應用監控提供了基於指標的自訂警示配置,您可以通過預置的警示指標快速建立警示。另外,由於ARMS應用監控資料來源會預設整合至可觀測監控 Prometheus 版,您還可以使用Prometheus警示,通過PromQL陳述式完成更高階的自訂警示配置。本文會基於預置的警示指標提供一套常用的營運應急體系配置,並提供常用警示對應的PromQL語句。
前提條件
已接入應用監控,具體操作,請參見應用監控接入概述。
基礎警示
警示配置思路
為確保業務穩定運行,達成預期SLA目標,警示作為事中環節,對快速響應有很重要的意義。快速響應、快速定位需要有明確的分層定義,本文提供一套基礎的設計,從業務、應用到底層基礎進行了垂直的拆分。
本文提供的配置情境涉及以下警示指標,應用監控所有預置的警示指標請參見警示規則指標說明。
指標名稱 | 指標說明 |
調用次數 | 應用入口調用(包括調用HTTP入口、調用Dubbo入口等)的次數。可以根據該指標分析當前應用調用量的大小,從而判斷業務量的大小,以及通過調用量是否偏大或偏小判斷應用是否存在異常。 |
調用錯誤率(%) | 應用入口調用的調用錯誤次數總和/入口的調用次數總和*100%。 |
調用回應時間 | 應用入口調用(包括調用HTTP入口、調用Dubbo入口等)的回應時間。可以根據該指標判斷是否有慢請求出現,從而判斷應用是否存在異常。 |
異常發生次數 | 在軟體系統運行過程中發生的各種異常的次數,如null 指標異常、數組越界異常、IO異常等。可以根據該指標判斷呼叫堆疊是否拋錯,從而判斷是否存在應用調用異常。 |
HTTP介面狀態代碼5xx調用次數 | 用戶端向伺服器發送請求時,伺服器返回的標準響應狀態代碼為5xx的調用次數,例如伺服器內部錯誤、系統繁忙等,常見的5xx狀態代碼有500和503。 |
資料庫調用回應時間 | 從應用程式發送請求,到資料庫返迴響應結果的時間。調用資料庫回應時間的快慢直接影響應用程式的效能和使用者體驗。如果回應時間過長,使用者可能會感到應用程式卡頓或無響應,降低使用者滿意度。 |
應用依賴服務調用錯誤率(%) | 該應用依賴的下遊介面的錯誤次數除以總請求數,用於判斷下遊依賴服務報錯是否增多,進而影響當前應用。 |
應用依賴服務調用回應時間(單位:毫秒) | 該應用依賴的下遊介面的平均回應時間,用於判斷下遊依賴服務耗時是否增多,進而影響當前應用。 |
JVM FullGC次數(瞬時值) | 最近N分鐘JVM執行了Full GC(Full Garbage Collection)的次數。可以根據該指標判斷應用是否過於頻繁發生FullGC,從而判斷應用是否存在異常。 |
JVM可運行線程數 | JVM在運行時支援的最大線程數量。如果建立線程數量過多,會佔用大量的記憶體資源,導致系統變慢或者崩潰。 |
線程池使用率 | 線程池中正在使用的線程數與線程池匯流排程數之比,反映了當前線程池的使用方式。 |
節點機CPU使用率(%) | 節點機(伺服器)上CPU處理器的使用率,過高的CPU使用率會導致系統響應變慢、服務不可用等問題。 |
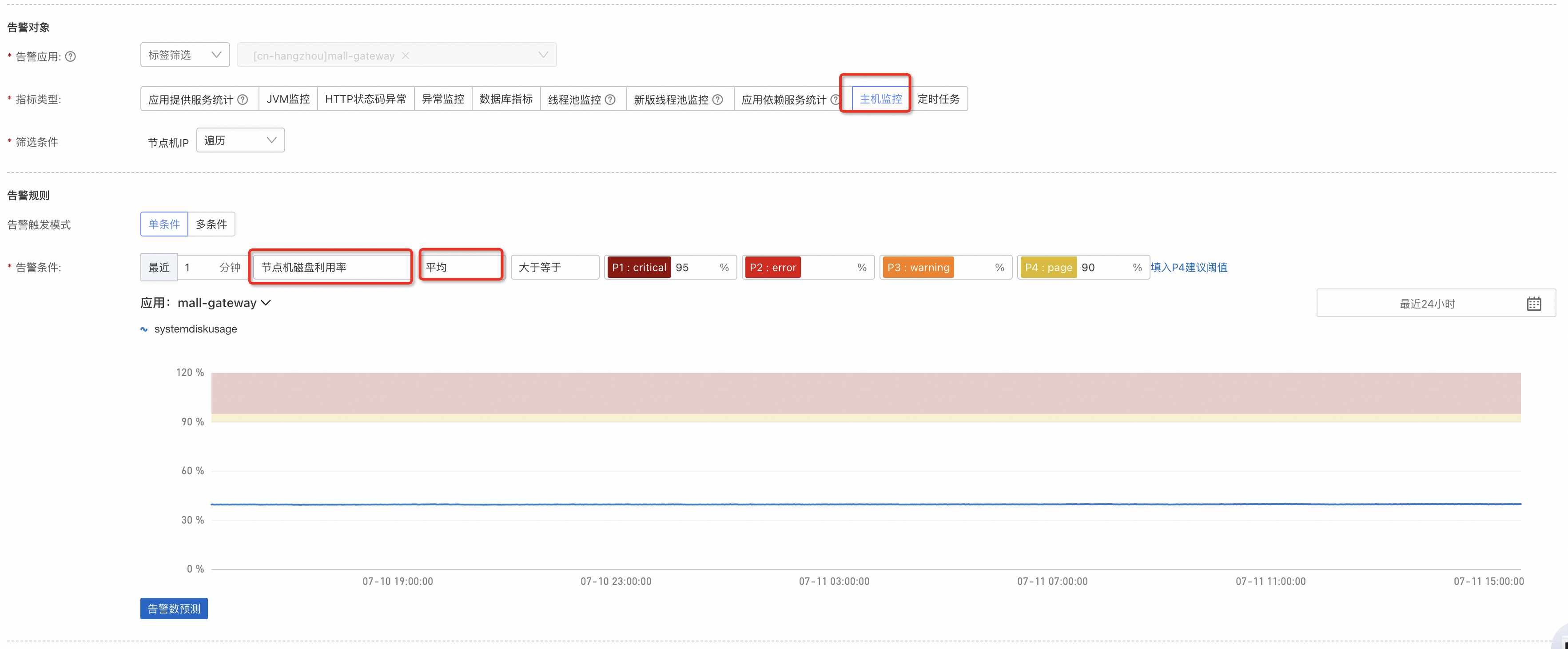
節點機磁碟利用率(%) | 節點機中硬碟的使用方式,即已使用的磁碟空間佔總磁碟空間的比例。磁碟利用率越高,表示節點機的儲存容量越緊張。 |
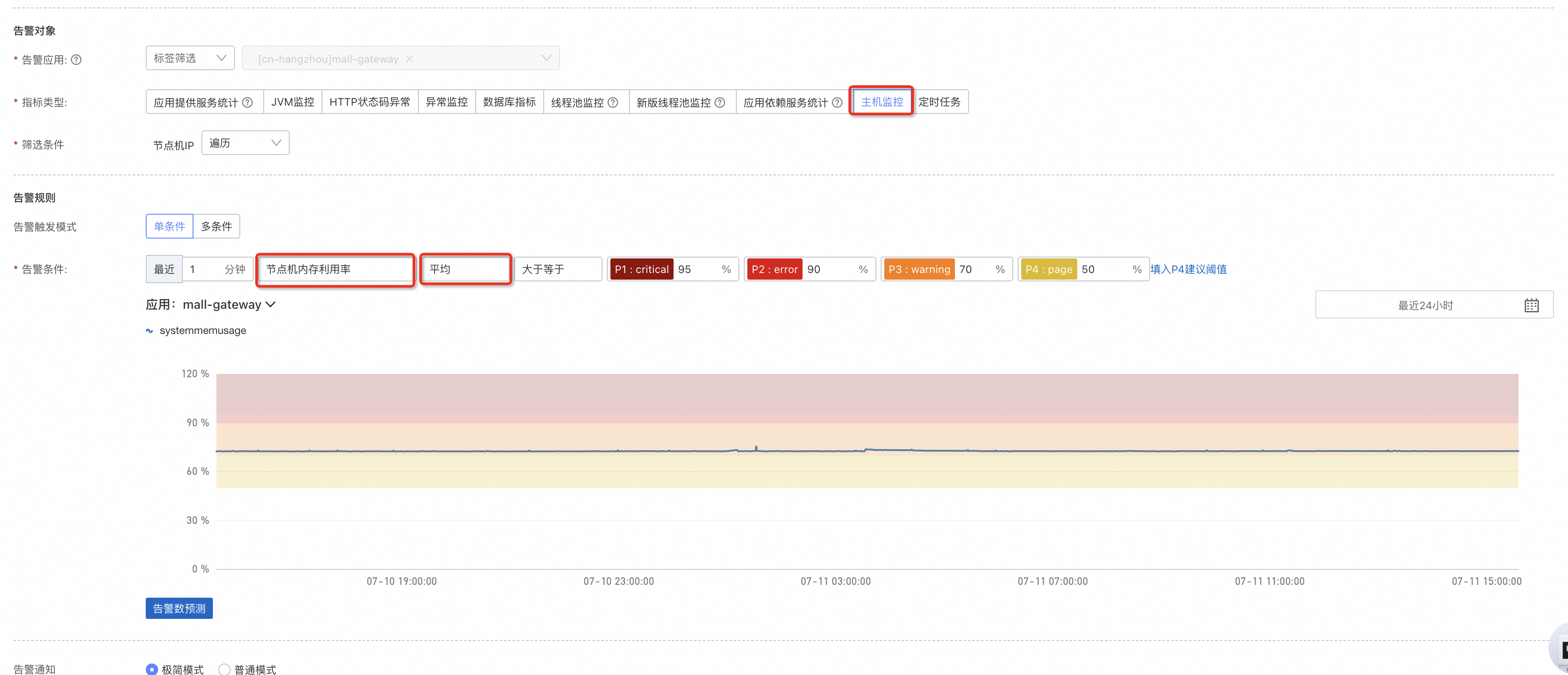
節點機記憶體利用率(%) | 當前節點機已經使用的記憶體佔總記憶體的比例。如果節點機的記憶體利用率超過了80%,就需要考慮調整節點機配置或者最佳化任務使用記憶體的方式來降低記憶體壓力。 |
業務
您可以選擇核心業務的介面作為警示的標準,例如電商業務可以配置下單介面作為警示的基準,遊戲業務可以選擇登入入口,具體可以根據實際情況選擇。
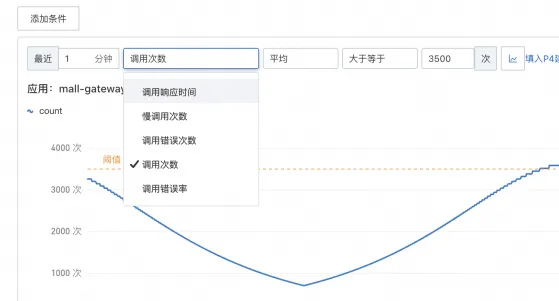
這裡以ARMS的電商Demo為例,選擇添加購物車介面。
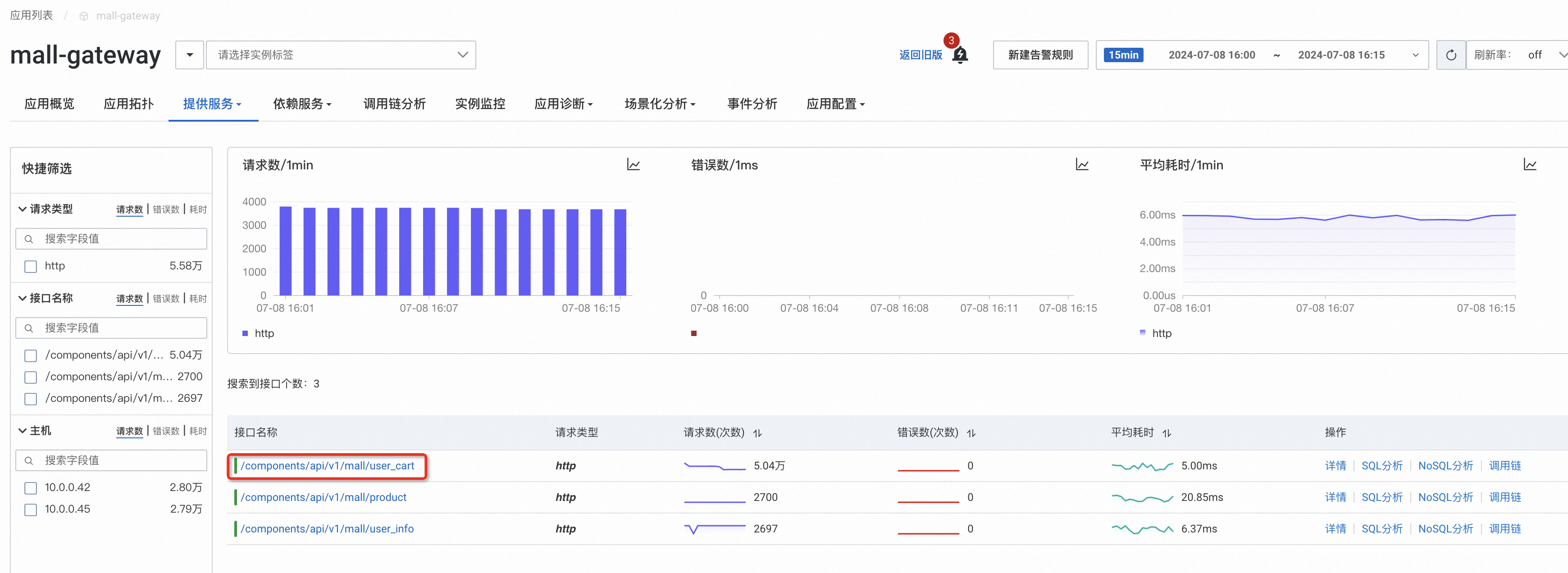
常用的警示指標為調用次數,業務受到影響時流量通常會下跌,突發流量上漲超過容量也會對業務造成影響。通過多條件可以設定業務量的上下邊界,當業務量大於或者小於預設值時進行警示。
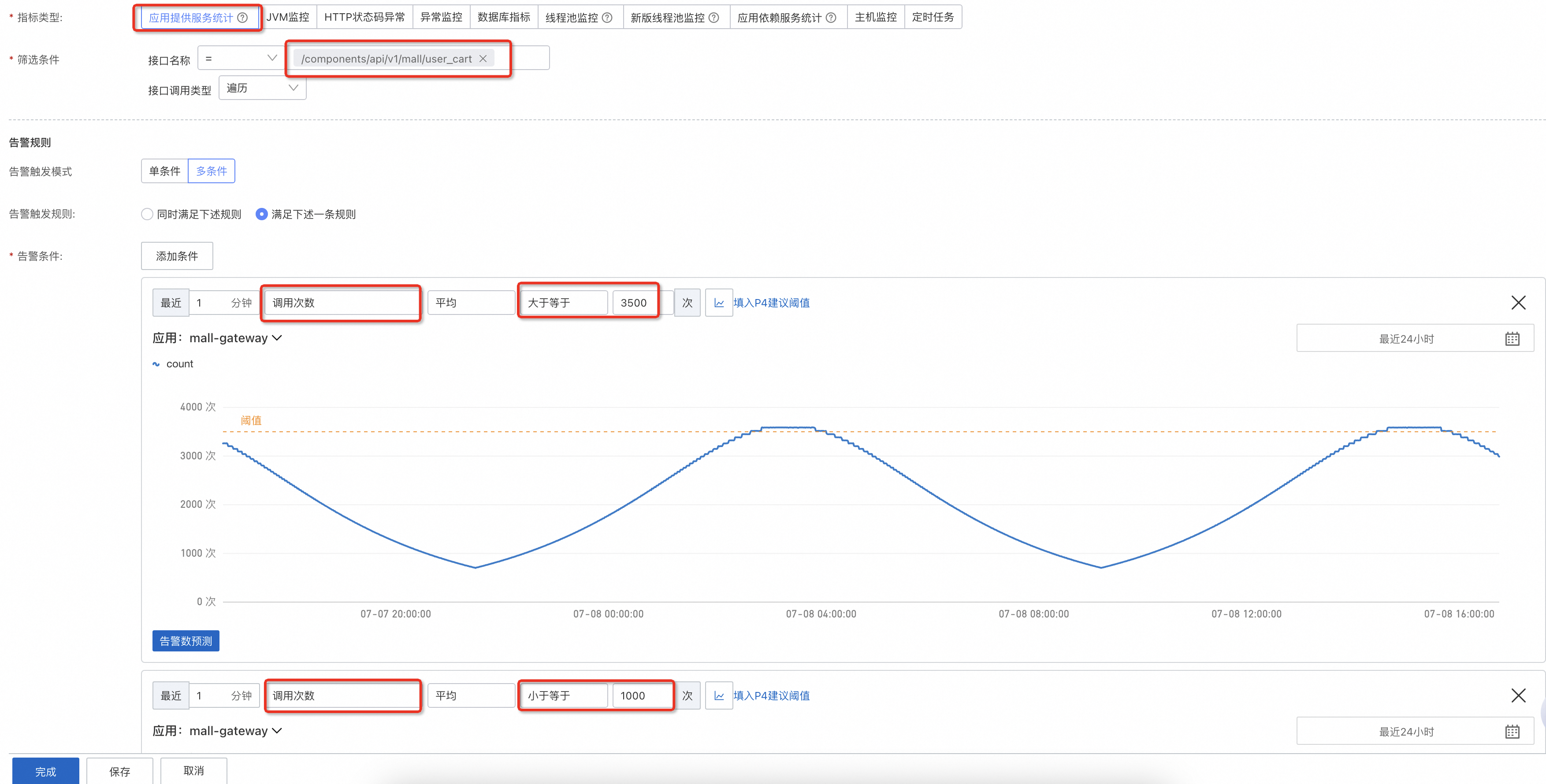
流量下跌推薦使用下限+下跌環比組合,業務在半夜時可能處於低穀期,僅設定一個下限就很容易觸發,應用出問題時流量往往會斷崖式下跌,因此可以增加一個環比作為補充。
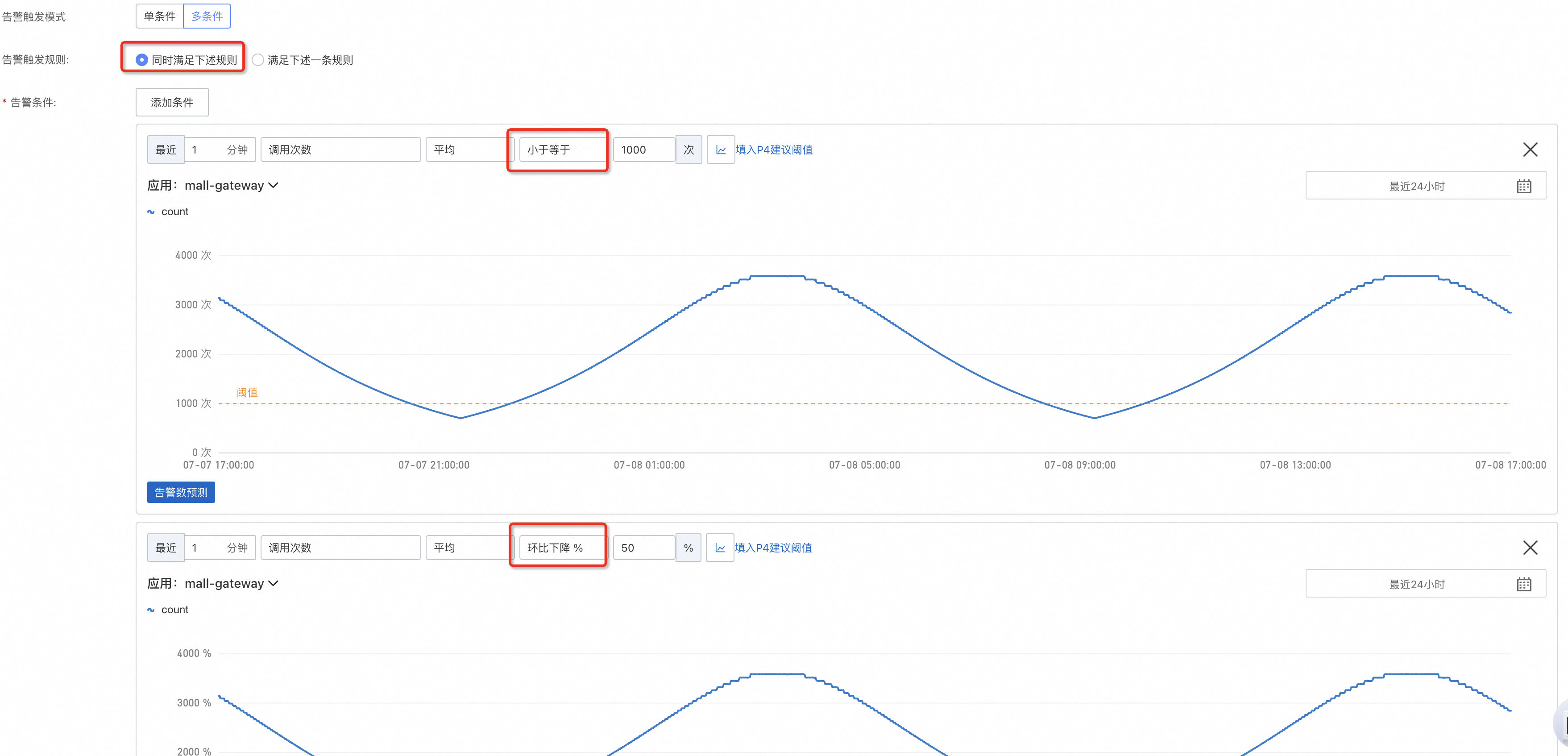
配置完流量,可以再補充下錯誤調用,對錯誤率設定警示上限。
此外,其他條件可以根據實際情況定製,例如對耗時敏感的可以使用回應時間或者慢調用次數指標。
應用
當業務受到影響時,依靠應用的各個指標可以快速定位或者輔助發現問題。
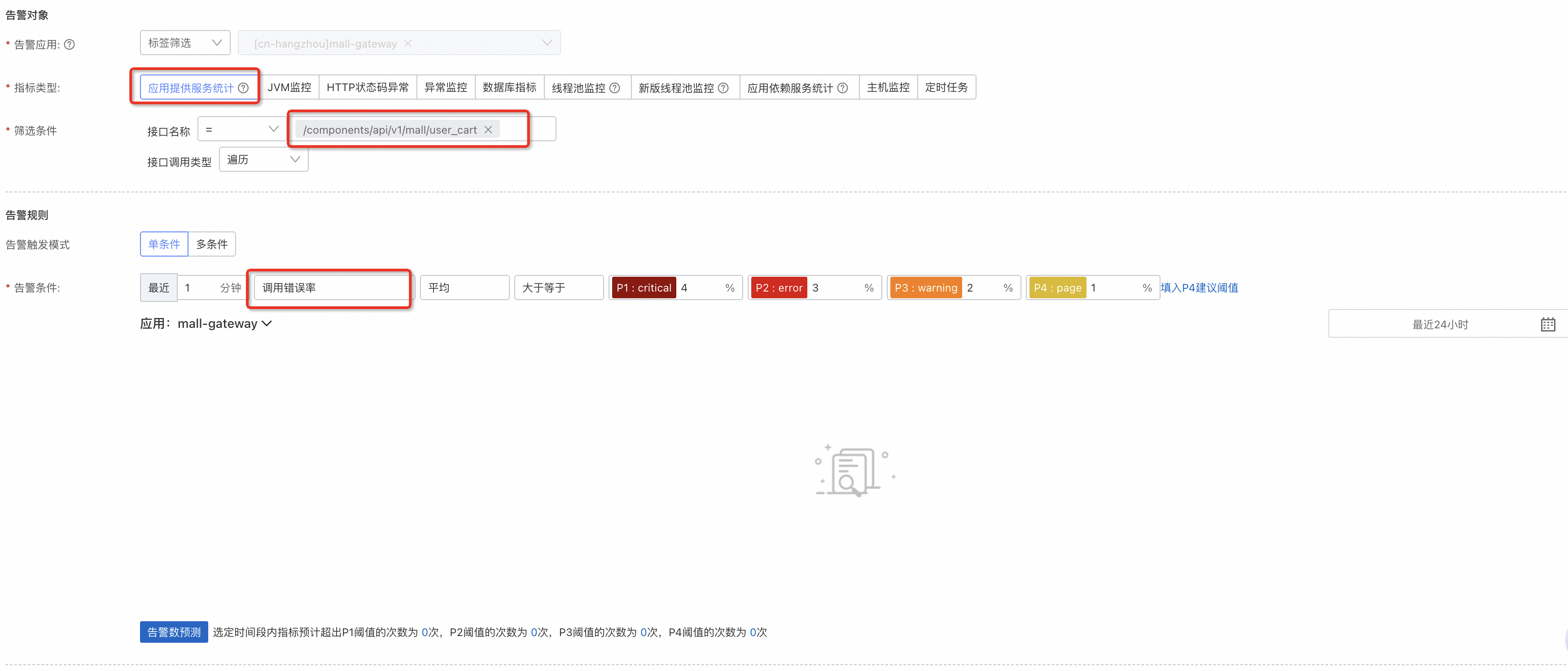
首先最能發現問題的指標是異常,無論是發版更新出了Bug,還是依賴的下遊應用出了問題,通常都伴隨著異常的突增。理想中的應用在正常運行時是沒有異常的,那麼只需要配置一個大於等於的警示即可,而現實中應用多多少少都有異常,所以可以通過配置一個異常的次數上限+環比上升的組合,用於反饋突增的異常。
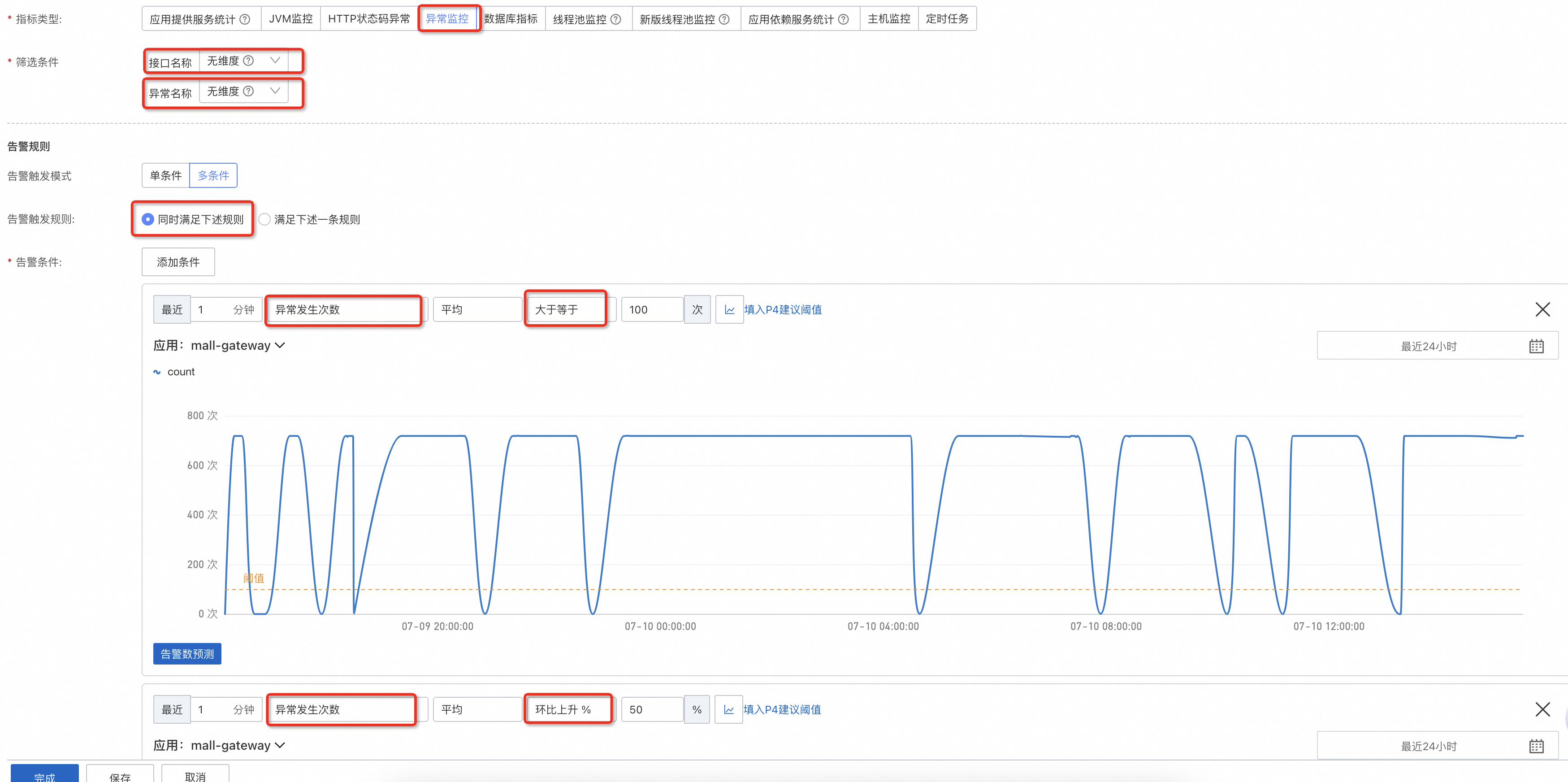
異常數上升不一定代表當前應用存在問題,被捕獲的異常通過良好的異常處理形成的降級機制能夠保證應用仍然可用,但沒有被捕獲的異常影響到了一次介面調用的返回結果,從而構成一次錯誤,因此可以直接為錯誤率配置上限。
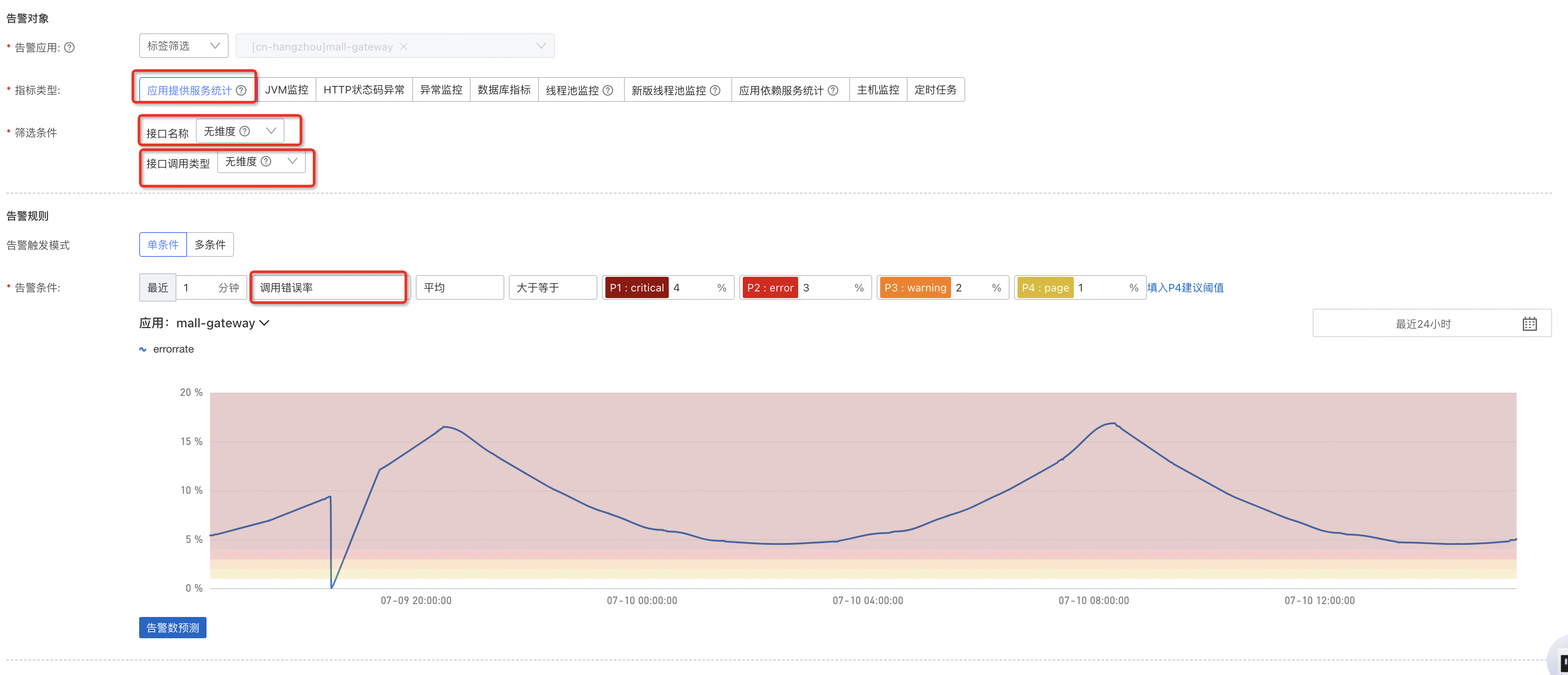
在錯誤率的基礎上,針對HTTP服務的應用,可以選擇HTTP狀態代碼異常,通常4xx是外部例外狀況,因此推薦配置5xx,建議配置次數上限+環比上升的組合。
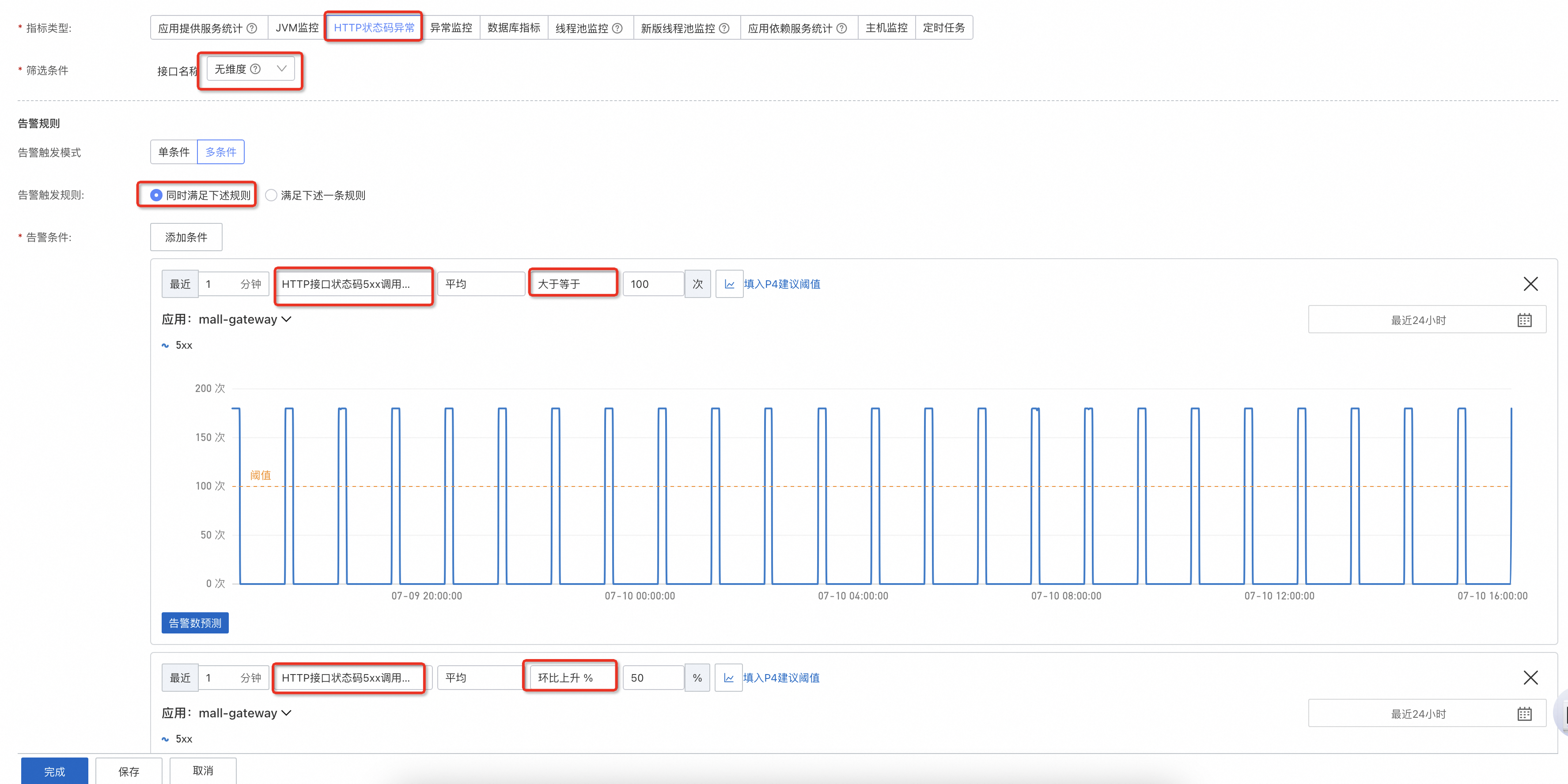
在應用發生問題或流量增大時,整體的耗時往往會有較大提升,所以可以根據實際情況配置一個耗時的上限,如圖所示配置的是一分鐘的平均值。如果業務本身就是有較大的起伏波動,可以調整最近x分鐘的最大值,例如5分鐘、10分鐘,這裡的x分鐘並非延遲x分鐘,是指當前這一分鐘向前x分鐘內的值。
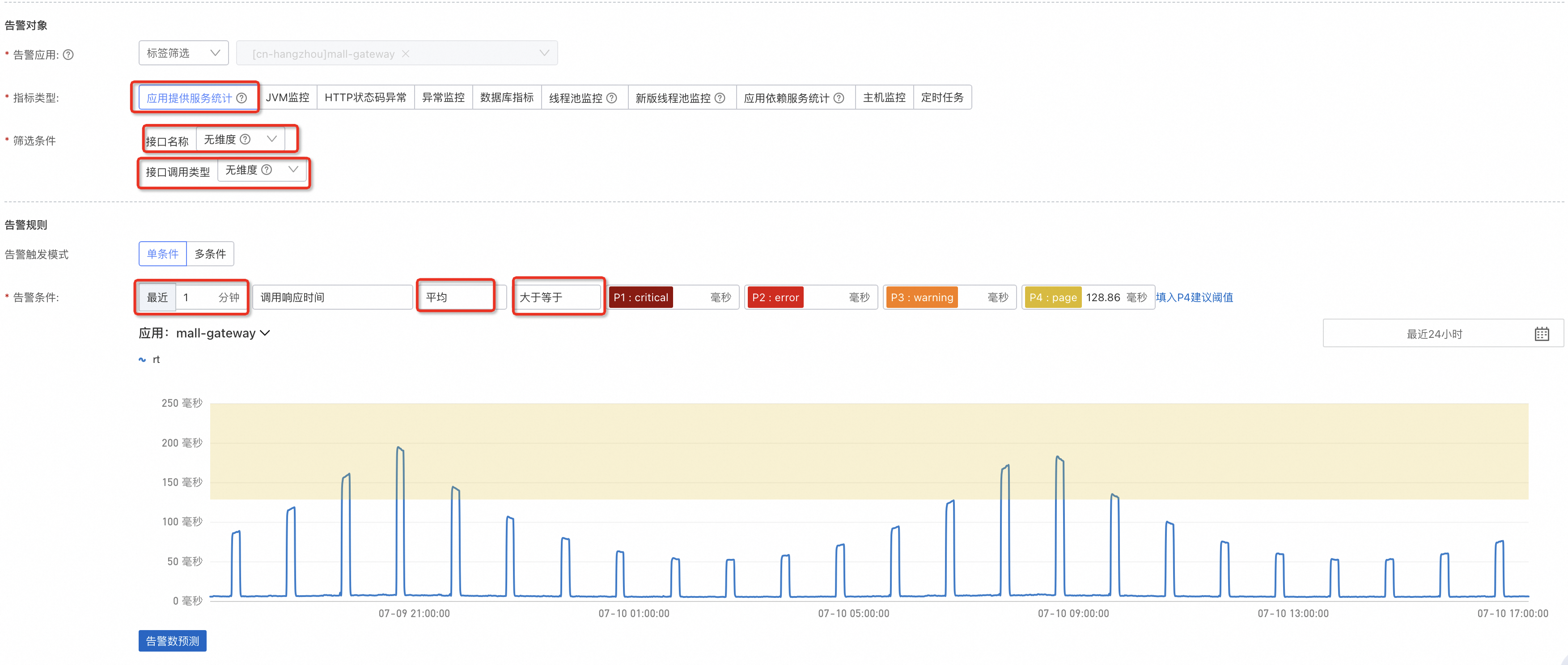
提供服務耗時的上升,分為內部原因和外部原因,外部原因指依賴方,可以是依賴的資料庫,也可以是依賴的服務。
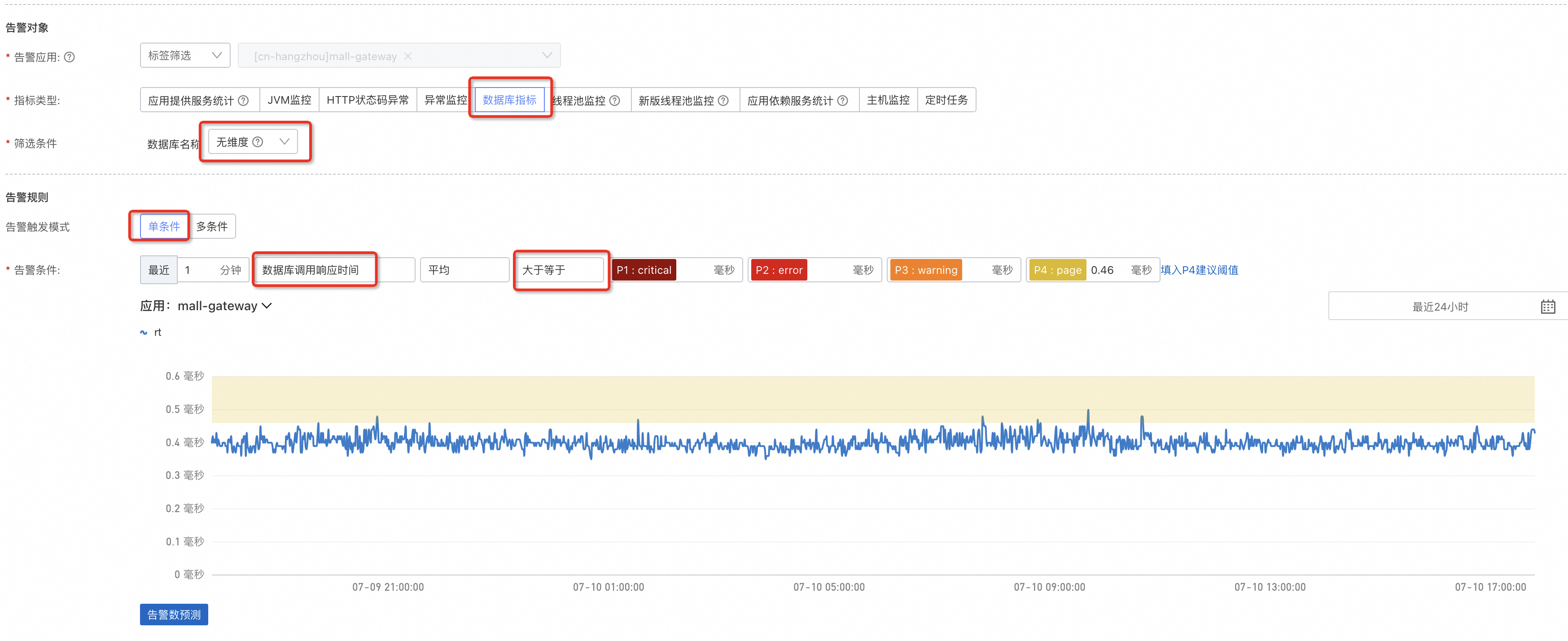
一般的情況下可以為資料庫設定一個耗時的上限,耗時上限可以設定大一些,資料庫有問題時往往會導致調用逾時,耗時會十倍百倍地增長,很容易觸發警示。
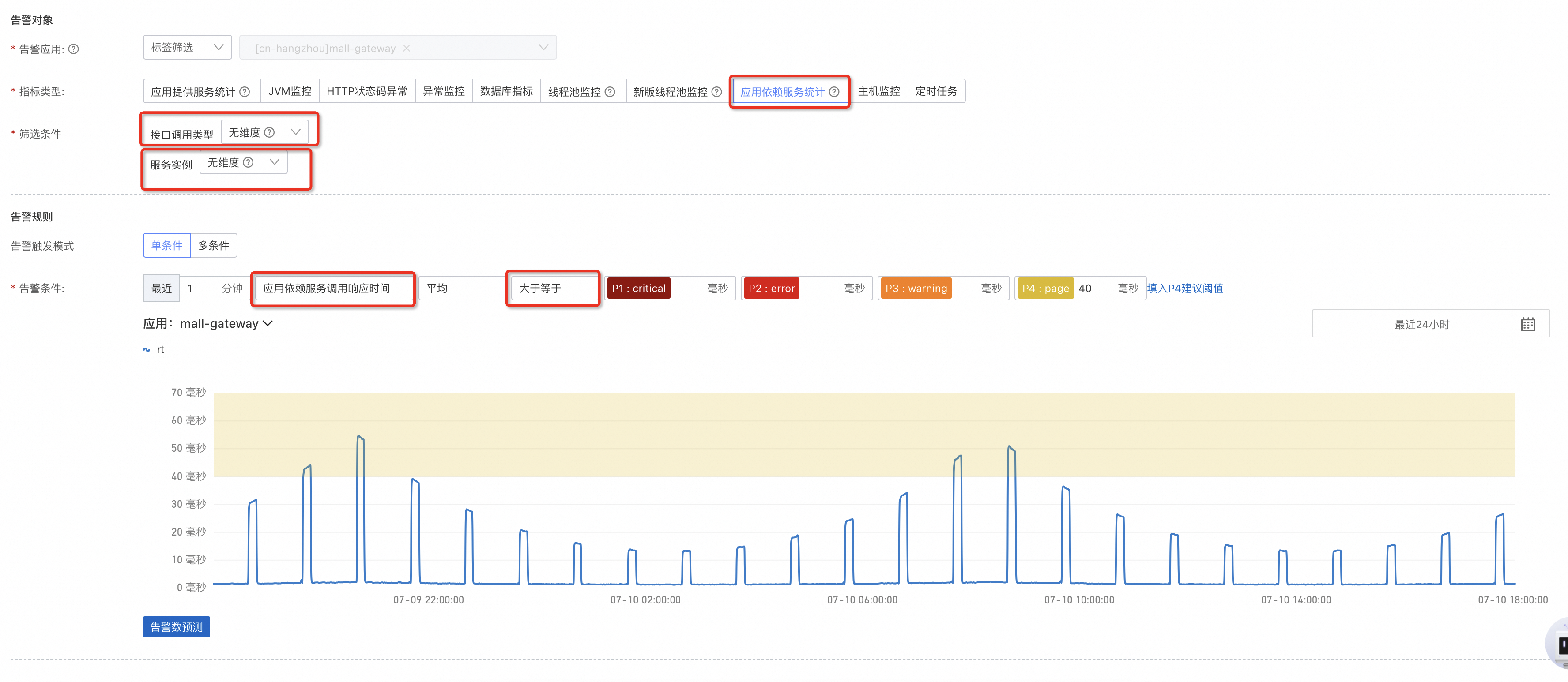
對於依賴的服務,可以分別設定耗時以及錯誤率的上限。
應用依賴服務調用回應時間:
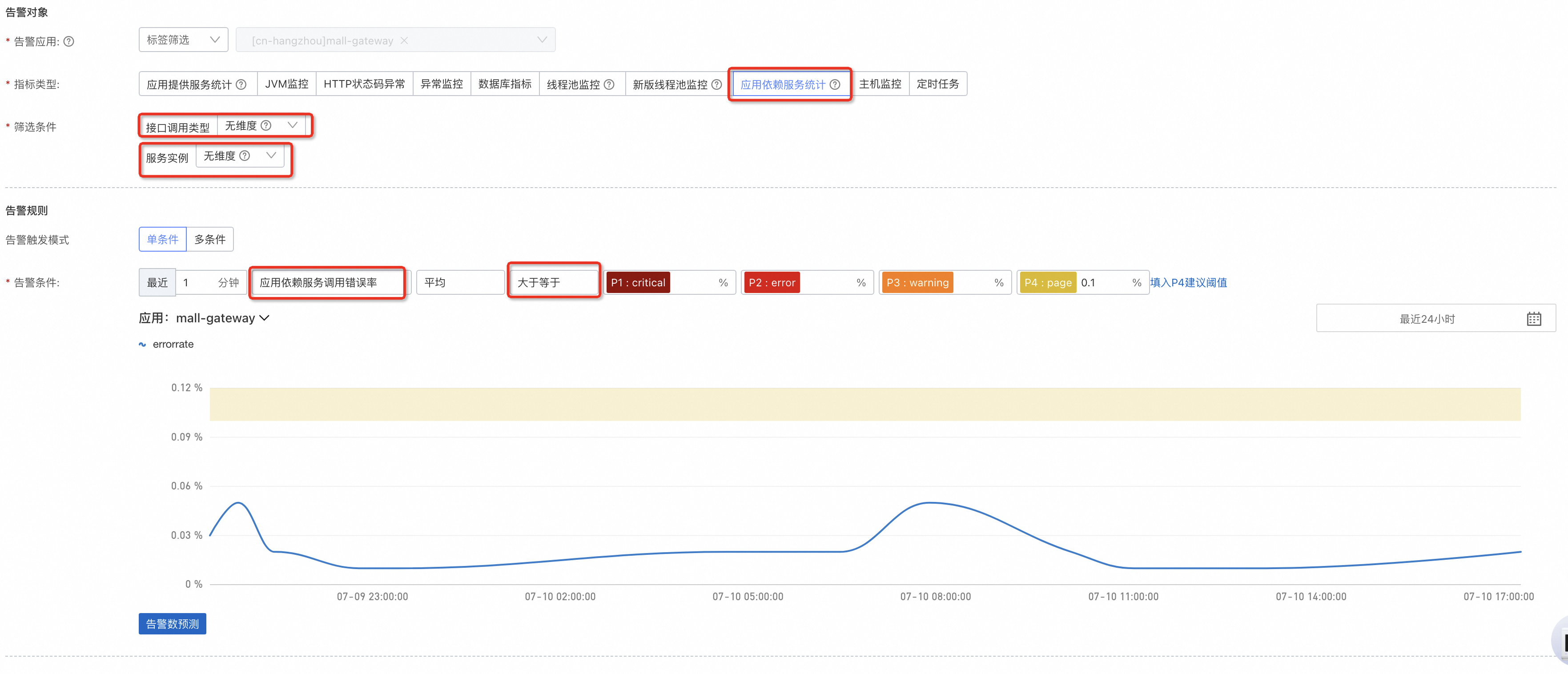
應用依賴服務調用錯誤率:
應用內部自身原因引起的問題,可以配置JVM監控和線程池監控。
JVM監控的指標非常多,建議主要配置一個FGC警示。選擇單機維度,持續的FGC和短時間內多次FGC都是不合理的,對應配置兩個FGC次數的條件警示。
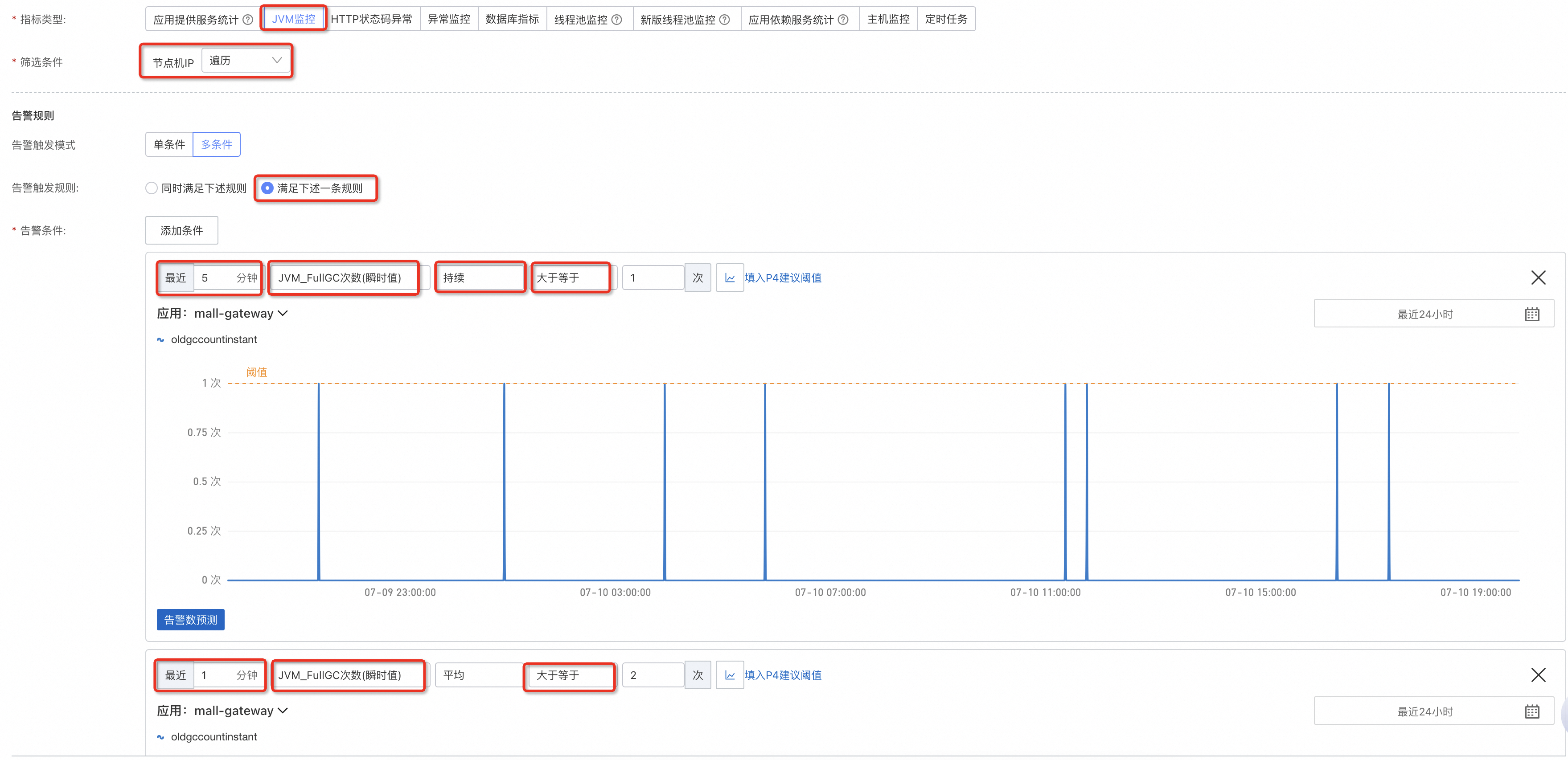
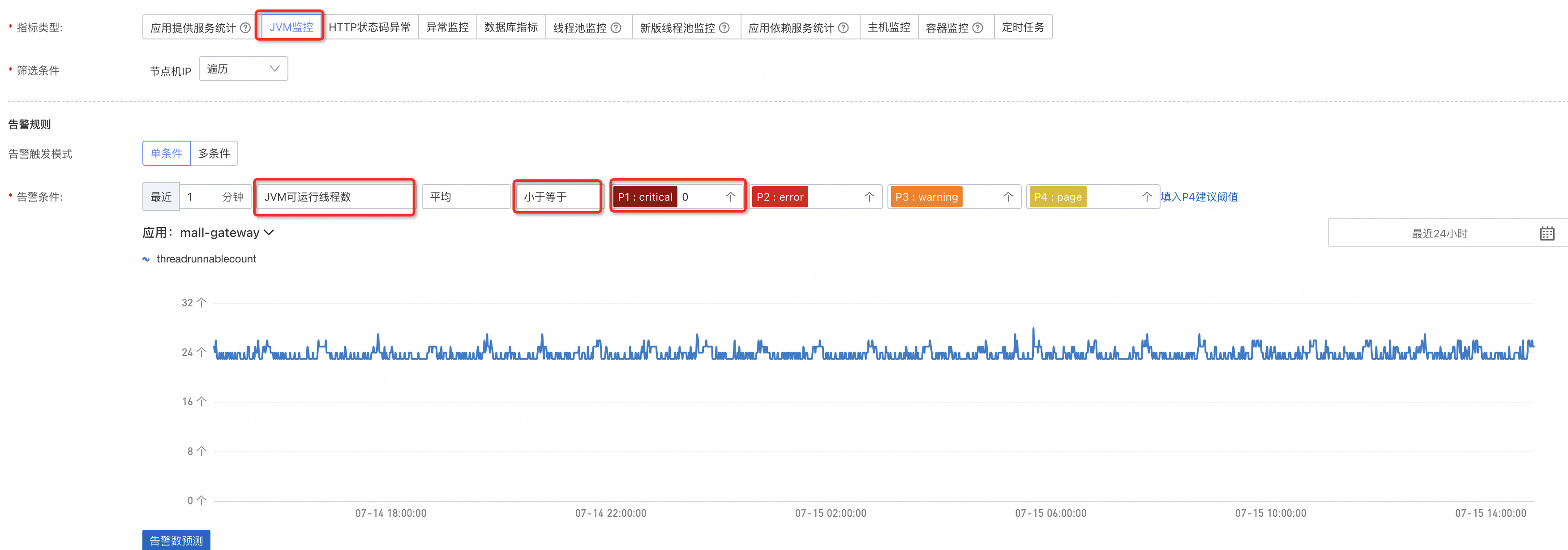
JVM可運行線程數過多會佔用大量的記憶體資源,相反如果值為0時,代表Java虛擬機器裡沒有可運行線程,服務也就有問題,所以可以配置一個線程數小於1的警示。
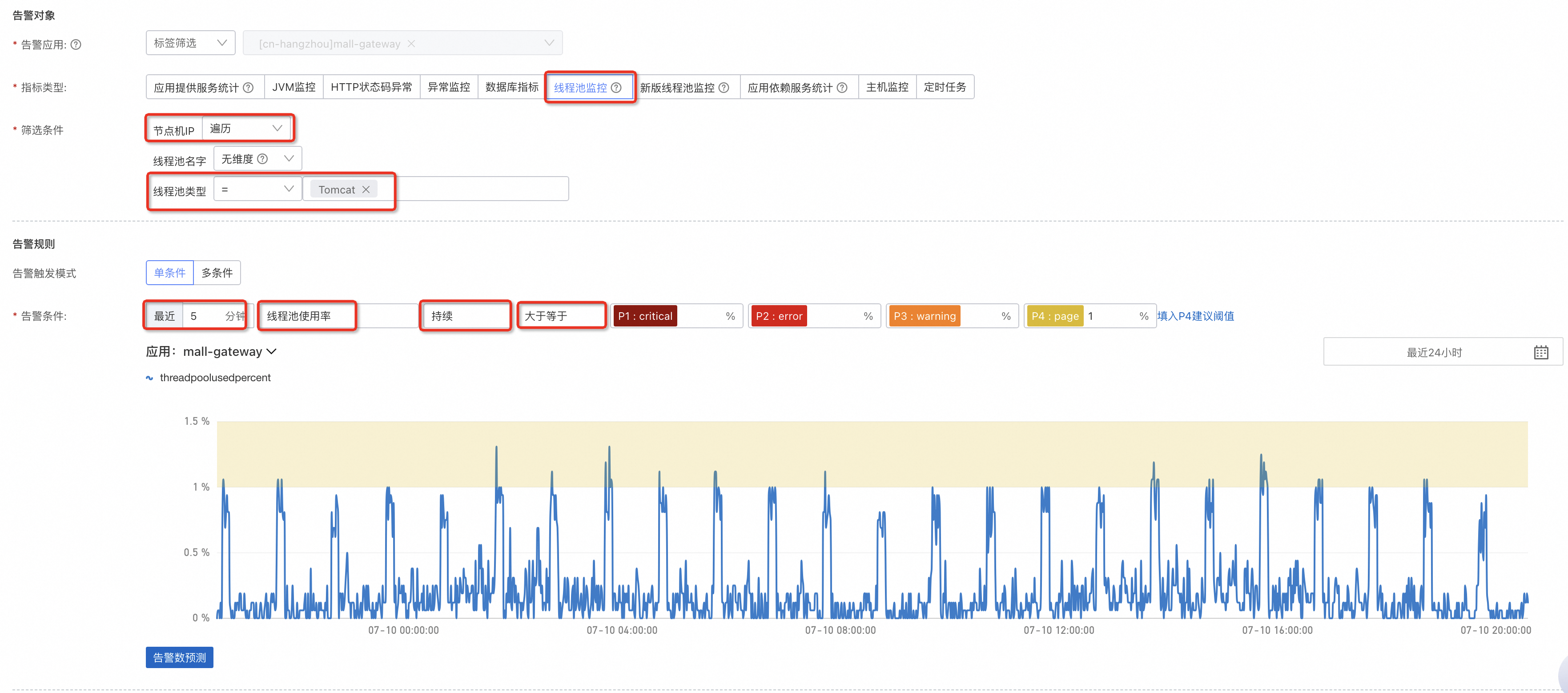
線程池監控可以設定線程池使用率、活躍線程數或最大線程數,線程池存在打滿或者高水位的情況,持續打滿的情況意味著容量達到上限,所以這裡配置的是期間。由於部分線程池未設定最大值,最大值會變成int的最大值2147483647,這種情況下,需要修改指標為活躍線程數。
說明指標類型的線程池監控和新版線程池監控分別對應3.x和4.x版本探針。
基礎
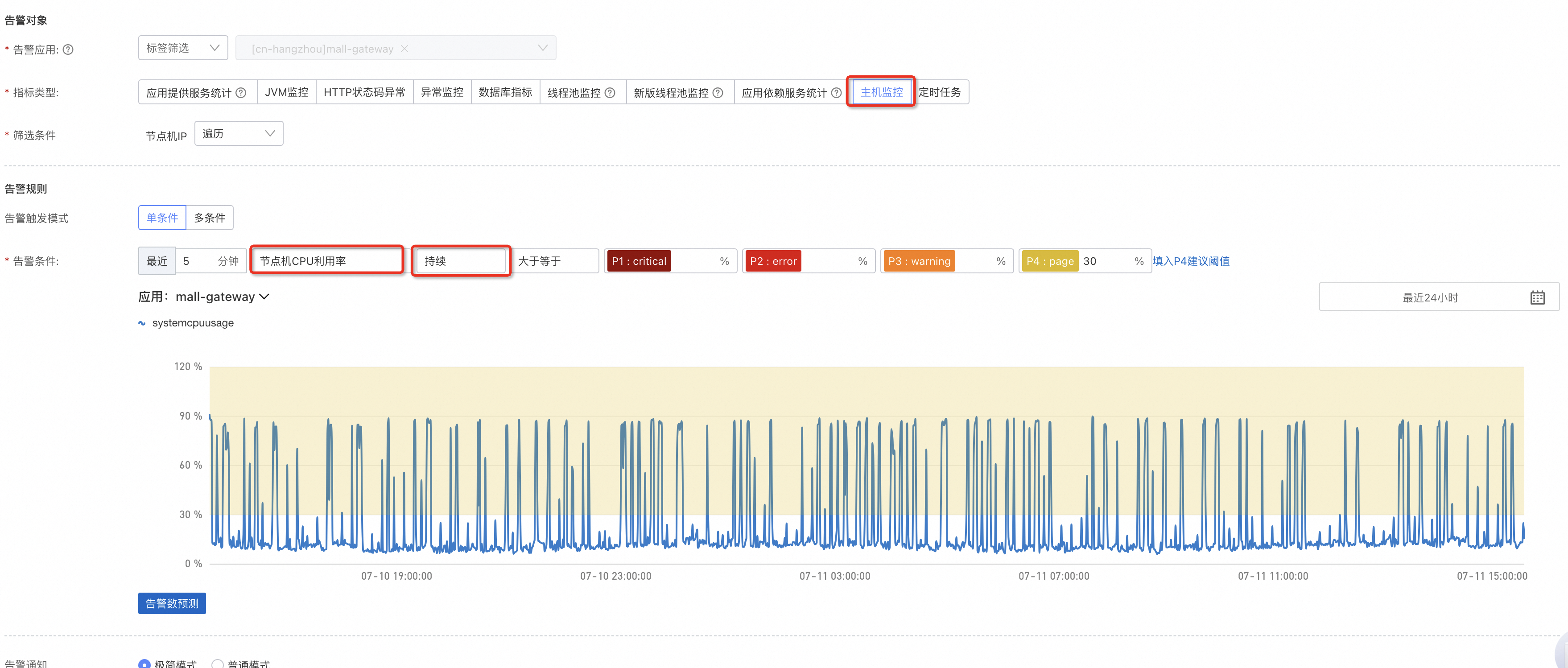
常規的ECS環境下,ARMS會採集對應節點主機上的資訊用於警示。核心的警示需要配置CPU利用率、記憶體利用率、磁碟利用率三項,分別按照實際情況設定上限。
節點機CPU利用率:由於CPU波動比較大,設定上限的前置可以選擇持續。
節點機記憶體利用率:
節點機磁碟利用率:
針對容器應用,如果容器接入了可觀測監控 Prometheus 版,建議優先配置Prometheus警示,具體操作請參見設定警示。
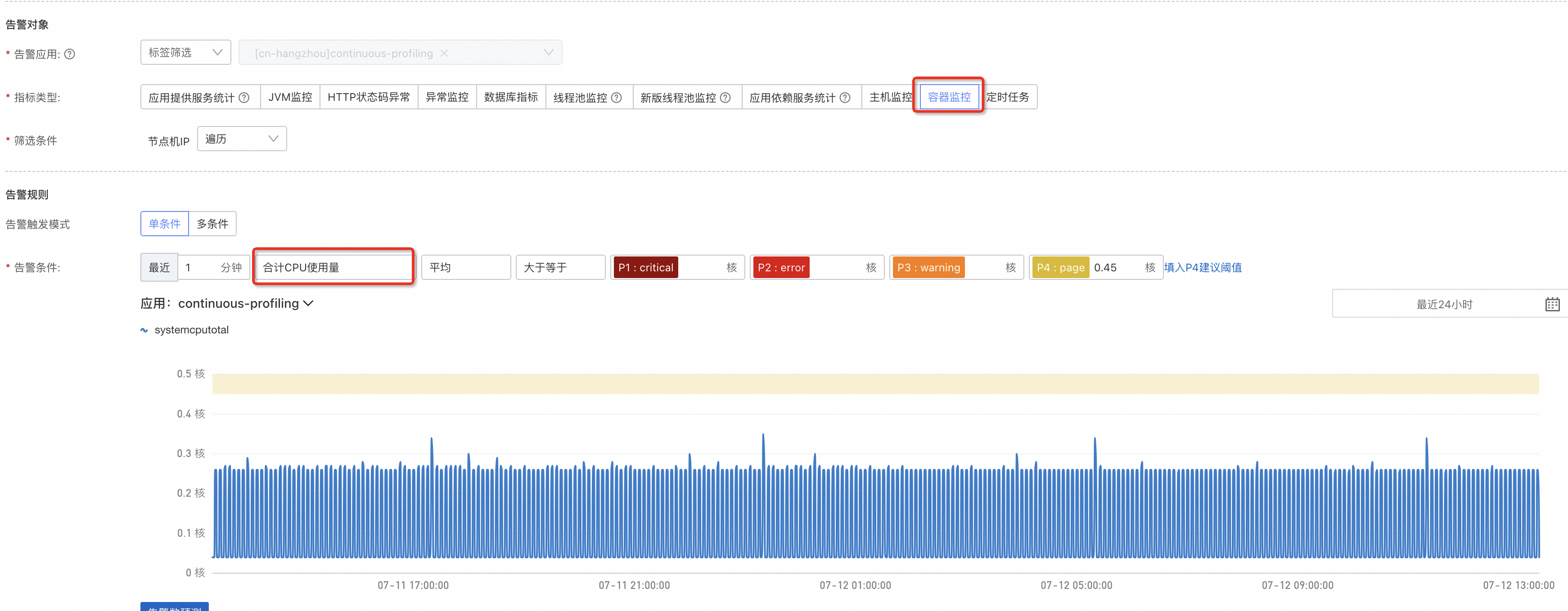
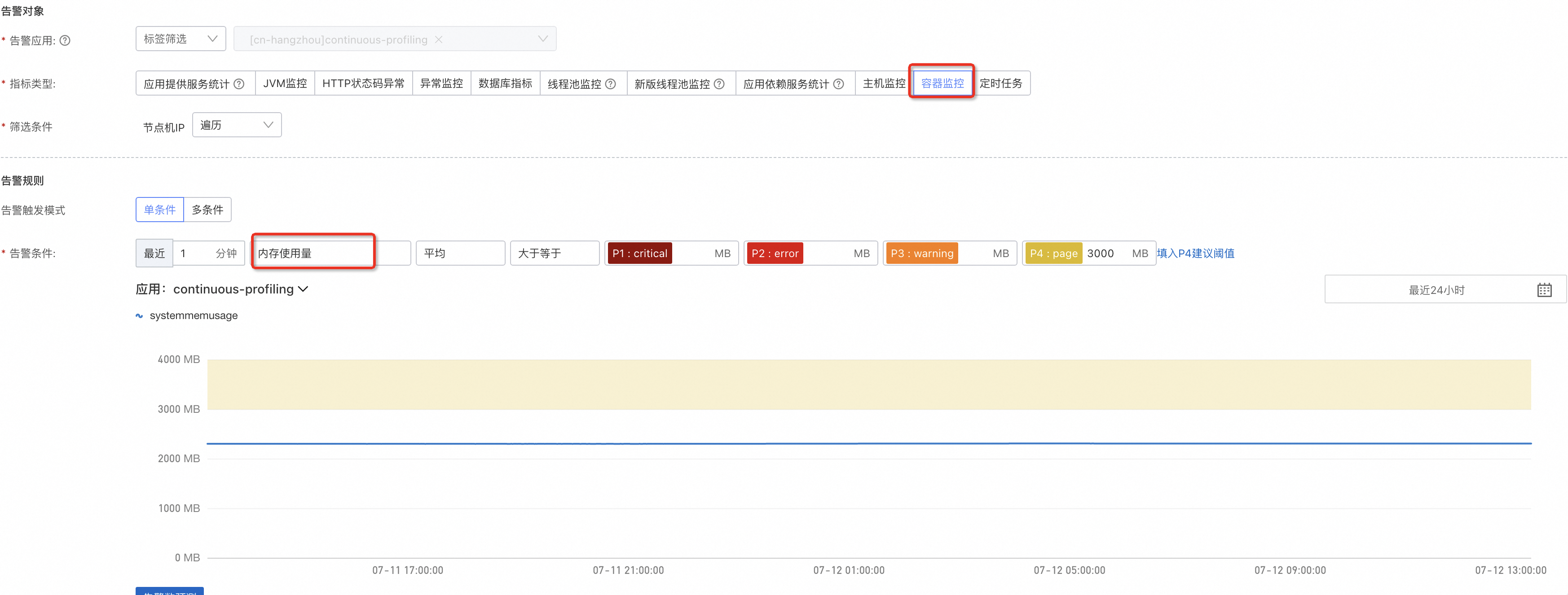
對於未接入可觀測監控 Prometheus 版的容器應用,應用監控(4.1.0及以上探針版本)會採集容器的CPU、記憶體用於監控、警示。您可以分別給CPU和記憶體用量設定上限,由於容器設定資源Limit非必需,此處不會提供百分比的換算,可以基於容器實際的Request、Limit做上限閾值設定。
容器CPU使用量:
容器記憶體使用量量:
其它
常見篩選條件
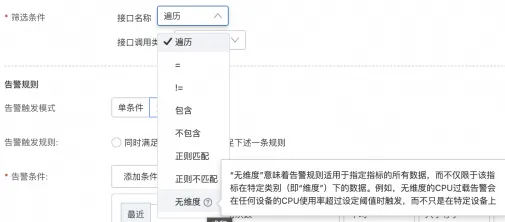
遍曆:遍曆每個節點機IP、介面等,相當於SQL裡的
group by,一般對單機做遍曆,很多介面不適合遍曆。=:指定固定的幾台節點機、介面,相當於是SQL裡的
where條件,一個應用往往有多個介面,可以用來選擇需要被監控的核心介面。無維度:不做過濾,不做分組,看整體。如果是CPU利用率這類主機性質的指標,會取CPU利用率最高的一台主機;如果是提供服務流量指標,則看總量;如果是RT指標,則看平均值。
警示條件
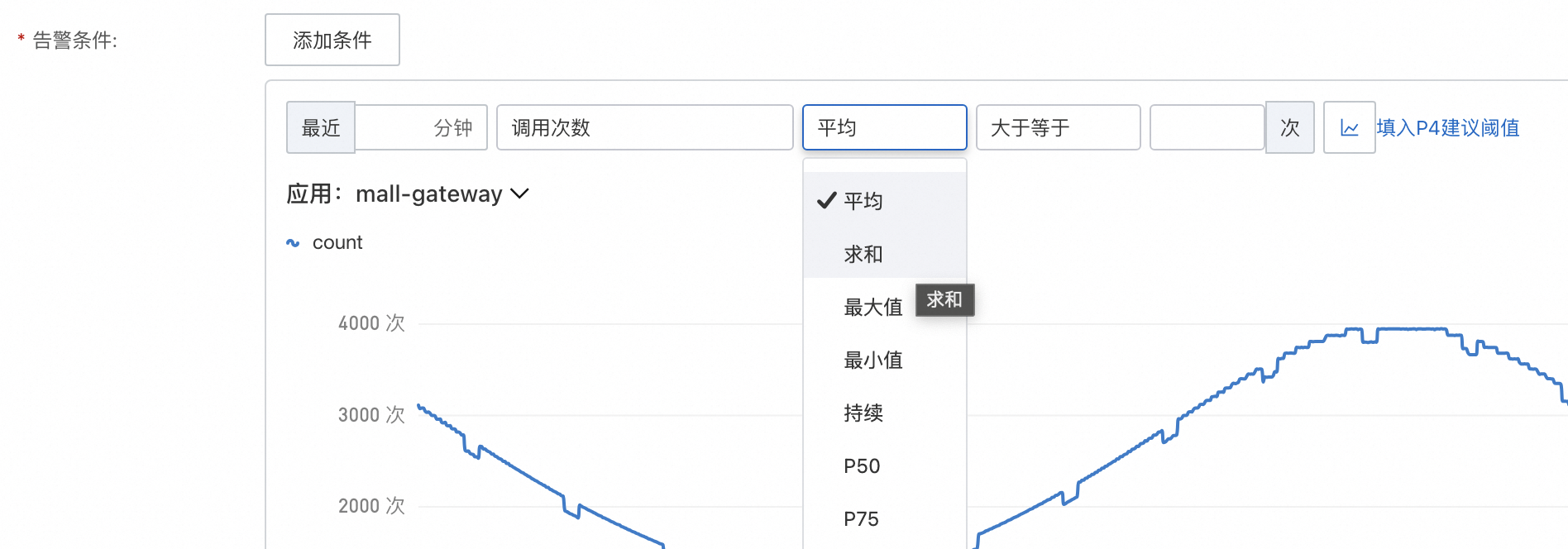
平均/求和/最大值/最小值:最近x分鐘的平均/求和/最大值/最小值。
持續:在x分鐘內,x次匹配則觸發警示。常用于波動比較大的情境,例如CPU利用率,1分鐘超過50%,但是下一分鐘低於50%,說明計算處理完成並沒有持續高水位,則不需要每次都警示。
Pxx:分位元,常用於耗時情境。
警示指標的最小時間顆粒度為1分鐘,所以在最近1分鐘條件下,平均、求和、最大、最小、持續這些條件沒有區別。
閾值
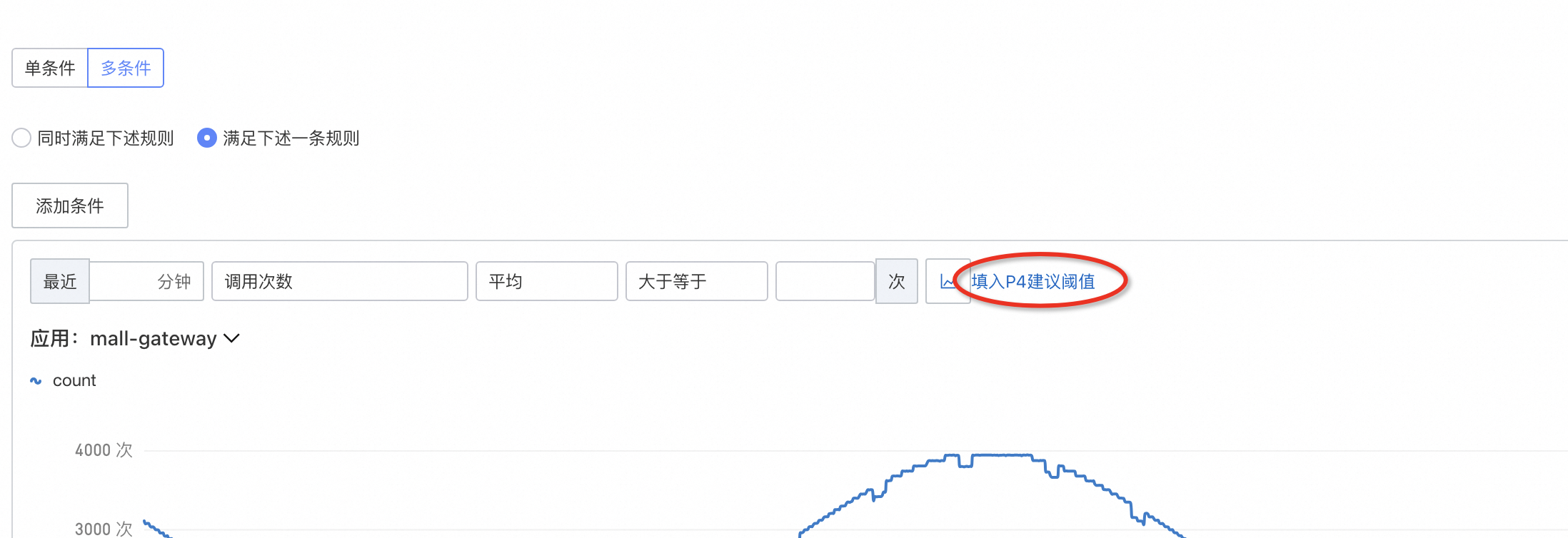
不同業務不同情境下,閾值也是不同的,需要結合實際找到應用合適的點位,經歷多次打磨來逐步最佳化。
對於首次設定警示不確定閾值時,可以使用建議閾值功能。
高階警示
應用警示做了很多封裝,其本質還是基於Prometheus做指標的查詢,所以使用阿里雲可觀測監控 Prometheus 版警示同樣可以通過PromQL配置警示指標。
應用接入ARMS應用監控後,可觀測監控 Prometheus 版會在每個地區下為應用監控自動建立一個專用的儲存執行個體。
通過建立Prometheus警示可以配置更多預設規則之外的警示。

以JVM堆內使用記憶體量指標為例,應用監控裡限制了單個應用,但在Prometheus警示裡可以突破單個應用限制,查看當前地區下全部應用的單機值,對應的PromQL為max by (serverIp,pid) (last_over_time(arms_jvm_mem_used_bytes{area="heap",id="eden"}[1m]))。
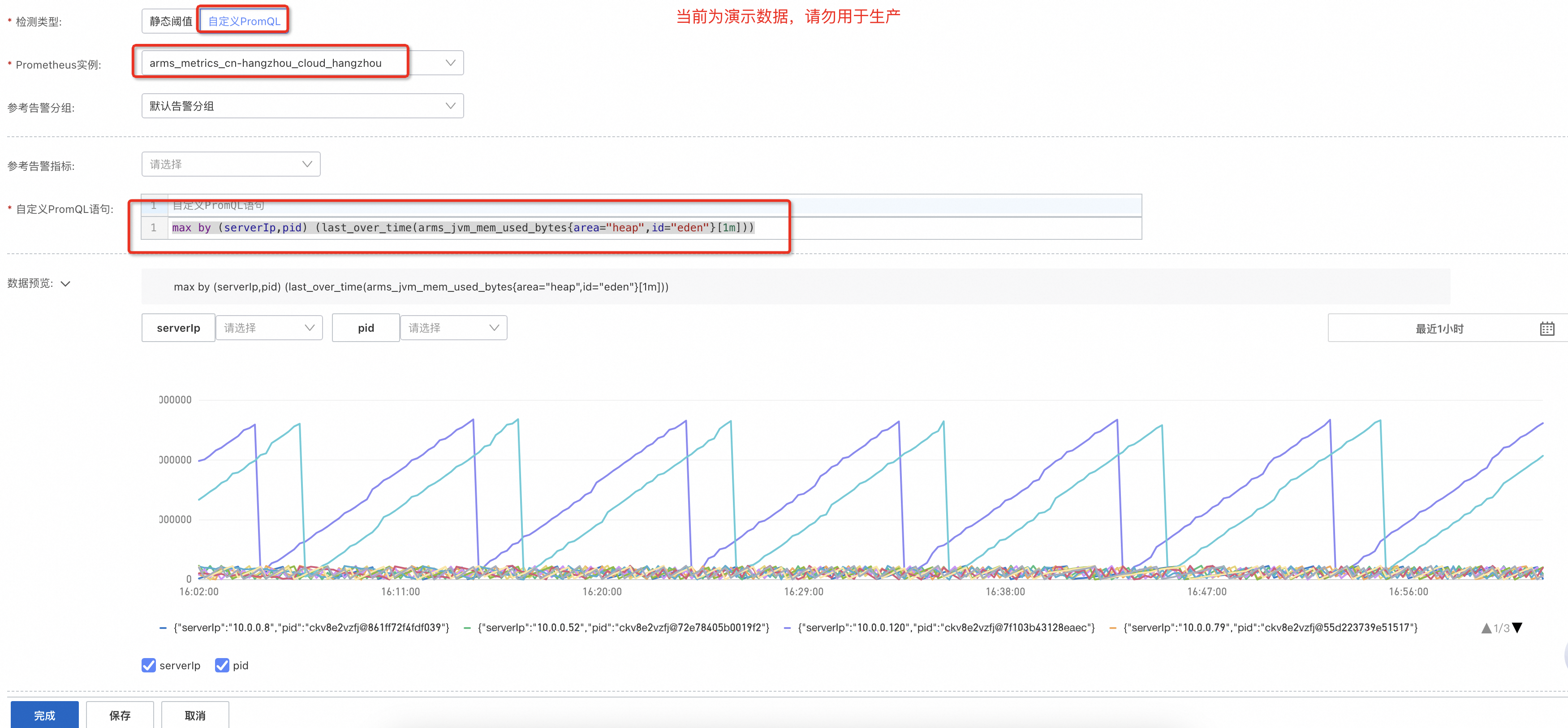
目前可用的穩定指標請參見應用監控指標說明,不在文檔裡的指標在後續升級中可能會導致不相容,因此不推薦使用。
常用模板
業務類
指標PromQL:
模板 | PromQL |
HTTP介面調用次數 | sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
HTTP介面調用耗時 | sum by ($dims) (sum_over_time_lorc(arms_http_requests_seconds{$labelFilters}[1m])) / sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
HTTP介面錯誤次數 | sum by ($dims) (sum_over_time_lorc(arms_http_requests_error_count{$labelFilters}[1m])) |
HTTP介面慢請求次數 | sum by ($dims) (sum_over_time_lorc(arms_http_requests_count{$labelFilters}[1m])) |
維度使用說明:
$dims用於分組,相當於SQL裡的group by。$labelFilters用於過濾,相當於SQL裡的where。
維度名稱 | 維度Key |
服務名稱 | service |
服務PID | pid |
機器IP | serverIp |
介面 | rpc |
樣本:
IP為127.0.0.1的機器上的HTTP介面調用次數,按介面分組。
sum by (rpc) (sum_over_time_lorc(arms_http_requests_count{"serverIp"="127.0.0.1"}[1m]))介面名稱為mall/pay的HTTP介面調用次數,按機器分組。
sum by (serverIp) (sum_over_time_lorc(arms_http_requests_count{"rpc"="mall/pay"}[1m]))
JVM指標
指標PromQL:
模板 | PromQL |
JVM堆內總記憶體量 | max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="old",$labelFilters}[1m)) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="eden",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="survivor",$labelFilters}[1m])) |
JVM YoungGC次數 | sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_delta{gen="young",$labelFilters}[1m])) |
JVM FullGC次數 | sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_delta{gen="old",$labelFilters}[1m])) |
YoungGC耗時 | sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_seconds_delta{gen="young",$labelFilters}[1m])) |
FullGC耗時 | sum by ($dims) (sum_over_time_lorc(arms_jvm_gc_seconds_delta{gen="old",$labelFilters}[1m])) |
活躍線程數 | max by ($dims) (last_over_time_lorc(arms_jvm_threads_count{state="live",$labelFilters}[1m])) |
堆記憶體使用量率 | (max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="old",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="eden",$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_jvm_mem_used_bytes{area="heap",id="survivor",$labelFilters}[1m])))/max by ($dims) (last_over_time_lorc(arms_jvm_mem_max_bytes{area="heap",id="total",$labelFilters}[1m])) |
維度:
維度名稱 | 維度Key |
服務名稱 | service |
服務PID | pid |
機器IP | serverIp |
系統指標
指標PromQL:
模板 | PromQL |
CPU利用率 | max by ($dims) (last_over_time_lorc(arms_system_cpu_system{$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_system_cpu_user{$labelFilters}[1m])) + max by ($dims) (last_over_time_lorc(arms_system_cpu_io_wait{$labelFilters}[1m])) |
記憶體利用率 | max by ($dims) (last_over_time_lorc(arms_system_mem_used_bytes{$labelFilters}[1m]))/max by ($dims) (last_over_time_lorc(arms_system_mem_total_bytes{$labelFilters}[1m])) |
磁碟利用率 | max by ($dims) (last_over_time_lorc(arms_system_disk_used_ratio{$labelFilters}[1m)) |
系統負載 | max by ($dims) (last_over_time_lorc(arms_system_load{$labelFilters}[1m])) |
接受錯誤判文數 | max by ($dims) (max_over_time_lorc(arms_system_net_in_err{$labelFilters}[1m])) |
維度:
維度名稱 | 維度Key |
服務名稱 | service |
服務PID | pid |
機器IP | serverIp |
線程池/串連池指標
指標PromQL:
4.1.x及以上探針版本
模板 | PromQL |
線程池已使用百分比 | avg by ($dims) (avg_over_time_lorc(arms_thread_pool_active_thread_count{$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_thread_pool_max_pool_size{$labelFilters}[1m])) |
串連池已使用百分比 | avg by ($dims) (avg_over_time_lorc(arms_connection_pool_connection_count{state="used",$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_connection_pool_connection_max_count{$labelFilters}[1m])) |
4.1.x以下探針版本
舊版探針的線程池和串連池指標相同,自訂配置時需要指定ThreadPoolType,例如Tomcat、apache-http-client、Druid、SchedulerX、okhttp3、Hikaricp,支援的線程池、串連池架構參見線程池和串連池監控。
模板 | PromQL |
線程池已使用百分比 | avg by ($dims) (avg_over_time_lorc(arms_threadpool_active_size{ThreadPoolType="$ThreadPoolType",$labelFilters}[1m]))/avg by ($dims) (avg_over_time_lorc(arms_threadpool_max_size{ThreadPoolType="$ThreadPoolType",$labelFilters}[1m])) |
維度:
維度名稱 | 維度Key |
服務名稱 | service |
服務PID | pid |
機器IP | serverIp |
線程池名稱(4.1.x以下探針版本支援) | name |
線程池類型(4.1.x以下探針版本支援) | type |