ClickHouse分區鍵最佳實務
本文介紹在雲資料庫ClickHouse中,表設計情境下如何正確選擇表分區鍵,以最佳化效能和提升資料管理效率。
分區鍵
資料分割函數會根據指定的鍵將資料群組織成邏輯段,即資料會按照分區鍵劃分為多個獨立的片段(part)。
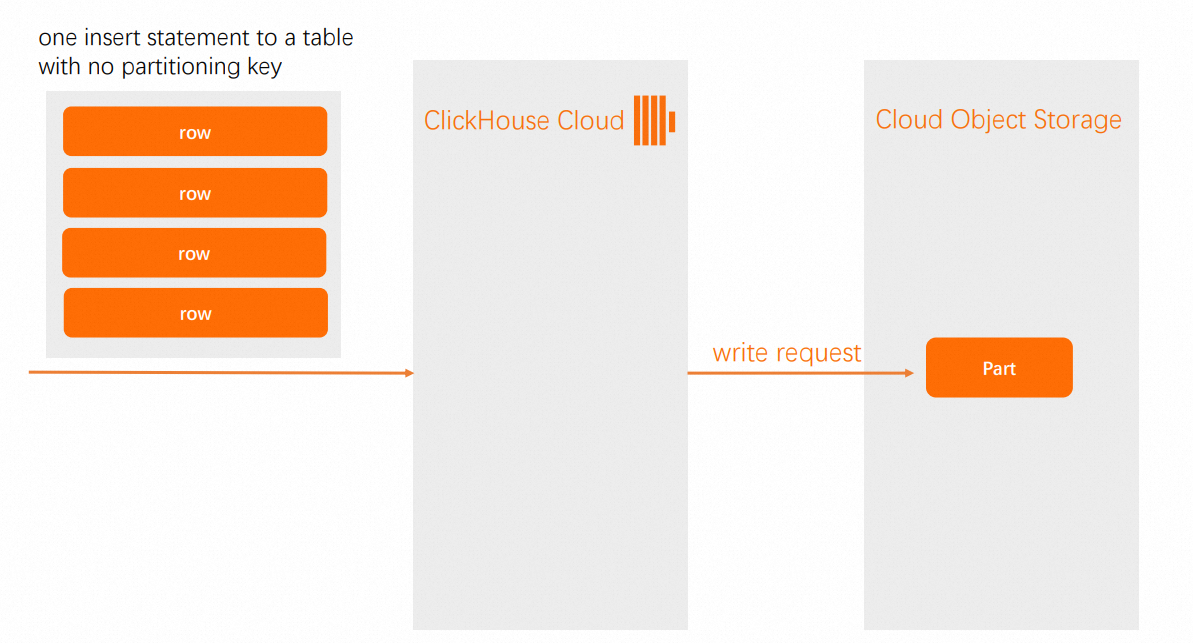
在雲資料庫 ClickHouse 企業版中,當您向沒有分區鍵的表發送插入語句(插入許多行)時,所有資料將會被寫入一個新的part(即資料片段)。然而,當表使用了分區鍵,會執行以下操作:
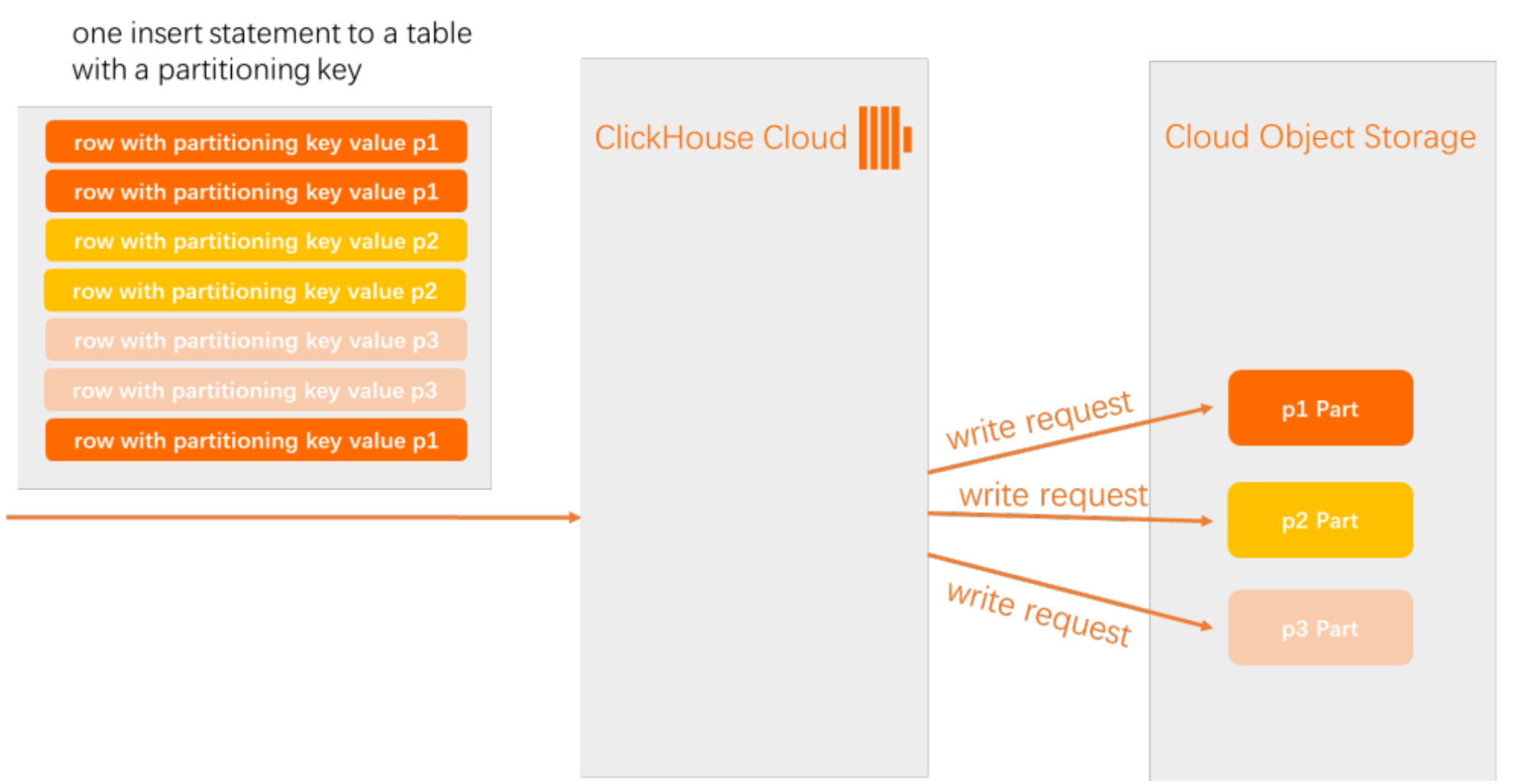
檢查插入表中包含的行的分區索引值。
在儲存中為每個不同的分區索引值建立新的part(即資料片段)。
將行按照分區索引值放入相應的分區中。
沒有分區鍵的表
| 有分區鍵的表
|
核心原則
為了最小化向雲資料庫 ClickHouse 企業版的Object Storage Service發送寫入請求數量,分區鍵應優先選擇低基數(即不同分區值的數量較小)、易於資料管理的欄位(如時間),主鍵應覆蓋常用過濾欄位且順序合理。避免高基數欄位、過細分區和無關主鍵,以發揮ClickHouse的高效能和易管理優勢。
分區是資料管理手段
分區主要用於高效的資料到期、階層式存放區、大量刪除等,而不是首選的查詢最佳化工具。詳細資料,請參見 Choosing a Partitioning Key。
推薦分區數控制在100~1000以內,避免高基數欄位(即不同分區值的數量很大,如user_id、裝置號等)作為分區鍵,否則會導致Part數量爆炸,影響效能,甚至出現“too many parts”錯誤。
常見分區方式為按時間分區
按月、按天等時間維度進行分區,如toYYYYMM(date)、toStartOfMonth(date)、toDate(date),便於資料生命週期管理和冷熱階層式存放區。詳細資料,請參見Custom Partitioning Key。
分區鍵應與資料生命週期、歸檔、清理等管理需求緊密結合
優先考慮業務上易於批量管理的維度。詳細資料,請參見Applications of partitioning。
表設計建議
優先按時間分區
對於日誌、時序、監控等情境,推薦按月或按天分區。例如,log表按月份分區,每個月資料為一個分區,具有以下優勢:
避免高基數欄位分區
如使用者ID、訂單號、裝置號等。例如,某個表按照user_id作為分區鍵,該欄位為高基數欄位(每個使用者唯一代表基數很高),這樣會導致分區數非常多,存在以下弊端:
分區數爆炸:每個唯一的使用者ID都會產生一個分區,分區數量極大,遠超推薦的100~1000範圍,導致中繼資料管理和檔案系統壓力巨大。
後台合并失效:ClickHouse只會在同一分區內合并parts,分區過多會導致合併作業無法進行,產生大量小part,影響查詢和寫入效能。
查詢效能下降:分區過多會導致查詢時需要掃描大量分區中繼資料,降低查詢效率。
執行個體資源耗盡:過多的分區part會消耗大量記憶體和檔案控制代碼,甚至導致ClickHouse啟動變慢或失敗。
分區鍵不宜過細
如按小時、分鐘、秒分區,除非資料量極大且有明確需求。例如,某個表toYYYYMMDDhhmm(event_time) 以分鐘為單位分區,每天就有1440個分區,一年將產生超過50萬個分區,存在以下弊端:
分區數過多:分區過細會導致分區數量遠超推薦的100~1000範圍,極大增加中繼資料和檔案系統的管理負擔。
典型報錯:
DB::Exception: Too many parts (N). Merges are processing significantly slower than inserts。後台合并失效:ClickHouse只會在同一分區內合并parts,分區過多會導致合併作業無法進行,產生大量小part,影響查詢和寫入效能。
查詢和寫入效能下降:分區過多會導致查詢時需要掃描大量分區中繼資料,降低查詢效率,同時寫入時也會因part數量過多而變慢。
分區鍵應為原始欄位或簡單運算式
避免複雜函數,便於ClickHouse利用分區裁剪。
分區鍵與主鍵配合設計
主鍵應覆蓋常用查詢過濾欄位,分區鍵則服務於資料管理。
例如,有一張日誌表,典型的業務需求是經常按時間範圍和服務名查詢,同時需要定期清理到期資料,設計如下:
分區鍵:toYYYYMM(event_time),每月一個分區,便於按月大量刪除、歸檔、冷熱分層等資料管理操作。
主鍵:(service_name, event_time),常用查詢如
WHERE service_name = 'A' AND event_time BETWEEN ...,能充分利用主鍵索引進行資料裁剪,加速查詢。
表設計樣本
CREATE TABLE logs
(
event_time DateTime,
service_name String,
log_level String,
message String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(event_time) -- 按月分區,便於資料管理
ORDER BY (service_name, event_time) -- 主鍵覆蓋常用過濾欄位不推薦的分區鍵選擇
分區鍵為user_id(高基數):每個使用者一個分區,分區數極多,merge失效,效能極差。
分區鍵為裝置號device_id(高基數):同上,導致“too many parts”錯誤,無法管理。
分區鍵為訂單號order_id(高基數):每個訂單一個分區,極端片段化。
分區鍵為name(高基數字串):分區數不可控,管理困難。
分區鍵為toHour(event_time)(過細):每天24個分區,長期運行後分區數極大,merge 失效。
分區鍵為toMinute(event_time)(極細):分區數爆炸,嚴重影響效能。
主鍵為高基數欄位且順序不合理:例如ORDER BY (user_id, event_time),但常按 event_time 查詢,導致主鍵索引利用率低。
主鍵包含過多欄位:例如ORDER BY (a, b, c, d, e, f, g, h, i, j),導致主鍵索引體積大,記憶體消耗高。
主鍵為低基數欄位:例如ORDER BY (status),只有幾個狀態值,導致主鍵索引裁剪能力極差。
分區鍵與主鍵完全無關,且都不覆蓋常用查詢條件:例如分區鍵為region,主鍵為type,但常按event_time 查詢,導致分區和主鍵都無法加速查詢。