本文為您介紹如何用Spark SQL建立外部使用者資訊表ods_user_info_d_spark以及日誌資訊表ods_raw_log_d_spark訪問儲存在私人OSS中的使用者與日誌資料,通過DataWorks的EMR Spark SQL節點進行加工得到目標使用者畫像資料,閱讀本文後,您可以瞭解如何通過Spark SQL來計算和分析已同步的資料,完成數倉簡單資料加工情境。
前提條件
開始本案例前,請先完成同步資料中的操作。
已通過EMR Spark SQL節點建立
ods_user_info_d_spark外部表格,可成功訪問同步至私人OSS的使用者基本資料。已通過EMR Spark SQL節點建立
ods_raw_log_d_spark外部表格,可成功訪問同步至私人OSS的日誌資訊。
注意事項
由於EMR Serverless Spark空間不支援註冊函數,無法通過註冊新函數的方式將日誌資訊進行切分並轉換IP為地區。本案例通過Spark SQL自有的函數對ods_raw_log_d_spark日誌表進行切分的方式產生dwd_log_info_di_spark,從而實現進一步的使用者Portrait analysis。
章節目標
本小節將對ods_user_info_d_spark和ods_raw_log_d_spark外部表格進行加工處理,並產生基本使用者畫像表。
通過Spark SQL對
ods_raw_log_d_spark表進行處理,產生新的明細日誌表dwd_log_info_di_spark。利用明細日誌表
dwd_log_info_di_spark和使用者表ods_user_info_d_spark的uid欄位進行關聯,產生匯總使用者日誌表dws_user_info_all_di_spark。dws_user_info_all_di_spark表,直接應用於資料消費,表資料較多,所以將其進一步加工為ads_user_info_1d_spark表。
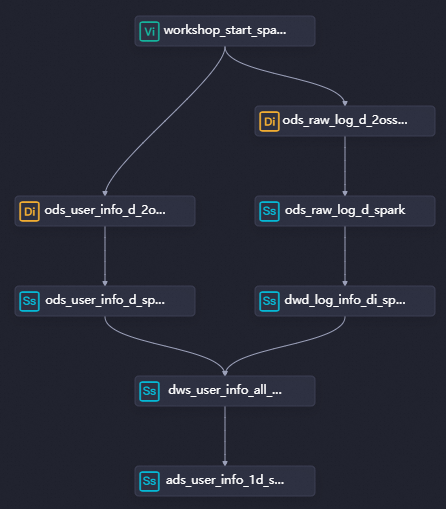
一、設計工作流程
在上一同步資料章節中完成了使用者表使用者Portrait analysis(Spark版)的資料同步流程。在資料加工階段將會新增dwd_log_info_di_spark節點對日誌表進行細分,dws_user_info_all_di_spark節點對日誌明細表和使用者表進行串連產生新表後,再通過ads_user_info_1d_spark節點對使用者日誌明細表進一步處理,實現使用者畫像表的輸出。
進入資料開發。
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
在同步資料階段,已經成功用EMR Spark SQL節點建立外部表格訪問私人OSS資料,接下來的流程的目標是對資料進行進一步加工,以輸出基本使用者畫像資料。
各層級節點以及工作邏輯。
在商務程序畫布中單擊建立節點,建立以下節點,以供加工資料使用。
節點分類
節點類型
節點名稱
(以最終產出表命名)
代碼邏輯
EMR
 EMR Spark SQL
EMR Spark SQLdwd_log_info_di_spark
將ods_raw_log_d_spark日誌表進行拆分,產生新的日誌表,以供後續關聯使用。
EMR
 EMR Spark SQL
EMR Spark SQLdws_user_info_all_di_spark
將使用者基本資料和初步加工後的日誌資料進行匯總,合并為一張表。
EMR
 EMR Spark SQL
EMR Spark SQLads_user_info_1d_spark
進一步加工產出基本使用者畫像。
流程DAG圖。
將節點群組件拖拽至商務程序畫布,並通過拉線設定節點上下遊依賴的方式,設計資料加工階段的商務程序。
二、配置EMR Spark SQL節點
配置完成商務程序後,在EMR Spark SQL節點中利用Spark SQL函數對ods_raw_log_d_spark表進行切分處理,從而通過對切分後的日誌表與使用者表進行關聯成新的明細表之後進一步對資料表進行清洗、處理操作後,從而實現對不同使用者的一個使用者畫像。
配置dwd_log_info_di_spark節點
在商務程序面板,雙擊EMR Spark SQL節點dwd_log_info_di_spark節點,進入dwd_log_info_di_spark節點的編輯頁面,編寫處理上遊ods_raw_log_d_spark表,將日誌詳細資料寫入dwd_log_info_di_spark表中。
配置代碼
雙擊
dwd_log_info_di_spark節點,進入節點配置頁面,編寫如下語句。-- 情境:以下SQL為Spark SQL,通過Spark SQL函數將載入至Spark中的ods_raw_log_d_spark按"##@@"進行切分後產生多個欄位,並寫入新表dwd_log_info_di_spark。 -- 補充: -- DataWorks提供調度參數,可實現調度情境下,將每日增量資料寫入目標表對應的業務分區內。 -- 在實際開發情境下,您可通過${變數名}格式定義代碼變數,並在調度配置頁面通過變數賦值調度參數的方式,實現調度情境下代碼動態入參。 CREATE TABLE IF NOT EXISTS dwd_log_info_di_spark ( ip STRING COMMENT 'ip地址', uid STRING COMMENT '使用者ID', tm STRING COMMENT '時間yyyymmddhh:mi:ss', status STRING COMMENT '伺服器返回狀態代碼', bytes STRING COMMENT '返回給用戶端的位元組數', method STRING COMMENT'要求方法', url STRING COMMENT 'url', protocol STRING COMMENT '協議', referer STRING , device STRING, identity STRING ) PARTITIONED BY ( dt STRING ); ALTER TABLE dwd_log_info_di_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}'); INSERT OVERWRITE TABLE dwd_log_info_di_spark PARTITION (dt='${bizdate}') SELECT ip, uid, tm, status, bytes, regexp_extract(request, '(^[^ ]+) .*', 1) AS method, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) AS url, regexp_extract(request, '.* ([^ ]+$)', 1) AS protocol, regexp_extract(referer, '^[^/]+://([^/]+){1}', 1) AS referer, CASE WHEN lower(agent) RLIKE 'android' THEN 'android' WHEN lower(agent) RLIKE 'iphone' THEN 'iphone' WHEN lower(agent) RLIKE 'ipad' THEN 'ipad' WHEN lower(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN lower(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN lower(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device, CASE WHEN lower(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN lower(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) RLIKE 'feed' THEN 'feed' WHEN lower(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^(Mozilla|Opera)' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$', 1) NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip, SPLIT(col, '##@@')[1] AS uid, SPLIT(col, '##@@')[2] AS tm, SPLIT(col, '##@@')[3] AS request, SPLIT(col, '##@@')[4] AS status, SPLIT(col, '##@@')[5] AS bytes, SPLIT(col, '##@@')[6] AS referer, SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_spark WHERE dt = '${bizdate}' ) a;配置調度屬性
配置項
圖示
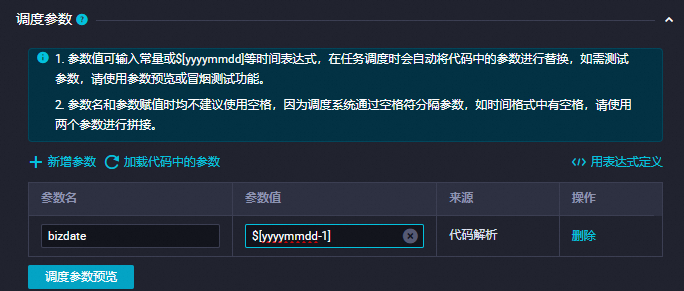
新增參數
在調度參數項中單擊新增參數,添加:
參數名:
bizdate參數值:
$[yyyymmdd-1]
詳情可參見:配置調度參數。
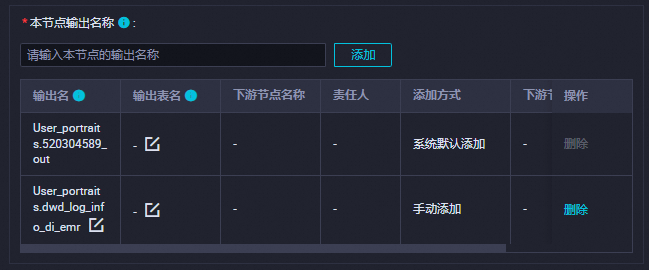
調度依賴
在調度依賴確認產出表已作為本節點輸出。
格式為
worksspacename.節點名。詳情可參見:配置調度依賴。
 說明
說明時間屬性的配置,配置調度周期為日,無需單獨配置當前節點定時調度時間,當前節點每日調起時間由商務程序虛擬節點workshop_start_spark的定時調度時間控制,即每日00:30後才會調度。
儲存配置
本案例其他必填配置項,您可按需自行配置,配置完成後,在節點代碼編輯頁面,單擊工具列中的
 按鈕,儲存當前配置。
按鈕,儲存當前配置。驗證日誌表拆分情況
在確保上遊節點以及本節點運行成功的情況下,在左側導覽列的臨時查詢中建立EMR Spark SQL臨時查詢,編寫SQL查看EMR Spark SQL節點建立的表是否正常產出。
-- 您需要將分區過濾條件更新為您當前操作的實際業務日期。例如,任務啟動並執行日期為20230222,則業務日期為20230221,即任務運行日期的前一天。 SELECT * FROM dwd_log_info_di_spark WHERE dt ='業務日期';說明在本教程在SQL中配置了調度參數
${bizdate},並將其賦值為T-1。在離線計算情境下bizdate為業務交易發生的日期,也常被稱為業務日期(business date)。例如,今天統計前一天的營業額,此處的前一天指的是交易發生的日期,也就是業務日期。
配置dws_user_info_all_di_spark節點
基於dwd_log_info_di_spark日誌表和ods_user_info_d_spark使用者表,通過uid對兩表進行關聯,產出新的使用者日誌明細表dws_user_info_all_di_spark。
編輯代碼
雙擊dws_user_info_all_di_spark節點,進入節點配置頁面。在節點編輯頁面,編寫如下語句。
-- 情境:以下SQL為Spark SQL,通過uid將dwd_log_info_di_spark和ods_user_info_d_spark進行關聯,並寫入對應的dt分區。 -- 補充: -- DataWorks提供調度參數,可實現調度情境下,將每日增量資料寫入目標表對應的業務分區內。 -- 在實際開發情境下,您可通過${變數名}格式定義代碼變數,並在調度配置頁面通過變數賦值調度參數的方式,實現調度情境下代碼動態入參。 CREATE TABLE IF NOT EXISTS dws_user_info_all_di_spark ( uid STRING COMMENT '使用者ID', gender STRING COMMENT '性別', age_range STRING COMMENT '年齡段', zodiac STRING COMMENT '星座', device STRING COMMENT '終端類型 ', method STRING COMMENT 'http請求類型', url STRING COMMENT 'url', `time` STRING COMMENT '時間yyyymmddhh:mi:ss' ) PARTITIONED BY (dt STRING); --添加分區 ALTER TABLE dws_user_info_all_di_spark ADD IF NOT EXISTS PARTITION (dt = '${bizdate}'); --插入user表與日誌表資料 INSERT OVERWRITE TABLE dws_user_info_all_di_spark PARTITION (dt = '${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid, b.gender AS gender, b.age_range AS age_range, b.zodiac AS zodiac, a.device AS device, a.method AS method, a.url AS url, a.tm FROM ( SELECT * FROM dwd_log_info_di_spark WHERE dt='${bizdate}' ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d_spark WHERE dt='${bizdate}' ) b ON a.uid = b.uid;配置調度屬性
配置項
配置內容
圖示
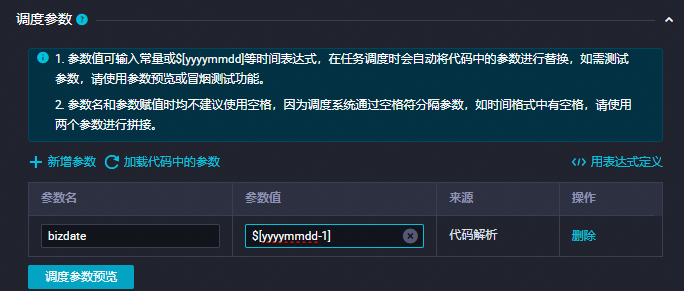
新增參數
在調度參數項中單擊新增參數,添加:
參數名:
bizdate參數值:
$[yyyymmdd-1]
詳情可參見:配置調度參數。
調度依賴
在調度依賴確認產出表已作為本節點輸出。
格式為
worksspacename.節點名。詳情可參見:配置調度依賴。
 說明
說明時間屬性的配置,配置調度周期為日,無需單獨配置當前節點定時調度時間,當前節點每日調起時間由商務程序虛擬節點workshop_start_spark的定時調度時間控制,即每日00:30後才會調度。
儲存配置
本案例其他必填配置項,您可按需自行配置,配置完成後,在節點代碼編輯頁面,單擊工具列中的
按鈕,儲存當前配置。驗證使用者日誌明細表資料情況
在確保上遊節點以及本節點運行成功的情況下,在左側導覽列的臨時查詢中建立EMR Spark SQL臨時查詢,編寫SQL查看EMR Spark SQL節點建立的表是否正常產出。
-- 您需要將分區過濾條件更新為您當前操作的實際業務日期。例如,任務啟動並執行日期為20240808,則業務日期為20240807,即任務運行日期的前一天。 SELECT * FROM dws_user_info_all_di_spark WHERE dt ='業務日期';說明在本教程在SQL中配置了調度參數
${bizdate},並將其賦值為T-1。在離線計算情境下bizdate為業務交易發生的日期,也常被稱為業務日期(business date)。例如,今天統計前一天的營業額,此處的前一天指的是交易發生的日期,也就是業務日期。
配置ads_user_info_1d_spark節點
基於dws_user_info_all_di_spark表,進行最大值、以及計數計算,產出ads_user_info_1d_spark表作為使用者畫像表進行消費。
編輯代碼
雙擊ads_user_info_1d_spark節點,進入節點配置頁面。在節點編輯頁面,編寫如下語句。
-- 情境:以下SQL為Spark SQL,通過Spark SQL函數將Spark中的dws_user_info_all_di_spark表進一步的加工,並寫入新表ads_user_info_1d_spark。 -- 補充: -- DataWorks提供調度參數,可實現調度情境下,將每日增量資料寫入目標表對應的業務分區內。 -- 在實際開發情境下,您可通過${變數名}格式定義代碼變數,並在調度配置頁面通過變數賦值調度參數的方式,實現調度情境下代碼動態入參。 CREATE TABLE IF NOT EXISTS ads_user_info_1d_spark ( uid STRING COMMENT '使用者ID', device STRING COMMENT '終端類型 ', pv BIGINT COMMENT 'pv', gender STRING COMMENT '性別', age_range STRING COMMENT '年齡段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING ); ALTER TABLE ads_user_info_1d_spark ADD IF NOT EXISTS PARTITION (dt='${bizdate}'); INSERT OVERWRITE TABLE ads_user_info_1d_spark PARTITION (dt='${bizdate}') SELECT uid , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_spark WHERE dt = '${bizdate}' GROUP BY uid;調度配置
配置項
配置內容
圖示
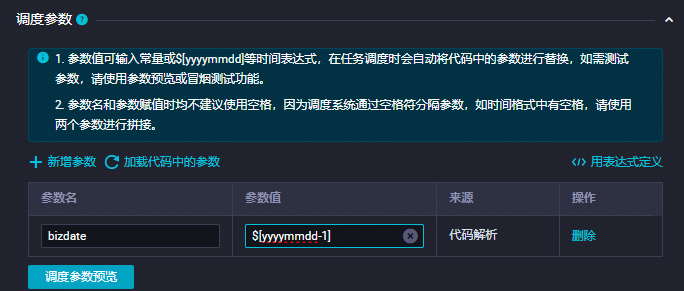
新增參數
在調度參數項中單擊新增參數,添加:
參數名:
bizdate參數值:
$[yyyymmdd-1]
詳情可參見:配置調度參數。
調度依賴
在調度依賴確認產出表已作為本節點輸出。
格式為
worksspacename.節點名。詳情可參見:配置調度依賴。
 說明
說明時間屬性的配置,配置調度周期為日,無需單獨配置當前節點定時調度時間,當前節點每日調起時間由商務程序虛擬節點workshop_start_spark的定時調度時間控制,即每日00:30後才會調度。
儲存配置
本案例其他必填配置項,您可按需自行配置,配置完成後,在節點代碼編輯頁面,單擊工具列中的
按鈕,儲存當前配置。驗證使用者畫像表資料情況
在確保上遊節點以及本節點運行成功的情況下,在左側導覽列的臨時查詢中建立EMR Spark SQL臨時查詢,編寫SQL查看該節點建立的表是否正常產出。
-- 您需要將分區過濾條件更新為您當前操作的實際業務日期。例如,任務啟動並執行日期為20230222,則業務日期為20230221,即任務運行日期的前一天。 SELECT * FROM ads_user_info_1d_spark WHERE dt ='業務日期';說明在本教程在SQL中配置了調度參數
${bizdate},並將其賦值為T-1。在離線計算情境下bizdate為業務交易發生的日期,也常被稱為業務日期(business date)。例如,今天統計前一天的營業額,此處的前一天指的是交易發生的日期,也就是業務日期。
三、提交商務程序
完成商務程序所有配置後,測試該流程是否能正常運行,測試成功後,需要提交流程等待發布。
在商務程序的編輯頁面,單擊
 ,運行商務程序。
,運行商務程序。待商務程序中的所有節點後出現
 ,單擊
,單擊 ,提交運行成功的商務程序。
,提交運行成功的商務程序。選擇提交對話方塊中需要提交的節點,勾選忽略輸入輸出不一致的警示,然後單擊確認。
提交成功後,發布各流程節點。
單擊頁面右側發布,進入建立發布包頁面。
選中待發布的節點,單擊發布選中項,在確認發布對話方塊,單擊發布。
四、在生產環境運行任務
任務發布後,次日才會產生執行個體運行,您可以通過補資料來對發行流程進行補資料操作,以便查看任務在生產環境是否可以運行,詳情可參見執行補資料並查看補資料執行個體(新版)。
任務發布成功後,單擊右上方的營運中心。
您也可以進入商務程序的編輯頁面,單擊工具列中的前往營運,進入營運中心頁面。
單擊左側導覽列中的,進入周期任務頁面,單擊workshop_start_spark虛節點。
在右側的DAG圖中,按右鍵workshop_start_spark節點,選擇。
勾選需要補資料的任務,輸入業務日期,單擊確定,自動跳轉至補資料執行個體頁面。
單擊重新整理,直至SQL任務全部運行成功即可。