在ChatBI中進行互動式會話之前,需要通過資料集來圈定開展分析的資料範圍。資料集可以是目標資料來源中的資料表,也可以是本地檔案。
準備工作
已在使用ChatBI功能的對應地區建立Serverless資源群組。
適用範圍
-
資料來源類型的資料集,僅支援選擇Hologres、MaxCompute、StarRocks和MySQL類型的資料來源。
-
本地檔案類型的資料集,僅支援
xls、xlsx和csv格式,且最多上傳10個檔案,每個檔案不超過1GB。
建立資料集
-
進入ChatBI功能入口。
您需要先登入阿里雲,然後通過瀏覽器訪問ChatBI智能資料洞察頁面。請根據您的DataWorks資源群組、資料集等業務所在地區按需選擇。
-
在頁面左側導覽列單擊數據集,進入資料集頁面,點擊新建數據集。
-
在新建數據集頁面,填寫資料集相關資訊:
-
資料集類型為數據源:
參數
描述
基本信息
名稱
自訂資料集名稱。
類型
資料集類型,包括:
-
數據源
-
本地文件
此處選擇數據源類型。
數據源類型
資料來源類型,包括:
-
Hologres
-
MaxCompute
-
StarRocks
-
MySQL
資料來源相關資訊
不同資料來源配置參數有差異。
以Hologres為例,需要配置地域、Hologres實例、數據庫名稱。
資源組
選擇一個DataWorks Serverless資源群組名稱,用於在後續會話中使用該資源群組訪問資料來源以進行資料查詢。
測試連通性
測試目標DataWorks Serverless資源群組和當前資料來源之間的連通性。
選擇目標表
選擇目標表
配置完基本信息後,單擊下一步,進入選擇目標表步驟。
在待選擇列表中選中目標資料表,單擊
 ,將其添加至已選擇列表中,表示將目標資料表加入當前資料集。
,將其添加至已選擇列表中,表示將目標資料表加入當前資料集。 -
-
資料集類型是本地文件:
參數
描述
基本信息
名稱
自訂資料集名稱。
類型
資料集類型,包括:
-
資料來源
-
本地檔案
此處選擇本地文件類型。
上傳本地檔案
上傳本地檔案時支援
xls、xlsx和csv格式,最多上傳10個檔案,每個檔案不超過1GB。 -
-
-
當完成資料集配置後,點擊下一步進入數據洞察步驟,將自動開始對資料集進行掃描,擷取資料取值特徵,有助於提升會話過程中的分析準確性。
-
資料洞察可能耗時較久,您可以直接單擊完成,後續可在資料集中查看。
查看資料集
-
在頁面左側導覽列單擊數據集,進入資料集頁面。
-
找到目標資料集卡片,單擊進入資料集詳情頁。
-
在資料集詳情頁中,頂部是資料集的基礎資訊(包括:類型、表/檔案數量、建立者),左側是表/檔案清單,右側是表/檔案的基礎資訊和資料預覽(可預覽20條資料記錄)。
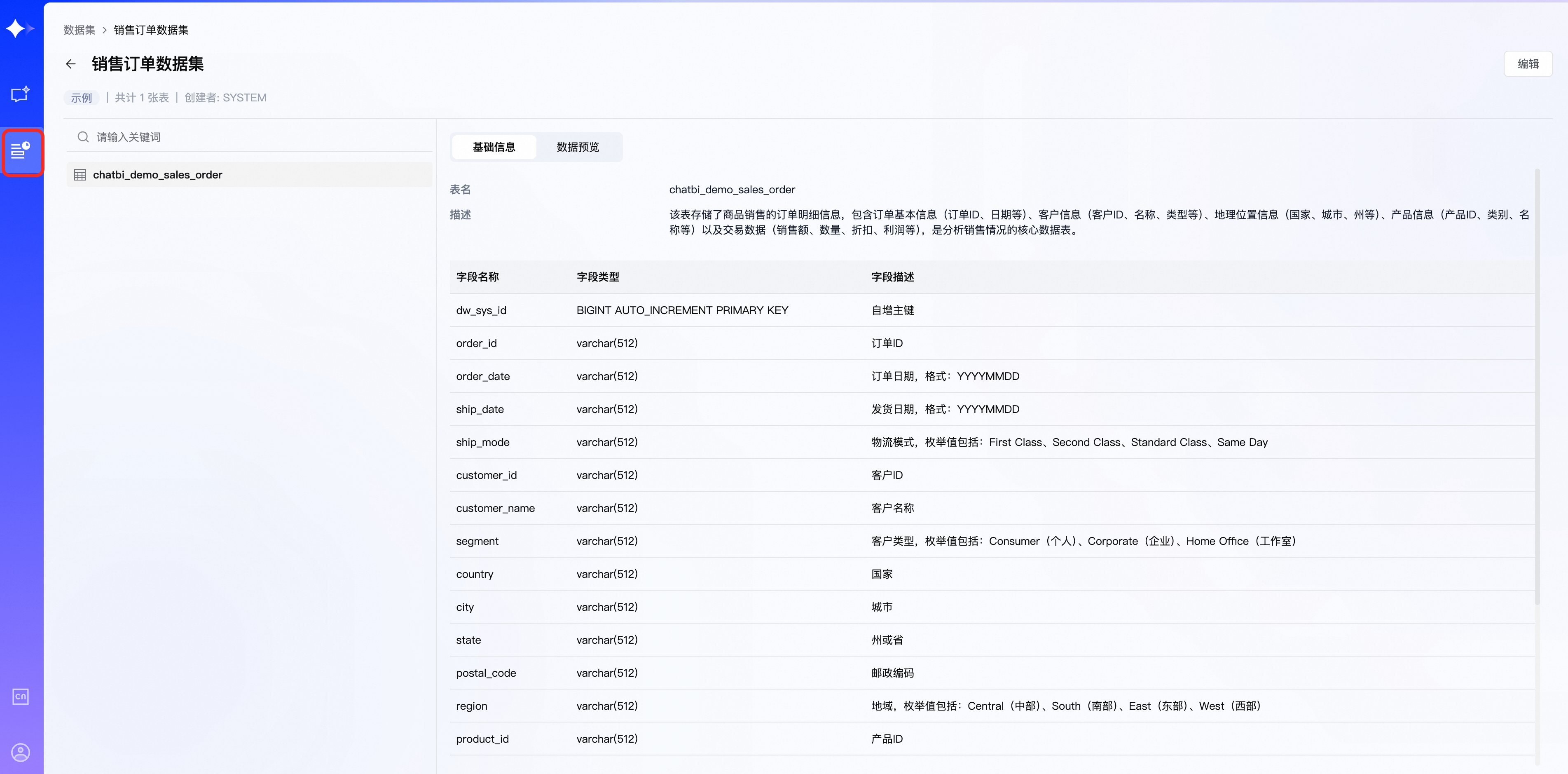
編輯資料集
-
在頁面左側導覽列單擊數據集,進入資料集頁面。
-
找到目標資料集卡片,您可以通過兩種方式進入資料集編輯頁。
-
滑鼠移至上方在目標資料集卡片上,在卡片右上方單擊
 > 編輯。
> 編輯。 -
單擊目標資料集卡片,進入資料集詳情頁,在右上方單擊編輯按鈕。
-
-
修改資料集相關配置。相關參數解釋同建立資料集。
說明編輯已有資料集配置時,類型、資料來源類型不可修改。
-
當完成資料集編輯後,點擊下一步進入資料洞察,重新對資料集中的資料進行資料洞察。
刪除資料集
-
在頁面左側導覽列單擊數據集,進入資料集頁面。
-
滑鼠移至上方在目標資料集卡片上,在卡片右上方單擊
> 刪除。刪除資料集後,相關聯的會話和圖表均無法正常顯示資料。
後續步驟:基於資料集開始會話
-
您可以通過如下兩種方式基於指定資料集開始會話。
-
在頁面左側導覽列單擊數據集,進入資料集頁面。滑鼠移至上方在目標資料集卡片上,在卡片右上方單擊
 開始對話。
開始對話。 -
在頁面左側導覽列單擊建立會話,進入ChatBI會話視窗。然後在會話視窗中,單擊选择数据集。

-
-
進入会话頁面,通過輸入需求或問題後,即可開始資料分析。詳情請參見ChatBI會話。
提問技巧
ChatBI 的分析品質與提問方式密切相關。掌握以下提問技巧,可以協助您獲得更精準、更有價值的資料分析結果。
明確分析目標
一個好的分析問題應包含明確的分析對象、度量指標和分析維度。
|
正常化提問方式(推薦) |
非規範表述(需避免) |
|
2025年各月份華東地區銷售額趨勢 |
幫我看看銷售情況 |
|
近7天每天新增使用者數及其同比增長率 |
最近使用者增長怎麼樣? |
|
各商品類目 TOP10 退貨率及對應退貨原因分布 |
退貨多嗎? |
善用時間和篩選條件
在提問中明確指定時間範圍和篩選條件,可以協助 ChatBI 產生更精確的 SQL,避免不必要的全表掃描。
-
指定時間範圍:例如"2025年Q4各產品線的毛利率"比"各產品線毛利率"更精確,能減少查詢資料量。
-
指定篩選維度:例如"華北地區VIP客戶的客單價分布"比"客單價是多少"更有針對性。
-
使用業務術語:提問時使用資料表中的實際欄位值或知識庫中配置的業務術語,例如使用"status='已完成'"而非"完成了的訂單",有助於 ChatBI 精確匹配資料。
分步提問複雜需求
對於複雜的分析需求,建議將其拆分為多個簡單問題分步提問,逐步深入分析。
-
第一步:全域概覽:先提出總覽性問題,瞭解整體趨勢。例如"2025年各月銷售額整體趨勢"。
-
第二步:定位異常:發現異常後,針對性地深入提問。例如"3月份銷售額下降的原因,按產品類目拆解"。
-
第三步:歸因分析:對關鍵發現進行進一步歸因。例如"3月份電子產品類目中,哪些子品類的下降幅度最大"。
多輪對話技巧
ChatBI 支援在同一會話中進行多輪連續提問。以下技巧可以協助您更高效地進行多輪分析。
-
追問細化:在上一輪結果基礎上追問,例如先問"各地區銷售額排名",再追問"排名第一的地區按月度的銷售額明細"。
-
修正指令:如果分析結果不符合預期,可以在下一輪明確指出需要調整的部分。例如"上面的分析結果請按季度匯總,而不是按月"或"請排除測試資料,只看正式訂單"。
-
切換可視化:對同一份資料結果,可以要求不同的展示方式。例如"請把上面的資料用餅圖展示"或"請按降序排列"。
結果不準確時的處理
當 ChatBI 的分析結果不夠準確時,可以從以下幾個方面進行最佳化。
-
檢查目標表匹配:在分析結果的"識別目標表"步驟中確認 ChatBI 是否選擇了正確的資料表。如果匹配了錯誤的表,可以在提問中明確指定表名,例如"基於 ods_order_detail 表分析各品類銷售額"。
-
最佳化提問表述:使用更精確的業務術語和明確的指標定義重新提問。例如將"活躍使用者有多少"改為"近30天有登入行為的去重使用者數"。
-
完善知識庫:如果某類問題持續不準確,建議管理員在知識庫中添加對應的問題範本、術語或商務邏輯。配置後 ChatBI 會優先使用知識庫中的知識來理解和處理該類問題。
-
檢查產生的 SQL:展開"產生執行計畫"步驟中的 SQL 代碼,確認查詢邏輯是否正確。如有問題,可複製 SQL 進行手動修改後執行,並將正確的 SQL 作為問題範本添加到知識庫中。
資料來源配置指南
MySQL
-
全表掃描風險:ChatBI 根據提問產生的 SQL 可能會進行全表掃描。如果表中資料量較大(百萬行以上),將會對資料庫造成較高負載。強烈建議將唯讀備庫或從庫作為資料集的資料來源,避免對生產環境造成影響。
-
索引最佳化:為高頻查詢的篩選欄位(如時間列、狀態列、分類列)建立索引,可以加速 ChatBI 產生的 SQL 執行速度。
-
欄位命名:使用有明確業務含義的英文欄位名(如
order_amount、customer_name),並添加中文欄位注釋。ChatBI 依賴欄位名和注釋來理解表結構,良好的命名可以顯著提升目標表匹配和 SQL 產生的準確性。 -
適用情境:適合資料量在千萬行以內的業務資料庫查詢情境,如訂單分析、客戶管理等線上業務資料分析。
Hologres
-
分區表設計:推薦使用分區表,按時間(如日期或月份)進行分區。ChatBI 產生的 SQL 在查詢分區表時,能夠自動進行分區裁剪,大幅減少掃描的資料量,避免因查詢範圍過大導致查詢逾時。
-
表注釋和列注釋:Hologres 支援為表和列添加
COMMENT,ChatBI 會讀取這些注釋來理解資料語義。建議為每張表和每個關鍵字段添加中文注釋,描述其業務含義。 -
行列混合儲存:對於 ChatBI 以彙總分析為主的查詢情境,建議使用列存模式,可獲得更好的查詢效能。
-
適用情境:適合即時和近即時資料分析情境,支援億級資料量的互動式查詢,特別適合即時看板和即時指標分析。
MaxCompute
-
分區裁剪:MaxCompute 為海量資料處理引擎,單次查詢可能掃描大量資料。強烈建議使用分區表,並確保常用的過濾維度(如日期、地區)作為分區鍵。ChatBI 產生 SQL 時會盡量使用分區條件,減少不必要的全表掃描。
-
查詢耗時:MaxCompute 為離線批處理引擎,查詢回應時間通常在數秒到數分鐘之間,取決於資料量和查詢複雜度。如需秒級響應,建議使用 Hologres 或 StarRocks。
-
SQL 方言差異:MaxCompute 使用自有 SQL 方言,部分函數和文法與標準 SQL 存在差異。ChatBI 已適配 MaxCompute SQL 文法,會自動產生符合 MaxCompute 規範的 SQL。如發現產生的 SQL 執行報錯,可在知識庫中添加問題範本來引導正確的 SQL 寫法。
-
適用情境:適合 TB 到 PB 層級的海量離線資料分析情境,如歷史資料趨勢分析、全量使用者行為分析等。
StarRocks
-
MPP 架構特性:StarRocks 採用大規模平行處理(MPP)架構,擅長多維分析和複雜彙總查詢。ChatBI 提出的多維度交叉分析類問題,在 StarRocks 上通常能獲得較好的查詢效能。
-
物化視圖:如果某些彙總查詢是高頻情境,建議在 StarRocks 中建立物化視圖來加速查詢。ChatBI 會自動利用物化視圖來提升查詢效能。
-
資料建模:StarRocks 支援明細模型、彙總模型、更新模型和主鍵模型。對於 ChatBI 分析情境,明細模型適合靈活多維分析,彙總模型適合固定指標查詢情境。根據實際分析需求選擇合適的模型。
-
適用情境:適合即時多維分析和 Ad-hoc 查詢情境,支援億級資料量的秒級查詢響應,特別適合使用者行為分析、即時報表等情境。