使用搶佔式執行個體節省大模型微調成本
為降低模型微調訓練成本,您可以使用伸縮組自動調度搶佔式執行個體,同時配置搶佔式執行個體中斷回收時自動建立新執行個體、基於最新Checkpoint恢複訓練,保障任務連續性。
方案概覽
本方案基於伸縮組實現大模型低成本微調訓練,採用搶佔式執行個體優先策略並結合Object Storage Service實現Checkpoint持久化,在訓練過程中:
優先使用搶佔式執行個體:伸縮組優先調度搶佔式執行個體執行訓練任務,並使用Object Storage Service儲存Checkpoint檔案。
搶佔式執行個體中斷回收時:伸縮組會優先嘗試從其他可用性區域庫存中調度搶佔式執行個體,若搶佔式庫存不足,則自動調度按量執行個體,從最新的Checkpoint恢複訓練任務。
搶佔式庫存恢複後:自動將按量執行個體替換為搶佔式執行個體,並從最新的Checkpoint恢複訓練。
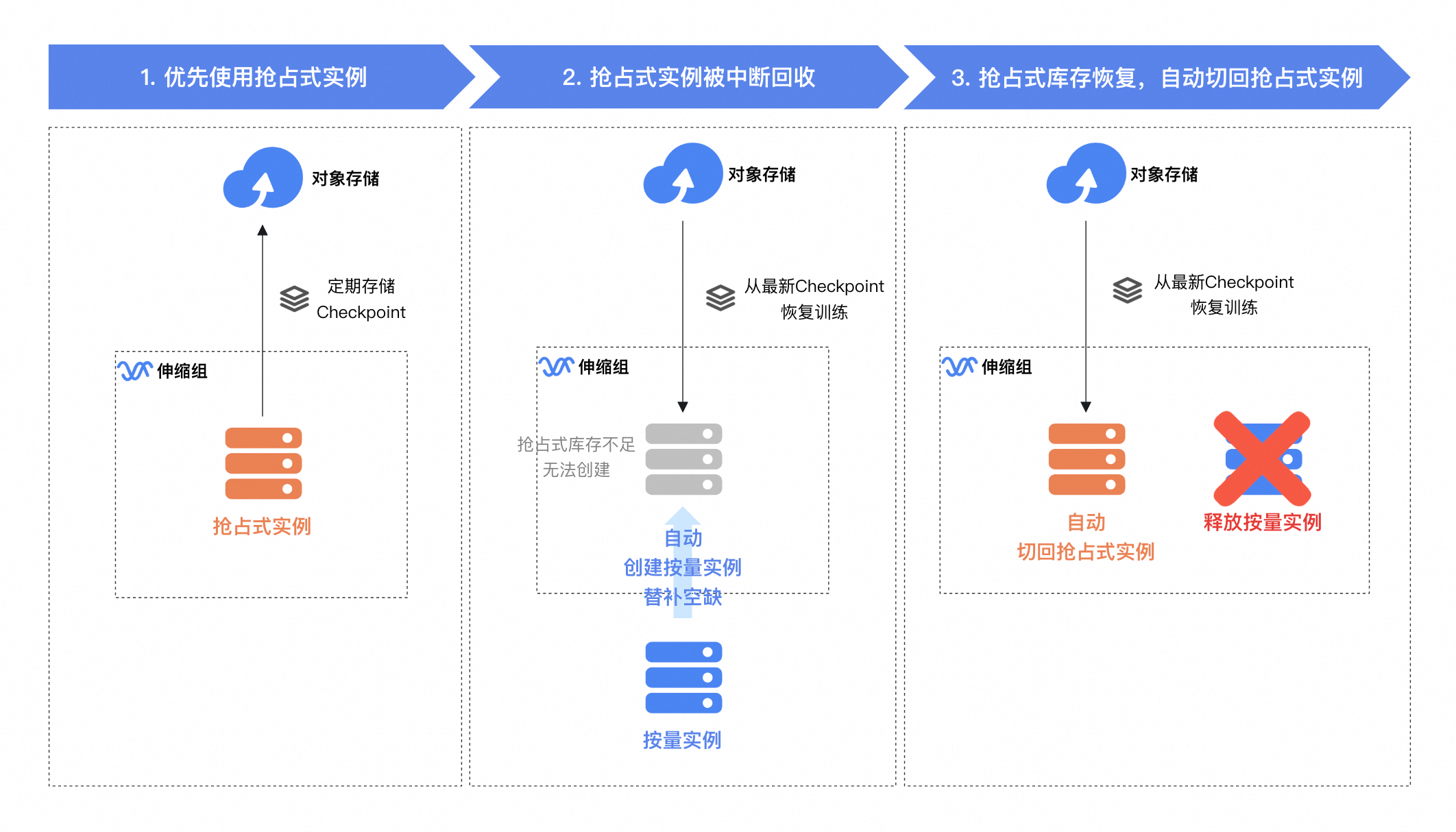
若您對成本敏感且能接受訓練結束時間延遲,可配置伸縮組全程使用搶佔式執行個體。在無法使用搶佔式執行個體時暫停訓練,庫存恢複後繼續使用搶佔式執行個體,以極致節省成本。點擊瞭解更多伸縮組與搶佔式執行個體的組合用法。
成本對比
以下成本對比僅供參考,成本節省效果視實際運行情況而定。
假設訓練共需12小時,搶佔式執行個體單價為3.5/h,按量執行個體單價10/h,成本對比如下。
模式 | 全程使用搶佔式執行個體 | 搶佔式、按量交替 | 全程使用按量 |
說明 | 當搶佔式執行個體被中斷回收時,暫停訓練,在庫存恢複後自動啟動新的搶佔式執行個體繼續訓練。 | 假設每1小時搶佔式執行個體中斷回收一次,然後按需執行個體使用0.5小時後切回搶佔式執行個體。 | 全部使用按量執行個體進行訓練。 |
成本 | 12h * 3.5/h = 42 | 8h * 3.5/h + 4h * 10/h = 68 | 12h * 10/h = 120 |
相比全程按量成本節省 | 65% | 43.33% | 0% |
搭建流程
構建包含訓練基礎環境的執行個體鏡像。
該鏡像將作為伸縮組執行個體的啟動鏡像,內建開機自動訓練指令碼,確保新執行個體能夠快速恢複訓練任務,實現自動化運行。
建立並配置伸縮組。
伸縮組負責在執行個體中斷或回收後,自動建立新的搶佔式或按量執行個體,確保訓練任務持續進行。
啟動訓練任務。
啟動伸縮組後自動觸發擴容,建立執行個體以開始訓練任務,並按照預先設定的自動化機制工作。
類比中斷回收(驗證)。
手動釋放執行個體以類比中斷或資源回收情境,驗證是否能啟動新執行個體並自動回復訓練任務,確保任務的穩定性和可靠性。
1. 構建包含訓練基礎環境的執行個體鏡像
本文將以單機單卡情境下,使用Swift訓練架構對DeepSeek-R1-Distill-Qwen-7B模型進行自我認知微調為例,進行步驟說明。
首先需建立包含訓練環境及依賴的執行個體並製作鏡像,作為伸縮組執行個體的啟動鏡像,以提升任務執行個體啟動效率;鏡像內建自動訓練指令碼和開機自啟服務,實現全流程自動化運行。用於製作該鏡像的ECS執行個體架構如圖所示。
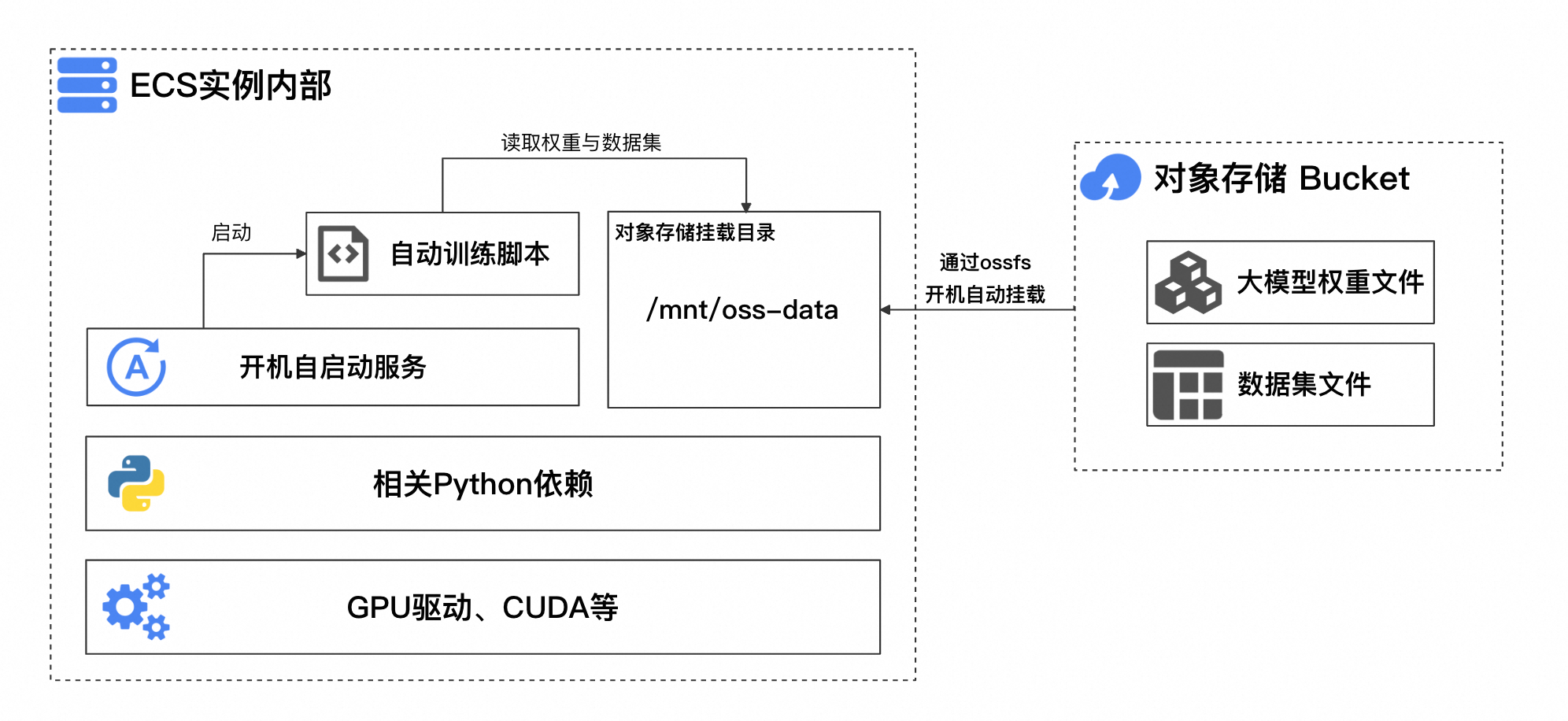
關鍵點說明如下:
訓練環境基礎依賴:包含GPU驅動、CUDA以及相關Python依賴(根據訓練架構而定)。
自動訓練指令碼:此指令碼需能夠自動判斷是否從最新的Checkpoint恢複訓練,並判斷訓練是否已完成。
開機自動掛載Bucket:訓練指令碼啟動時會從Object Storage ServiceBucket中讀模數型權重、資料集以及訓練產生的Checkpoint檔案。
開機自啟動服務:該服務確保執行個體開機後,自動啟動訓練指令碼,讀取Bucket中的相關檔案,開始或繼續訓練。
在瞭解以上內容後,您可以參考以下步驟完成該鏡像的構建。
1.1 建立執行個體並構建基礎環境
該執行個體會作為模板執行個體,產出鏡像,後續伸縮組會自動以該鏡像建立新執行個體。
前往ECS控制台建立GPU執行個體。
首先需要建立一個按量的GPU執行個體用於基礎環境的搭建。本文以在杭州地區的可用性區域J建立規格為
ecs.gn7i-c8g1.2xlarge的執行個體為例。配置步驟:①:付費類型。隨用隨付。
②:地區。華東1(杭州)。
③④:網路及可用區。選擇專用網路和交換器,若沒有可按照介面提示建立。
⑤⑥:選擇執行個體規格。
ecs.gn7i-c8g1.2xlarge。⑦⑧⑨:鏡像。Ubuntu 22.04 64位。
⑩:安裝GPU驅動。版本:CUDA版本 12.4.1、Driver版本 550.127.08、CUDNN版本 9.2.0.82。
⑪:。60GiB。
⑫⑬⑭:分配公網IPv4地址使執行個體可以訪問公網,下載模型檔案。頻寬計費模式選擇按使用流量。頻寬峰值選擇100Mbps。
⑮⑯⑰:建立普通安全性群組,連接埠至少放開SSH(TCP:22)和ICMP(IPv4),便於後續遠端連線執行個體。
⑱⑲⑳:登入憑證。用於後續登入執行個體。可根據需求選擇金鑰組或密碼。根據介面提示完成設定。
㉑:實例名稱。設定便於記憶的執行個體名稱,便於尋找。本文以
ess-lora-deepseek7b-template為例。完成配置後單擊確認下單,等待執行個體建立完成。
在執行個體建立完成後,串連執行個體並等待GPU驅動安裝完成。
訪問ECS控制台-執行個體。
找到上一步建立的執行個體,單擊操作列下的遠端連線,通過Workbench串連執行個體,並根據介面提示完成登入操作。
若未找到執行個體,可能是當前地區與執行個體地區不符,可以在左上方切換地區。
若執行個體處於停止狀態,請重新整理頁面並等待執行個體啟動。
串連執行個體後,等待GPU驅動安裝完成。安裝完成後,會提示您重新串連執行個體。
若介面卡住,您可以嘗試重新整理頁面,重新串連執行個體。
Welcome to Alibaba Cloud Elastic Compute Service ! Last login: Tue Mar 18 21:12:39 2025 from xxx % Total % Received % Xferd Average Speed Time Time Current Dload Upload Total Spent Left Speed 100 21 100 21 0 0 875 0 --:--:-- --:--:-- --:--:-- 913 Driver-xxx installing, it takes 0 minutes. Remaining installation time 11 to 15 minutes! [cuda-12.4.1. Installing, it tasks 2 to 5 minutes. Remaining installation time 9 to 12 minutes!
安裝相關Python依賴。
使用以下命令,安裝訓練相關依賴。
本樣本所選擇的鏡像為Ubuntu 22.04 64-bit,已經包含Python 3.10環境,因此不需要安裝Python。
# ubuntu 22.04鏡像內建python 3.10,無需額外安裝 python3 -m pip install --upgrade pip # 切換為阿里雲內網鏡像源 pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
在等待依賴安裝時,可以點擊右上方開啟多屏終端,同時進行步驟1.2的操作。
1.2 建立Object Storage Service的儲存空間並掛載到執行個體
本步驟需要先在Object Storage Service建立儲存空間(Bucket),並將該儲存空間作為額外的資料盤掛載到ECS執行個體,負責儲存後續步驟下載的模型權重檔案、訓練資料集以及訓練過程中產生的Checkpoint。
前往Object Storage Service控制台建立Bucket。
關鍵配置項說明如下,未提及配置項保持預設。
②:Bucket名稱。該Bucket名稱在後續掛載儲存空間時會用到。
③:地區。選擇有地區屬性,地區需與ECS執行個體所在地區保持一致,本樣本為華東 1 (杭州)。
ECS執行個體支援通過內網訪問同地區的Object Storage ServiceBucket,內網訪問不會產生流量費用,具體說明,請參見ECS執行個體通過OSS內網地址訪問OSS資源。
建立並綁定執行個體RAM角色。
執行個體RAM角色用於授權ECS執行個體訪問您建立的Object Storage ServiceBucket。建立並綁定執行個體RAM角色的操作流程如下:
在控制台建立執行個體RAM角色。關鍵配置項說明如下。
進入RAM存取控制控制台的角色頁面,單擊建立角色。
②:信任主體類型。選擇雲端服務。
③:信任主體名稱。選擇Elastic Compute Service,代表該角色需要授權給ECS執行個體。
④:單擊確定後,根據介面提示設定執行個體RAM角色的名稱。
在控制台建立以下自訂權限原則。
進入RAM存取控制控制台的權限原則頁面,單擊建立權限原則。
選擇指令碼編輯頁簽,輸入以下權限原則指令碼內容。
③:該策略代表某個Bucket的全部許可權。權限原則指令碼內容如下。
重要設定以下自訂策略時,請將
<bucket_name>替換為您所建立的儲存空間的Bucket名稱。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }完成配置後單擊確定,根據介面提示設定權限原則名稱。
在控制台為執行個體RAM角色授權。
⑥:授权主体。選擇之前建立的執行個體RAM角色。
⑦:权限策略。選擇之前建立的自訂權限原則。
完成配置後單擊確認新增授權。
前往ECS控制台,將執行個體RAM角色授予給執行個體。
若未找到執行個體,可能是當前地區與執行個體地區不符,可以在左上方切換地區。
在ECS控制台執行個體列表中找到對應執行個體,通過操作列為其綁定步驟1.2中建立的執行個體RAM角色。
將儲存空間掛載到ECS執行個體。
串連步驟1.1建立的執行個體,執行以下命令,安裝ossfs工具。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.5_ubuntu22.04_amd64.deb apt-get update DEBIAN_FRONTEND=noninteractive apt-get install gdebi-core DEBIAN_FRONTEND=noninteractive gdebi -n ossfs_1.91.5_ubuntu22.04_amd64.deb執行以下命令完成掛載操作。需注意替換命令中的以下內容:
<bucket_name>:替換為您所建立的儲存空間的Bucket名稱。<ecs_ram_role>:替換為您所建立的執行個體RAM角色名稱。<internal_endpoint>:替換為oss-cn-hangzhou-internal.aliyuncs.com。重要本樣本所建立的Bucket地區為華東 1 (杭州),故使用
oss-cn-hangzhou-internal.aliyuncs.com作為VPC內網Endpoint。
# 需替換對應的Bucket名稱、內網存取點、執行個體RAM角色 BUCKET_NAME="<bucket_name>" ECS_RAM_ROLE="<ecs_ram_role>" INTERNAL_ENDPOINT="<internal_endpoint>" # Bucket掛載目錄 BUCKET_MOUNT_PATH="/mnt/oss-data" # 1. 掛載前備份fstab檔案 cp /etc/fstab /etc/fstab.bak # 2. 建立被掛載的目錄 mkdir $BUCKET_MOUNT_PATH # 3. 掛載Bucket到執行個體 ossfs $BUCKET_NAME $BUCKET_MOUNT_PATH -ourl=$INTERNAL_ENDPOINT -oram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE # 4. 設定開機自動掛載 echo "ossfs#$BUCKET_NAME $BUCKET_MOUNT_PATH fuse _netdev,url=http://$INTERNAL_ENDPOINT,ram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE,allow_other 0 0" | sudo tee -a /etc/fstab
(驗證)測試儲存空間是否可用。
在Object Storage Service的Bucket中上傳任意檔案。
在OSS控制台進入Bucket的檔案清單頁面,單擊上傳檔案,上傳一個測試檔案用於驗證掛載。
在執行個體中輸入以下命令,測試是否可以在目錄看到Object Storage Service中的檔案。
ls /mnt/oss-data/如果可以看到,則代表掛載成功。
root@ixxx:~# ls /mnt/oss-data/ test.txt
1.3 準備模型與資料集
本文使用的模型權重檔案與資料集均從魔搭社區下載,串連執行個體後,按照以下步驟操作。將模型與資料集下載到Object Storage ServiceBucket所掛載的目錄,並等待所有檔案下載完成。
下載資料集
# Bucket掛載目錄 BUCKET_MOUNT_PATH="/mnt/oss-data" # 從魔搭社區下載微調資料集 # 使用步驟1.1中安裝的modelscope工具 modelscope download --dataset swift/self-cognition --local_dir $BUCKET_MOUNT_PATH/self-cognition modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-en若進度卡住可以多次點擊斷行符號。
下載模型權重檔案
重要由於模型權重檔案過大,若下載失敗,或提示
please try again,請重試該命令恢複下載。# Bucket掛載目錄 BUCKET_MOUNT_PATH="/mnt/oss-data" # 從魔搭社區下載DeepSeek-R1-Distill-Qwen-7B模型 modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B若進度卡住可以多次點擊斷行符號。
測試模型權重檔案是否有效
在下載完成後,您可以在命令列執行以下命令,使用模型進行推理測試,測試模型權重檔案是否完整。
# Bucket掛載目錄 BUCKET_MOUNT_PATH="/mnt/oss-data" CUDA_VISIBLE_DEVICES=0 swift infer \ --model $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B \ --stream true \ --infer_backend pt \ --max_new_tokens 2048模型載入完成後,您可以與大模型進行對話。如果模型權重檔案載入失敗,請重新下載模型權重檔案。
[INFO:swift] Start time of running main: 2025-03-26 13:35:50.564493 [INFO:swift] request_config: RequestConfig(max_tokens=2048, temperature=None, top_k=None, top_p=None, repetition_penalty=None, num_beams=1, stop=[], seed=None, stream=True, logprobs=False, top_logprobs=None, n=1, best_of=None, presence_penalty=0.0, frequency_penalty=0.0, length_penalty=1.0) [INFO:swift] Input 'exit' or 'quit' to exit the conversation. [INFO:swift] Input 'multi-line' to switch to multi-line input mode. [INFO:swift] Input 'reset-system' to reset the system and clear the history. [INFO:swift] Input 'clear' to clear the history. <<< 你是誰?測試完成後可輸入
exit退出對話。
1.4 編寫自動訓練指令碼
編寫自動訓練指令碼。
輸入以下命令建立自動訓練指令碼,並授予可執行許可權。本指令碼包含自動從最新Checkpoint恢複訓練的以及判斷訓練完成的功能。
# 建立自動訓練指令碼 cat <<EOF > /root/train.sh #!/bin/bash # Bucket掛載目錄 BUCKET_MONTH_PATH="/mnt/oss-data" # 模型權重檔案及資料集儲存目錄 MODEL_PATH="\$BUCKET_MONTH_PATH/DeepSeek-R1-Distill-Qwen-7B" DATASET_PATH="\$BUCKET_MONTH_PATH/alpaca-gpt4-data-zh#500 \$BUCKET_MONTH_PATH/alpaca-gpt4-data-en#500 \$BUCKET_MONTH_PATH/self-cognition#500" # 設定輸出目錄 OUTPUT_DIR="\$BUCKET_MONTH_PATH/output" mkdir -p "\$OUTPUT_DIR" # 判斷已經完成訓練,無需操作的邏輯 if [ -f "\$OUTPUT_DIR/logging.jsonl" ]; then last_line=\$(tail -n 1 "\$OUTPUT_DIR/logging.jsonl") if echo "\$last_line" | grep -q "last_model_checkpoint" && echo "\$last_line" | grep -q "best_model_checkpoint"; then echo "Training already completed. Exiting." exit 0 fi fi # 初始化恢複參數 RESUME_ARG="" # 尋找最新檢查點 LATEST_CHECKPOINT=\$(ls -dt \$OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1) if [ -n "\$LATEST_CHECKPOINT" ]; then RESUME_ARG="--resume_from_checkpoint \$LATEST_CHECKPOINT" echo "Resume training from: \$LATEST_CHECKPOINT" else echo "No checkpoint found. Starting new training." fi # 啟動訓練命令 CUDA_VISIBLE_DEVICES=0 swift sft \\ --model \$MODEL_PATH \\ --train_type lora \\ --dataset \$DATASET_PATH \\ --torch_dtype bfloat16 \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --per_device_eval_batch_size 1 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 10 \\ --save_total_limit 5 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir "\$OUTPUT_DIR" \\ --add_version False \\ --overwrite_output_dir True \\ --system 'You are a helpful assistant.' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 \\ --model_author swift \\ --model_name swift-robot \\ \$RESUME_ARG EOF # 授予可執行許可權 chmod +x /root/train.sh建立Linux服務,並配置開機自啟動。
輸入以下命令建立服務,並配置訓練指令碼開機自啟動。
# 建立日誌儲存目錄 mkdir -p /root/train-service-log # 編寫Service設定檔 cat <<EOF > /etc/systemd/system/train.service [Unit] Description=Train AI Model Script After=network.target local-fs.target remote-fs.target Requires=local-fs.target remote-fs.target [Service] ExecStart=/root/train.sh WorkingDirectory=/root/ User=root Environment="PATH=/usr/bin:/usr/local/bin" Environment="CUDA_VISIBLE_DEVICES=0" StandardOutput=append:/root/train-service-log/train.log StandardError=append:/root/train-service-log/train_error.log [Install] WantedBy=multi-user.target EOF # 重新載入systemd配置 systemctl daemon-reload # 配置train.service服務開機自啟動 systemctl enable train.service命令執行完成返回如下內容:
Created symlink /etc/systemd/system/multi-user.target.wants/train.service → /etc/systemd/system/train.service.
1.5 構建鏡像
在完成前面所有步驟後,需要從完成配置的執行個體構建自訂鏡像,後續在擴容時,可以直接使用該鏡像作為執行個體的啟動鏡像,無需重新安裝相關依賴等操作。
訪問ECS控制台-執行個體。
根據以下步驟說明建立鏡像。
在ECS控制台的執行個體列表中,找到對應執行個體,單擊操作列的更多 > 雲端硬碟與鏡像 > 建立自訂鏡像,根據介面提示完成鏡像建立。
等待鏡像建立完成。鏡像建立大概需要5分鐘左右的時間,您可以在ECS控制台-鏡像查看您的鏡像建立進度。
鏡像建立完成後,可釋放步驟1.1中建立的執行個體。
2. 建立伸縮組
配置伸縮組以實現對執行個體的自動化管理。伸縮組主要負責確保執行個體在中斷回收後,可以自動建立新的搶佔式執行個體或按量執行個體,繼續訓練任務。在可以建立搶佔式執行個體時,自動使用搶佔式執行個體替換按量執行個體以節省成本。
2.1 建立伸縮組
首先需要建立伸縮組,操作步驟如下。
前往Auto Scaling控制台建立伸縮組。
重要注意伸縮組所在地區要與步驟1.1中建立的執行個體地區保持一致。
根據以下步驟,完成伸縮組的配置。如需瞭解配置項詳細說明,請參見配置項說明。
配置以下參數:伸縮組名稱設為ess-lora-deepseek-7b,伸縮群組類型選擇ECS,組內執行個體配置資訊來源選擇已啟動執行個體,組內最小執行個體數設為0,組內最大執行個體數設為1,預設冷卻時間保持300秒。
重要在⑤⑥選擇專用網路和交換器時,建議選擇多個可用性區域的交換器,使伸縮組可以跨可用性區域調度庫存,提高搶佔式執行個體的使用機率。
重要如果您希望僅使用搶佔式執行個體進行訓練,以極致節省成本,需關閉⑮使用按量執行個體補充搶佔式容量和⑯搶佔式執行個體自動替換按量兩個配置項。
完成配置後單擊建立。可根據介面提示繼續建立伸縮配置。
2.2 建立伸縮配置
伸縮配置主要用於定義伸縮組中執行個體的規格、鏡像等資訊。完成該配置後,伸縮組會自動按照該配置定義的執行個體資訊,建立新執行個體。在建立伸縮配置頁面,完成以下配置:
①:伸縮配置名稱。 ②:付費模式。搶佔式執行個體。 |
③④:選擇鏡像。選擇自訂鏡像,然後選擇步驟1.5中構建的自訂鏡像。 ⑤:執行個體配置方式。選擇指定執行個體規格。 ⑥:執行個體使用時間長度。選擇設定執行個體使用1小時,使用該選項,在執行個體運行一小時後,開始檢測是否中斷回收執行個體。 如果選擇無確定使用時間長度,雖然能以更低的成本使用按量執行個體,但由於其中斷回收的機率更高,可能執行個體被回收前不能產生有效Checkpoint,導致訓練進度緩慢。該配置項兩個選項之間的區別,請參見在伸縮組使用搶佔式執行個體降低成本。 ⑦:單台執行個體上限價格。選擇使用自動出價,自動跟隨市場價進行出價。 ⑧:選擇執行個體規格。選擇步驟1.1中建立執行個體時設定的執行個體規格,即 |
⑨:安全性群組。選擇步驟1.1中建立執行個體時設定的安全性群組。 本樣本為離線訓練方案,無需分配公網IP。 |
⑩:登入憑證。選擇使用鏡像預設密碼。 |
⑪⑫⑬:。選擇步驟1.2中建立的執行個體RAM角色。後續在伸縮組自動建立執行個體時,將自動為新執行個體設定該執行個體RAM角色。 |
單擊建立後,可能會提示伸縮配置強度不足,點擊繼續即可。
建立伸縮配置後,根據介面提示啟用伸縮配置並啟動伸縮組。
伸縮配置建立成功後,在彈出的對話方塊中單擊啟用配置。 | 在選用伸縮配置確認對話方塊中,單擊確定。 | 在啟用伸縮組確認對話方塊中,單擊確定啟用伸縮組。 |
3. 開始訓練任務
在伸縮組配置完成後,需調整伸縮組的期望執行個體數為1,操作步驟如下。
進入伸縮組詳情頁,查看執行個體伸縮概覽,當前各項執行個體數均為0。 | 單擊修改執行個體伸縮概覽,開啟期望執行個體數開關,將組內期望執行個體數設為1,單擊確認。伸縮組將自動建立一台搶佔式執行個體。 |
完成後,伸縮組會自動建立一台新的執行個體並開始訓練任務。
伸縮組會定期檢測伸縮組中的執行個體數量是否滿足期望執行個體數。當前伸縮組中執行個體數為0,將自動觸發擴容,建立新執行個體。
調整期望執行個體數後,建立執行個體的操作可能會有延遲。您可以在伸縮活動頁簽下,查看伸縮組中進行中的伸縮活動。
執行個體建立並啟動完成後,您可以在Object Storage Service中找到
output檔案夾,該檔案夾用於儲存訓練過程中產生的Checkpoint檔案。
4. 類比中斷回收(驗證)
在執行個體開始執行訓練任務後,可以觀察Object Storage Service的Bucket中output目錄下是否已經產生類似checkpoint-10的檔案夾,當產生Checkpoint後,您可以手動釋放正在訓練的執行個體,類比執行個體的中斷回收,手動釋放執行個體的操作如下:
手動釋放執行個體。
首先進入伸縮組的執行個體列表,單擊雲端服務器ID進入對應的執行個體管理頁。
在執行個體管理頁,單擊右上方的,根據介面提示完成執行個體的釋放操作。
檢查是否從最新的Checkpoint恢複訓練。
等待伸縮組建立新執行個體,執行個體建立完成後,串連該執行個體,查看任務日誌。
進入伸縮組的執行個體列表,單擊雲端服務器ID進入對應的執行個體管理頁。
單擊右上方的遠端連線,根據介面提示串連執行個體。
執行以下命令查看模型訓練日誌,該日誌輸出路徑是您在步驟1.4中設定的開機自啟動服務的日誌輸出路徑。
cat /root/train-service-log/train.log可以看到,訓練任務從最新的Checkpoint繼續訓練。
root@ixxx:~# cat train-service-log/train.log Resume training from: /mnt/oss-data/output/checkpoint-10 run sh: /usr/bin/python3 /usr/local/lib/python3.10/dist-packages/xxx s-data/self-cognition#500 --torch_dtype bfloat16 --num_train_epochs xxx --eval_steps 50 --save_steps 10 --save_total_limit 5 --logging_steps xxx --num_workers 4 --model_author swift --model_name swift-robot --resume xxx
後續步驟
使用微調完成後的模型進行推理
釋放本文涉及資源
在生產環境應用本方案的建議
在將本方案應用於生產環境前,您需要根據實際業務情況,並參考以下建議,改進方案。
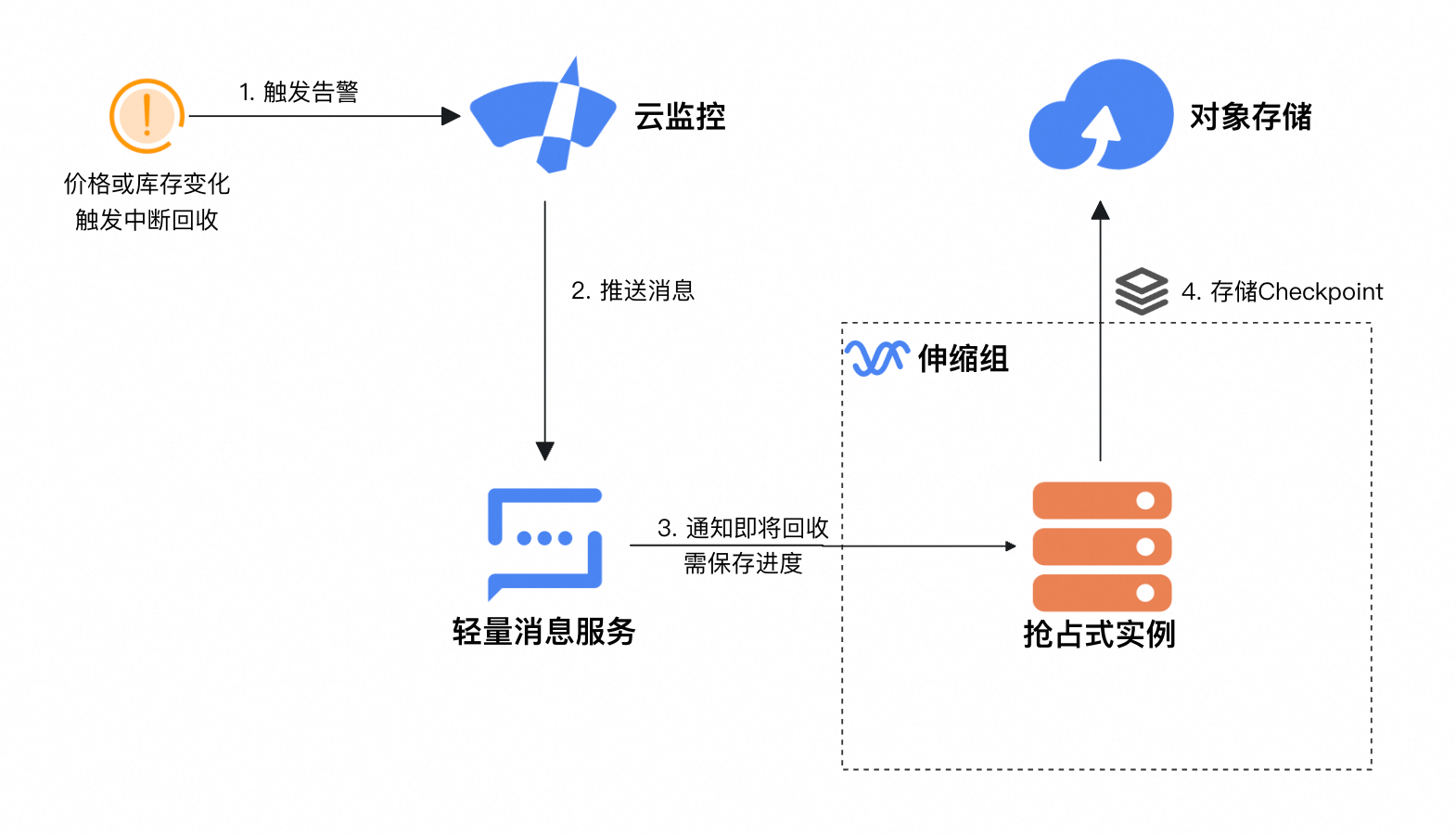
接入CloudMonitor,感知中斷回收並響應
在生產環境中應用該方案,建議在訓練代碼中接入CloudMonitor,感知並響應搶佔式執行個體中斷事件,在中斷回收前5分鐘儲存Checkpoint檔案,以減少恢複訓練時的進度損失。改良後的架構如下:
建立完善的任務恢複機制
本文樣本中恢複訓練時,會自動從最新的Checkpoint恢複,但不會檢測其有效性。在實際應用中,建議建立異常檢測機制,以排除無效Checkpoint,並自動從最新的有效Checkpoint恢複訓練。
完善訓練任務執行結束的操作
您可以在訓練代碼中補充訓練結束的判斷邏輯,在訓練結束時使用CLI或SDK等方式調用伸縮組的API,將期望執行個體數修改為0,伸縮組會自動根據期望執行個體數釋放多餘執行個體,避免資源浪費造成的額外開支。
此外,還可以在任務完成時,向CloudMonitor上報自訂事件,將訓練執行結果以郵件、簡訊、DingTalk機器人等方式通知到您。
使用效率更高的OSFS儲存模型與Checkpoint檔案
訓練大參數量模型時,Object Storage Service可能成為系統瓶頸,建議使用高吞吐、低延遲的CPFS替代Object Storage Service作為檔案系統掛載,以提高系統整體效率。
配置多可用性區域交換器,提高搶佔式執行個體的使用機率
僅配置單個可用性區域交換器時,伸縮組僅能從一個可用性區域建立執行個體,容易因庫存不足導致擴容失敗。建議配置多個可用性區域的交換器,在搶佔式執行個體被回收時,系統會自動嘗試從其他可用性區域建立新的搶佔式執行個體,有效提高搶佔式執行個體的使用機率。