在EMR任務開發中,通過建立EMR(E-MapReduce)的MR(MapReduce)節點,可以將大規模資料集分解為多個平行處理的Map任務,從而顯著提高資料處理效率。本文將以一個執行個體——從Object Storage Service服務OSS讀取文字檔,並統計其中單詞數量為例,向您詳細介紹如何開發和配置EMR MR節點作業,協助您全面掌握這一流程。
前提條件
-
已建立阿里雲EMR叢集,並註冊EMR叢集至DataWorks。操作詳情請參見新版資料開發:綁定EMR計算資源。
-
(可選,RAM帳號需要)進行任務開發的RAM帳號已被添加至對應工作空間中,並具有開發或空間管理員(許可權較大,謹慎添加)角色許可權,新增成員的操作詳情請參見為工作空間增加空間成員。
如果您使用的是主帳號,則可忽略該添加操作。
-
如果您使用本文的作業開發樣本執行相關作業流程,則還需要建立好OSS的儲存空間Bucket。建立OSS的儲存空間Bucket,詳情請參見控制台建立儲存空間。
使用限制
-
僅支援使用Serverless資源群組(推薦)或獨享調度資源群組運行該類型任務。
-
DataLake或自訂叢集若要在DataWorks管理中繼資料,需先在叢集側配置EMR-HOOK。詳情請參見配置Hive的EMR-HOOK。
說明若未在叢集側配置EMR-HOOK,則無法在DataWorks中即時展示中繼資料、產生審計日誌、展示血緣關係、開展EMR相關治理任務。
準備初始資料及JAR資源套件
準備初始資料
建立樣本檔案input01.txt檔案內容如下。
hadoop emr hadoop dw
hive hadoop
dw emr上傳初始資料檔案
-
登入OSS管理主控台,單擊左側導覽列的Bucket列表。
-
單擊目標Bucket名稱,進入文件管理頁面。
本文樣本使用的Bucket為
onaliyun-bucket-2。 -
單擊建立目錄,建立初始資料及JAR資源的存放目錄。
-
配置目錄名為
emr/datas/wordcount02/inputs,建立初始資料的存放目錄。 -
配置目錄名為
emr/jars,建立JAR資源的存放目錄。
-
-
上傳初始資料檔案至初始資料的存放目錄。
-
進入
/emr/datas/wordcount02/inputs路徑,單擊上傳文件。 -
在待上傳檔案地區單擊掃描檔案,添加
input01.txt檔案至Bucket,單擊上傳文件。
-
使用MapReduce讀取OSS檔案並產生JAR包
-
開啟已建立的IDEA專案,添加pom依賴。
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.8.5</version> <!--因為EMR-MR用的是2.8.5--> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.8.5</version> </dependency> -
在MapReduce中讀寫OSS檔案,需要配置如下參數。
重要風險提示: 阿里雲帳號AccessKey擁有所有API的存取權限,建議您使用RAM使用者進行API訪問或日常營運。強烈建議不要將AccessKey ID和AccessKey Secret儲存到工程代碼裡或者任何容易被泄露的地方,AccessKey泄露會威脅您帳號下所有資源的安全。以下程式碼範例僅供參考,請妥善保管好您的AccessKey資訊。
conf.set("fs.oss.accessKeyId", "${accessKeyId}"); conf.set("fs.oss.accessKeySecret", "${accessKeySecret}"); conf.set("fs.oss.endpoint","${endpoint}");參數說明如下:
-
${accessKeyId}:阿里雲帳號的AccessKey ID。 -
${accessKeySecret}:阿里雲帳號的AccessKey Secret。 -
${endpoint}:OSS對外服務的訪問網域名稱。由您叢集所在的地區決定,對應的OSS也需要是在叢集對應的地區,詳情請參見地區和Endpoint。
以Java代碼為例,修改Hadoop官網WordCount樣本,即在代碼中添加AccessKey ID和AccessKey Secret的配置,以便作業有許可權訪問OSS檔案。
-
-
編輯完上述Java代碼後將該代碼產生JAR包。樣本產生的JAR包為
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar。
操作步驟
-
在EMR MR節點編輯頁面,執行如下開發操作。
開發EMR MR任務
您可以根據不同情境需求選擇適合您的操作方案:
方案一:先上傳資源後引用EMR JAR資源
DataWorks也支援您從本地先上傳資源至Data Studio,再引用資源。若EMR MR節點依賴的資源較大,則無法通過DataWorks頁面上傳。您可將資源存放至HDFS上,然後在代碼中進行引用。
-
建立EMR JAR資源。
-
詳情請參見資源管理。將準備初始資料及JAR資源套件中產生的JAR包儲存在JAR資源的存放目錄
emr/jars下。單擊点击上传按鈕,上傳JAR資源。 -
選擇存储路径、數據源及資源組。
-
單擊保存按鈕進行儲存。

-
-
引用EMR JAR資源。
-
開啟建立的EMR MR節點,停留在代碼編輯頁面。
-
在左側導覽列的資源管理中找到待引用資源(樣本為
onaliyun_mr_wordcount-1.0-SNAPSHOT.jar),右鍵選擇引用資源。 -
選擇引用後,當EMR MR節點的代碼編輯頁面出現如下引用成功提示時,表明已成功引用代碼資源。此時,需要執行下述命令。如下命令涉及的資源套件、Bucket名稱、路徑資訊等為本文樣本的內容,使用時,您需要替換為實際使用資訊。
##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs說明EMR MR節點編輯代碼時不支援備註陳述式。
-
方案二:直接引用OSS資源
當前節點可通過OSS REF的方式直接引用OSS資源,在運行EMR節點時,DataWorks會自動載入代碼中的OSS資源至本地使用。該方式常用於“需要在EMR任務中運行JAR依賴”、“EMR任務需依賴指令碼”等情境。
-
上傳JAR資源。
-
完成代碼開發後,您需登入OSS管理主控台,單擊所在地區左側導覽列的Bucket列表。
-
單擊目標Bucket名稱,進入文件管理頁面。
本文樣本使用的Bucket為
onaliyun-bucket-2。 -
上傳JAR資源至JAR資源的存放目錄。
進入存放目錄
emr/jars,單擊上傳文件,在待上傳檔案地區單擊掃描檔案,添加onaliyun_mr_wordcount-1.0-SNAPSHOT.jar檔案至Bucket,單擊上傳文件。
-
-
引用JAR資源。
編輯引用JAR資原始碼。
在已建立的EMR MR節點編輯頁面,編輯引用JAR資原始碼。
hadoop jar ossref://onaliyun-bucket-2/emr/jars/onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs說明上述命令列格式為
hadoop jar <引用運行JAR儲存路徑> <啟動並執行主類全名稱> <讀入檔案儲存體目錄> <寫出結果儲存目錄>。引用運行JAR儲存路徑參數說明:
參數
參數說明
引用運行JAR儲存路徑
格式為
ossref://{endpoint}/{bucket}/{object}-
Endpoint:OSS對外服務的訪問網域名稱。Endpoint為空白時,僅支援使用與當前訪問的EMR叢集同地區的OSS,即OSS的Bucket需要與EMR叢集所在地區相同。
-
Bucket:OSS用於儲存物件的容器,每一個Bucket有唯一的名稱,登入OSS管理主控台,可查看當前登入帳號下所有Bucket。
-
object:儲存在Bucket中的一個具體的對象(檔案名稱或路徑)。
-
(可選)配置進階參數
您可在節點右側調度配置的中配置下表特有屬性參數。
說明-
不同類型EMR叢集可配置的進階參數存在部分差異,具體如下表。
-
更多開源Spark屬性參數,可在節點右側調度配置的中進行配置。
DataLake叢集/自訂叢集:EMR on ECS
進階參數
配置說明
queue
提交作業的調度隊列,預設為default隊列。關於EMR YARN說明,詳情請參見隊列基礎配置。
priority
優先順序,預設為1。
FLOW_SKIP_SQL_ANALYZE
SQL語句執行方式。取值如下:
-
true:表示每次執行多條SQL語句。 -
false(預設值):表示每次執行一條SQL語句。
說明該參數僅支援用於資料開發環境測試回合流程。
其他
您也可以直接在進階配置裡追加自訂MR任務參數。提交代碼時DataWorks會自動在命令中通過
-D key=value語句加上新增的參數。Hadoop叢集:EMR on ECS
進階參數
配置說明
queue
提交作業的調度隊列,預設為default隊列。關於EMR YARN說明,詳情請參見隊列基礎配置。
priority
優先順序,預設為1。
USE_GATEWAY
設定本節點提交作業時,是否通過Gateway叢集提交。取值如下:
-
true:通過Gateway叢集提交。 -
false(預設值):不通過Gateway叢集提交,預設提交到header節點。
說明如果本節點所在的叢集未關聯Gateway叢集,此處手動設定參數取值為
true時,後續提交EMR作業時會失敗。執行SQL任務
-
在回合組態的計算資源中,選擇配置計算資源和資源組。
說明-
您還可以根據任務執行所需的資源情況來調度 CU。預設CU為
0.25。 -
訪問公用網路或VPC網路環境的資料來源需要使用與資料來源測試連通性成功的調度資源群組。詳情請參見網路連通方案。
-
-
在工具列的參數對話方塊中選擇已建立的資料來源,單擊運行SQL任務。
-
-
如需定期執行節點任務,請根據業務需求配置調度資訊。配置詳情請參見節點調度配置。
-
節點任務配置完成後,需對節點進行發布。詳情請參見節點/工作流程發布。
-
任務發布後,您可以在營運中心查看周期任務的運行情況。詳情請參見營運中心入門。
查看結果
-
登入OSS管理主控台,您可以在目標Bucket的初始資料存放目錄下查看寫入結果。樣本路徑為emr/datas/wordcount02/outputs。
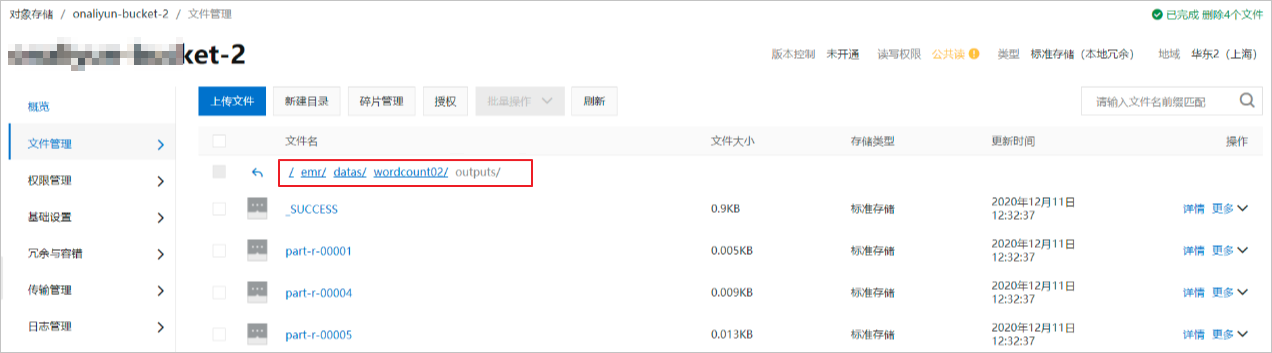
-
在DataWorks讀取統計結果。
-
建立EMR Hive節點,詳情請參見建立調度工作流程的節點。
-
在EMR Hive節點中建立掛載在OSS上的Hive外表,讀取表資料。程式碼範例如下。
CREATE EXTERNAL TABLE IF NOT EXISTS wordcount02_result_tb ( `word` STRING COMMENT '單詞', `cout` STRING COMMENT '計數' ) ROW FORMAT delimited fields terminated by '\t' location 'oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs/'; SELECT * FROM wordcount02_result_tb;運行結果如下圖。
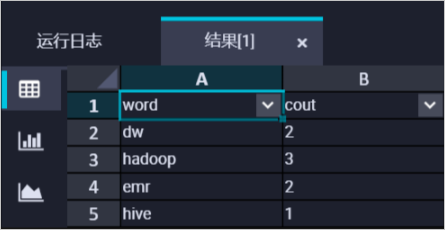
-