Kafka輸出組件可以將外部資料庫中讀取資料寫入到Kafka,或從巨量資料平台對接的儲存系統中將資料複製推送至Kafka,進行資料整合和再加工。本文為您介紹如何配置Kafka輸出組件。
前提條件
已建立Kafka資料來源。具體操作,請參見建立Kafka資料來源。
進行Kafka輸出組件屬性配置的帳號,需具備該資料來源的同步讀許可權。如果沒有許可權,則需要申請資料來源許可權。具體操作,請參見申請資料來源許可權。
操作步驟
在Dataphin首頁頂部功能表列,選擇研發 > Data Integration。
在整合頁面頂部功能表列選擇專案(Dev-Prod模式需要選擇環境)。
在左側導覽列中單擊離線整合,在離線整合列表中單擊需要開發的離線管道,開啟該離線管道的配置頁面。
單擊頁面右上方的組件庫,開啟組件庫面板。
在組件庫面板左側導覽列中需選擇輸出,在右側的輸出組件列表中找到KAFKA組件,並拖動該組件至畫布。
單擊並拖動目標輸入、轉換或流程組件的
 表徵圖,將其串連至當前KAFKA輸出組件上。
表徵圖,將其串連至當前KAFKA輸出組件上。單擊Kafka輸出組件卡片中的
 表徵圖,開啟KAFKA輸出配置對話方塊。
表徵圖,開啟KAFKA輸出配置對話方塊。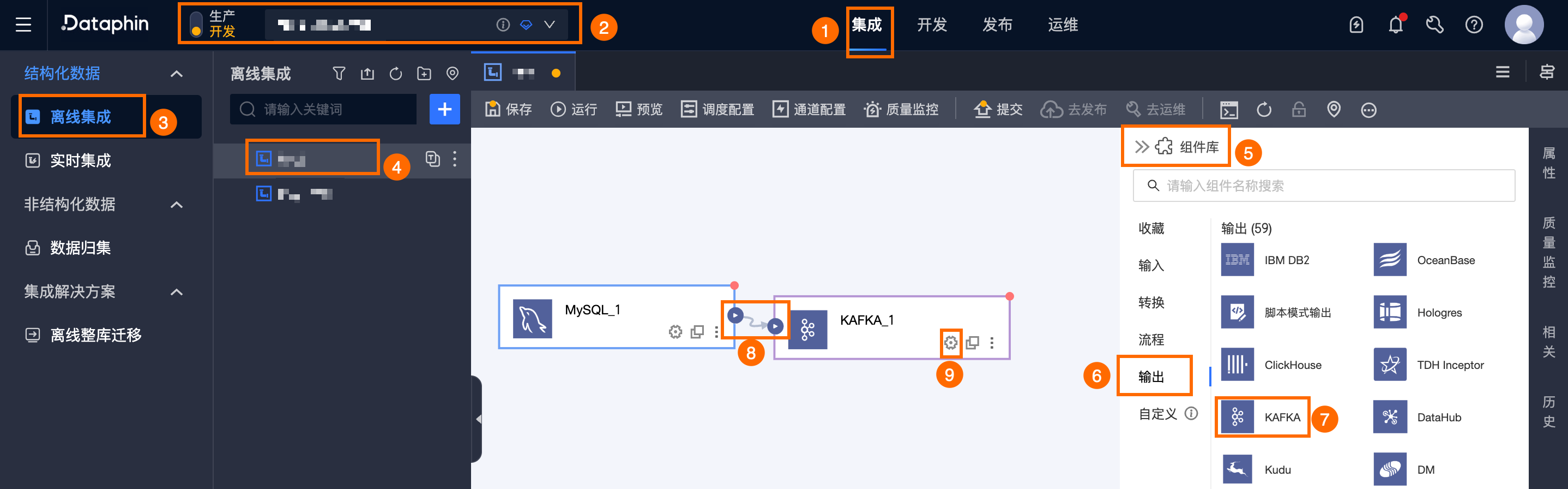
在KAFKA輸出配置對話方塊,按照下表配置參數。
參數
描述
基本設定
步驟名稱
即Kafka輸出組件的名稱。Dataphin自動產生步驟名稱,您也可以根據業務情境修改。命名規則如下:
只能包含中文、字母、底線(_)、數字。
不能超過64個字元。
資料來源
在資料來源下拉式清單中,展示所有Kafka類型的資料來源,包括您已擁有同步寫入權限的資料來源和沒有同步寫入權限的資料來源。單擊
 表徵圖,可複製當前資料來源名稱。
表徵圖,可複製當前資料來源名稱。對於沒有同步寫入權限的資料來源,您可以單擊資料來源後的申請,申請資料來源的同步寫入權限。具體操作,請參見申請、續期和交還資料來源許可權。
如果您還沒有Kafka類型的資料來源,單擊建立資料來源,建立資料來源。具體操作,請參見建立Kafka資料來源。
主題
根據實際情境,選擇需要的Topic。沒有匹配項時,也支援根據手動輸入的Topic名進行整合。 單擊
 表徵圖,可複製當前所選Topic的名稱。
表徵圖,可複製當前所選Topic的名稱。如果Kafka資料來源中沒有所需的Topic,您可以通過一鍵建Topic的功能,簡單快速的產生Topic。詳細操作步驟如下:
單擊一鍵建Topic,在一鍵建Topic對話方塊中配置以下參數。
Topic名稱:輸入Topic名稱,支援所有字元。
分區數:輸入大於等於1的整數,預設分區數為1。
副本數:輸入大於等於1的整數,預設副本數為2。
Topic參數(非必填):輸入Topic建立參數,格式為
key=value,多個參數間需換行分隔。生產環境建Topic:選中後,將同時在生產環境中建立Topic。如果生產環境已經有同名的Topic,則您無需選中生產環境建Topic。
單擊建立。
鍵取值列
填寫鍵取值列。
如果選擇多列,會將配置的所有列序號的值用逗號串連作為寫入Kafka記錄的Key。
如果不選擇,寫入Kafka記錄Key為null,資料輪流寫入topic的各個分區中。
寫入模式
該配置項決定將資料來源端讀取記錄的所有列拼接作為寫入Kafka記錄Value的格式,可選值為text和json,預設值為text。
text:將所有列按照分隔字元配置項指定分隔字元拼接。
json:將所有列按照目標表欄位名稱拼接為JSON字串。
說明如果配置了valueIndex,該配置項無效。
例如源端記錄有三列,值為a、b和c:
當寫入模式配置為text、分隔字元配置為#時,寫入Kafka的記錄Value為字串a#b#c。
當寫入模式配置為JSON、目標表欄位配置為["col1","col2","col3"]時,寫入Kafka的記錄Value為字串{"col1":"a","col2":"b","col3":"c"}。
值分隔字元
Value分隔字元配置。
當寫入模式為json時,不支援Value分隔字元配置。
當寫入模式為text時,支援配置單個或者多個字元作為分隔字元,支援以\u0001格式配置unicode字元,支援\t、\n等逸出字元。預設為\t(水平定位字元),支援Value分隔字元配置。
鍵類型和實值型別
選擇Kafka的Key和Value的類型。
當鍵取值列不選擇或選擇多列時,Key類型和Value類型可選項包含BYTEARRAY、STRING和KAFKA AVRO(資料來源配置了schema.registry時可選擇)。
當鍵取值列選擇一列時,Key類型和Value類型可選項包含BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG、SHORT、STRING和KAFKA AVRO(資料來源配置了schema.registry時可選擇)。
進階配置
按需進行配置,支援以下參數:
keyfieldDelimiter:鍵分隔字元,Kafka的鍵取值列為多列時的串連字元,預設為空白。
valueIndex:配置Kafka Writer中作為Value的列,例如valueIndex=[0,1,2,3] ,[ ]內的數字代表輸入組件的欄位的seqnumber
寫入模式為text時,預設將所有列拼起來作為Value,使用分隔字元配置的分隔字元進行分割,實值型別只能選擇BYTEARRAY或STRING。
寫入模式為JSON時,以索引值對寫入JSON。
partition=0:指定寫入Kafka topic指定分區的編號,是一個大於等於0的整數,預設為0。
nullKeyFormat=null:key指定的源端列值為null時,替換為該配置項指定的字串,如果不配置不做替換。
nullValueFormat=null:當源端列值為null時,組裝寫入kafka記錄Value時替換為該配置項指定的字串,如果不配置不做替換。
acks=all:初始化Kafka Producer時的acks配置,決定寫入成功的確認方式。值為0不進行寫入成功確認,值為1確認主副本寫入成功,值為all確認所有副本寫入成功。預設acks=all。
keySchema: 如topic配置了schema.regisrty, 請輸入key schema。預設為空白。
valueSchema: 如topic配置了schema.regisrty, 請輸入value schema。預設為空白。
欄位對應
輸入欄位
為您展示上遊組件的輸出欄位。
輸出欄位
為您展示輸出欄位。 Dataphin支援通過大量新增和建立輸出欄位的方式配置輸出欄位:
大量新增:單擊大量新增,支援JSON、TEXT格式大量設定。
以JSON格式大量設定,例如:
// 樣本: [{"name": "user_id","type": "String"}, {"name": "user_name","type": "String"}]說明name表示引入的欄位名稱,type表示引入後的欄位類型。 例如:
"name":"user_id","type":"String"表示把欄位名為user_id的欄位引入,設定欄位類型為String。以TEXT格式大量設定,例如:
// 樣本: user_id,String user_name,String行分隔字元用於分隔每個欄位的資訊,預設為分行符號(\n),可支援分行符號(\n)、分號(;)、點(.)。
資料行分隔符號用於分隔欄位名與欄位類型,預設英文逗號(,)。
建立輸出欄位。
單擊+建立輸出欄位,根據頁面提示填寫欄位及選擇類型。
複製上遊欄位。
單擊複製上遊欄位,系統將根據上遊的欄位名自動產生輸出欄位。
管理輸出欄位。
同時您也可以對已添加的欄位執行如下操作:
單擊操作列下的
 表徵圖,編輯已有的欄位。
表徵圖,編輯已有的欄位。單擊操作列下的
 表徵圖,刪除已有的欄位。
表徵圖,刪除已有的欄位。
映射關係
映射關係用於將源表的輸入欄位和目標表的輸出欄位對應起來,便於後續進行資料同步。映射關係包括同名映射和同行映射。適用情境說明如下:
同名映射:對欄位名稱相同的欄位進行映射。
同行映射:源表和目標表的欄位名稱不一致,但欄位對應行的資料需要映射。只映射同行的欄位。
單擊確認,完成Kafka輸出組件配置。