HBase資料來源為您提供讀取和寫入HBase的雙向通道,本文為您介紹DataWorks的HBase資料來源的同步能力支援情況。
支援的版本
HBase外掛程式可分為HBase和HBase{xx}xsql兩種,其中HBase{xx}xsql外掛程式需通過HBase結合Phoenix使用。
HBase外掛程式:
支援
HBase0.94.x、HBase1.1.x、HBase2.x,支援嚮導模式和指令碼模式,可使用hbaseVersion指定版本。如果您的HBase版本為
HBase0.94.x,Reader和Writer端的外掛程式請選擇094x。"reader": { "hbaseVersion": "094x" }"writer": { "hbaseVersion": "094x" }如果您的HBase版本為HBase1.1.x或HBase2.x,Reader和Writer端的外掛程式請選擇11x。
"reader": { "hbaseVersion": "11x" }"writer": { "hbaseVersion": "11x" }HBase1.1.x外掛程式當前可以相容HBase 2.0。
HBase{xx}xsql外掛程式
HBase20xsql外掛程式:支援
HBase2.x和Phoenix5.x。 只支援指令碼模式。HBase11xsql外掛程式:支援
HBase1.1.x和Phoenix5.x。只支援指令碼模式。HBase{xx}xsql Writer外掛程式實現了向HBase中的SQL表(Phoenix)大量匯入資料。因為Phoenix對rowkey進行了資料編碼,如果您直接使用HBaseAPI寫入,需要手動轉換資料,麻煩且易錯。HBase{xx}xsql Writer外掛程式為您提供了簡單的SQL表的資料匯入方式。
說明通過Phoenix的JDBC驅動,執行UPSERT語句向表中批量寫入資料。因為使用上層介面,所以可以同步更新索引表。
使用限制
HBase Reader | HBase20xsql Reader | HBase11xsql Writer |
|
|
|
支援的功能
HBase Reader
支援normal和multiVersionFixedColumn模式 ,配置方式參見:HBase欄位對應配置指導。。
normal模式:把HBase中的表當成普通二維表(橫表)進行讀取,擷取最新版本資料。hbase:007:0> scan 'student' ROW COLUMN+CELL s001 column=basic:age, timestamp=2026-03-09T14:41:40.240, value=20 s001 column=basic:name, timestamp=2026-03-09T14:41:40.214, value=Tom s001 column=score:english, timestamp=2026-03-09T14:41:40.333, value=90 s001 column=score:math, timestamp=2026-03-09T14:41:40.277, value=85 1 row(s) in 0.0580 seconds讀取後的資料如下所示。
rowKey
basic:age
basic:name
score:english
score:math
s001
20
Tom
90
85
multiVersionFixedColumn模式:把HBase中的表當成豎表進行讀取。讀出的每條記錄是四列形式,依次為rowKey、family:qualifier、timestamp和value。讀取時需要明確指定要讀取的列,把每一個cell中的值,作為一條記錄(record),若有多個版本則存在多條記錄。hbase:007:0> scan 'student',{VERSIONS=>5} ROW COLUMN+CELL s001 column=basic:age, timestamp=2026-03-09T14:41:40.240, value=20 s001 column=basic:age, timestamp=2026-03-09T14:30:00.100, value=19 s001 column=basic:name, timestamp=2026-03-09T14:41:40.214, value=Tom s001 column=score:english, timestamp=2026-03-09T14:41:40.333, value=90 s001 column=score:math, timestamp=2026-03-09T14:41:40.277, value=85 1 row(s) in 0.0260 seconds }讀取後的資料(4列) 如下所示。
rowKey
column:qualifier
timestamp
value
s001
basic:age
2026-03-09T14:41:40.240
20
s001
basic:age
2026-03-09T14:30:00.100
19
s001
basic:name
2026-03-09T14:41:40.214
Tom
s001
score:english
2026-03-09T14:41:40.333
90
s001
score:math
2026-03-09T14:41:40.277
85
HBase Writer
rowkey建置規則:目前HBase Writer支援源端多個欄位拼接作為HBase表的rowkey。寫入HBase的版本(時間戳記)支援:
指定目前時間作為版本。
指定源端列作為版本。
指定一個時間作為版本。
支援的欄位類型
離線讀
支援讀取HBase資料類型及HBase Reader針對HBase類型的轉換列表如下表所示。
類型分類
Data Integrationcolumn配置類型
資料庫資料類型
整數類
long
short、int和long
浮點類
double
float和double
字串類
string
binary_string和string
日期時間類
date
date
位元組類
bytes
bytes
布爾類
boolean
boolean
HBase20xsql Reader支援大部分Phoenix類型,但也存在個別類型未被支援的情況,請注意檢查您的類型。
HBase20xsql Reader針對Phoenix類型的轉換列表,如下所示。
DataX內部類型
Phoenix資料類型
long
INTEGER、TINYINT、SMALLINT、BIGINT
double
FLOAT、DECIMAL、DOUBLE
string
CHAR、VARCHAR
date
DATE、TIME、TIMESTAMP
bytes
BINARY、VARBINARY
boolean
BOOLEAN
離線寫
支援讀取HBase資料類型,HBase Writer針對HBase類型的轉換列表,如下表所示。
column的配置需要和HBase表對應的列類型保持一致。
除下表中羅列的欄位類型外,其它類型均不支援。
類型分類 | 資料庫資料類型 |
整數類 | INT、LONG和SHORT |
浮點類 | FLOAT和DOUBLE |
布爾類 | BOOLEAN |
字串類 | STRING |
注意事項
如果您在測試連通性時遇到"tried to access method com.google.common.base.Stopwatch"的錯誤資訊,請在資料來源的配置資訊中添加 hbaseVersion屬性,指定HBase版本。
建立資料來源
在進行資料同步任務開發時,您需要在DataWorks上建立一個對應的資料來源,操作流程請參見資料來源管理,詳細的配置參數解釋可在配置介面查看對應參數的文案提示。
資料同步任務開發
資料同步任務的配置入口和通用配置流程可參見下文的配置指導。
單表離線同步任務配置指導
使用嚮導模式時,由於HBase為無固定結構的資料來源,預設不會顯示欄位對應,您需要手動設定欄位對應。
HBase作為資料來源時,首先需要選擇輸出模式:橫表(normal 模式)和豎表(multiVersionFixedColumn 模式)。
兩種模式下的欄位對應配置方式不同:
橫表(normal)模式:預設模式,將HBase表按普通二維表讀取,擷取最新版本資料。HBase作為資料來源,需要配置來源欄位和目標欄位的映射關係。如圖所示,源端與目的端欄位為一一映射關係。當前資料來源類型由於源端表無固定欄位,預設為同行映射,如需改變映射關係,需手動編輯欄位順序。
新版資料開發

舊版資料開發
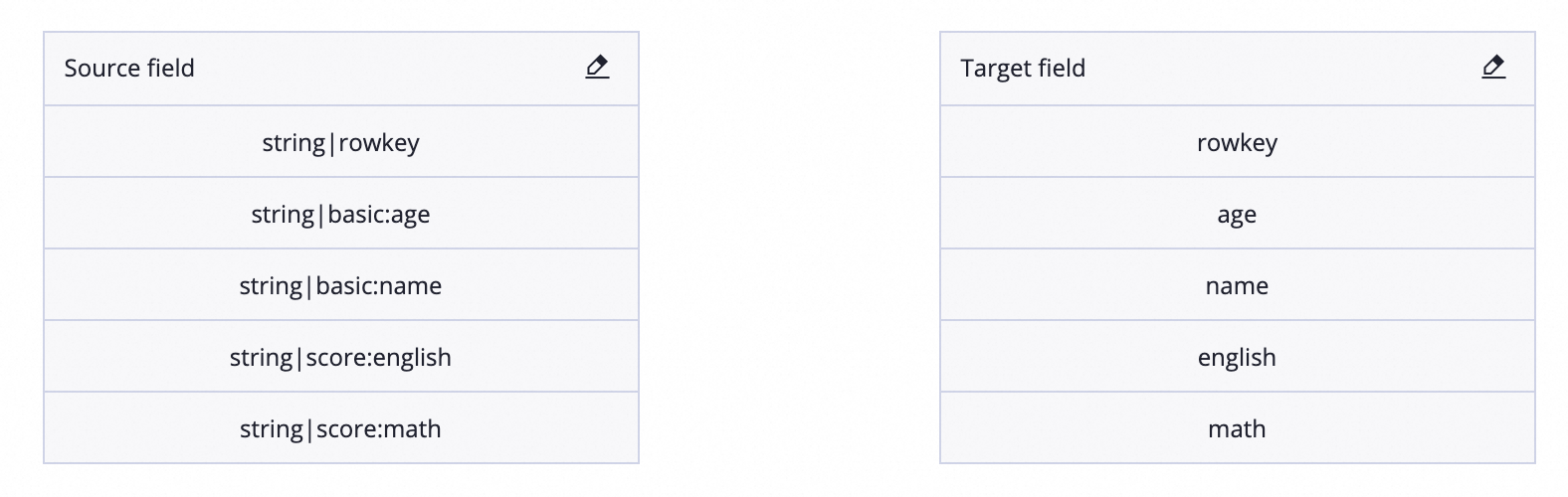
目標表寫入結果:

豎表(multiVersionFixedColumn)模式:每條輸出記錄由4列組成(rowKey、family:qualifier、timestamp、value),可讀取多版本資料。來源欄位配置格式為:
ColumnFamily:Qualifier(如basic:age),目標端為固定的4列表(欄位為如row_key、cf、timestamp_col、value)。配置時,無需關注映射關係。新版資料開發

舊版資料開發
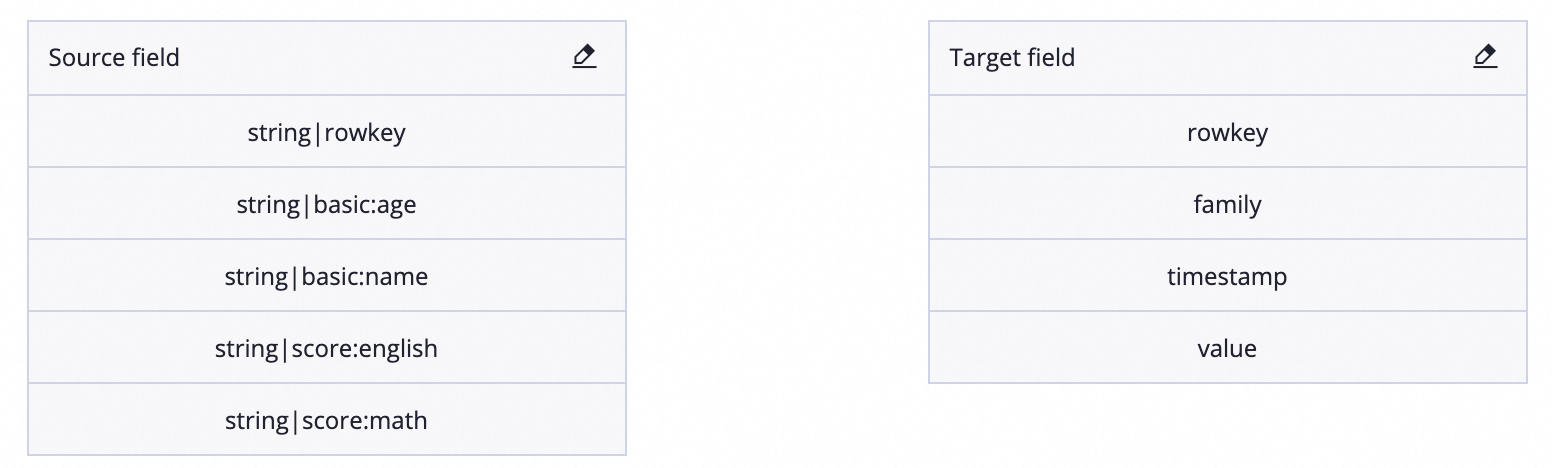
目標表結果:

HBase作為資料去向(僅支援normal模式),需要分別配置目標欄位和rowkey。其中,rowkey欄位可以由多個源端欄位拼接而成。
指令碼模式配置的全量參數和指令碼Demo請參見下文的附錄:指令碼Demo與參數說明。
常見問題
Q:並發設定多少比較合適?速度慢時增加並發有用嗎?
A:資料匯入進程預設JVM的堆大小是2GB,並發(channel數)是通過多線程實現的,開過多的線程有時並不能提高匯入速度,反而可能因為過於頻繁的GC導致效能下降。一般建議並發數(channel)為5-10。
Q:batchSize設定多少比較合適?
A:預設是256,但應根據每行的大小來計算最合適的batchSize。通常一次操作的資料量在2MB~4MB左右,用該值除以行大小,即可得到batchSize。
Q:使用
multiVersionFixedColumn模式讀取HBase時,報錯java.lang.StringIndexOutOfBoundsException: String index out of range: -1,如何解決?A:該錯誤通常是由於column配置中的
name欄位未使用列族:列名(columnFamily:qualifier)格式導致的。例如唯寫了列名age而非basic:age。請確保除rowkey外,所有column的name必須包含列族首碼,格式為columnFamily:qualifier。
附錄:指令碼Demo與參數說明
離線任務指令碼配置方式
如果您配置離線任務時使用指令碼模式的方式進行配置,您需要按照統一的指令碼格式要求,在任務指令碼中編寫相應的參數,詳情請參見指令碼模式配置,以下為您介紹指令碼模式下資料來源的參數配置詳情。
HBase Reader指令碼Demo
{
"type":"job",
"version":"2.0",//版本號碼。
"steps":[
{
"stepType":"hbase",//外掛程式名。
"parameter":{
"mode":"normal",//讀取HBase的模式,支援normal模式、multiVersionFixedColumn模式。
"scanCacheSize":"256",//HBase client每次RPC從伺服器端讀取的行數。
"scanBatchSize":"100",//HBase client每次RPC從伺服器端讀取的列數。
"hbaseVersion":"094x/11x",//HBase版本。
"column":[//欄位。
{
"name":"rowkey",//欄位名。
"type":"string"//資料類型。
},
{
"name":"basic:age",
"type":"string"
},
{
"name":"basic:name",
"type":"string"
},
{
"name":"score:english",
"type":"string"
},
{
"name":"score:math",
"type":"string"
}
],
"range":{//指定HBase Reader讀取的rowkey範圍。
"endRowkey":"",//指定結束rowkey。
"isBinaryRowkey":true,//指定配置的startRowkey和endRowkey轉換為byte[]時的方式,預設值為false。
"startRowkey":""//指定開始rowkey。
},
"maxVersion":"",//指定在多版本模式下的HBase Reader讀取的版本數。
"encoding":"UTF-8",//編碼格式。
"table":"student",//表名。
"hbaseConfig":{//串連HBase叢集需要的配置資訊,JSON格式。
"hbase.zookeeper.quorum":"hostname",
"hbase.rootdir":"hdfs://ip:port/database",
"hbase.cluster.distributed":"true"
}
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"odps",//目標端外掛程式名。此處以MaxCompute為例,您可以根據實際情況替換為其他Writer外掛程式。
"parameter":{
"partition":"",//目標表的分區資訊。非分區表無需配置。
"truncate":true,//寫入前是否清空表或分區中的資料,true表示清空。
"datasource":"odps_datasource",//MaxCompute資料來源名稱。
"column":[//目標端欄位列表。
"rowkey",
"basic_age",
"basic_name",
"score_english",
"score_math"
],
"table":"student_target"//MaxCompute目標表名。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1,//作業並發數。
"mbps":"12"//限流,此處1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}HBase Reader指令碼Demo(multiVersionFixedColumn模式)
以下樣本展示了使用multiVersionFixedColumn模式讀取HBase資料,並寫入MaxCompute的完整指令碼配置。在該模式下,HBase中每個Cell的值將被轉換為一條獨立的記錄,每條記錄由4列組成:rowKey、family:qualifier、timestamp、value。
{
"type":"job",
"version":"2.0",
"steps":[
{
"stepType":"hbase",//外掛程式名。
"parameter":{
"mode":"multiVersionFixedColumn",//讀取HBase的模式,此處使用multiVersionFixedColumn模式。
"scanCacheSize":"256",//HBase client每次RPC從伺服器端讀取的行數。
"scanBatchSize":"100",//HBase client每次RPC從伺服器端讀取的列數。
"hbaseVersion":"20x",//HBase版本。
"datasource":"hbase_datasource",//HBase資料來源名稱。
"column":[//欄位。第一個欄位必須為rowkey,其餘欄位的name必須為"列族:列名"格式。
{
"name":"rowkey",//rowkey欄位。
"type":"string"
},
{
"name":"basic:age",//列族basic下的列age。
"type":"string"
},
{
"name":"basic:name",//列族basic下的列name。
"type":"string"
},
{
"name":"score:english",//列族score下的列english。
"type":"string"
},
{
"name":"score:math",//列族score下的列math。
"type":"string"
}
],
"range":{
"isBinaryRowkey":false
},
"maxVersion":"-1",//讀取所有版本資料。multiVersionFixedColumn模式下此參數必填。取值為-1表示讀取所有版本。
"encoding":"UTF-8",//編碼格式。
"table":"student"//HBase表名。
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"odps",//目標端外掛程式名。此處以MaxCompute為例。
"parameter":{
"partition":"",//目標表的分區資訊。非分區表無需配置。
"truncate":true,//寫入前是否清空表或分區中的資料,true表示清空。
"datasource":"odps_datasource",//MaxCompute資料來源名稱。
"column":[//目標端固定4列,分別對應rowKey、family:qualifier、timestamp、value。
"rowkey",
"cf",
"timestamp_col",
"value"
],
"table":"hbase_multiversion_target"//MaxCompute目標表名。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數。
},
"speed":{
"throttle":false,//不限流。
"concurrent":2//作業並發數。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}MaxCompute目標表需要提前建立,建表語句樣本:CREATE TABLE IF NOT EXISTS hbase_multiversion_target (row_key STRING, cf STRING, timestamp_col STRING, value STRING);
HBase Reader指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
haveKerberos | haveKerberos值為true時,表示HBase叢集需要Kerberos認證。 說明
| 否 | false |
hbaseConfig | 串連HBase叢集需要的配置資訊,JSON格式。必填的配置為hbase.zookeeper.quorum,表示HBase的ZK連結地址。同時可以補充更多HBase client的配置,例如設定scan的cache、batch來最佳化與伺服器的互動。 說明 如果是雲HBase的資料庫,需要使用內網地址串連訪問。 | 是 | 無 |
mode | 讀取HBase的模式,支援normal模式和multiVersionFixedColumn模式。 | 是 | 無 |
table | 讀取的HBase表名(大小寫敏感) 。 | 是 | 無 |
encoding | 編碼方式,UTF-8或GBK,用於將二進位儲存的HBase byte[]轉換為String時的編碼。 | 否 | utf-8 |
column | 要讀取的HBase欄位,normal模式與multiVersionFixedColumn模式下必填。
| 是 | 無 |
maxVersion | 指定在多版本模式下的HBase Reader讀取的版本數,取值只能為-1或大於1的數字,-1表示讀取所有版本。 | multiVersionFixedColumn模式下必填項 | 無 |
range | 指定HBase Reader讀取的rowkey範圍。
| 否 | 無 |
scanCacheSize | HBase Reader每次從HBase中讀取的行數。 | 否 | 256 |
scanBatchSize | HBase Reader每次從HBase中讀取的列數。配置為-1時將返回所有列。 說明 scanBatchSize配置的數值最好大於實際列數,避免出現資料品質風險。 | 否 | 100 |
HBase Writer指令碼Demo
{
"type":"job",
"version":"2.0",//版本號碼
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"hbase",//外掛程式名。
"parameter":{
"mode":"normal",//寫入HBase的模式。
"walFlag":"false",//關閉(false)放棄寫WAL日誌。
"hbaseVersion":"094x",//Hbase版本。
"rowkeyColumn":[//要寫入的HBase的rowkey列。
{
"index":"0",//序號。
"type":"string"//資料類型。
},
{
"index":"-1",
"type":"string",
"value":"_"
}
],
"nullMode":"skip",//讀取的為null值時,如何處理。
"column":[//要寫入的HBase欄位。
{
"name":"columnFamilyName1:columnName1",//欄位名。
"index":"0",//索引號。
"type":"string"//資料類型。
},
{
"name":"columnFamilyName2:columnName2",
"index":"1",
"type":"string"
},
{
"name":"columnFamilyName3:columnName3",
"index":"2",
"type":"string"
}
],
"encoding":"utf-8",//編碼格式。
"table":"",//表名。
"hbaseConfig":{//串連HBase叢集需要的配置資訊,JSON格式。
"hbase.zookeeper.quorum":"hostname",
"hbase.rootdir":"hdfs: //ip:port/database",
"hbase.cluster.distributed":"true"
}
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1, //作業並發數。
"mbps":"12"//限流
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}HBase Writer指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
haveKerberos | haveKerberos值為true時,表示HBase叢集需要Kerberos認證。 說明
| 否 | false |
hbaseConfig | 串連HBase叢集需要的配置資訊,JSON格式。必填的配置為hbase.zookeeper.quorum,表示HBase的ZK串連地址。同時可以補充更多HBase client的配置,例如設定scan的cache、batch來最佳化與伺服器的互動。 說明 如果使用阿里雲HBase的資料庫,需要使用內網地址串連訪問。 | 是 | 無 |
mode | 寫入HBase的模式,目前僅支援normal模式,後續考慮動態列模式。 | 是 | 無 |
table | 要寫入的HBase表名(大小寫敏感) 。 | 是 | 無 |
encoding | 編碼方式,UTF-8或GBK,用於STRING轉HBase byte[]時的編碼。 | 否 | utf-8 |
column | 要寫入的HBase欄位:
| 是 | 無 |
rowkeyColumn | 要寫入的HBase的rowkey列:
配置格式如下所示。 | 是 | 無 |
versionColumn | 指定寫入HBase的時間戳記。支援目前時間、指定時間列或指定時間(三者選一),如果不配置則表示用目前時間。
配置格式如下所示。
| 否 | 無 |
nullMode | 讀取的資料為null值時,您可以通過以下兩種方式解決:
| 否 | skip |
walFlag | HBase Client向叢集中的RegionServer提交資料時(Put/Delete操作),首先會先寫WAL(Write Ahead Log)日誌(即HLog,一個RegionServer上的所有Region共用一個HLog),只有當WAL日誌寫成功後,才會接著寫MemStore,最後用戶端被通知提交資料成功。 如果寫WAL日誌失敗,用戶端則被通知提交失敗。關閉(false)放棄寫WAL日誌,從而提高資料寫入的效能。 | 否 | false |
writeBufferSize | 設定HBase Client的寫Buffer大小,單位位元組,配合autoflush使用。 autoflush(預設處於關閉狀態):
| 否 | 8M |
fileSystemUsername | 同步任務時如果出現Ranger許可權問題,可將嚮導式配置任務轉為指令碼模式,並配置有許可權的fileSystemUsername,DataWorks將按照指定的使用者訪問HBase。 | 否 | 無 |
HBase20xsql Reader指令碼Demo
{
"type":"job",
"version":"2.0",//版本號碼。
"steps":[
{
"stepType":"hbase20xsql",//外掛程式名。
"parameter":{
"queryServerAddress": "http://127.0.0.1:8765", //填寫串連Phoenix QueryServer地址。
"serialization": "PROTOBUF", //QueryServer序列化格式。
"table": "TEST", //讀取表名。
"column": ["ID", "NAME"], //所要讀取列名。
"splitKey": "ID" //切分列,必須是表主鍵。
},
"name":"Reader",
"category":"reader"
},
{
"stepType":"stream",
"parameter":{},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//錯誤記錄數。
},
"speed":{
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1,//作業並發數。
"mbps":"12"//限流,此處1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}HBase20xsql Reader指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
queryServerAddress | HBase20xsql Reader外掛程式需要通過Phoenix輕用戶端去串連Phoenix QueryServer,因此,您需要在此處填寫對應的QueryServer地址。如果HBase增強版(Lindorm)使用者需要透傳user、password參數,可以在queryServerAddress後增加對應的可選屬性。格式為: | 是 | 無 |
serialization | QueryServer使用的序列化協議。 | 否 | PROTOBUF |
table | 所要讀取的表名(大小寫敏感)。 | 是 | 無 |
schema | 表所在的schema。 | 否 | 無 |
column | 所配置的表中需要同步的列名集合,使用JSON的數組描述欄位資訊,空值表示讀取所有列。預設值為空白值。 | 否 | 全部列 |
splitKey | 讀取表時對錶進行切分,如果指定splitKey,表示您希望使用splitKey代表的欄位進行資料分區,資料同步因此會啟動並發任務進行資料同步,提高了資料同步的效能。您可以選擇兩種不同的切分方式,如果splitPoint為空白,預設根據方法一自動切分:
| 是 | 無 |
splitPoints | 根據切分列的最大值和最小值切分時不能保證避免資料熱點,因此,建議切分點根據Region的startkey和endkey進行設定,保證每個查詢對應單個Region。 | 否 | 無 |
where | 篩選條件,支援對錶查詢增加過濾條件。HBase20xsql Reader根據指定的column、table、where條件拼接SQL,並根據該SQL進行資料幫浦。 | 否 | 無 |
querySql | 在部分業務情境中,where配置項不足以描述所篩選的條件,您可以通過該配置項來自訂篩選SQL。配置該項後,除queryserverAddress參數必須設定外,HBase20xsql Reader會直接忽略column、table、where和splitKey條件的配置,使用該項配置的內容對資料進行篩選。 | 否 | 無 |
HBase11xsql Writer指令碼Demo
{
"type": "job",
"version": "1.0",
"configuration": {
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"throttle":true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent":1, //作業並發數。
"mbps":"1"//限流,此處1mbps = 1MB/s。
}
},
"reader": {
"plugin": "odps",
"parameter": {
"datasource": "",
"table": "",
"column": [],
"partition": ""
}
},
"plugin": "hbase11xsql",
"parameter": {
"table": "目標hbase表名,大小寫有關",
"hbaseConfig": {
"hbase.zookeeper.quorum": "目標hbase叢集的ZK伺服器位址",
"zookeeper.znode.parent": "目標hbase叢集的znode"
},
"column": [
"columnName"
],
"batchSize": 256,
"nullMode": "skip"
}
}
}HBase11xsql Writer指令碼參數
參數 | 描述 | 是否必選 | 預設值 |
plugin | 外掛程式名字,必須是hbase11xsql。 | 是 | 無 |
table | 要匯入的表名,大小寫敏感,通常Phoenix表都是大寫表名。 | 是 | 無 |
column | 列名,大小寫敏感。通常Phoenix的列名都是大寫。 說明
| 是 | 無 |
hbaseConfig | HBase叢集地址,ZK為必填項,格式為ip1, ip2, ip3。 說明
| 是 | 無 |
batchSize | 批量寫入的最大行數。 | 否 | 256 |
nullMode | 讀取到的列值為null時,您可以通過以下兩種方式進行處理:
| 否 | skip |