離線物理表可協助您統一配置與管理計算任務開發過程中用到的離線物理表,提升開發效率。
使用限制
若您未購買資料標準模組,不支援設定表中的資料標準欄位。
若您未購買資產安全模組,不支援設定表中的資料分級、資料分類欄位。
僅支援MaxCompute、Hadoop、Lindorm、Databricks、GaussDB(DWS)、TDH 6.x、TDH 9.3.x、AnalyticDB for PostgreSQL計算引擎。
多引擎模式下,僅當專案綁定計算源的引擎類型為MaxCompute、Hadoop、AnalyticDB for PostgreSQL、GaussDB(DWS)、Databricks、Lindorm(計算引擎)、星環TDH 6.x、星環TDH 9.3.x時,支援表管理。
建立離線物理表
步驟一:配置基本資料
在Dataphin首頁的頂部功能表列選擇研發 > 資料研發。
在頂部功能表列選擇專案(Dev-Prod模式還需選擇環境)。
在左側導覽列選擇資料處理 > 表管理。
在表管理列表中單擊
 表徵圖,選擇離線物理表。
表徵圖,選擇離線物理表。在建立物理表設定精靈中,配置以下參數。不同類型的計算引擎,所需配置參數不同。
MaxCompute計算引擎
參數
描述
表名稱
輸入離線物理表的名稱,僅支援英文字母、數字和底線(_),不超過128個字元。
目錄
選擇離線物理表所存放的目錄。
若未建立目錄,您可以建立檔案夾,操作方法如下:
在頁面左側計算工作清單上方單擊
 表徵圖,開啟建立檔案夾對話方塊。
表徵圖,開啟建立檔案夾對話方塊。在建立檔案夾對話方塊中輸入檔案夾名稱,類型選擇為離線,並根據需要選擇目錄位置。
單擊確定。
主題域(非必選)
選擇表所歸屬的主題域。若無可選主題域,您可以進行建立。請參見建立主題域。
描述(非必填)
填寫簡單的描述,1000個字元以內。
Hadoop計算引擎
參數
描述
表名稱
輸入離線物理表的名稱,僅支援英文字母、數字和底線(_),不超過128個字元。
目錄
選擇離線物理表所存放的目錄。
若未建立目錄,您可以建立檔案夾,操作方法如下:
在頁面左側計算工作清單上方單擊
表徵圖,開啟建立檔案夾對話方塊。在建立檔案夾對話方塊中輸入檔案夾名稱,類型選擇為離線,並根據需要選擇目錄位置。
單擊確定。
主題域(非必選)
選擇表所歸屬的主題域。若無可選主題域,您可以進行建立,請參見建立主題域。
描述(非必填)
填寫簡單的描述,1000個字元以內。
儲存格式
選擇離線物理表的儲存格式,當前支援選擇以下格式。
hudi、delta(Delta Lake):若且唯若專案對應的計算源開啟了Spark SQL時,支援選擇;若當前專案對應的計算源未開啟Spark SQL,但研發平台-表管理設定中的預設儲存格式選擇為hudi或delta(Delta Lake),則此處儲存格式預設為引擎預設(建表語句中可另外指定)。
選擇hudi,建表語句中儲存格式子句為
using hudi;選擇delta(Delta Lake),建表語句中儲存格式子句為using delta。paimon
iceberg
parquet:建表語句中儲存格式子句為
stored as parquet。avro:建表語句中儲存格式子句為
stored as avro。rcfile:建表語句中儲存格式子句為
stored as rcfile。orc:建表語句中儲存格式子句為
stored as orc。textfile:建表語句中儲存格式子句為
stored as textfile。sequencefile:建表語句中儲存格式子句為
stored as sequencefile。
Lindom計算引擎
參數
描述
表名稱
輸入離線物理表的名稱,僅支援英文字母、數字和底線(_),不超過128個字元。
目錄
選擇離線物理表所存放的目錄。
若未建立目錄,您可以建立檔案夾,操作方法如下:
在頁面左側計算工作清單上方單擊
表徵圖,開啟建立檔案夾對話方塊。在建立檔案夾對話方塊中輸入檔案夾名稱,類型選擇為離線,並根據需要選擇目錄位置。
單擊確定。
主題域(非必選)
選擇表所歸屬的主題域。若無可選主題域,您可以進行建立。請參見建立主題域。
描述(非必填)
填寫簡單的描述,1000個字元以內。
儲存格式
選擇離線物理表的儲存格式,預設與研發平台-表管理設定中的預設儲存格式一致,當前支援選擇以下格式。
引擎預設(建表語句中可另外指定):建表語句無儲存格式設定語句(using或stored as)。
iceberg
parquet
avro
rcfile
orc
textfile
sequencefile
Databricks計算引擎
參數
描述
表名稱
輸入離線物理表的名稱,僅支援英文字母、數字和底線(_),不超過128個字元。
目錄
選擇離線物理表所存放的目錄。
若未建立目錄,您可以建立檔案夾,操作方法如下:
在頁面左側計算工作清單上方單擊
表徵圖,開啟建立檔案夾對話方塊。在建立檔案夾對話方塊中輸入檔案夾名稱,類型選擇為離線,並根據需要選擇目錄位置。
單擊確定。
主題域(非必選)
選擇表所歸屬的主題域。若無可選主題域,您可以進行建立。請參見建立主題域。
描述(非必填)
填寫簡單的描述,1000個字元以內。
儲存格式
選擇離線物理表的儲存格式,預設與研發平台-表管理設定中的預設儲存格式一致,當前支援選擇以下格式。
引擎預設(建表語句中可另外指定):建表語句無儲存格式設定語句(using或stored as)。
avro
binaryfile
csv
delta(Delta Lake)
json
orc
parquet
text
GaussDB(DWS)/AnalyticDB for PostgreSQL計算引擎
參數
描述
表名稱
輸入離線物理表的名稱,僅支援英文字母、數字和底線(_),不超過63個字元。
目錄
選擇離線物理表所存放的目錄。
若未建立目錄,您可以建立檔案夾,操作方法如下:
在頁面左側計算工作清單上方單擊
表徵圖,開啟建立檔案夾對話方塊。在建立檔案夾對話方塊中輸入檔案夾名稱,類型選擇為離線,並根據需要選擇目錄位置。
單擊確定。
主題域(非必選)
僅當專案所屬板塊已綁定業務板塊時,支援選擇主題域。
描述(非必填)
填寫簡單的描述,1000個字元以內。
配置完成後,單擊下一步。
步驟二:配置欄位列表
不同計算引擎支援的儲存格式不同,詳情請參見表管理設定。不同儲存格式欄位列表所支援的配置不同,詳見下表。
Databricks計算引擎下的離線物理表,當儲存格式為引擎預設(建表語句中可另外指定)時,欄位列表所支援的配置與儲存格式為delta(Delta Lake)時相同。
儲存格式為hudi、delta(Delta Lake)、iceberg或paimon
在欄位列表配置頁面配置當前物理表的表欄位、資料類型、資料分類等結構資訊。
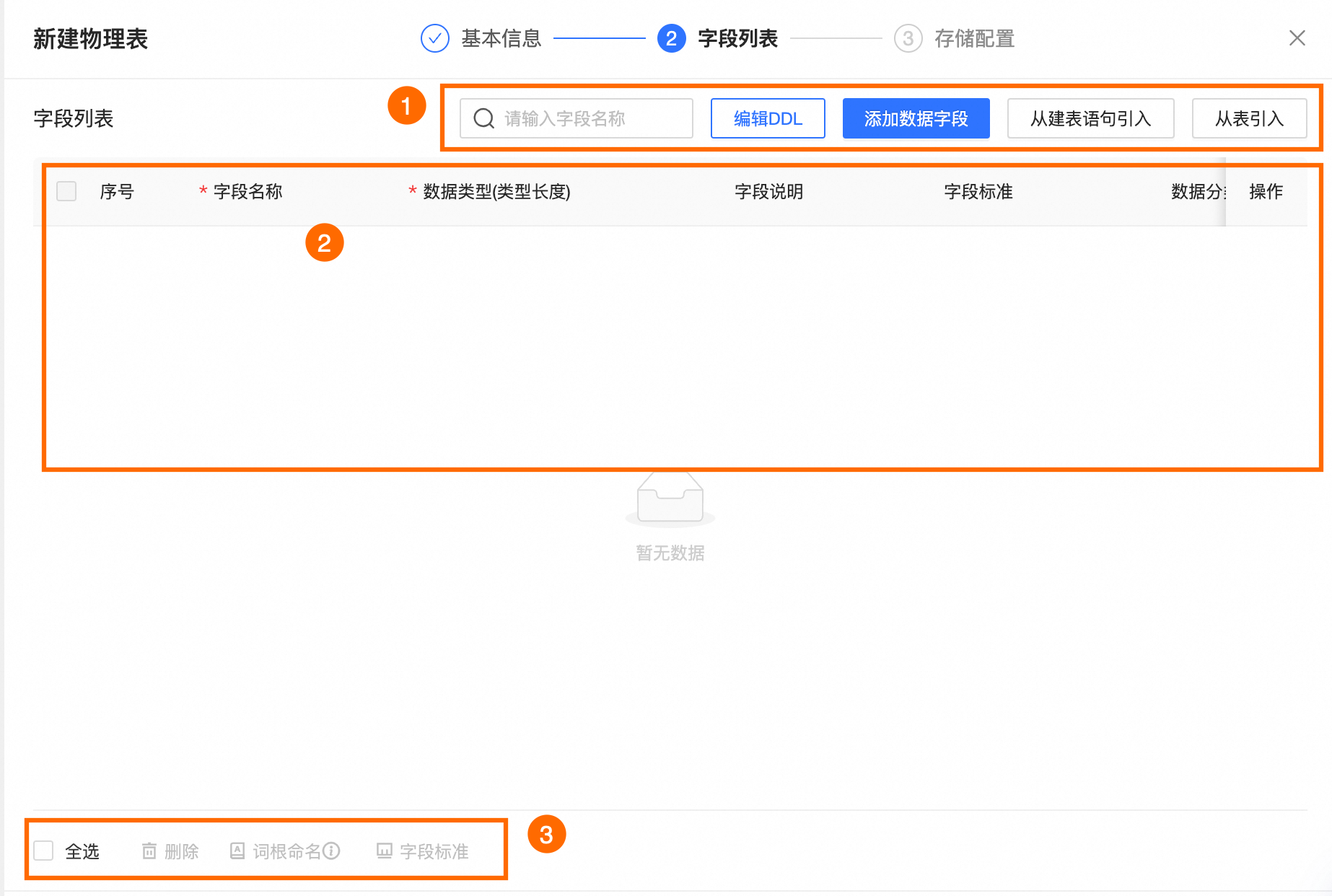
區塊
說明
①欄位列表操作
搜尋:您可以通過表欄位名稱搜尋所需欄位。
編輯DDL:編輯當前物理表的DDL語句。
添加資料欄位:單擊添加資料欄位,在新添加的欄位行中填寫欄位名稱、資料類型和欄位說明等資訊。
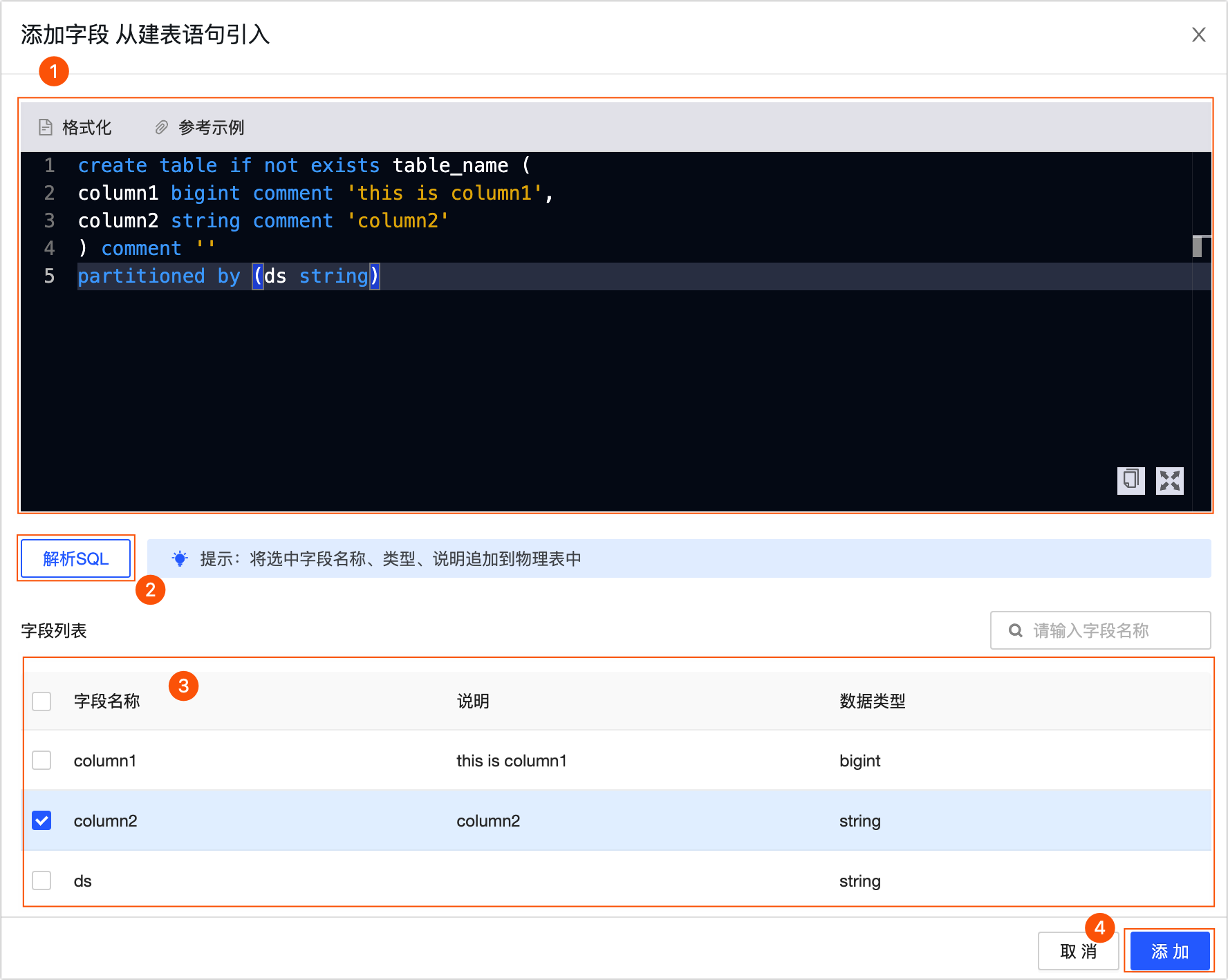
從建表語句引入:使用建表語句引入新欄位。單擊從建表語句引入,在從建表語句引入對話方塊中,按照下圖操作指引,輸入建表語句後單擊解析SQL,在解析出的欄位中選中所需引入的欄位,並單擊添加進行引入。
從表引入:單擊從表引入,在從表引入對話方塊中,選擇引入欄位所在的來源表並選中所需引入欄位,並單擊添加進行引入。
②欄位列表
欄位列表為您展示欄位的序號、欄位名稱、資料類型、欄位說明、欄位標準、資料分類、資料分級等欄位的詳細資料。
序號:表欄位序號。每新增1個欄位,按序遞增。
欄位名稱:表欄位名稱。您可輸入詞根的全稱進行搜尋,系統將自動匹配治理 > 資料標準 >詞根中配置的詞根。
資料類型:支援string、bigint、double、timestamp、decimal、文本、數值、日期時間及其他資料類型。
文本:varchar、char。
數值:int、smaIlint、tinyint、float。
日期時間:date。MaxCompute計算引擎支援datetime。
說明Hadoop計算引擎不支援datetime。
其他:boolean、binary。
欄位說明:表欄位說明資訊,512個字元以內。
欄位標準:選擇欄位的欄位標準。如需建立標準,請參見建立和管理資料標準。
資料分類:選擇欄位的資料分類。如需建立資料分類,請參見建立資料分類。
資料分級:選擇資料分類後,系統將自動識別資料層級。
同時您可以在操作列下對欄位進行刪除操作。
說明欄位刪除後不可撤銷。
③大量操作
您可以批量選擇表欄位,進行以下操作。
刪除:單擊
 表徵圖,大量刪除已經選中的資料欄位。
表徵圖,大量刪除已經選中的資料欄位。詞根命名:單擊
 表徵圖,系統將對欄位的說明內容進行分詞並匹配已經建立的詞根,進列欄位名稱推薦。您可以在詞根命名對話方塊中,將選中欄位的名稱替換為修改後的值。說明
表徵圖,系統將對欄位的說明內容進行分詞並匹配已經建立的詞根,進列欄位名稱推薦。您可以在詞根命名對話方塊中,將選中欄位的名稱替換為修改後的值。說明若推薦的欄位名稱均不滿足需求,您可以在修複後欄位名稱輸入框中進行修改。
單擊重設將重設修改後欄位名稱為系統的命中詞根。
欄位標準:單擊
 表徵圖,系統將根據欄位名稱進列欄位標準推薦。您可以在欄位標準對話方塊中,將欄位設定為推薦的欄位標準。
表徵圖,系統將根據欄位名稱進列欄位標準推薦。您可以在欄位標準對話方塊中,將欄位設定為推薦的欄位標準。
完成欄位添加後,單擊下一步。
非hudi、delta(Delta Lake)、iceberg或paimon儲存格式
在欄位列表配置頁面配置當前物理表的表欄位、資料類型、資料分類等結構資訊。
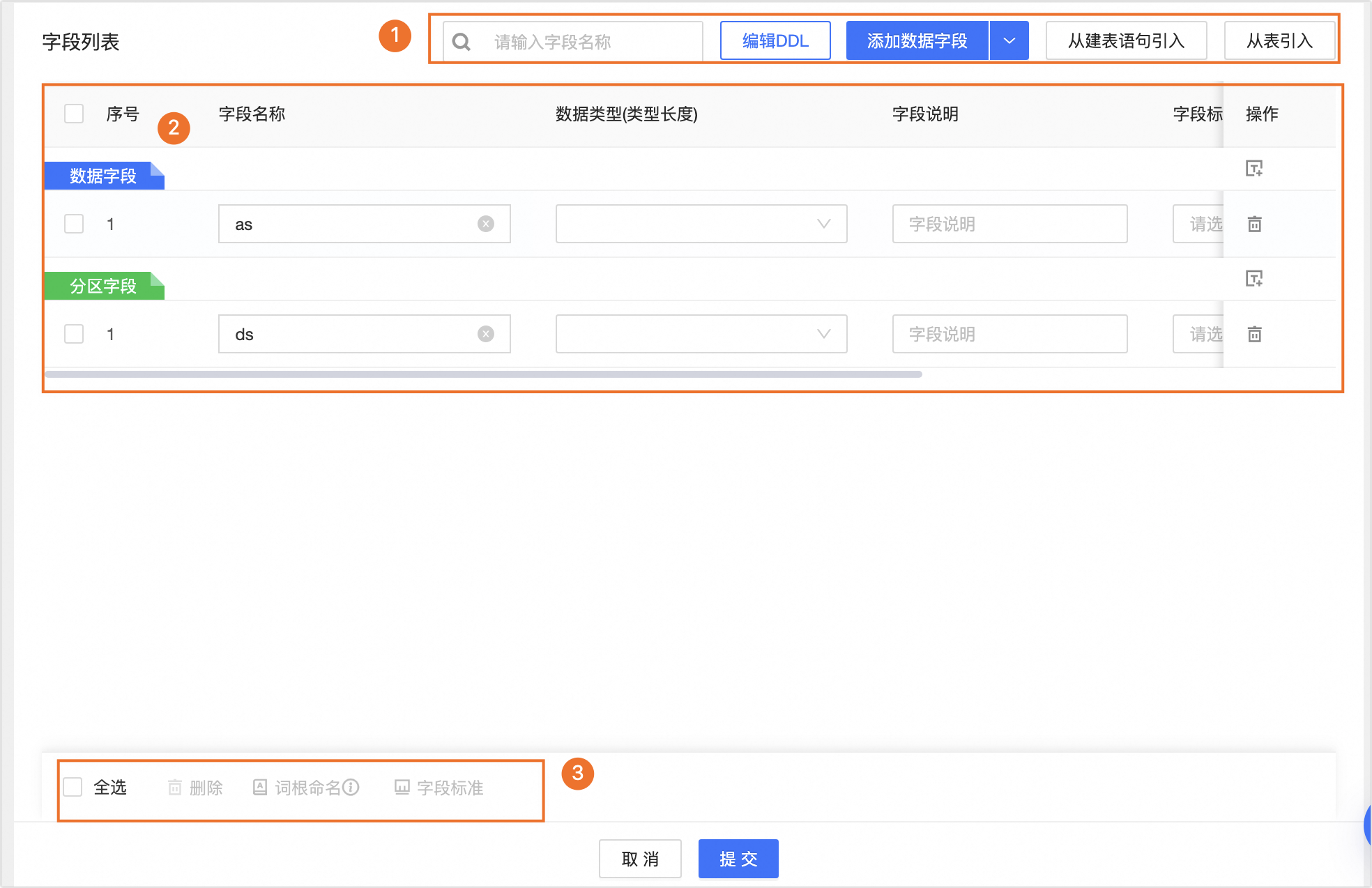
區塊
說明
①欄位列表操作
搜尋:您可以通過表欄位名稱搜尋所需欄位。
編輯DDL:編輯當前物理表的DDL語句。
添加資料欄位:單擊添加欄位,選擇資料欄位、分區欄位或快捷添加日期分區欄位類型,並在新添加的欄位行中填寫欄位名稱、資料類型和欄位說明等資訊。
添加資料欄位:單擊可在表欄位中添加一行資料欄位。
分區欄位:單擊可在表欄位中添加一行分區欄位。
快捷添加日期分區:單擊可在表欄位中添加一行日期分區。預設為
ds。
從建表語句引入:使用建表語句引入新欄位。單擊從建表語句引入,在從建表語句引入對話方塊中,按照下圖操作指引,輸入建表語句後單擊解析SQL,在解析出的欄位中選中所需引入的欄位,並單擊添加進行引入。
從表引入:單擊從表引入,在從表引入對話方塊中,選擇引入欄位所在的來源表並選中所需引入欄位,並單擊添加進行引入。
②欄位列表
欄位列表為您展示欄位的序號、欄位名稱、資料類型、欄位說明、欄位標準、資料分類、資料分級等欄位的詳細資料。
序號:表欄位序號。每新增1個欄位,自增+1。
欄位名稱:表欄位名稱。您可輸入詞根的全稱進行搜尋,系統將自動匹配治理 > 資料標準 >詞根中配置的詞根。
資料類型:支援string、bigint、double、timestamp、decimal、文本、數值、日期時間及其他資料類型。
文本:varchar、char。
數值:int、smaIlint、tinyint、float。
日期時間:date。MaxCompute計算引擎支援datetime。
說明Hadoop計算引擎不支援datetime。
其他:boolean、binary。
欄位說明:表欄位說明資訊,512個字元以內。
欄位標準:選擇欄位的欄位標準。如需建立標準,請參見建立和管理資料標準。
資料分類:選擇欄位的資料分類。如需建立資料分類,請參見建立資料分類。
資料分級:選擇資料分類後,系統將自動識別資料層級。
同時您可以在操作列下對欄位進行刪除操作。
說明欄位刪除後不可撤銷。
③大量操作
您可以批量選擇表欄位,進行以下操作。
刪除:單擊
表徵圖,大量刪除已經選中的資料欄位。詞根命名:單擊
表徵圖,系統將對欄位的說明內容進行分詞並匹配已經建立的詞根,進列欄位名稱推薦。您可以在詞根命名對話方塊中,將選中欄位的名稱替換為修改後的值。說明若推薦的欄位名稱均不滿足需求,您可以在修複後欄位名稱輸入框中進行修改。
單擊重設將重設修改後欄位名稱為系統的命中詞根。
欄位標準:單擊
表徵圖,系統將根據欄位名稱進列欄位標準推薦。您可以在欄位標準對話方塊中,將欄位設定為推薦的欄位標準。
完成欄位添加後,單擊下一步。
GaussDB(DWS)/AnalyticDB for PostgreSQL計算引擎
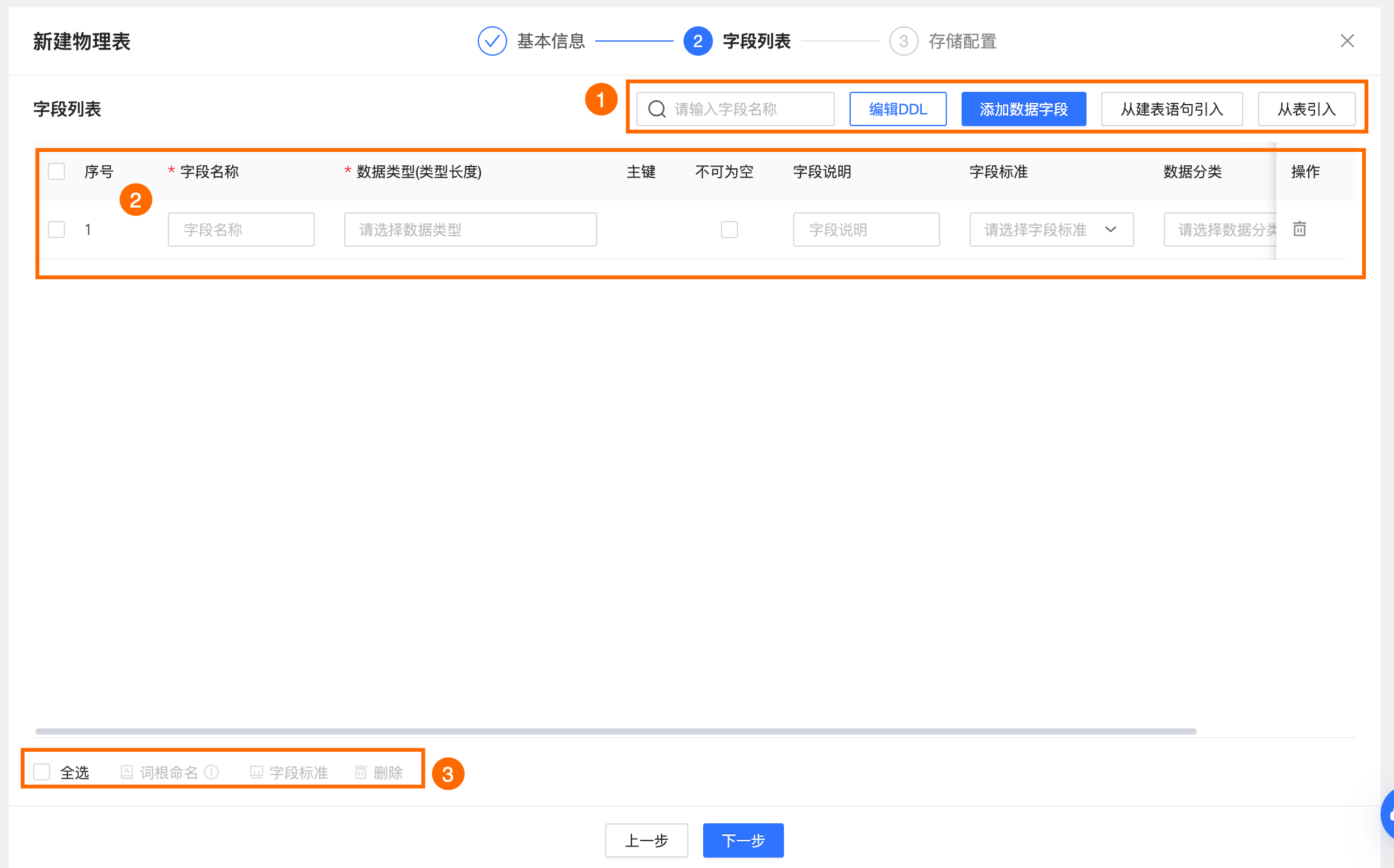
區塊 | 說明 |
①欄位列表操作 |
|
②欄位列表 | 欄位列表為您展示欄位的序號、欄位名稱、資料類型(類型長度)、主鍵、不可為空白、欄位說明、欄位標準、資料分類、資料分級等欄位的詳細資料。
同時您可以在操作列下對欄位進行刪除操作。 說明 欄位刪除後不可撤銷。 |
③大量操作 | 您可以批量選擇表欄位,進行以下操作。
|
步驟三:儲存配置
MaxCompute計算引擎、Hadoop計算引擎下不同儲存格式儲存配置所支援的配置不同,詳見下表。
儲存格式為hudi
參數 | 描述 |
資料更新類型(非必選) | 選擇type,可選擇cow(Copy on Write)或mor(Merge on Read)。 |
主鍵與合并排序鍵(非必選) |
|
資料分布 | 開啟或關閉Partition,預設為關閉。 開啟Partition後,還需選擇Partitioned By,可選擇欄位列表中的一個或多個欄位。 說明 Partitioned By不支援將所有欄位作為分區欄位,即列表中欄位不可全選。 |
儲存地址(非必填) | 輸入Location(儲存地址),支援使用全域變數,不超過512個字元。 說明 外部表格可省略external關鍵詞。若建表語句中包含location子句,則所建立的表為外部表格。 |
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
hudi編輯SQL的DDL語句可參見SQL DDL、Schema Evolution。
若Location(儲存地址)為空白,則建表語句中無location子句。
若當前計算引擎為Hadoop計算引擎,則使用Spark SQL;若當前計算引擎為Lindorm(計算引擎)或Databricks,則使用計算源預設SQL。
儲存格式為delta(Delta Lake)
參數 | 描述 |
資料分布 |
說明
|
儲存地址(非必填) | 輸入Location(儲存地址),支援使用全域變數,不超過512個字元。 說明 外部表格可省略external關鍵詞。若建表語句中包含location子句,則所建立的表為外部表格。 |
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
delta編輯SQL的DDL語句可參見AlTER TABLE。
若Location(儲存地址)為空白,則建表語句中無location子句。
若當前計算引擎為Hadoop計算引擎,則使用Spark SQL;若當前計算引擎為Lindorm(計算引擎)或Databricks,則使用計算源預設SQL。
儲存格式為iceberg
參數 | 描述 |
Partition | 預設關閉,開啟後需配置Partitioned By。 Partitioned By:可選擇多個欄位列表中的任意欄位,同時支援手動輸入欄位,多個欄位間使用半形逗號(,)分隔。 |
Location | 輸入Location(儲存地址),支援使用全域變數,不超過512個字元。 說明 外部表格可省略 |
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
若Location(儲存地址)為空白,則建表語句中無location子句。
若當前計算引擎為Hadoop計算引擎,則使用Spark SQL;若當前計算引擎為Lindorm(計算引擎),則使用計算源預設SQL。
儲存格式為paimon
參數 | 描述 |
Primary Key | 選擇一個或多個Primary Key(主鍵),選擇完成後還需配置Table Mode。 |
Table Mode | 選擇Table Mode(資料更新類型),可選擇MOR、COW或MOW。 |
Partition | 預設關閉,開啟後需配置Partitioned By。 Partitioned By:可選擇一個或多個欄位列表中的任意欄位。 |
Location | 輸入Location(儲存地址),支援使用全域變數,不超過512個字元。 說明 外部表格可省略 |
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
若Location(儲存地址)為空白,則建表語句中無location子句。
當前計算引擎為Hadoop計算引擎,則使用Spark SQL。
其他儲存格式
參數 | 描述 |
儲存類型 | 可選擇內部表或外部表格。若選擇外部表格,還需配置Location。 |
Location | 輸入Location(儲存地址),支援使用全域變數,不超過512個字元。 |
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
若當前計算引擎為Hadoop計算引擎,且儲存格式選擇為kudu,則使用Impala SQL。
MaxCompute計算引擎
MaxCompute內部表
參數
描述
儲存類型
選擇內部表。
是否事物表
選擇是或否,若選擇是,還可繼續配置Primary Key,將表建立為Delta表。
Primary Key(非必選)
選擇一個或多個主鍵,可選擇欄位列表中的所有欄位。若選擇多個主鍵,將按照選擇順序進行排序。
生命週期(非必填)
當前表的儲存時間。支援輸入正整數天,也可以快速選擇7、14、30或360天。
MaxCompute外部表格
參數
描述
儲存類型
選擇外部表格。
儲存格式
選擇儲存格式,預設與研發平台-表管理設定中的外部表格預設儲存格式一致。可選擇parquet、avro、rcfile、orc、textfile或sequencefile。
Location
輸入Location(儲存地址),支援使用全域變數,不超過512個字元。
參數配置完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
GaussDB(DWS)/AnalyticDB for PostgreSQL計算引擎
表級約束(Table Constraint):單擊新增約束,新增一行約束,需配置約束類型、約束設定和Deferrable策略。
參數
描述
約束類型
可選擇主鍵、唯一約束或Check約束。
約束設定
當約束類型選擇為主鍵時:可選擇一個或多個資料類型為text、character varying(varchar)、bigint (int8)、smallint(int2)、integer(int/int4)的欄位。
說明一個表僅支援設定一個主鍵約束。
如果已在欄位列表中選擇了主鍵,則系統將自動在表級約束添加主鍵約束,約束設定為欄位列表中的選中欄位。
當約束類型選擇為唯一約束時:可選擇一個或多個欄位,欄位列表中所有欄位均可選。
當約束類型選擇為Check約束時:可輸入任一字元,不超過512個字元。
Deferrable策略
可選擇not deferrable、initially immediate或initially deferred,預設為not deferrable。
說明當約束類型為Check約束時,不支援此參數。
單擊刪除表徵圖,可刪除對應行約束。
分布方式(Distributed By)(非必選):
AnalyticDB for PostgreSQL計算引擎:可選擇RANDOMLY、BY(<columns>)或REPLICATED。
GaussDB(DWS)計算引擎:可選擇REPLICATION、ROUNDROBIN或BY HASH(<columns>)。當選擇BY HASH(<columns>)時,還需選擇分布欄位,可選項中包含欄位列表中的所有欄位。
分區(Partition):單擊新增分區,新增一個分區欄位,根據分區類型配置不同參數。單擊刪除表徵圖,可刪除對應分區欄位(包含此分區中所有資料分區資訊)。
分區類型為LIST、RANGE時:
分區欄位:選擇分區欄位,或手動輸入運算式。
AnalyticDB for PostgreSQL計算引擎(資料庫版本6.x)僅支援單欄位分區;AnalyticDB for PostgreSQL計算引擎(資料庫版本7.x)、GaussDB(DWS)計算引擎支援輸入運算式。
分區名稱和分區值:單擊添加表徵圖,可添加一行資料分區;單擊刪除表徵圖,可刪除對應行的資料分區資訊。
說明計算引擎為AnalyticDB for PostgreSQL(資料庫版本6.x)時,系統將自動添加一行預設分區,預設分區的分區名稱為非必填。當預設分區的分區名稱為空白時,需添加至少一個資料分區。
計算引擎為GaussDB(DWS)時,需添加至少一個資料分區。
計算引擎為AnalyticDB for PostgreSQL(資料庫版本7.x)時,可不添加任何資料分區。
分區名稱:僅支援英文、數字和底線(_),長度不超過63個字元。
說明分區本身是一個表,完整分區表名格式預設為
{主表名稱}_{分區層級#}_prt_{分區名}。分區值:
當分區類型為LIST時:支援任一字元,長度不超過512個字元。當輸入的值為文本類型(例如,text、varchar、char)時,需加單引號('')。
當分區類型為RANGE時:需配置START、END、EVERY,可輸入任一字元,長度不超過512個字元。當輸入的值為文本類型(例如,text、varchar、char)時,需加單引號('')。
START和END還需選擇INCLUSIVE或EXCLUSIVE,START預設選擇INCLUSIVE;END預設選擇EXCLUSIVE。
說明分區值的有效性取決於分區欄位的類型。
分區類型為HASH:僅需配置分區欄位,無需配置資料分區。分區欄位配置說明同LIST和RANGE類型。
說明分布方式為REPLICATED的表,不支援分區。
當計算引擎為GaussDB(DWS)時,不支援多級分區。
僅當計算引擎為AnalyticDB for PostgreSQL(資料庫版本7.x)時,分區類型支援選擇HASH。
匯入資料
提交離線物理表後,您可匯入資料至離線物理表。
在表管理列表中單擊目標離線物理表,可輸入表名關鍵字搜尋。
在表詳情頁面,單擊匯入資料,開啟匯入資料對話方塊。
在匯入資料對話方塊的基礎配置步驟中上傳資料並配置匯入參數。
參數
描述
上傳檔案
單擊選擇檔案,上傳需匯入的資料檔案。僅支援.txt、.csv類型的檔案,檔案大小不超過10MB。
分隔字元
資料的分隔字元,支援逗號(,)、水平定位字元(\t)、豎線(|)、正斜線(/)。也可以輸入指定其他分隔字元。
字元集編碼
選擇上傳的資料檔案字元集編碼。支援解析utf-8(無BOM)、utf-8(有BOM)、gbk、big5、gb2312、ascii、utf-16字元集。
首行為標題
根據上傳的資料檔案選擇首行是否為標題。
目標資料分割
如果表為分區表,需輸入匯入資料的目標資料分割名稱。
單擊下一步。
在匯入資料步驟中,配置資料表欄位的映射關係。
映射關係:
同行映射:即按相同行數對應進行綁定為映射關係。
同名映射:即按相同名稱對應進行綁定為映射關係。
匯入檔案資料列:支援設定為資料列、空值NULL或固定值。
單擊開始匯入,即可將資料匯入到表中。
編輯離線物理表
提交離線物理表後,您可編輯物理表資料。
在表管理列表中單擊目標離線物理表,可輸入表名關鍵字搜尋。
在表詳情頁面,單擊編輯,開啟物理表編輯頁面。
不同類型的儲存格式,支援編輯的參數不同,詳見下表。
儲存格式為hudi
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯和刪除除hudi系統欄位外其他欄位的欄位名稱和欄位類型。hudi系統欄位包含:
_hoodie_commit_time
_hoodie_commit_seqno
_hoodie_record_key
_hoodie_partition_path
_hoodie_file_name
說明在修改欄位名稱、欄位類型或添加/刪除欄位時,根據不同引擎的設定,可能會因不支援而報錯。
儲存配置
僅支援編輯type、primaryKey、preCombineField和Location。其中僅噹噹前資料表為外部表格時,可編輯Location。
編輯完成後,單擊提交,提交時使用計算源預設SQL。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
說明對儲存格式為hudi的表(Hudi表)做重新命名欄位、刪除欄位、修改欄位類型等操作時,如果遇到引擎報錯,請聯絡引擎服務商檢查引擎設定。
儲存格式為delta(Delta Lake)
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯、刪除已有欄位,可添加新欄位。欄位填寫要求與建立離線物理表時一致。
儲存配置
資料分布
當Liquid Clustering開啟時,支援關閉或重新選擇Cluster By欄位。
當Liquid Clustering關閉,且Partition也關閉時,可開啟Liquid Clustering並指定Cluster By欄位。
當Liquid Clustering關閉,且Partition也關閉時,Partition不可開啟。
當Partition開啟時,Liquid Clustering、Partition和Partitioned By均不支援修改。
儲存地址:僅噹噹前資料表為外部表格時,支援編輯Location。
編輯完成後,單擊提交,提交時使用計算源預設SQL。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
儲存格式為iceberg
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯欄位名稱和欄位類型,同時支援新增和刪除欄位。
說明在修改欄位名稱、欄位類型或添加/刪除欄位時,根據不同引擎的設定,可能會因不支援而報錯。
儲存配置
僅噹噹前資料表為外部表格時,可編輯Location。
編輯完成後,單擊提交,若當前計算引擎為Hadoop計算引擎,則使用Spark SQL;若當前計算引擎為Lindorm(計算引擎),則使用計算源預設SQL。
在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
儲存格式為paimon
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯欄位名稱和欄位類型,同時支援新增和刪除欄位。
說明在修改欄位名稱、欄位類型或添加/刪除欄位時,根據不同引擎的設定,可能會因不支援而報錯。
儲存配置
僅噹噹前資料表為外部表格時,可編輯Location。
編輯完成後,單擊提交,提交時使用Spark SQL。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
MaxCompute計算引擎
MaxCompute內部表
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯、刪除已有欄位,可添加新欄位。欄位填寫要求與建立離線物理表時一致,當修改欄位類型時會產生DDL。
支援取消選中欄位的不可為空白選項。
若當前表為內部事務表,已設定為主鍵的欄位,不可取消選中且不可為空白。
僅支援對已選中不可為空白的欄位做取消選中不可為空白的操作。
儲存配置
支援編輯生命週期,填寫要求與建立離線物理表時一致。
MaxCompute外部表格
頁簽
描述
基本資料
僅支援編輯表名稱和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯、刪除已有欄位,可添加新欄位。欄位填寫要求與建立離線物理表時一致,當修改欄位類型時會產生DDL。
僅支援對已選中不可為空白的欄位做取消選中不可為空白的操作。
儲存配置
支援編輯儲存地址(Location),參數填寫要求與建立離線物理表時一致。
編輯完成後,單擊提交。在提交對話方塊中查看並確認當前建表的SQL語句,確認後單擊確定並提交。
說明如果變更中包含刪除欄位或修改欄位類型等操作,須先在MaxCompute側的專案級設定
setproject odps.schema.evolution.enable=true;。GaussDB(DWS)/AnalyticDB for PostgreSQL計算引擎
頁簽
描述
基本資料
僅支援編輯表名稱、主題域和描述,參數填寫要求與建立離線物理表時一致。
欄位列表
支援編輯、刪除已有欄位,可添加新欄位。欄位填寫要求與建立離線物理表時一致,當修改欄位類型時會產生DDL。
支援修改欄位的不可為空白選項。
不支援重新選擇主鍵,如有需要,您可通過編輯表級約束來修改主鍵。
儲存配置
支援編輯表級約束和分布方式,填寫要求與建立離線物理表時一致。分區資訊可前往資產清單 > 對象詳情 > 欄位
單租戶多引擎
使用從表引入方式配置欄位列表時,僅支援從引擎類型相同的專案引入表。
後續步驟
如果您的開發模式是Dev-Prod模式,則需要發布離線物理表。更多資訊,請參見管理髮布任務。
如果您的開發模式是Basic模式,提交成功後的離線物理表可在資產目錄進行管理。更多資訊,請參見。