本文以MaxCompute單表離線同步寫入ClickHouse情境為例,為您介紹ClickHouse離線同步在資料來源配置、網路聯通、同步任務配置方面的最佳實務。
ClickHouse介紹
雲資料庫ClickHouse是面向線上分析處理的列式資料庫。Data Integration支援從ClickHouse同步資料到其他目標端,也支援從其他目標端同步資料到ClickHouse。本文以MaxCompute單表離線同步寫入ClickHouse為例,為您介紹ClickHouse離線同步的完整流程。
使用限制
ClickHouse單表離線同步僅支援阿里雲ClickHouse。
前提條件
已購買Serverless資源群組。
已建立MaxCompute資料來源和ClickHouse資料來源,詳情請參見資料來源配置。
已完成資源群組與資料來源間的網路連通,詳情請參見網路連通方案概述。
操作步驟
本文以資料開發(Data Studio)(新版)介面操作為例,示範離線同步任務配置。
一、建立節點與任務配置
對於通用的節點建立和嚮導配置步驟,本文將直接引用通用操作指南嚮導模式配置,不再贅述。
二、配置資料來源與去向
在資料來源地區和運行資來源區域分別配置來來源資料源MaxCompute和去向資料來源ClickHouse,並配置資源群組測試連通性。
配置資料來源(MaxCompute)參數
資料來源MaxCompute表的配置要點如下。
配置項 | 配置要點 |
Tunnel資源組 | 本教程預設為公用傳輸資源,若您擁有獨享Tunnel Quota,可下拉選擇。 |
錶 | 選擇待同步的MaxCompute表。如果您使用的是標準類型的DataWorks工作空間,請確保在MaxCompute的開發環境和生產環境中存在同名且表結構一致的MaxCompute表。
|
過濾方式 | 支援通過分區過濾和數據過濾。
|
分區 | 當過濾方式選擇為分區時需要配置,您可以填入分區列的取值。
|
分區不存在時 | 當分區不存在時,同步任務的處理策略,支援:
|
配置資料去向(ClickHouse)參數
資料去向ClickHouse表的配置要點如下。
配置項 | 配置要點 |
錶 | 選擇待同步的ClickHouse表。建議對於要進行資料同步的表,ClickHouse資料來源開發和生產環境保持相同的表結構。 說明 此處會展示ClickHouse資料來源開發環境的表列表,如果您的ClickHouse資料來源開發和生產環境的表定義不同,則可能出現任務在開發環境配置正常但提交生產運行後報錯表不存在、列不存在的問題。 |
主鍵或者唯一鍵衝突處理 | 選擇 |
導入前準備語句 | 您可以在執行資料同步任務的前後按需執行SQL語句。比如在按天進行資料同步前清理對應天分區的資料,保證本次資料寫入前對應分區是無資料的。 |
導入後完成語句 | |
批量插入字節大小 | 資料同步寫入ClickHouse時採用攢批寫入方式,此處是攢批的位元組數上限、條數上限。如果讀取到的資料達到攢批的位元組數上限或條數上限,則認為攢夠一批,每攢夠一批則寫入一批資料到ClickHouse。 批量插入位元組大小建議值為16777216(16MB),批量插入條數建議按照您單條記錄的大小調整為一個較大值,從而依靠批量插入位元組大小觸發批次寫入。 例如單條記錄大小為1KB,批量插入位元組大小設定為16777216(16MB),批量插入條數設定為20000(大於16MB/1KB=16384),則會通過批量插入位元組大小觸發寫入,每達到16MB寫入一次。 |
批量插入條數 | |
批量寫入異常時 | 批量寫入ClickHouse異常時,可以選擇異常處理策略:
|
四、配置欄位對應
選擇資料來源和資料去向後,需要指定讀取端和寫入端列的映射關係。您可以選擇同名映射、同行映射、取消映射或自動排版。
五、進階配置
離線同步任務支援設定任務期望最大併發數、髒數據策略等。本教程髒數據策略配置為不容忍髒數據,其他配置保持預設。更多資訊,請參見嚮導模式配置。
六、調試配置並運行
單擊離線同步節點編輯頁面右側的回合組態,設定調試運行使用的資源組和腳本參數,然後單擊頂部工具列的運行,測試同步鏈路是否成功運行。
您可以在左側導覽列單擊
 ,然後單擊個人目錄右側的建立表徵圖,建立SQL檔案,執行如下SQL,以查詢資料去向表中的資料是否符合預期。說明
,然後單擊個人目錄右側的建立表徵圖,建立SQL檔案,執行如下SQL,以查詢資料去向表中的資料是否符合預期。說明此方式查詢需要將目標端ClickHouse綁定為DataWorks的計算資源。
您需要在
.sql檔案編輯頁面右側單擊回合組態,指定資料來源類型、計算資源、資源組後,再單擊頂部工具列的運行。
SELECT * FROM <ClickHouse側目標表名> LIMIT 20;
七、調度配置與發布
單擊離線同步任務右側的調度配置,設定周期運行所需的調度配置參數後,單擊頂部工具列的發布,進入發布面板,根據頁面提示完成發布。
附錄:調整記憶體參數
如果您在並發調大後同步速率增長不明顯,可以嘗試手工調整同步任務記憶體參數。調整方式如下:
在離線同步任務頁面頂部工具列單擊腳本模式,將任務從嚮導模式切換為指令碼模式。

在指令碼JSON段的
setting中增加jvmOption參數,參數形如-Xms${heapMem} -Xmx${heapMem} -Xmn${newMem}。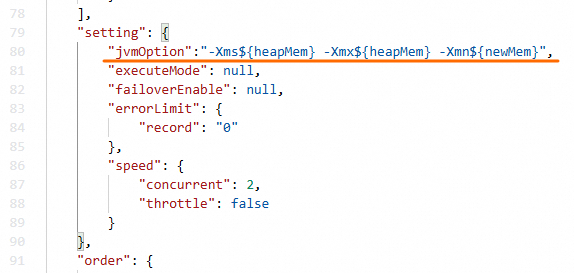
嚮導模式下系統計算的${heapMem}的取值為768MB+(並發數-1)*256 MB。建議您在指令碼模式中將${heapMem}設定為更大值,並將${newMem}設定為${heapMem}的三分之一。如並發數為8時,嚮導模式預設計算的${heapMem}為2560MB,指令碼模式中可設定更大值,如設定jvmOption為-Xms3072m -Xmx3072m -Xmn1024m。