見中繼資料採集。
重要Serverless Spark引擎、Serverless StarRocks引擎和Serverless Flink引擎需綁定到DataWorks工作空間,否則對應血緣會被認為與DataWorks無關而被忽略。
-
EMR Hive 計算叢集相關:EMR on ACK類型的Spark叢集不支援查看血緣,EMR Serverless Spark叢集支援查看血緣。
-
EMR Hive 計算叢集相關:EMR Presto節點的任務不支援查看血緣關係。
-
EMR Impala 引擎:EMR Impala 任務的血緣採集依賴 Impala 自身的血緣日誌。需要在 EMR 叢集的 叢集服務 > Impala > 配置 中,將參數
lineage_event_log_dir配置為/mnt/disk1/log/impala/lineage_log並重啟 Impala 服務,DataWorks 資料地圖即可展示 EMR Impala 任務的表級和欄位級血緣。說明-
僅支援 EMR DataLake 叢集的 Impala 任務。HMS(對應資料來源類型 EMR Hive)和 DLF(對應資料來源類型 DLF)兩種中繼資料均支援。
-
對 EMR 叢集版本和 Impala 版本無要求,叢集中部署有 Impala 即可。
-
該能力當前處於灰階開放階段,使用前請提交工單或聯絡阿里雲支援人員開通。
-
AnalyticDB for MySQL
-
在對應引擎執行SQL
set adb_config RC_LINEAGE_INFO_LOG_ENABLE=true,開啟AnalyticDB for MySQL執行個體的資料血緣功能。 -
當中繼資料來源為AnalyticDB for Spark類型時,支援自動採集。
-
當中繼資料來源為AnalyticDB for Spark類型時,配置spark參數
spark.sql.queryExecutionListeners = com.aliyun.dataworks.meta.lineage.LineageListener後,可支援即時血緣。
對於AnalyticDB for MySQL類型的表,部分SQL處理命令不支援在資料地圖中產生血緣關係資訊,限制詳情如下。
-
不支援展示血緣的SQL命令:
不支援的SQL
樣本
不支援
join、union,或使用了*等關鍵字。例如,以下SQL中使用了
*,資料地圖無法展示血緣關係。INSERT INTO test SELECT * FROM test1, test2 WHERE test1.id = test2.id不支援子查詢。
例如,以下SQL中包含子查詢,資料地圖無法展示血緣關係。
SELECT column1, column2 FROM table1 WHERE column3 IN (SELECT column4 FROM table2 WHERE column5 = 'value') -
可正常展示血緣的SQL命令樣本:
-
樣本1:建立名為A的表(不包含具體列資訊),同時從B表中選擇某些具體列(不包含*)作為A表的內容。例如:
CREATE TABLE test AS SELECT id,name FROM test1; -
樣本2:將表A中滿足條件column1= value1的某些具體列(不包含*)資料插入到表B(不包含具體列資訊)中。例如:
INSERT INTO test SELECT id,name FROM test1 WHERE name='test'; -
樣本3:將A表的某些列(不包含*)資料覆蓋寫入到某個資料庫中的B表中。例如:
INSERT OVERWRITE INTO db_name.test SELECT id,name FROM test1;
-
CDH
如果需要在資料地圖中展示CDH Spark SQL及CDH Spark節點資料加工過程的表血緣關係,請按照資料加工的模組,在的Spark參數處單獨配置。
進入管理中心頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入管理中心。
-
在左側導覽列單擊集群管理,然後找到已建立的目標CDH叢集。
-
單擊編輯Spark參數。
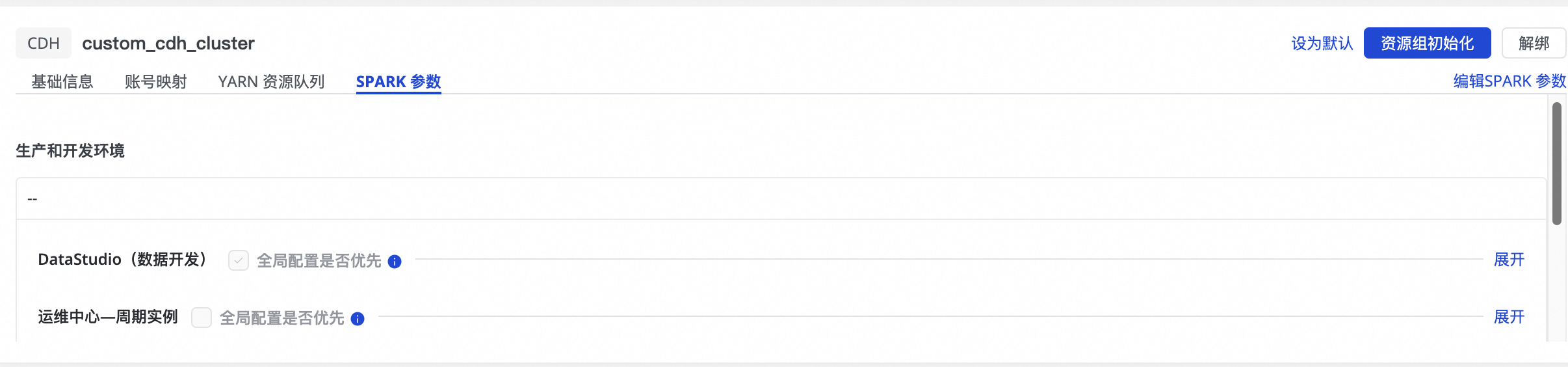
-
根據具體資料加工模組添加Spark參數。
例如要在資料地圖中展示CDH Spark SQL及CDH Spark節點在營運中心-周期執行個體模組中資料加工過程的表血緣關係,則需要在對應模組中,添加如下參數:
-
Spark屬性名稱:
spark.sql.queryExecutionListeners。 -
Spark屬性值:
com.aliyun.dataworks.meta.lineage.LineageListener。
-
-
單擊確認完成編輯。
Lindorm
僅執行個體模式支援血緣資訊採集,串連串模式無法採集血緣資訊。
如果需要在資料地圖中展示Lindorm Spark及Lindorm Spark SQL節點資料加工過程的表血緣關係,請按照資料加工的模組,在的Spark參數處單獨配置。
進入管理中心頁面。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入管理中心。
-
在左側導覽列單擊計算資源,然後找到已建立的Lindorm計算資源。
-
單擊編輯Spark參數。
-
根據具體資料加工模組添加Spark參數。
例如要在資料地圖中展示Lindorm Spark及Lindorm Spark SQL節點在營運中心-周期執行個體模組中資料加工過程的表血緣關係,則需要在對應模組中,添加如下參數:
-
Spark屬性名稱:
spark.sql.queryExecutionListeners。 -
Spark屬性值:
com.aliyun.dataworks.meta.lineage.LineageListener。
-
-
單擊確認,完成Spark參數配置。
各資料來源血緣展示情況說明
原E-MapReduce在資料地圖中已按中繼資料來源拆分為EMR Hive、DLF和DLF-Legacy,下表按當前控制台中的資料來源分類列出血緣支援情況。
|
資料來源 |
Data Integration |
資料開發 |
||
|
表級血緣 |
欄位級血緣 |
表級血緣 |
欄位級血緣 |
|
|
AnalyticDB MySQL
|
|
|
|
|
|
AnalyticDB PostgreSQL
|
|
|
|
|
|
ClickHouse
|
|
|
|
|
|
CDH/CDP
|
|
|
Hive、Impala、Spark、Spark SQL
|
Hive、Impala、Spark、Spark SQL
|
|
EMR Hive
|
(OSS、Hive)
|
(OSS、Hive)
|
支援 E-MapReduce、Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
支援 E-MapReduce、Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
|
DLF-Legacy
|
(OSS、Hive)
|
(OSS、Hive)
|
支援 E-MapReduce、Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
支援 E-MapReduce、Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
|
DLF
|
(OSS、Hive)
|
(OSS、Hive)
|
支援 Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
支援 Serverless Spark、Serverless StarRocks、Serverless Flink 引擎,以及 EMR Impala 引擎(僅 EMR DataLake 叢集,當前為灰階開放階段,使用前請聯絡阿里雲支援人員開通)。
|
|
Hologres
|
|
|
|
|
|
Kafka
|
(Kafka同步至MaxCompute/Hologres) |
|
|
|
|
Lindorm
|
|
|
|
|
|
MaxCompute
|
|
|
|
|
|
MySQL
|
(MySQL同步至MaxCompute/Hologres) |
|
|
|
|
Oracle
|
|
|
|
|
|
OceanBase
|
|
|
|
|
|
OSS
|
|
|
|
|
|
PolarDB MySQL
|
|
|
|
|
|
PolarDB PostgreSQL
|
|
|
|
|
|
PostgreSQL
|
|
|
|
|
|
StarRocks
|
|
|
|
|
|
SQL Server
|
|
|
|
|
|
Tablestore(OTS)
|
|
|
|
|
 詳情頁
詳情頁 即時同步
即時同步資料服務API血緣
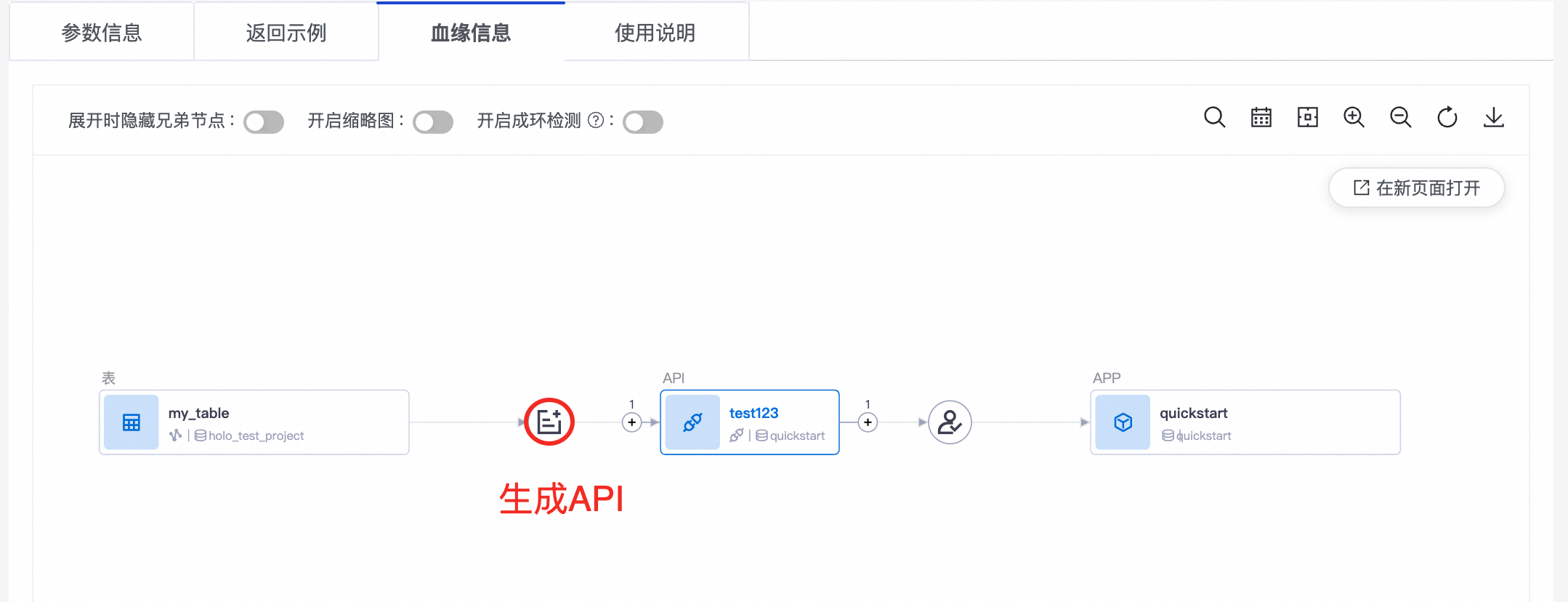
尋找某個資料服務API並進入API詳情頁面後,您可以單擊血緣信息頁簽,查看API的血緣詳情。
AI資產血緣
AI資產血緣服務允許企業追蹤模型訓練的輸入資料集、輸出結果集以及模型之間的血緣關係。詳細的AI資產血緣說明,請參見查看AI資產。