專案目錄區的節點及工作流程往往都是需要周期性調度的,故我們需要在節點或工作流程的調度配置面板配置調度相關屬性,包括調度周期、調度依賴、調度參數等。本文為您介紹調度配置的相關內容。
前提條件
注意事項
任務的調度配置僅用於定義任務調度運行時的相關屬性,任務需通過發布流程發布至生產環境後,才會根據該配置進行最終調度。
調度時間僅定義任務預期執行時間,其實際執行時間還受上遊執行情況控制,關於任務執行條件說明,詳情請參見任務運行診斷。
DataWorks支援多種類型任務互相依賴,操作前,建議您先查看複雜依賴情境調度配置原則與樣本文檔瞭解DataWorks在該情境下預設依賴的情況。
DataWorks上,調度任務會根據調度類型及周期數產生相應的查看周期執行個體(例如,小時調度任務每天會根據周期數產生相應數量的小時執行個體),並通過周期執行個體的方式自動調度運行該任務。
在使用調度參數的情況下,DataWorks調度任務各周期代碼入參由該周期對應的定時時間以及您調度參數運算式最終決定。各周期代碼入參與調度參數配置與替換的關係,請參見調度參數來源及其運算式。
工作流程包括本身工作流程節點以及內部節點,依賴關係較為複雜,本文僅介紹單獨節點的依賴及調度說明,工作流程調度依賴關係的詳細說明,請參見周期工作流程編排。
進入調度配置頁面
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的,進入Data Studio。
進入調度配置頁面。
在資料開發(Data Studio)介面,您需找到目標節點,進入該節點的編輯頁面。
單擊節點編輯頁面右側導覽列的調度配置,進入節點調度配置頁面。
配置節點調度屬性
在節點的調度配置頁面,您需要分別配置節點的調度參數、調度策略、調度時間、調度依賴和節點輸出參數。
(可選)調度參數
若您在編輯節點代碼時,在代碼中定義了變數,需在此處對該變數進行賦值。
調度參數是根據任務調度的業務時間及調度參數的取值格式自動替換為具體的值,實現任務調度時間內參數的動態替換。
配置調度參數
您可以通過如下兩種方式定義調度參數。
定義調度參數方式 | 描述 | 配置圖示 |
添加參數 | 同一個調度任務可以配置多個調度參數,當需使用多個調度參數時,可以單擊添加參數添加。
|
|
載入代碼中的參數 | 用於自動識別當前任務代碼中定義的變數名,並將識別到的變數名添加為調度參數,便於調度任務後續使用。 說明 通常,代碼中是按照 Pyodps節點、通用Shell節點對於變數名的定義方式與其他節點存在差異。各類型節點的調度參數配置格式,詳情請參見各類型節點的調度參數配置樣本。 |
|


調度參數支援格式
具體請參見調度參數來源及其運算式。
確認生產環境任務的調度參數配置
為避免周期調度任務運行時,由於調度參數不符合預期而導致任務運行出現問題,建議在任務發布後,前往生產營運中心的周期任務介面,查看生產環境下該周期任務的調度參數配置情況。查看周期任務,詳情請參見管理周期任務。
調度策略
調度策略用於定義周期調度任務中執行個體的產生方式、調度類型、計算資源與資源群組等資訊。
參數 | 說明 |
執行個體產生方式 | 節點提交發布至生產環境調度系統後,平台會根據節點配置的執行個體產生方式產生自動調度的周期執行個體。 |
調度類型 |
|
逾時定義 | 設定逾時時間後,如果任務運行時間長度超過逾時時間,任務將自動終止運行。其配置說明如下:
|
重跑屬性 | 配置節點在特定情況下重跑。 重跑屬性不可為空,其支援的類型及應用情境如下:
|
失敗自動重跑 | 開啟後,當任務運行失敗(不包括使用者主動終止任務運行)時,調度系統會根據重跑次數和重跑間隔自動觸發重跑。
說明
|
計算資源 | 請配置任務運行所需的引擎資源。如需建立新的資源,您可以通過計算資源管理進行操作。 |
計算配額 | 支援在MaxCompute SQL節點、MaxCompute Script節點配置任務運行所需的計算配額(Quota),為計算作業提供計算資源(CPU及記憶體)。 |
資源群組 | 配置任務運行使用的調度資源群組,按需選擇即可。
|
最大並行執行個體數 | 限制同一任務同時可啟動並執行最大執行個體數,以實現並發控制和資源保護。預設不限制任務的最大並行執行個體數,開啟限制後,支援設定並行執行個體數,預設值為
|
資料集 | 單擊
|
 為節點添加
為節點添加調度時間
調度時間用於配置調度任務自動執行的周期、時間等資訊。
如果是工作流程中的節點,則調度時間相關參數在工作流程頁面的調度配置中設定,如果是非工作流程中的節點,則在各節點的調度配置中設定調度時間。
注意事項
任務調度頻率與上遊任務周期無關
任務多久調度一次與任務本身定義的調度周期有關,與上遊任務調度周期無關。
DataWorks支援不同調度周期的任務互相依賴
DataWorks中,調度任務會根據調度類型及周期數產生相應的周期執行個體(例如,小時調度任務每天會根據周期數產生相應數量的小時執行個體),通過執行個體的方式運行任務。周期任務設定的依賴關係,其本質是任務間所產生執行個體的依賴。上下遊任務的調度類型不同,其產生的周期執行個體數及執行個體的依賴情況不同。不同調度周期的上下遊依賴情況,請參見調度依賴方式選擇(跨周期依賴)。
非調度時間任務會空跑
DataWorks上非每天調度的任務(例如周、月調度的任務)在非調度時間內會空跑,當到達任務定義的調度時間後立即返回成功狀態。若下遊存在日調度任務,會調起該下遊日調度任務正常執行。即上遊空跑,下遊調度任務正常根據節點定義的調度時間執行。
任務執行時間說明
此處僅設定任務預期調度時間,任務的實際執行時間受多種因素影響。例如,上遊定時時間、任務執行資源情況、任務實際運行條件等,詳情請參見任務運行條件說明。
配置調度時間
參數 | 說明 |
調度周期 | 調度周期即任務在調度情境下自動執行的周期數,用於定義在生產環境調度系統中,多久會真實執行一次節點中的代碼邏輯。調度任務會根據調度類型及周期數產生相應的周期執行個體(例如,小時調度任務每天會根據周期數產生相應數量的小時執行個體),通過周期執行個體的方式自動調度運行周期任務。
重要 周調度、月調度和年調度在非調度時間內仍會每日產生執行個體,執行個體顯示為成功狀態,但實際會空跑,不會真實執行任務。 |
生效日期 | 調度節點在有效日期內生效並自動調度,超過有效期間的任務將不會自動調度。此類任務為到期任務,您可在營運大屏查看到期任務數量,並根據情況對其做下線等處理。 |
Cron運算式 | 該運算式根據時間屬性配置自動產生,無需配置。 |
調度依賴
DataWorks上任務的調度依賴是指調度情境下節點間的上下遊依賴關係。在DataWorks中,上遊節點任務運行完成且運行成功,下遊節點任務才會開始運行。配置調度依賴後,可保障調度任務在運行時能擷取到正確的資料(即當前節點依賴的上遊節點成功運行後,DataWorks通過節點的運行狀態識別到上遊表的最新資料已產生,下遊節點再去取數),避免下遊節點取資料時,上遊表資料還未正常產出,導致下遊節點取數出現問題。
注意事項
節點依賴關係配置後,預設在任務調度運行時,下遊節點運行條件之一為其依賴的上遊節點均已執行成功,否則當前任務取數會存在品質問題。
任務實際已耗用時間除了取決於任務本身的定時時間(即任務在調度情境下的預期執行時間)外,還取決於上遊任務的完成時間(即下遊任務實際執行時間還取決於上遊任務的定時時間)。若上遊任務未完成運行,即便下遊任務的定時時間早於上遊任務,下遊任務也不會運行。任務運行條件,詳情請參見任務運行診斷。
配置調度依賴
DataWorks任務依賴最終是為了保障下遊取數無誤,實際是上下遊表資料的血緣依賴。您可根據業務需求,選擇是否需要基於表的血緣關係配置調度依賴。節點的調度依賴配置流程如下。

由於節點依賴關係配置後,預設節點的上下遊產出表存在強依賴關係(即下遊表資料的產出需要依賴上遊產出的表資料),因此,任務在配置調度依賴時,需確認是否存在強血緣依賴,即確認當前任務是否會因為上遊資料未產出而導致當前任務取數出現問題。若下遊節點中表資料的產出,需依賴上遊節點產出的表資料,則認為上下遊節點的表存在強血緣依賴關係。
序號 | 說明 |
① | 為避免當前任務執行時間不符合預期,您可先評估表之間是否存在強依賴關係,確認是否需要基於血緣關係配置調度依賴。 |
② | 確認當前情境是否為周期調度任務產出的表資料。不在DataWorks周期調度產出的表資料,DataWorks無法通過任務運行情況監控資料產出,因此,部分表不支援配置調度依賴。 非DataWorks周期性調度產出資料的表包括但不限於以下幾類:
|
③④ | 根據需要依賴上遊昨天還是今天的資料、小時分鐘任務是否要依賴自己上一個小時或分鐘執行個體,來選擇依賴上遊同周期還是上一周期。
說明 根據血緣配置時,調度依賴情境選擇配置細節,請參見調度依賴方式選擇(同周期依賴)。 |
⑤⑥⑦ | 依賴關係配置完成並發布生產後,可在營運中心周期任務中查看任務依賴關係是否符合預期。 |
自訂節點配置依賴
若DataWorks上任務間不存在強血緣依賴(例如,不強依賴上遊某個分區資料,僅取上遊目前時間點最大分區資料),或依賴的資料非周期調度節點產出的表資料(例如,本地上傳的表資料),則您可自訂節點的依賴關係。自訂依賴配置具體如下:
依賴工作空間根節點
例如,同步任務中的上遊資料來源於其他業務資料庫,SQL類型任務對即時同步任務產出的表資料進行加工等情境,您可直接選擇掛載依賴至工作空間根節點下。
依賴虛擬節點
當工作空間中商務程序較多或較複雜時,您可通過虛擬節點管理該商務程序,將需要統一管控的節點掛載依賴至某虛擬節點,使工作空間下資料流轉路徑更加清晰。例如,控制商務程序整體調度時間、控制商務程序整體調度與凍結(即不調度)。
節點輸出參數
在上遊節點定義輸出參數及其取值後,在下遊節點定義輸入參數(取值引用上遊節點的輸出參數),即可在下遊節點中使用此參數擷取上遊節點傳遞過來的取值。
注意事項
節點輸出參數僅作為下遊節點的輸入參數(在下遊節點調度參數地區添加參數,通過參數操作列的
 關聯上遊參數),部分節點無法直接將上遊節點的查詢結果傳遞到下遊,如果您需要將上遊節點的查詢結果傳遞到下遊節點,可以使用賦值節點,詳情可參見文檔:賦值節點。
關聯上遊參數),部分節點無法直接將上遊節點的查詢結果傳遞到下遊,如果您需要將上遊節點的查詢結果傳遞到下遊節點,可以使用賦值節點,詳情可參見文檔:賦值節點。支援節點輸出參數的節點為:
EMR Hive、EMR Spark SQL、ODPS Script、Hologres SQL、AnalyticDB for PostgreSQL和MySQL節點。
配置節點輸出參數
節點輸出參數的取值分為常量和變數兩種類型。
完成輸出參數的定義並提交當前節點後,即可在下遊節點配置調度參數時,綁定上遊節點的輸出參數作為下遊節點的輸入參數。
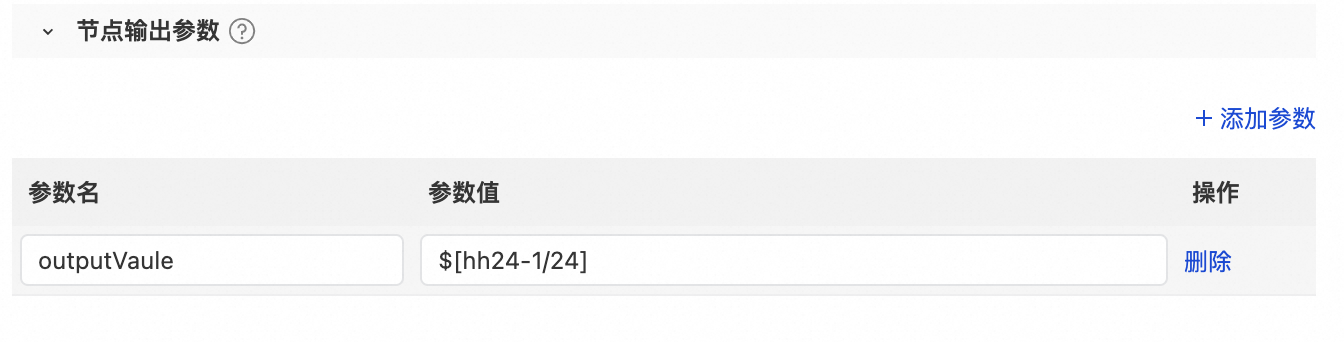
參數名:定義的輸出參數名稱。
參數值:輸出參數的取值。取實值型別包括常量和變數:
常量為固定字串。
變數包括系統支援的全域變數、調度內建參數、自訂參數。
配置節點關聯角色
DataWorks關聯角色允許為特定任務節點指定一個預設的 RAM 角色,任務在運行時將通過阿里雲 STS (Security Token Service) 動態擷取該角色的臨時訪問憑證。您的代碼無需明文填寫永久 AK,即可獲得訪問其他雲資源的許可權。
資源群組限制:僅支援運行在Serverless 資源群組的節點。
節點類型限制:僅支援Python、Shell、Notebook、PyODPS 2、PyODPS 3節點。
1、在 DataWorks 節點中配置關聯角色
在節點編輯介面的右側,找到並單擊回合組態。
在調度配置面板中,切換到關聯角色頁簽。
在RAM角色下拉框中,選擇您準備好的 RAM 角色。
重要如果下拉框為空白,或找不到所需的角色,請參考配置關聯角色(使用STS方式)訪問其他雲產品完成RAM角色配置。
配置完成後,提交節點。此配置僅對調試運行生效。
2、在代碼中擷取和使用臨時憑證
配置關聯角色後,DataWorks 會在任務運行時,將擷取到的臨時憑證注入到運行環境中。您可以通過以下兩種方式在代碼中擷取它們。
方式一:讀取環境變數(推薦 Shell, Python)
系統會自動化佈建以下三個環境變數,您可以直接在代碼中讀取。
LINKED_ROLE_ACCESS_KEY_ID:臨時存取金鑰 ID。LINKED_ROLE_ACCESS_KEY_SECRET:臨時存取金鑰 Secret。LINKED_ROLE_SECURITY_TOKEN:臨時安全性權杖。
程式碼範例 (Python):
此案例在運行中需選擇安裝oss2的Python自訂鏡像,相關操作請參見自訂鏡像。
import os
import oss2
# 1. 從環境變數擷取臨時憑證
access_key_id = os.environ.get('LINKED_ROLE_ACCESS_KEY_ID')
access_key_secret = os.environ.get('LINKED_ROLE_ACCESS_KEY_SECRET')
security_token = os.environ.get('LINKED_ROLE_SECURITY_TOKEN')
# 檢查是否成功擷取
if not all([access_key_id, access_key_secret, security_token]):
raise Exception("Failed to get linked role credentials from environment variables.")
# 2. 使用臨時憑證初始化 OSS 用戶端
# 假設您已為角色授予了訪問 'your-bucket-name' 的許可權
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, 'http://oss-<regionID>-internal.aliyuncs.com', 'your-bucket-name')
# 3. 使用用戶端訪問 OSS 資源
try:
# 列出 bucket 中的檔案
for obj in oss2.ObjectIterator(bucket):
print('object name: ' + obj.key)
print("Successfully accessed OSS with linked role.")
except oss2.exceptions.OssError as e:
print(f"Error accessing OSS: {e}")程式碼範例 (Shell):
#!/bin/bash
access_key_id=${LINKED_ROLE_ACCESS_KEY_ID}
access_key_secret=${LINKED_ROLE_ACCESS_KEY_SECRET}
security_token=${LINKED_ROLE_SECURITY_TOKEN}
# 訪問OSS,需替換regionID、bucket_name和file_name為真實資訊
echo "ID:"$access_key_id
echo "token:"$security_token
ls -al /home/admin/usertools/tools/
# 樣本為通過ossutil從OSS指定路徑下載檔案到本地test_dw.py,並輸出檔案內容。
/home/admin/usertools/tools/ossutil64 cp --access-key-id $access_key_id --access-key-secret $access_key_secret --sts-token $security_token --endpoint http://oss-<regionID>-internal.aliyuncs.com oss://<bucket_name>/<file_name> test_dw.py
echo "************************ 擷取成功 ************************,列印結果"
cat test_dw.py方式二:使用 Credentials Client (推薦 Python)
程式碼範例 (Python):
此案例在運行中需選擇安裝oss2、alibabacloud_credentials的Python自訂鏡像,相關操作請參見自訂鏡像。
from alibabacloud_credentials.client import Client as CredentialClient
import oss2
# 1. 使用 SDK 自動擷取憑證
# 它會自動尋找環境變數中的 LINKED_ROLE_* 等憑證資訊
cred_client = CredentialClient()
credential = cred_client.get_credential()
access_key_id = credential.get_access_key_id()
access_key_secret = credential.get_access_key_secret()
security_token = credential.get_security_token()
if not all([access_key_id, access_key_secret, security_token]):
raise Exception("Failed to get linked role credentials via SDK.")
# 2. 使用憑證初始化 OSS 用戶端
auth = oss2.StsAuth(access_key_id, access_key_secret, security_token)
bucket = oss2.Bucket(auth, 'http://oss-cn-hangzhou.aliyuncs.com', 'your-bucket-name')
# 3. 訪問 OSS
print("Listing objects in bucket...")
for obj in oss2.ObjectIterator(bucket):
print(' - ' + obj.key)
print("Successfully accessed OSS with linked role via SDK.")3、運行與驗證
Shell、Python:任務運行時,將使用指定的RAM角色訪問其他雲產品。
PyODPS:訪問其他雲產品(如OSS)時,使用您設定的 RAM 角色身份;但訪問 MaxCompute 資料時,仍然自動使用計算資源(專案層級)配置的訪問身份。
配置調度屬性
節點完成調試後,需將回合組態中的關聯角色同步至調度配置的。發布後,任務將以該角色的身份運行。
若在回合組態中配置自訂鏡像,需同步設定到調度配置中。
在營運中心查看執行角色
任務運行結束後,在營運中心查看任務執行個體的詳細資料,以確認是否成功使用指定的角色。
進入。
找到您啟動並執行節點執行個體,單擊進入詳情頁。
在執行個體詳情的屬性地區,查看執行身份欄位,此處展示本次運行實際使用的關聯角色ARN。
ARN為資源唯一標識,詳細說明可參見權限原則基本元素。
附錄參考
調度參數參考文檔:調度參數格式參考。
調度策略參考文檔:
調度時間參考文檔:調度時間參考文檔。
調度依賴參考文檔:
節點輸出參數參考文檔:配置並使用節點上下文參數。
其他參考文檔:夏令時切換對調度任務啟動並執行影響。