對於開源FlinkRealtime Compute引擎的即時執行個體,可在Dataphin中查看運行分析。運行分析不僅可以支援對即時執行個體資訊進行分析、重新整理等操作,也可以展示失敗次數、反壓情況、各Sink的資料輸出、Checkpoint失敗次數等資訊。
許可權說明
查看專案的運行分析,需要具備專案空間許可權。
查看Apache Flink Dashboard需要填寫使用者名稱和密碼,支援超級管理員、系統管理員、任務負責人、專案營運負責人查看使用者名稱密碼提示資訊。
運行分析入口
在Dataphin首頁的頂部功能表列中,選擇研發 > 任務營運。
在左側導覽列選擇執行個體營運 > 即時執行個體,在即時執行個體頁面中,單擊目標執行個體操作列的
 表徵圖。
表徵圖。
查看運行分析
在運行分析頁面您可以查看各指標的運行情況。如下圖所示:
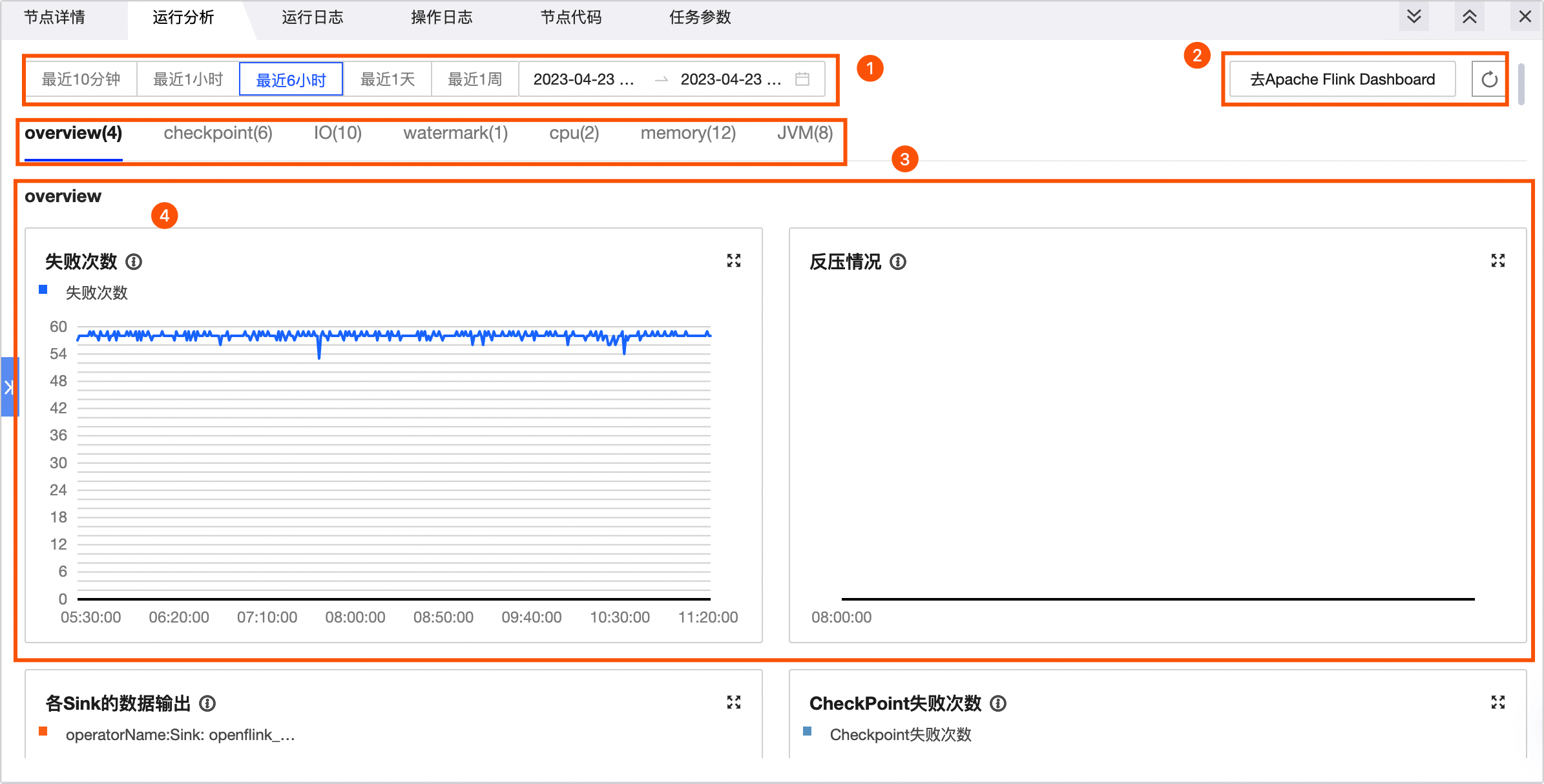
功能 | 描述 |
①時間地區選取項目 |
|
②去Apache Flink Dashboard與重新整理 |
|
③即時監控指標 | Flink SQL或Flink Datastream任務,可查看以下指標:overview、checkpoint、IO、watermark、cpu、memory、JVM。各指標詳情,請參見即時監控指標說明。 |
④指標資料統計 | 您可查看各指標在目前時間段內的資料情況。 |
指標統計說明
若所選擇的時間區間小於或等於6小時,可查看每分鐘採集的所有資料點。
若所選擇的時間區間大於6小時且小於等於24小時,可查看從整點開始的每5分鐘所採集的資料點,每個資料點為該時間點前5分鐘的記數。
若所選擇的時間區間大於24小時,可查看從整點開始的每10分鐘所採集的資料點,每個資料點為該時間點前10分鐘的記數。
即時監控指標說明
overview
監控指標 | 描述 | 單位 |
失敗次數 | 目前時間段內任務的失敗次數。 | 次數 |
反壓情況 | 目前時間段內該任務是否存在反壓。當前任務生產資料的速率比下遊任務消費資料的速率要快時,將產生反壓。 | 是或否 |
各Sink的資料輸出 | Sink輸出的情況(TPS)。 | 次/秒 |
Checkpoint失敗次數 | 目前時間段內任務Checkpoint的失敗次數。 | 次數 |
checkpoint
監控指標 | 細分類型 | 描述 | 單位 |
Checkpoint總數 (Num of Checkpoints) | Checkpoint總數 (totalNumberOfCheckpoints) | 目前時間段內任務Checkpoint總數。 | 個 |
失敗的Checkpoint總數 (numberOfFailedCheckpoints) | 目前時間段內任務失敗的Checkpoint數量。 | 個 | |
已完成的Checkpoint總數 (numberOfCompletedCheckpoints) | 目前時間段內任務已完成的Checkpoint數量。 | 個 | |
進行中的Checkpoint總數 (numberOfInProgressCheckpoints) | 目前時間段內任務進行中的Checkpoint數量。 | 個 | |
最近Checkpoint期間(lastCheckpointDuration) | 最近一個Checkpoint的期間 (lastCheckpointDuration) | 任務最近一個Checkpoint的期間。 如果Checkpoint耗時過長或者逾時,可能由於狀態過大、臨機操作網路原因、Barrier未對齊或者資料存在反壓等原因造成。 | 毫秒(ms) |
最近Checkpoint大小 (lastCheckpointSize) | 最近一個Checkpoint的大小 (lastCheckpointSize) | 任務最近一次實際上傳的Checkpoint大小,可以在Checkpoint有瓶頸時協助分析Checkpoint效能。 | 位元組(Byte) |
IO
監控指標 | 含義 | 監控指標 | 描述 | 單位 |
每秒輸入位元組總數。 (numBytesIn PerSecond) | 可查看上遊流速的輸入情況,協助您觀察作業流量表現。 | 每秒本地讀取資料的位元組數 (numBytesInLocal PerSecond) | 每秒本地讀取資料的位元組數。 | 位元組(Byte) |
每秒遠端讀取資料的位元組數 (numBytesInRemote PerSecond) | 每秒遠端讀取資料的位元組數。 | 位元組(Byte) | ||
每秒本地讀取網路緩衝區資料的位元組數 (numBuffersIn Local PerSecond) | 每秒本地讀取網路緩衝區資料的位元組數。 | 位元組(Byte) | ||
每秒遠端讀取網路緩衝區的資料的位元組數 (numBuffersIn Remote PerSecond) | 每秒遠端讀取網路緩衝區的資料的位元組數。 | 位元組(Byte) | ||
每秒輸出位元組總數。 (numBytesOut PerSecond) | 可查看上遊吞吐輸出情況,協助您觀察作業流量表現。 | 每秒輸出位元組數 (numBytesOut PerSecond) | 每秒輸出位元組數。 | 位元組(Byte) |
每秒輸出網路緩衝區的資料的位元組數 (numBuffersOut PerSecond) | 每秒輸出網路緩衝區的資料的位元組數。 | 位元組(Byte) | ||
每個Subtask每秒收到和輸出的總資料量。 (Task numRecords I/O PerSecond) | 可根據該指標判斷作業是否存在I/O瓶頸並且通過速率判斷嚴重程度。 | 每秒接收的記錄數 (numRecordsIn PerSecond) | 每秒接收的記錄數。 | 個 |
每秒發出的記錄數 (numRecordsOut PerSecond) | 每秒發出的記錄數。 | 個 | ||
每個Subtask收到和輸出的總資料量。 (Task numRecords I/O) | 可根據該指標判斷作業是否存在I/O瓶頸。 | 接收的記錄總數 (numRecordsIn) | 接收的記錄總數。 | 個 |
發出的記錄總數 (numRecordsOut) | 發出的記錄總數。 | 個 |
watermark
監控指標 | 描述 | 單位 |
每個任務收到最近一個Watermark的時間 (Task InputWatermark) | 每個任務收到最近一個Watermark的時間,說明TM收到資料的延時情況。 | 毫秒(ms) |
cpu
監控指標 | 描述 | 單位 |
單個JM CPU使用率 (JM CPU Load) | 單個JM CPU使用率。如果該值長期大於100%,說明CPU很繁忙,負載很高。這可能會影響系統效能,導致系統卡頓、回應時間過長等問題。 | 個 |
單個TM CPU使用率 (TM CPU Load) | 單個TM CPU使用率。該值反映Flink對CPU時間片的佔用情況,1個Core的CPU用滿為100%,4個Core用滿為400%。如果該值長期大於100%則說明CPU很繁忙。如果負載很高,但CPU使用率卻比較低,可能因為頻繁的讀寫操作導致不可中斷睡眠狀態的進程過多。 | 個 |
memory
監控指標 | 細分類型 | 描述 | 單位 |
JM 堆記憶體 (JM Heap Memory) | JM 堆記憶體已使用量 (JM Heap Memory Used) | JM 堆記憶體已使用量。 | 位元組(Byte) |
JM 堆記憶體已申請量 (JM Heap Memory Committed) | JM 堆記憶體已申請量。 | 位元組(Byte) | |
JM 堆記憶體最大可用量 (JM Heap Memory Max) | JM 堆記憶體最大可用量。 | 位元組(Byte) | |
JM的非堆記憶體 (JM NonHeap Memory) | JM 堆外記憶體已使用量 (JM NonHeap Memory Used) | JM 堆外記憶體已使用量。 | 位元組(Byte) |
JM 堆外記憶體已申請量 (JM NonHeap Memory Committed) | JM 堆外記憶體已申請量。 | 位元組(Byte) | |
JM 堆外記憶體最大可用量 (JM NonHeap Memory Max) | JM 堆外記憶體最大可用量。 | 位元組(Byte) | |
TM 堆記憶體 (TM Heap Memory) | TM 堆記憶體已使用量 (TM Heap Memory Used) | TM 堆記憶體已使用量。 | 位元組(Byte) |
TM 堆記憶體已申請量 (TM Heap Memory Committed) | TM 堆記憶體已申請量。 | 位元組(Byte) | |
TM 堆記憶體最大可用量 (TM Heap Memory Max) | TM 堆記憶體最大可用量。 | 位元組(Byte) | |
TM 堆外記憶體 (TM NonHeap Memory) | TM 堆外記憶體已使用量 (TM NonHeap Memory Used) | TM 堆外記憶體已使用量。 | 位元組(Byte) |
TM 堆外記憶體已申請量 (TM NonHeap Memory Committed) | TM 堆外記憶體已申請量。 | 位元組(Byte) | |
TM 堆外記憶體最大可用量 (TM NonHeap Memory Max) | TM 堆外記憶體最大可用量。 | 位元組(Byte) |
JVM
監控指標 | 描述 | 單位 |
JM活躍線程總數 (JM Threads) | JM活躍線程總數。JM線程數過多時,會導致佔用過大的記憶體空間,從而降低作業穩定性。 | 個 |
TM活躍線程總數 (TM Threads) | TM活躍線程總數(按 TM 彙總,多個 TM 多條線)。 | 個 |
JM年輕代記憶體回收行程已耗用時間 (JM GC Time) | JM年輕代記憶體回收行程已耗用時間。長時間GC會導致佔用過大記憶體空間,從而影響作業效能。該指標協助您進行作業診斷,排查作業層級的故障原因。 | 毫秒(ms) |
TM年輕代記憶體回收行程已耗用時間 (TM GC Time) | TM年輕代記憶體回收行程已耗用時間。長時間GC會導致佔用過大記憶體空間,從而影響作業效能。該指標協助您進行作業診斷,排查作業層級的故障原因。 | 毫秒(ms) |
JM年輕代記憶體回收行程運行次數 (JM GC Count) | JM年輕代記憶體回收行程運行次數。GC次數過多會導致佔用過大記憶體空間,從而影響作業效能。該指標協助您進行作業診斷,排查作業層級的故障原因。 | 個 |
TM年輕代記憶體回收行程運行次數 (TM GC Count) | TM年輕代記憶體回收行程運行次數。GC次數過多會導致佔用過大記憶體空間,從而影響作業效能。該指標協助您進行作業診斷,排查作業Task層級的故障原因。 | 個 |
TM自JVM啟動以來已載入的類總數 (TM ClassLoader) | TM自JVM啟動以來已載入的類總數。JM所在的JVM建立後載入類的總數或卸載類的總數過大,會導致佔用過大記憶體空間,從而影響作業效能。 | 個 |
JM自JVM啟動以來已載入的類總數 (JM ClassLoader) | JM自JVM啟動以來已載入的類總數。JM所在的JVM建立後,載入類的總數或卸載類的總數過大,會導致佔用過大的記憶體空間,從而影響作業效能。 | 個 |