節點上下文功能支援在上遊和下遊節點之間自動傳遞參數。可傳遞的參數類型包括常量、變數或上遊節點的查詢結果,以實現任務的動態調度與執行。
使用限制
-
產品版本:DataWorks為標準版及以上版本支援添加賦值參數功能(用於傳遞查詢結果)。
-
節點類型限制:僅部分節點類型支援通過賦值參數傳遞查詢結果,包括:EMR Hive、EMR Spark SQL、ODPS Script、Hologres SQL、AnalyticDB for PostgreSQL、Click House SQL和MySQL節點。
工作原理
節點上下文參數通過在上遊節點(提供方)定義輸出參數,在下遊節點(使用方)引用該參數,實現值的傳遞。
-
上遊節點(提供方):負責產生一個值並將其作為輸出參數。提供值的方式有兩種:
-
配置普通輸出參數:在上遊節點的本節點輸出參數地區,定義參數並為其賦值。值可以是常量(如
'abc')或系統上下文變數(如${status})。 -
配置賦值輸出參數:系統將節點代碼(如
SELECT 'table_A';)的最後一行查詢結果,捕獲並賦值給一個內建的輸出參數outputs,然後將這個參數的值傳遞給下遊節點。參數值取決於代碼的運行結果。賦值節點和部分 SQL 類節點支援此方式。
-
-
下遊節點(使用方):接收並使用上遊節點提供的值。
-
建立調度依賴:配置對上遊節點的調度依賴。
-
配置輸入參數:在下遊節點的本節點輸入參數地區,添加輸入參數,並將其取值來源設定為上遊節點的輸出參數。
-
在代碼中引用:在下遊節點的代碼中,通過
${輸入參數名}的格式引用接收到的值。例如,若上遊節點傳遞了值table_A,下遊代碼中的SELECT * FROM ${input};在運行時會變為SELECT * FROM table_A;。
-
進入參數配置地區
-
登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
-
在数据开发面板,雙擊開啟相應節點的編輯頁面。
-
單擊右側的調度配置,在節點上下文參數地區單擊右側的
 ,即可進入節點上下文參數配置地區。
,即可進入節點上下文參數配置地區。
配置輸出參數
在節點上下文參數地區配置本節點輸出參數時,您可根據執行個體業務進行相關配置。
配置普通輸出參數
如需將上遊節點的配置的參數資訊傳遞到下遊節點,可參見以下內容。
|
參數 |
配置說明 |
|
編號 |
編號為系統控制,自動增加。 |
|
參數名 |
您需自訂輸出參數名稱。 |
|
類型 |
支援常量和變量,您可根據實際業務進行選擇配置。 |
|
取值 |
輸出參數的取值。取實值型別包括常量和變數:
|
|
描述 |
參數的簡要描述。 |
|
來源 |
當前參數的來源。 包括系統默認添加、代碼解析和手動添加。 |
|
操作 |
提供保存、編輯和刪除操作。 說明
存在下遊節點依賴時,不支援編輯和刪除。在下遊節點添加對上遊節點引用之前,請謹慎檢查,確保上遊輸出定義正確。 |
配置完相關參數後,單擊後面操作欄中的保存即可。
配置賦值輸出參數
如需將當前任務的查詢結果作為參數傳遞給下遊任務進行使用,可參見以下內容。
-
找到該節點的地區。
-
單擊添加賦值參數,一鍵添加輸出的賦值參數。
單擊添加賦值參數後,賦值參數會將本節點查詢結果傳遞到引用該賦值參數的下遊節點。如果產生結果為空白,不會阻塞本節點運行,但下遊引用的節點可能會失敗。
下遊節點需要在輸入參數中添加上遊節點的賦值參數,其使用方式與賦值節點的行為基本一致,可參考賦值節點完成配置。
配置完本節點輸出參數,您可在當前配置頁找到裡面添加方式為系統默認添加的輸出名稱,下遊節點可通過該輸出名稱綁定與本節點的依賴關係。
配置輸入參數
在節點上下文參數地區配置本節點輸入參數,您可通過該操作擷取上遊節點輸出參數給本節點使用。
-
節點的輸入參數可用於擷取其上遊節點的輸出參數,添加成功後可以在當前節點代碼中使用,使用方式與調度參數在代碼中的定義變數的方式一致。
-
當前節點設定依賴某個上遊節點後,當前節點才能在本節點輸入參數處將該上遊節點的輸出添加為當前節點的輸入參數。
-
已為上遊節點配置輸出參數。
-
設定上下遊依賴關係。
-
單擊下遊節點編輯頁面右側的調度配置。
-
在的節點輸出後面的對話方塊中,輸入並選擇您在上遊節點配置輸出參數時的輸出名稱。
-
單擊添加即可。
-
-
下遊節點配置輸入參數。
在節點上下文參數中,單擊添加本節點輸入參數,配置參數可參考下表:
參數
配置說明
編號
編號為系統控制,自動增加。
參數名
您需自訂輸出參數名稱。後續可在節點編輯頁通過該參數名引用上遊傳遞的參數資訊。
取值來源
參數的取值來源於上遊節點的輸出參數,具體取值為上遊節點的實際輸出結果。
描述
您可自訂參數的簡要描述。
父節點ID
自動從上遊節點解析得到。
來源
當前參數的來源。
包括系統默認添加、代碼解析和手動添加。
操作
提供保存、編輯和刪除操作。
-
配置完相關參數後,單擊後面操作欄中的保存即可。
下遊節點使用輸入參數
在節點中使用定義的輸入參數的方法與其它系統變數一致,可以通過${輸入參數名}的方式進行引用。以下以Shell節點為例,為您說明具體的引用方式。
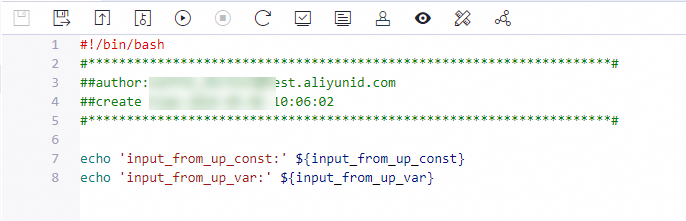
執行任務時,您需運行上下遊節點所在的商務程序,保證上下遊節點按順序執行。否則下遊節點使用的輸入參數無效。
系統支援的全域變數
-
系統變數
系統變數
說明
${projectId}
專案ID。
${projectName}
MaxCompute專案名。
${nodeId}
節點ID。
${gmtdate}
執行個體定時時間所在天的00:00:00,格式為yyyy-MM-dd 00:00:00。
${taskId}
任務執行個體ID。
${seq}
任務執行個體序號,代表該執行個體在當天同節點執行個體中的序號。
${cyctime}
執行個體定時時間。
${status}
執行個體的狀態:成功(SUCCESS)、失敗(FAILURE)。
${bizdate}
業務日期。
${finishTime}
執行個體結束時間。
${taskType}
執行個體運行類型:正常(NORMAL)、手動(MANUAL)、暫停(PAUSE)、空跑(SKIP)、未選擇(UNCHOOSE)、周月空跑(SKIP_CYCLE)。
${nodeName}
節點名稱。
-
其它參數設定請參見調度參數支援的格式。