Dataphin中繼資料倉庫(簡稱:元倉),是統一管理Dataphin內部業務中繼資料和相應計算引擎中繼資料的資料倉儲,存在於Dataphin元倉租戶中(OPS租戶)的一個Dataphin專案空間中,由一系列的周期性Data Integration節點、SQL指令碼節點、Shell節點群組成。元倉初始化即配置Dataphin系統的計算引擎類型並初始化中繼資料的過程。本文將為您介紹如何使用Hadoop作為元倉計算引擎進行元倉初始化。
前提條件
以Hadoop作為元倉時,需開放中繼資料庫或提供Hive Metastore服務,用於擷取中繼資料。
背景資訊
Dataphin支援通過直連中繼資料庫或Hive Metastore Service服務方式擷取中繼資料。各方式擷取中繼資料優劣勢對比詳情如下:

中繼資料擷取方式 | 優勢與劣勢 |
直連中繼資料庫 | 高效能:直接連接底層的中繼資料庫,省去了中間的HMS服務環節,用戶端在擷取meta(中繼資料)時效能更好,同時能夠減少網路傳輸上的耗時。 更開放:通過HMS服務查詢metastore,只能使用metastoreclient提供的幾種方法進行查詢。而直接連接中繼資料庫後,可以自由使用SQL進行查詢。 |
Hive Metastore Service服務 | 更安全:可以為metastore開啟kerberos認證,用戶端需要進行kerberos認證才能讀取到metastore中的資料。 更靈活:用戶端僅感知到HMS服務,並不能感知到背景中繼資料庫。因此底層的原資料庫可以隨時進行切換,而對應的用戶端無需變更。 |
通過DLF方式擷取中繼資料的效能與通過Hive Metastore Service服務的方式相近。
使用限制
系統僅支援元倉租戶超級管理員或系統管理員角色的帳號初始化系統。
請妥善保管元倉租戶超級管理員或系統管理員的帳號和密碼。同時,元倉租戶超級管理員帳號登入系統後,請謹慎操作。
操作步驟
在Dataphin首頁的頂部功能表列,選擇管理中心 > 系統設定。
在左側導覽列中選擇系統營運 > 雲倉設定,在中繼資料部署設定精靈頁面仔細閱讀安裝說明後,單擊開始。
在選擇初始化引擎類型頁面,選擇Hadoop引擎類型。
重要若元倉已經初始化,則預設選擇上次初始化成功的元倉。當切換成不相容的計算引擎時,會導致治理功能不可用。
Hadoop類型引擎包括Aliyun E-MapReduce 3.X、Aliyun E-MapReduce 5.x、CDH 5.X、CDH 6.X、FusionInsight 8.X、亞信DP 5.3 Hadoop、Cloudera Data Platform 7.x計算引擎。Hadoop類型計算引擎參數配置相同,此處以Aliyun E-MapReduce 3.X為例。
叢集配置
說明OSS-HDFS叢集儲存僅在Aliyun E-MapReduce5.x Hadoop引擎類型時支援。
HDFS叢集儲存
參數
描述
NameNode
NameNode用於管理HDFS中的檔案系統名稱空間及外部客戶機的存取權限。
單擊新增。
在新增NameNode對話方塊,填寫NameNode的Hostname名稱以及連接埠號碼,單擊確定。
填寫後自動產生對應的格式,例如
host=hostname,webUiPort=50070,ipcPort=8020。
設定檔
上傳叢集設定檔,用於配置叢集參數。系統支援上傳core-site.xml、hdfs-site.xml等叢集設定檔。
若需使用HMS方式擷取中繼資料,設定檔中必需上傳hdfs-site.xml、hive-site.xml、core-site xmI 、hivemetastore-site.xml檔案。若計算引擎類型為FusionInsight 8.X和E-MapReduce5.x Hadoop,還需上傳hivemetastore-site.xml檔案。
History Log
配置叢集的日誌路徑。例如
tmp/hadoop-yarn/staging/history/done。認證方式
支援無認證和Kerberos認證方式。Kerberos是一種基於對稱金鑰技術的身份認證協議,常用於叢集各組件間的認證。開啟Kerberos能夠提升叢集的安全性。
如果您選擇開啟Kerberos認證,需配置以下參數:

Kerberos配置方式
KDC Server:需輸入KDC統一服務地址,輔助完成Kerberos認證。
krb5檔案配置:需要上傳Krb5檔案進行Kerberos認證。
HDFS配置
HDFS Keytab File:需上傳HDFS Keytab檔案。
HDFS Principal:輸入Kerberos認證的Principal名。例如
XXXX/hadoopclient@xxx.xxx。
OSS-HDFS叢集儲存(Aliyun E-MapReduce5.x Hadoop)
初始化引擎類型選擇為Aliyun E-MapReduce5.x Hadoop時,支援配置叢集儲存類型為OSS-HDFS。
參數
描述
叢集儲存
可以通過以下方式查看叢集儲存類型。
未建立叢集:可以通過E-MapReduce5.x Hadoop叢集建立頁面查看所建立的叢集儲存類型。如下圖所示:

已建立叢集:可以通過E-MapReduce5.x Hadoop叢集的詳情頁查看所建立的叢集儲存類型。如下圖所示:
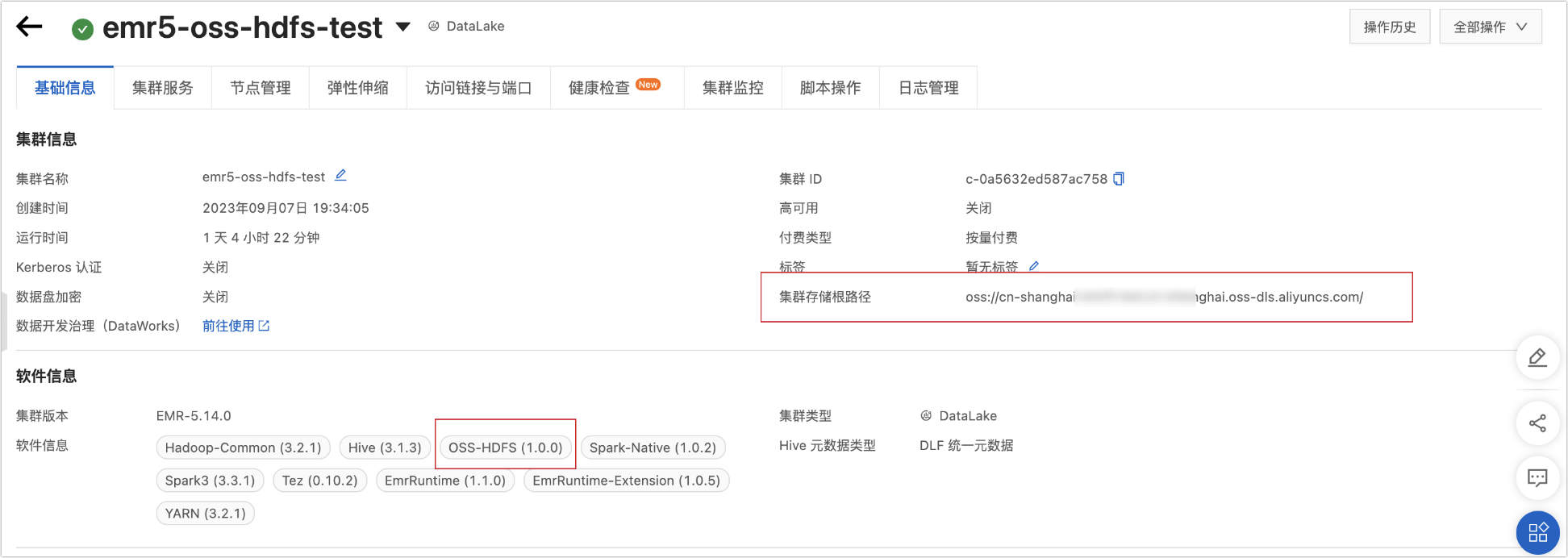
叢集儲存根目錄
填寫叢集儲存根目錄。可以通過查看E-MapReduce5.x Hadoop叢集資訊擷取進行。如下圖所示:
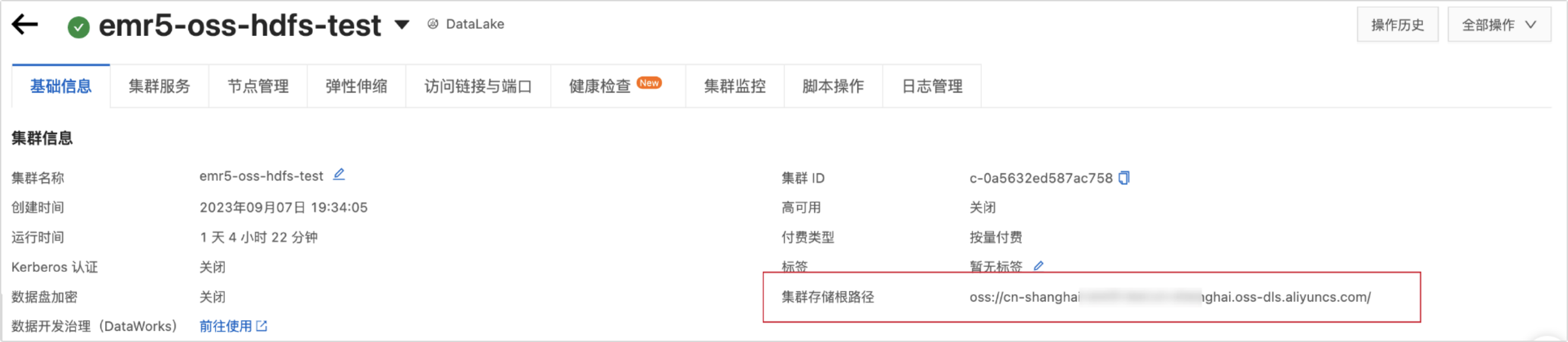 重要
重要若填寫的路徑中包括Endpoint,則Dataphin預設使用該Endpoint;若不包含,則使用core-site.xml中配置的Bucket層級的Endpoint;若未配置Bucket層級的Endpoint,則使用core-site.xml中的全域Endpoint。更多資訊請參見阿里雲OSS-HDFS服務(JindoFS 服務)Endpoint配置。
設定檔
上傳叢集設定檔,用於配置叢集參數。系統支援上傳core-site.xml、hive-site.xml等叢集設定檔。若需使用HMS方式擷取中繼資料,設定檔中必需上傳hive-site.xml、core-site.xml、hivemetastore-site.xml檔案。
History Log
配置叢集的日誌路徑。例如
tmp/hadoop-yarn/staging/history/done。AccessKey ID、AccessKey Secret
填寫訪問叢集OSS的AccessKey ID和AccessKey Secret。請使用已有AccessKey或者參考建立AccessKey重新建立。請注意:為降低AccessKey泄露的風險,AccessKey Secret只在建立時顯示一次,後續無法查看。請務必妥善保管。
重要此處填寫的配置優先順序高於core-site.xml中配置的AccessKey。
認證方式
支援無認證和Kerberos認證方式。Kerberos是一種基於對稱金鑰技術的身份認證協議,常用於叢集各組件間的認證。開啟Kerberos能夠提升叢集的安全性。如果您選擇開啟Kerberos認證,需要上傳Krb5檔案進行Kerberos認證。
Hive配置
參數
描述
JDBC URL
填寫串連Hive的JDBC URL。
認證方式
當叢集認證選擇無認證時,Hive的認證方式支援選擇無認證和LDAP。
當叢集認證選擇Kerberos時,Hive的認證方式支援選擇無認證、LDAP和Kerberos。
說明認證方式僅支援Aliyun E-MapReduce3.x、Aliyun E-MapReduce5.x、Cloudera Data Platform 7.x、亞信DP5.3、華為 FusionInsight 8.x。
使用者名稱、密碼
訪問Hive的使用者名稱和密碼。
無認證方式:需填寫使用者名稱;
LDAP認證方式:需填寫使用者名稱和密碼。
Kerberos認證方式:無需填寫。
Hive Keytab File
開啟Kerberos認證後需配置該參數。
上傳keytab檔案,您可以在Hive Server上擷取keytab檔案。
Hive Principal
開啟Kerberos認證後需配置該參數。
填寫Hive Keytab File檔案對應的Kerberos認證Principal名。例如
XXXX/hadoopclient@xxx.xxx。執行引擎
根據實際情況,選擇合適的執行引擎。各計算引擎所支援的執行引擎不同。支援情況如下:
Aliyun E-MapReduce 3.X:MapReduce、Spark。
Aliyun E-MapReduce 5.X:MapReduce、Tez。
CDH 5.X:MapReduce。
CDH 6.X:MapReduce、Spark、Tez。
FusionInsight 8.X:MapReduce。
亞信DP 5.3 Hadoop:MapReduce。
Cloudera Data Platform 7.x:Tez。
說明設定了執行引擎後,元倉租戶的計算設定、計算源、任務等都使用設定的Hive執行引擎。重新初始化後,計算設定、計算源、任務等將被初始化為新設定的執行引擎。
中繼資料擷取方式
中繼資料擷取方式支援中繼資料庫和HMS(Hive Metastore Serivce)、DLF三種方式擷取中繼資料。不同擷取方式所配置資訊不同。詳情如下:
中繼資料庫方式擷取
參數
描述
資料庫類型
選擇Hive的中繼資料庫類型。Dataphin支援選擇MySQL。
支援MySQL資料庫的版本包括MySQL 5.1.43、MYSQL 5.6/5.7和MySQL 8版本。
JDBC URL
填寫目標資料庫JDBC的串連地址。例如:
MySQL資料庫的串連地址格式為
jdbc:mysql://host:port/dbname使用者名稱、密碼
目標資料庫的使用者名稱和密碼。
HMS擷取方式
使用HMS方式擷取中繼資料庫,開啟Kerberos後,需上傳Keytab File檔案和填寫Principal。
參數
描述
Keytab File
Hive metastore的Kerberos認證的Keytabl檔案。
Principal
Hive metastore的Kerberos認證的Principal。
DLF擷取方式
重要DLF擷取方式僅支援Aliyun EMR5.x Hive 3.1.x版本。
參數
描述
Endpoint
填寫叢集在DLF資料中心所在地區的Endpoint。如何擷取,請參見DLF Region和Endpoint對照表。
AccessKey ID、AccessKey Secret
填寫叢集所在帳號的AccessKey ID和AccessKey Secret。請使用已有AccessKey或者參考建立AccessKey重新建立。請注意:為降低AccessKey泄露的風險,AccessKey Secret只在建立時顯示一次,後續無法查看。請務必妥善保管。
中繼資料生產專案
Meta Project:用於中繼資料生產,加工的邏輯專案空間。推薦配置為
dataphin_meta,重新初始化時請保持名稱不變,否則初始化失敗。
單擊測試連接。串連測試通過後,單擊下一步。
在初始化頁面,單擊開始。
說明初始化系統約15分鐘左右,請您耐心等待。
頁面提示執行成功後,單擊完成,即可完成配置。
後續步驟
完成系統的中繼資料初始化後,即可設定Dataphin執行個體的計算引擎。當元倉引擎設定為Hadoop時,業務租戶引擎可設定為除MaxCompute外的任意類型引擎,設定方法請參見計算設定。