為Java應用安裝探針後,ARMS即可開始監控Java應用,您可以在執行個體監控頁面瞭解應用的基礎監控、執行個體GC和JVM記憶體等資訊。
前提條件
ARMS應用監控面向已開通新版計費的使用者提供全新的監控詳情頁面,新版計費詳情,請參見產品計費(新版)。
對於未開通新版計費的使用者,如需查看新版監控詳情頁面,可在應用列表頁面單擊切換新版。
已為應用安裝探針,具體操作,請參見應用監控接入概述。
查看執行個體監控
登入ARMS控制台,在左側導覽列選擇。
在應用列表頁面頂部選擇目標地區,然後單擊目標應用程式名稱。
說明語言列的表徵圖含義如下:
 :接入應用監控的Java應用。
:接入應用監控的Java應用。 :接入應用監控的Golang應用。
:接入應用監控的Golang應用。 :接入應用監控的Python應用。
:接入應用監控的Python應用。-:接入Managed Service for OpenTelemetry的應用。
在上方導覽列單擊執行個體監控。
頁面說明
執行個體監控頁面會根據應用接入的資訊自動適配展示大盤,並針對ECS環境和容器環境做區別展示。
在容器情境下,如果已經接入Managed Service for Prometheus,則優先以Managed Service for Prometheus資料作為容器資訊的展示。容器環境接入Managed Service for Prometheus的操作,請參見容器可觀測。
容器環境如果未接入Managed Service for Prometheus,需要確保應用監控探針版本在4.1.0或以上,對應資料展示容器的基礎資訊。應用監控探針說明,請參見探針(Java Agent)版本說明。
ECS環境
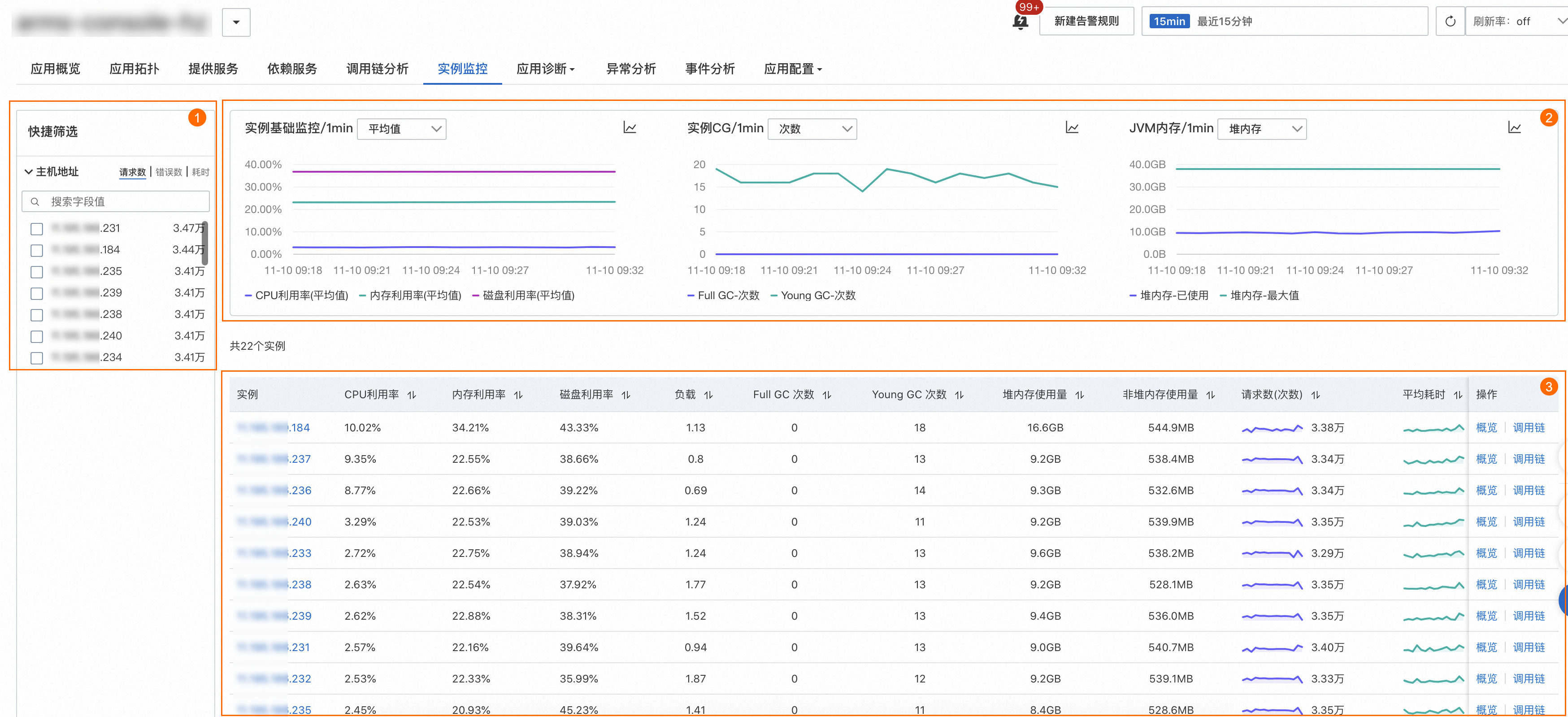
在快捷篩選區域(圖示①),您可以按主機地址對圖表、執行個體列表進行篩選。
在趨勢圖地區(圖示②),您可以查看執行個體的基礎監控、執行個體GC和JVM記憶體的時序曲線。
基礎監控:應用在指定時間範圍內CPU、記憶體和磁碟使用率趨勢圖。通過表徵圖名稱右側的下拉框可以切換展示各使用率的平均值和最大值。
執行個體GC:應用在指定時間範圍內Full GC和Young GC的趨勢圖。通過圖表名稱右側的下拉框可以切換展示GC的次數和平均耗時。
JVM記憶體:應用在指定時間範圍內堆記憶體已使用和最大值趨勢圖。通過表徵圖名稱右側的下拉框可以切換展示非堆記憶體已使用和最大值趨勢圖。
說明ARMS應用監控採集的資料來自JMX,其中非堆記憶體所包含的記憶體地區比Java進程中實際的非堆記憶體地區少,因此可能會出現監控中堆記憶體+非堆記憶體總和與通過
top命令看到的RES大小存在一定差值,相關細節請參見JVM監控記憶體詳情說明。
單擊
 表徵圖,可以在彈出的對話方塊中查看該指標在某個時間段的統計情況或對比不同日期在同一時間段的統計情況,通過選擇
表徵圖,可以在彈出的對話方塊中查看該指標在某個時間段的統計情況或對比不同日期在同一時間段的統計情況,通過選擇 表徵圖可以切換柱狀圖、趨勢圖進行展示。
表徵圖可以切換柱狀圖、趨勢圖進行展示。在執行個體列表地區(圖示③),您可以查看執行個體IP、CPU利用率、記憶體利用率、磁碟利用率、負載、Full GC次數、Young GC次數、堆記憶體使用量量、非堆記憶體使用量量、RED三指標(請求數、錯誤數、平均耗時)等資訊。
在執行個體列表,您可以執行以下操作:
容器環境(Prometheus版)
在快捷篩選區域(圖示①),您可以按叢集和主機地址對圖表、執行個體列表進行篩選。
在趨勢圖地區(圖示②),您可以查看執行個體的基礎監控、執行個體GC和JVM記憶體的時序曲線。
基礎監控:應用在指定時間範圍內CPU用量和記憶體用量趨勢圖。
執行個體GC:應用在指定時間範圍內Full GC和Young GC的趨勢圖。通過圖表名稱右側的下拉框可以切換展示GC的次數和平均耗時。
JVM記憶體:應用在指定時間範圍內堆記憶體已使用和最大值趨勢圖。通過表徵圖名稱右側的下拉框可以切換展示非堆記憶體已使用和最大值趨勢圖。
說明ARMS應用監控採集的資料來自JMX,其中非堆記憶體所包含的記憶體地區比Java進程中實際的非堆記憶體地區少,因此可能會出現監控中堆記憶體+非堆記憶體總和與通過
top命令看到的RES大小存在一定差值,相關細節請參見JVM監控記憶體詳情說明。
單擊
表徵圖,可以在彈出的對話方塊中查看該指標在某個時間段的統計情況或對比不同日期在同一時間段的統計情況,通過選擇表徵圖可以切換柱狀圖、趨勢圖進行展示。在執行個體列表地區(圖示③),您可以查看執行個體IP、CPU用量、CPU請求、CPU限制、CPU利用率(未設定CPU限制時,此項展示為-)、記憶體用量、記憶體請求、記憶體限制、記憶體利用率(未設定記憶體限制時,此項展示為-)、磁碟用量、磁碟限制、磁碟利用率(未設定磁碟限制時,此項展示為-)、負載、Full GC 次數、Young GC 次數、堆記憶體使用量量、非堆記憶體使用量量、RED三指標(請求數、錯誤數、平均耗時)等。
在執行個體列表,您可以執行以下操作:
容器環境(ARMS自採集版)
在快捷篩選區域(圖示①),您可以按主機地址對圖表、執行個體列表進行篩選。
在趨勢圖地區(圖示②),您可以查看執行個體的基礎監控、執行個體GC和JVM記憶體的時序曲線。
基礎監控:應用在指定時間範圍內CPU用量和記憶體用量趨勢圖。
執行個體GC:應用在指定時間範圍內Full GC和Young GC的趨勢圖。通過圖表名稱右側的下拉框可以切換展示GC的次數和平均耗時。
JVM記憶體:應用在指定時間範圍內堆記憶體已使用和最大值趨勢圖。通過表徵圖名稱右側的下拉框可以切換展示非堆記憶體已使用和最大值趨勢圖。
說明ARMS應用監控採集的資料來自JMX,其中非堆記憶體所包含的記憶體地區比Java進程中實際的非堆記憶體地區少,因此可能會出現監控中堆記憶體+非堆記憶體總和與通過
top命令看到的RES大小存在一定差值,相關細節請參見JVM監控記憶體詳情說明。
單擊
表徵圖,可以在彈出的對話方塊中查看該指標在某個時間段的統計情況或對比不同日期在同一時間段的統計情況,通過選擇表徵圖可以切換柱狀圖、趨勢圖進行展示。在執行個體列表地區(圖示③),您可以查看執行個體IP、CPU用量、記憶體用量、負載、Full GC 次數、Young GC 次數、堆記憶體使用量量、非堆記憶體使用量量、RED三指標(請求數、錯誤數、平均耗時)等。
在執行個體列表,您可以執行以下操作:
執行個體詳情
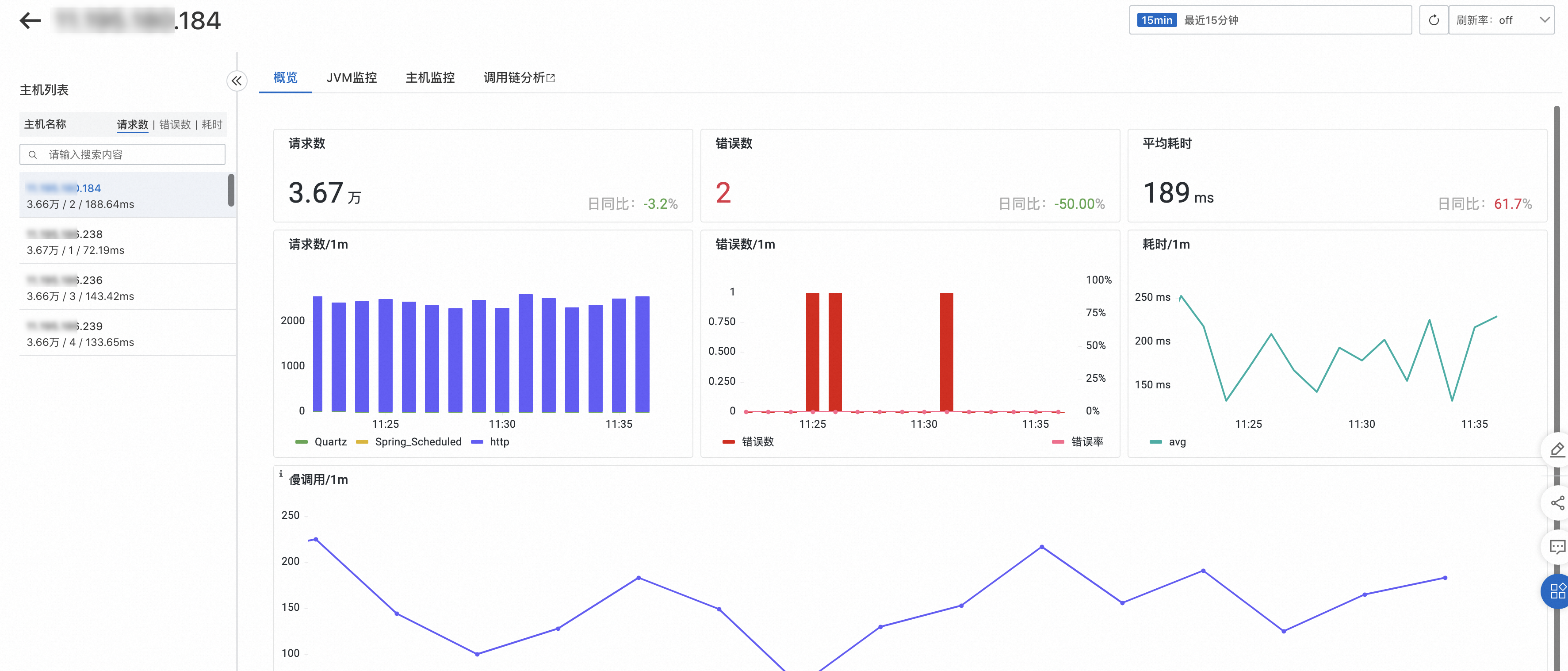
概覽
概覽頁簽可以查看目標介面的請求數、錯誤數、平均耗時和慢調用資訊。
JVM監控
JVM監控頁簽可以查看對應執行個體的GC、記憶體、線程、檔案等資訊。

線程池監控
4.1.x及以上探針版本
線程池監控頁簽可以查看應用所使用的線程池的各項指標,包括線程池初始化線程配置、線程池運行態線程情況、線程池任務執行情況。
在頁簽頂部可以按線程池類型和名稱篩選需要查詢的線程池。

4.1.x以下探針版本
線程池監控頁簽可以查看應用所使用的線程池的核心線程數量、當前線程數量、最大線程數量、活躍線程數量、任務隊列容量等指標。

串連池監控
4.1.x及以上探針版本
串連池監控頁簽可以查看應用所使用的串連池的各項指標,包括串連池初始化線程配置和串連池運行態線程情況。
在頁簽頂部可以按串連池類型篩選需要查詢的串連池。

4.1.x以下探針版本
串連池監控頁簽可以查看應用所使用的串連池的最大串連數和活躍串連數指標。

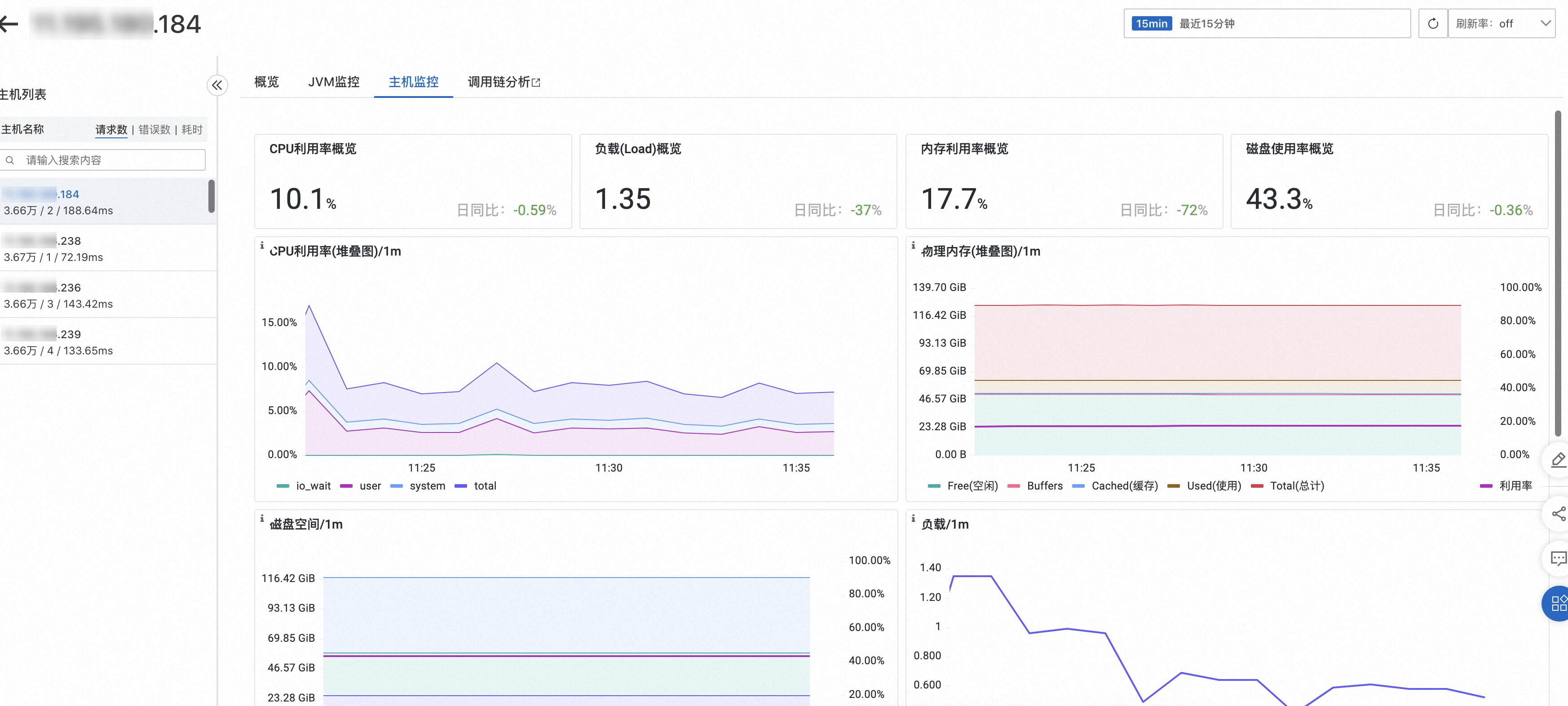
主機監控
主機監控頁簽可以查看CPU、記憶體、Disk(磁碟)、Load(負載)、網路流量和網路資料包的各項指標。
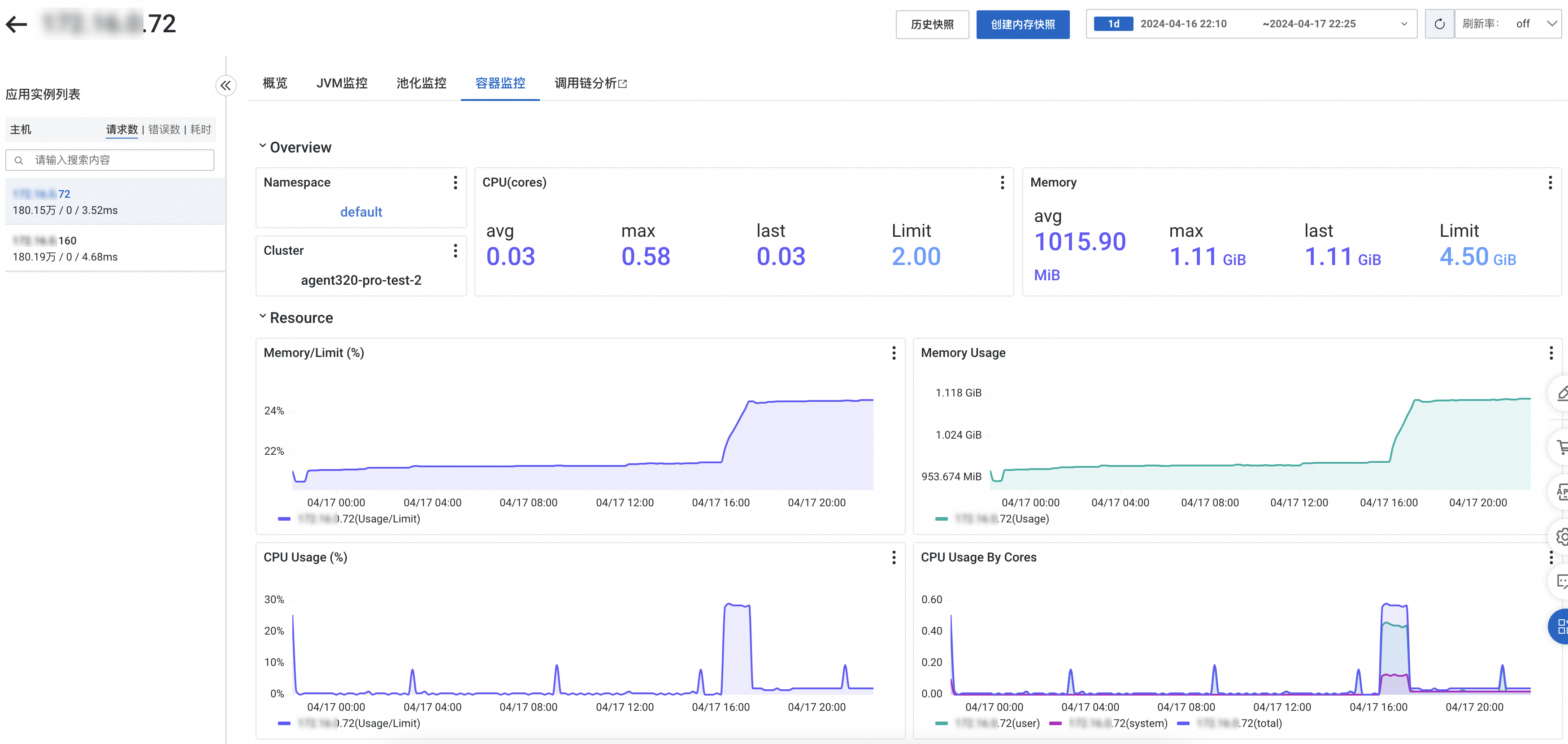
容器監控
容器環境(Prometheus版)
接入可觀測監控 Prometheus 版的操作請參見Prometheus執行個體 for Container Service。
容器監控頁簽可以查看容器視角的CPU、記憶體、Disk(磁碟)、Load(負載)、網路流量和網路資料包的各項指標。
容器環境(ARMS自採集版)
未接入可觀測監控 Prometheus 版的情況下,需要確保ARMS探針版本在4.1.0或以上。探針版本說明請參見探針(Java Agent)版本說明。
容器監控頁簽可以查看容器視角的CPU、記憶體、網路流量的時序曲線。
調用鏈分析
調用鏈分析功能基於已儲存的全量鏈路詳細資料,通過自由組合篩選條件與彙總維度進行即時分析,可以滿足不同情境的自訂診斷需求。更多資訊,請參見調用鏈分析。
相關文檔
應用監控詳細的指標資訊,請參見應用監控指標說明。
常見問題
應用層級的資料與單機的資料是什麼關係
RED(請求數、錯誤數、延遲)指標:
請求數、慢調用次數、HTTP狀態代碼次數:應用層級的資料是單機層級資料的匯總。
回應時間:應用層級的資料是單機層級資料的平均值。
JVM指標:
GC次數、GC耗時:應用層級的資料是單機層級資料的匯總。
堆記憶體資料、線程數:應用層級的資料是單機層級資料取最大值。
線程池/串連池指標
所有指標:應用層級的資料是單機層級資料的平均值。
系統指標
所有指標:應用層級的資料是單機層級資料取最大值。
SQL/NSQL調用:同RED指標,對於次數類指標,應用層級的資料是單機層級資料的匯總;對於其餘指標,應用層級的資料是單機層級資料的平均值。
異常指標:應用層級的資料是單機層級資料的匯總。
不同執行個體之間流量不均勻
在3.x版本探針中,如果開啟了記憶體最佳化開關,可能會導致部分指標統計丟失。該問題已在4.x版本探針中修複。
Undertow一次請求被統計成了兩次
3.2.x版本之前探針埋點方法在使用DeferredResult情境下一次調用中會被執行兩次。該問題已在3.2.x及以上版本中修複。
容器監控中CPU/記憶體配額與Pod實際設定不一致
請檢查您的Pod中是否定義了多個Container,該指標會統計所有Container加起來的總配額。
系統指標部分缺失、不準或者CPU使用率展示為100%
4.x之前版本探針不支援Windows環境下系統指標採集,4.x及以後版本探針已經修複。
為什麼應用剛啟動會FullGC
一般是因為使用者沒有配置元空間大小,預設的元空間大小約為20 MB,應用在剛啟動的時候可能會進行元空間的擴容從而觸發FullGC,可通過-XX:MetaspaceSize參數和-XX:MaxMetaspaceSize參數設定初始元空間和最大元空間大小。
VM Stack指標是如何計算的
該指標是通過存活(state=live)線程數×1 MB得到的,其中1 MB是線程堆棧預設大小。如果通過-Xss參數重新指定了線程堆棧大小,則該資料與實際情況會有差異。
state=live包含以下狀態:live、blocked、new、runnbale、timed-wait和wait。
JVM指標擷取原理
ARMS展示的JVM指標均是通過標準的JDK介面擷取的,對應介面如下:
記憶體相關指標:
ManagementFactory.getMemoryPoolMXBeans
java.lang.management.MemoryPoolMXBean#getUsage
GC相關指標:
4.4.0以下版本探針
ManagementFactory.getGarbageCollectorMXBeans
java.lang.management.GarbageCollectorMXBean#getCollectionCount
java.lang.management.GarbageCollectorMXBean#getCollectionTime
4.4.0及以上版本探針
通過訂閱由 GarbageCollectorMXBean提供的 GarbageCollectionNotificationInfo事件擷取。
為什麼JVM最大堆記憶體值為-1
-1代表未設定最大堆記憶體大小。
為什麼JVM堆記憶體使用量總量不等於設定的堆記憶體最大值
根據JVM記憶體配置機制,-Xms參數指定初始堆記憶體配置,當空餘堆記憶體不足後擴容,直到達到-Xmx參數設定的最大值,總量與最大量不一致說明還沒觸發擴容,使用量是當前實際用量。
JVM GC的頻率逐漸加快
可能是使用了JDK 8預設的GC演算法ParallelGC,該演算法預設開啟了-XX:+UseAdaptiveSizePolicy,其作用是自動調整堆的大小,包括新生代大小、SurvivorRatio等參數,為了滿足GC的停頓時間,當Young GC比較頻繁時,可能會動態縮小Survivor區的大小,這時候Survivor區的對象很容易晉陞到Old區,導致Old區空間漲幅過快,從而觸發Full GC的頻率也加快。更多資訊,請參見Java官方文檔。
線程池、串連池監控沒有資料
在自訂配置頁面的進階設定地區確認是否已經開啟線程池、串連池監控開關。
檢查架構是否在支援的範圍內,具體內容,請參見線程池和串連池監控。
HikariCP串連池擷取的最大串連數與實際不符
3.2.x版本之前的探針擷取最大串連數代碼有誤,3.2.x及以上版本已經修複。
池化監控指標展示數值是小數
探針每隔15s採集一次,因此一分鐘會採集4個點的資料,控制台會根據採集資訊展示一個時間段的平均值。例如:一分鐘採集的4個資料點為0、 0、 1、 0,理論上平均值為0.25。
線程池/串連池明明被打滿了,但為什麼監控上沒有體現出來
如果您的日誌或其他記錄中確實看到線程池/串連池被打滿,但是ARMS控制台卻看不到相關指標的增長,有可能是由於指標採樣時間點與打滿的時間點錯開導致的。目前ARMS自動採集線程池/串連池狀態指標的時間間隔為15s,發生在這個時間段內的瞬時沖高可能不會被採集到。
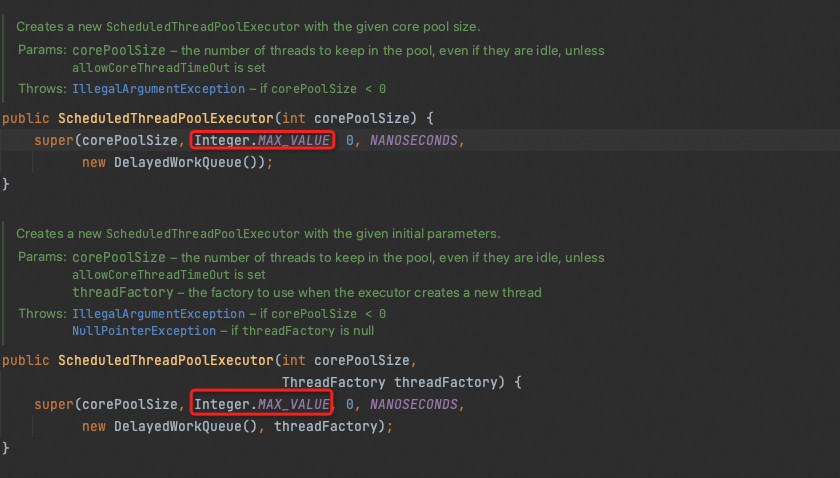
線程池監控最大線程數不符合預期或者最大線程數為21億
ARMS最大線程池是直接調用線程池對象的擷取最大線程數方法得到的,一般不會出錯。如果不符合使用者預期可能是使用者佈建的最大線程數未生效。
如果最大線程數為21億,通常是調度線程池,在調度線程池中,預設設定的最大線程數是Integer.MAX_VALUE,如下圖所示。
Tomcat 線程池監控各項指標均不符合預期
ARMS線程池指標是直接調用線程池對象的相應方法得到的,一般不會出錯。如果幾個維度都匹配不上(最大線程數、活躍線程數、核心線程數等),請先確認您的應用是否通過多個連接埠對外提供了 Tomcat 服務(如 spring-actuator 這類組件也會開放一個連接埠暴露指標),這種情況下探針會由於維度收斂機制將多個線程池的資料混在一起統計。如果資料混在一起,可以將探針版本升級到 4.1.10 及以上,並在頁面的池化監控配置地區,修改線程池線程名模式提取策略為替換結尾數字字元為*來解決。
某個線程池/串連池在某個時間點前無資料
由業務自行觸發了定時任務,任務初始化時產生了線程池/串連池資料,而定時任務被觸發前則沒有對應的線程池/串連池。流量型資料通常也會存在此類問題,例如某個介面的請求數。
HTTPClient串連池無資料
從ARMS 4.x版本探針開始,ARMS不再支援okHttp3、Apache HTTPClient等架構的串連池監控,主要考慮此類架構會為當前應用的每一個外部存取網域名稱建立一個串連池對象,當訪問外部網域名稱較多時,整體開銷較高,存在穩定性風險,因此不再支援。
ACK環境應用接入後無法看到容器監控資料
可能原因是建立ACK叢集的阿里雲帳號與接入ARMS的阿里雲帳號不同,ARMS目前僅支援展示同一阿里雲帳號下的容器監控資料。
控制代碼開啟率不為0,而檔案控制代碼數為0
請確認應用環境是否為JDK 9+,且ARMS探針版本為3.x,如果是,是由於相關指標採集邏輯在該環境存在相容性問題,該問題已在4.2.2+版本探針中修複,建議升級探針到對應版本。
JVM進程的實際實體記憶體佔用和JVM監控中的堆記憶體佔用有較大差距
這種情況一般是因為JVM進程有較大的堆外記憶體佔用,ARMS目前僅能監控到JVM進程的堆內記憶體以及部分堆外記憶體佔用,具體一個JVM佔用記憶體中哪些可以被ARMS監控到哪些無法被監控到請參見JVM監控記憶體詳情說明,如果出現較大的堆外記憶體佔用,可以參見該文檔的堆外記憶體泄露分析章節自行分析。
為什麼串連池 Druid 即時的空閑串連數會超過設定的最大空閑串連數?
MaxIdle是Druid為了方便DBCP使用者移轉而增加的,實際上不會生效。
部分執行個體探針升級到了最新版本,但為什麼沒資料?
若探針是從4.1.x以下版本升級上來的,則需要將全部執行個體對應的探針升級到最新版本,頁面才能自動適配並進行資料展示。