本文為您介紹資源調度的相關問題。
1、調度資源大盤無資料展示或展示時間未更新
需檢查是否已安裝Prometheus組件以及Prometheus是否串連正常。
若未安裝Prometheus組件,請聯絡Dataphin部署團隊。若已安裝Prometheus組件,但顯示的時間仍為舊時間段,這可能與Prometheus的串連異常有關。您可聯絡Dataphin營運團隊進行排查或通過以下方法判斷Prometheus是否串連異常:
登入Dataphin叢集。
使用
kubectl get pods -n dataphin | grep rs語句尋找rs Pod。使用
kubectl describe pod <pod名稱> -n dataphin語句尋找rs 主Pod。查看labels欄位
dataphin-rs-scheduler-rpc-service狀態是否為active。若狀態為active則為主Pod,若狀態為standby則為從Pod。使用
kubectl exec -it <pod名稱> -n dataphin -- bash語句登入rs主Pod。使用
cd/home/admin/logs/dataphin-rs語句進入rs日誌目錄。查看日誌資訊中,是否有涉及Prometheus串連異常的資訊,可使用
grep "failed to connect to" <記錄檔>語句搜尋。若包含Prometheus的資訊,則為串連異常。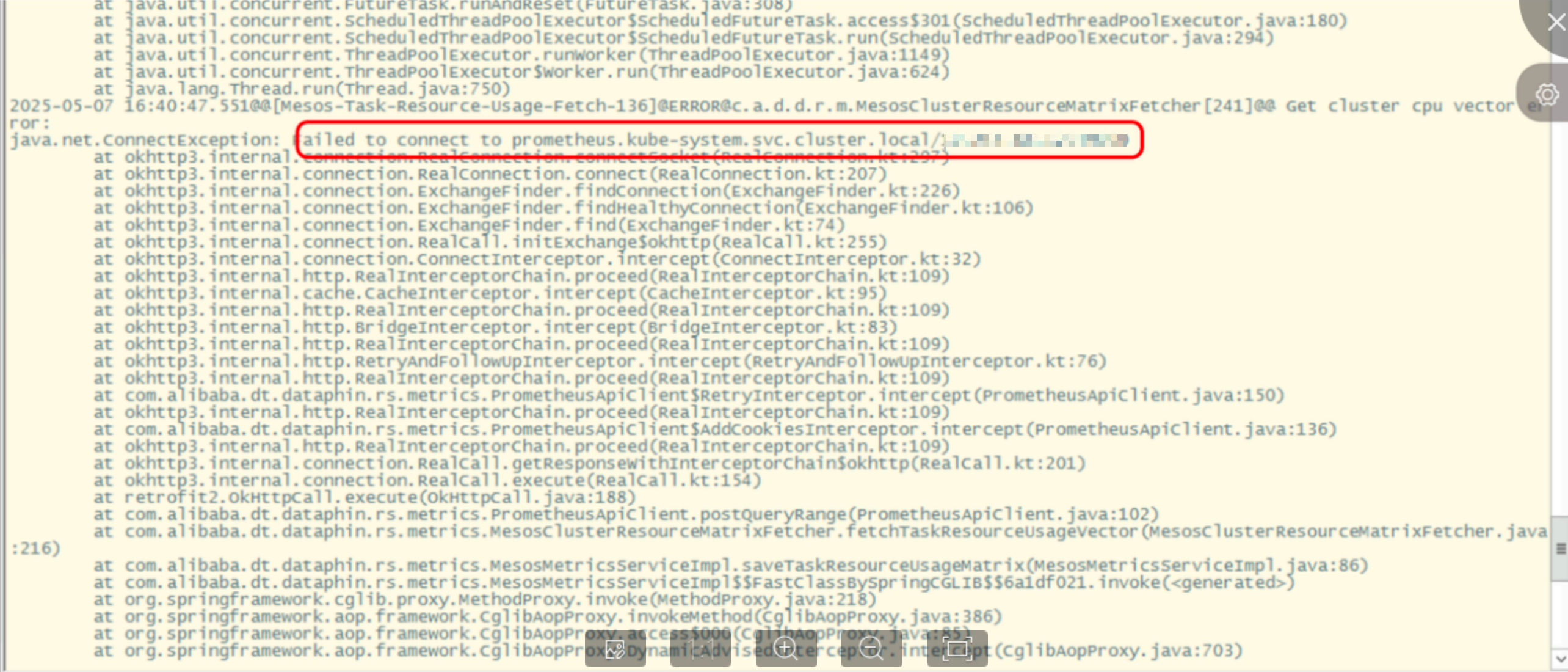
2、任務成功執行後被再次執行
需檢查該任務是否存在上遊依賴。若存在上遊依賴,上遊任務重跑後,將會觸發下遊任務重跑。
3、未展示資源設定頁面
匯入License後,才可查看管理中心 > 系統設定 > 資源設定頁面。
4、運行任務時提示資源等待
需依次確認以下情況:
當前資源群組是否有大量任務在運行。
是否存在許多已耗用時間較長的大型任務,這些任務持續運行將持續佔用資源群組的資源。
當前資源群組的設定是否合理。可前往管理中心 > 系統設定 > 資源設定,配置資源群組。
當前租戶資源的配置是否合理。當前租戶的資源值發生變化時,將聯動該租戶的資源群組進行相應調整。
例如,當作業記錄的最後提示內容類別似於Sending to agent e405****-****-****-****-****2fc2時,表明任務已經成功下發至調度叢集。但在調度叢集建立任務Pod時可能出現了問題,具體可能的原因如下:
調度叢集的剩餘資源不足,無法建立新的任務Pod。
調度叢集可能會出現故障,其中常見的問題包括網路外掛程式異常和時鐘異常。
4.1、租戶資源不足時的建議
終止資源群組中佔用資源優先順序較低的任務,釋放資源。
提高對應租戶資源群組的分配比例。
錯峰調度,避免在高峰期任務爭奪資源。
根據資源使用率最佳化任務的資源配置(可在資源大盤中查看任務資源使用率)。
4.2、叢集資源不足時的建議
終止資源群組中佔用資源優先順序較低的任務,釋放資源。
錯峰調度,避免在高峰期任務爭奪資源。
根據資源使用率最佳化任務的資源配置(可在資源大盤中查看任務資源使用率)。
叢集資源擴容。
5、運行共用任務時提示資源等待,但實際資源充足。
如果資源充足,但出現資源等待的情況,可能是由於共用任務的並發數限制所致。若超過設定的共用任務並發數量,任務將會被阻塞並進入等待狀態。
不同的共用類型任務,限制的並發數不同。
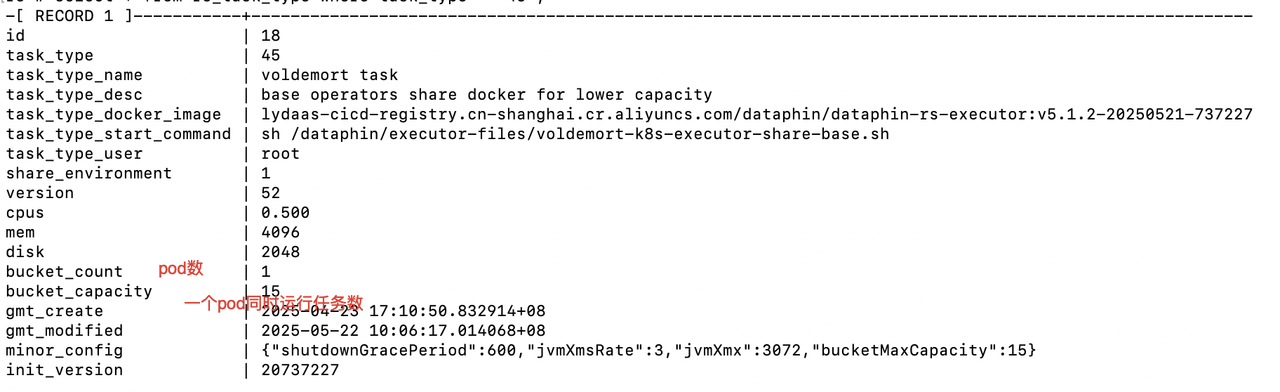
SQL類型預設值:預設建立⼀個共用容器Pod, ⼀個共用容器Pod可同時運⾏200個任務。
Python、Shell類型預設值:預設建立⼀個共用容器Pod,⼀個共用容器Pod可同時運⾏15個任務。
您可根據實際需求,改動共用容器Pod數和⼀個共用容器Pod同時運⾏任務數。
6、運行診斷中展示的佔用資源執行個體是當前資源下的還是當前租戶下的?
運行診斷中佔用資源執行個體為當前租戶下的執行個體。
7、已設定失敗自動重跑次數,但任務運行逾時後並未觸發自動重跑。
任務運⾏逾時預設不會觸發任務失敗⾃動重跑,任務逾時失敗⾃動重跑需要在營運 > 全域配置 > 運⾏配置 > 重跑配置中開啟對應開關。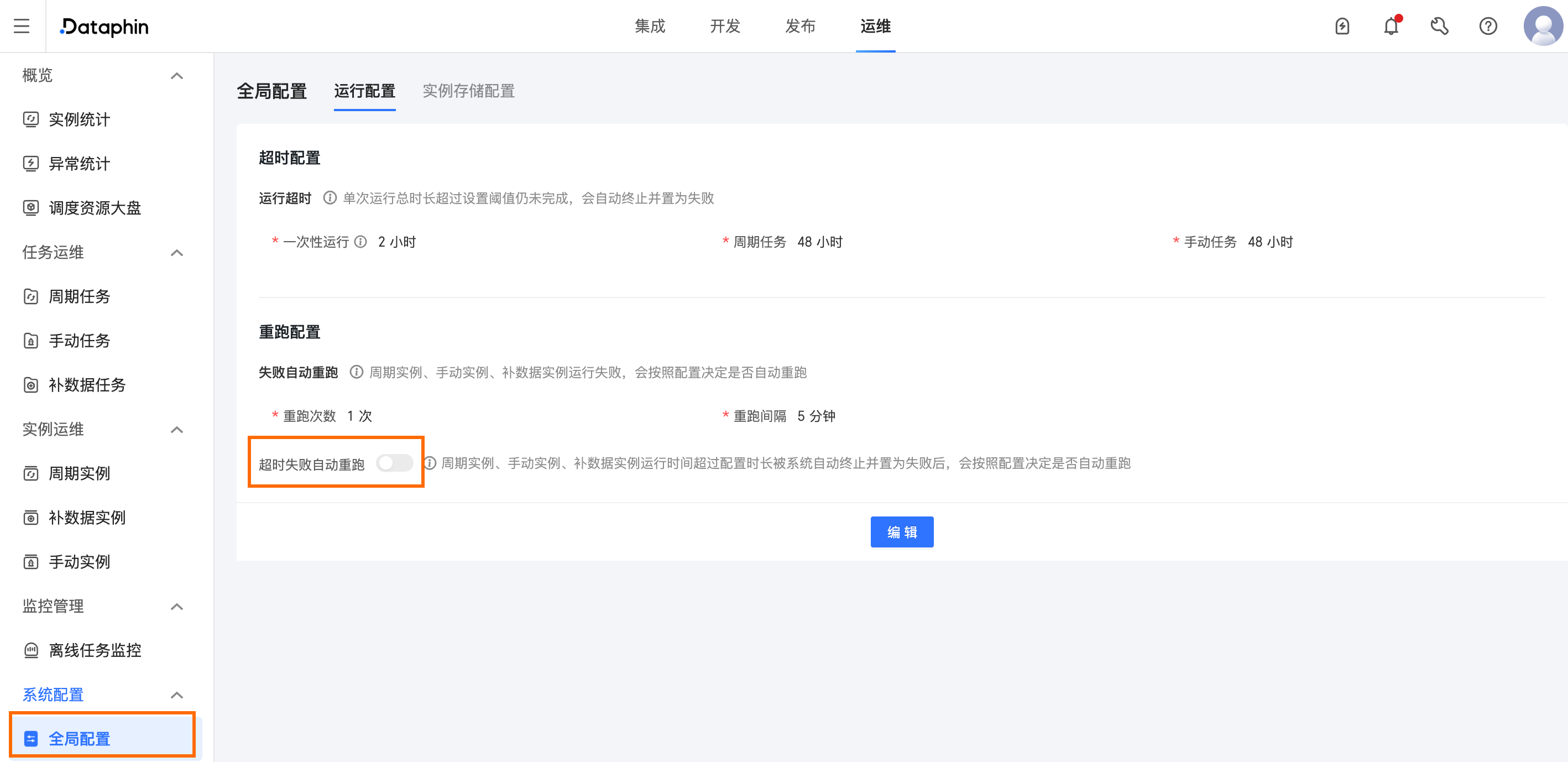
8、離線任務運行資源說明
離線任務運行資源詳細說明請參見任務運行資源說明。
例如,Python共用任務類型,啟動20個Pod,每個Pod處理50個任務,所需消耗的資源應按照以下方式計算。
一個Pod消耗的資源由基座資源和任務資源兩部分組成。其中,基座資源為0.5核和4096MB(4G);Python任務資源預設為0.1核和256MB。由此,一個Pod所需的總資源為0.6核和4352MB。若部署20個Pod,則所需資源為20 * 0.6核 = 12核,20 * 4352MB = 87040MB(85G)。
9、營運⻚⾯查詢執行個體列表資訊時,提示503 Service Temporarily Unavailable。
建議您優先排查是否被WAF(WAF是⼀種⽹絡安全⼯具,⽤於檢測和阻⽌惡意流量、SQL注⼊、XSS攻擊等)攔截。
10、作業記錄部分內容的時間戳記順序存在亂序現象
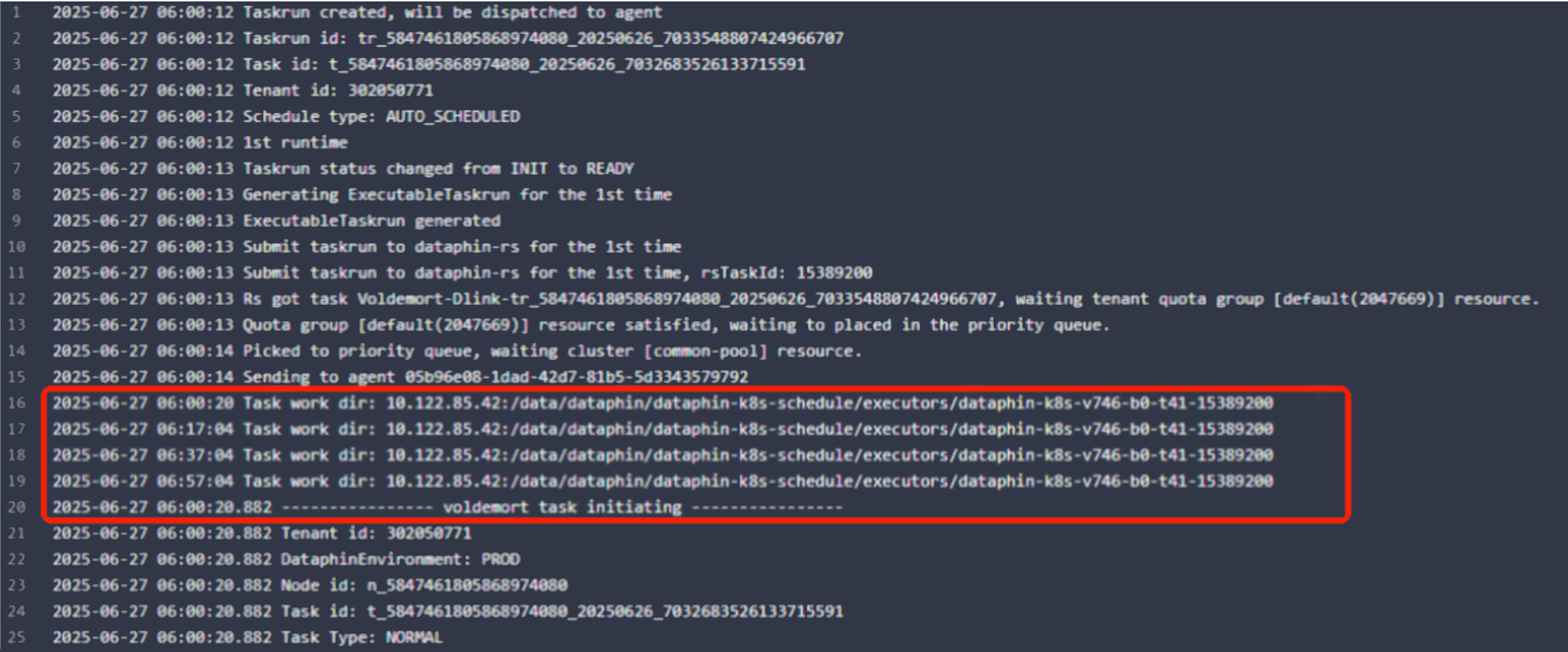
此處並非亂序,任務作業記錄是由三階段日誌拼接而成的。其中,中間部分為服務端定期詢問的日誌,三階段的日誌不會整體按照時間進行排序。
11、需要調⽤OpenAPI的觸發式節點,且使用Python開發,是否有對應的Python調⽤⽂檔?
目前僅部分介面(包含公用雲已上線以及營運相關的介面)支援使用Python開發。
相關文檔:
觸發式節點介紹:Dataphin v4.0,跨系統調度依賴再也不是難題
觸發式節點開發說明:觸發式節點開發說明
12、在代碼中指定的資源註解已被注釋,但在建議最佳化任務中仍然被納入統計。
被注釋的資源也會生效,徹底刪除資源後才不會被納入統計。
13、從低版本升級到高版本後,之前能夠正常啟動並執行OpenAPI介面運行報錯,提示tenantId不可為空。
若從低於Dataphin V3.0版本進⾏升級,則會提示該錯誤。從Dataphin V3.x版本開始,tenantId為必填。
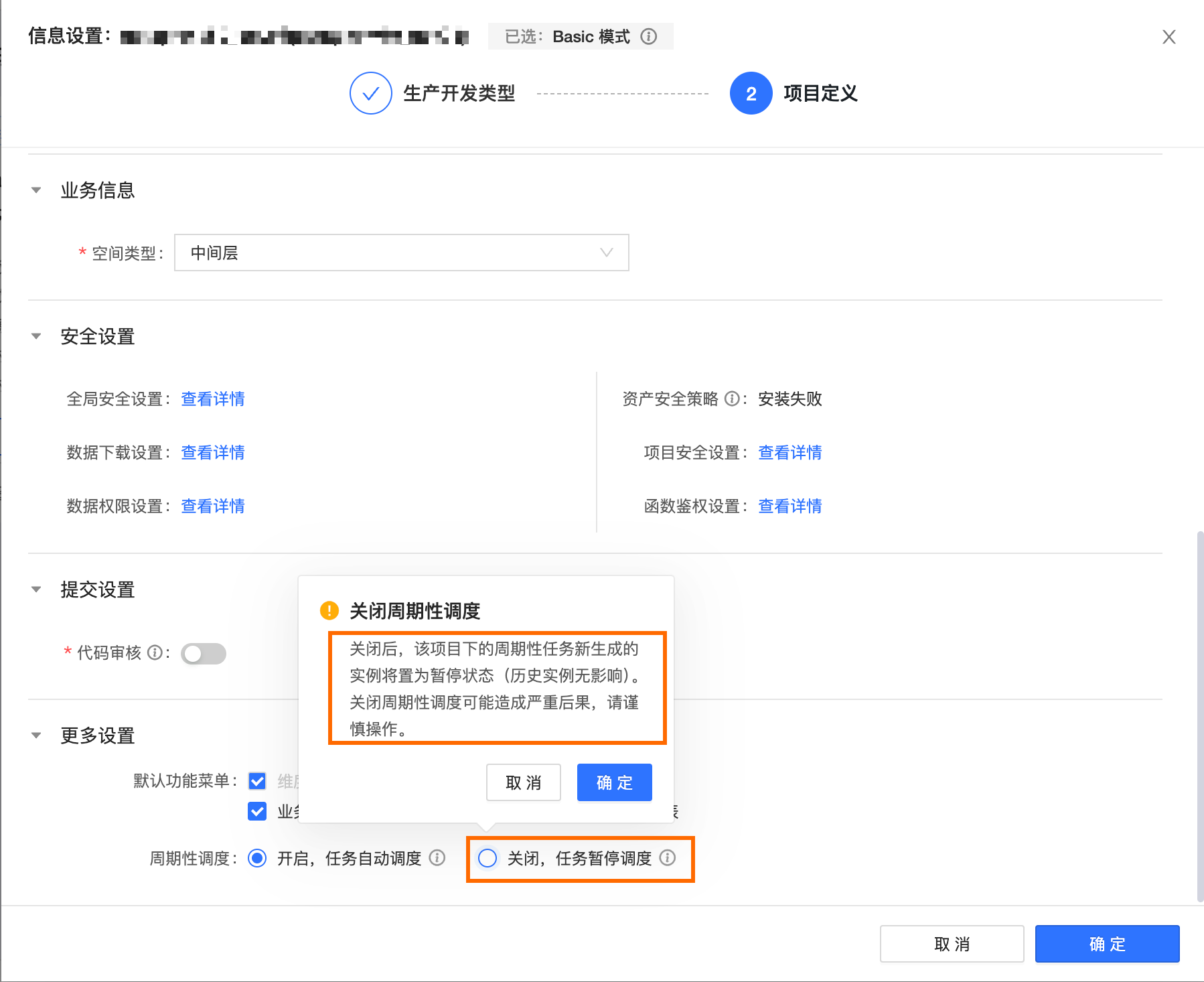
14、任務調度配置已設定為正常調度,但在營運的周期任務頁面中顯示為暫停狀態。
檢查該任務所屬專案的周期性調度是否選擇為已關閉,任務暫停調度,可改為選擇開啟,任務自動調度。