為LLM(Large Language Model)應用安裝Python探針後,ARMS即可開始監控LLM應用,您可以在Token分析頁面瞭解LLM應用中的Token使用方式。
在大模型應用中,Token 是文本處理的基本單位,用於表示模型輸入和輸出的最小語義單元。Token 可以是一個單詞、一個子詞(subword)或一個字元,具體取決於模型的分詞方式(Tokenizer)。
前提條件
已為LLM應用安裝探針,具體操作,請參見LLM 大語言模型應用/推理服務接入 ARMS。
查看LLM應用Token分析
-
登入ARMS控制台,在左側導覽列選擇。
-
在应用列表頁面頂部選擇目標地區,然後單擊目標應用程式名稱。
-
在上方導覽列單擊Token分析。
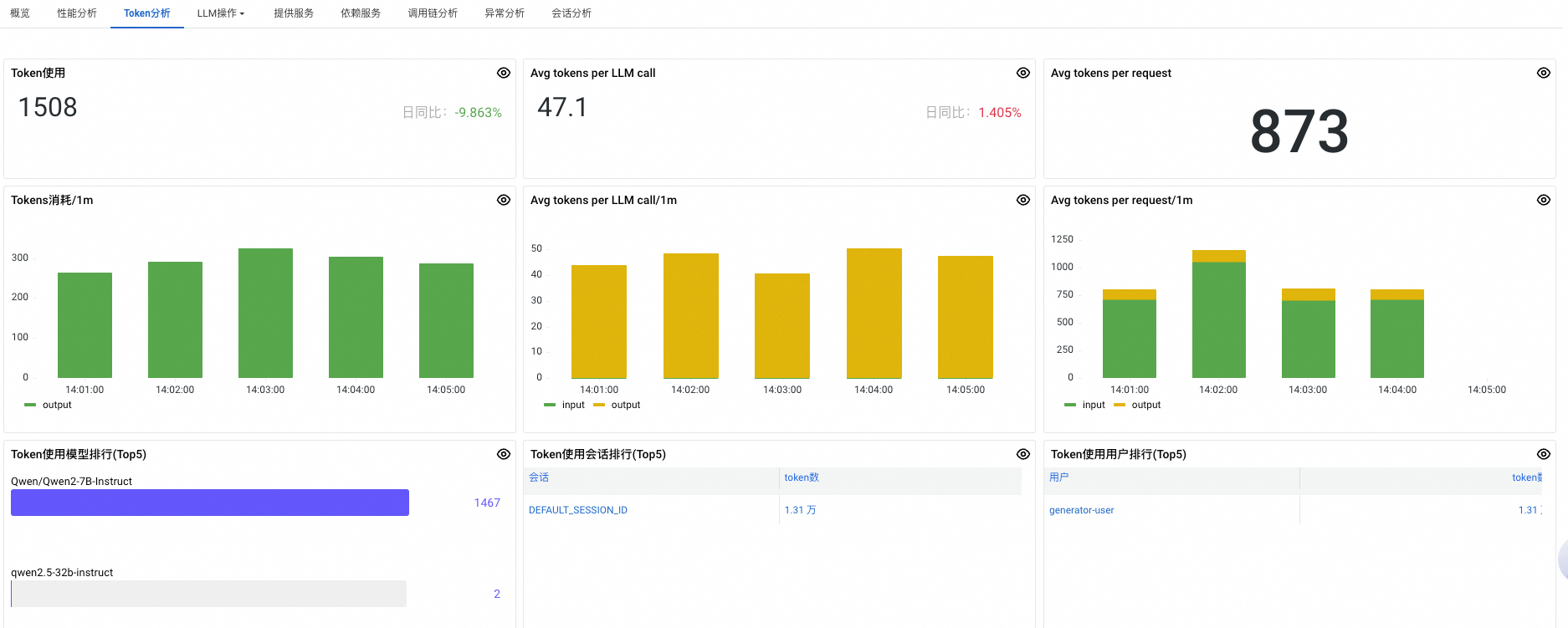
面板
說明
Token使用
指定時間段內所有模型調用消耗的 Token 總量。
Avg tokens per LLM call
每次模型調用(LLM Call)平均消耗的 Token 數量。
Avg tokens per request
每個使用者請求(Request)平均消耗的 Token 數量。
Tokens消耗/1m
每分鐘內所有模型調用消耗的 Token 總量。
Avg tokens per LLM call/1m
每分鐘內每次模型調用平均消耗的 Token 數量。
Avg tokens per request/1m
每分鐘內每個使用者請求平均消耗的 Token 數量。
Token使用模型排行(Top5)
按 Token 消耗總量從高到低排序,展示 Token 使用最多的前5個模型。
Token使用會話排行(Top5)
按 Token 消耗總量從高到低排序,展示 Token 使用最多的前5個會話(Session)。
Token使用使用者排行(Top5)
按 Token 消耗總量從高到低排序,展示 Token 使用最多的前5個使用者。