通過儀錶盤、監控警示等可觀測功能,您可以對訊息收發各階段的重點指標和服務端狀態進行監控和觀測,並對重點指標設定警示規則以便及時上報異常。本文為您介紹如何將雲訊息佇列 RocketMQ 版可觀測性功能應用於雲訊息佇列 RocketMQ 版的故障管理情境中,為您的日常營運和故障處理提供實踐方案。
設計思路
核心問題
營運情境下,故障處理的核心問題如下:
服務出現異常如何預警並上報
出現異常問題如何快速定位
解決方案
雲訊息佇列 RocketMQ 版定義的Metrics、Tracing指標覆蓋訊息收發各階段的狀態資訊、雲訊息佇列 RocketMQ 版服務端及資源的輸送量等資料。具體使用時可將這些指標大致分為以下三類:
一級指標:建議將沒有歧義的、可衡量業務正常啟動並執行指標作為一級指標,這些指標出現異常則一定是業務鏈路出現問題,一般可用做監控警示項。
例如,訊息收發TPS超過規格限制可觸發執行個體流控,您可以將執行個體訊息收發TPS指標作為監控項並建立警示規則,可以有效避免執行個體被流控處理,影響訊息收發。
二級指標:建議將能夠明確反映問題所在位置的指標作為二級指標。
例如,訊息堆積量可明確反映訊息消費階段出現問題;訊息生產調用成功率則可以明確反映訊息發送階段是否正常。
三級指標:三級指標可作為對二級指標的進一步分析,通過三級指標能夠高效定位二級指標波動的具體原因。
消費異常情境實踐方案
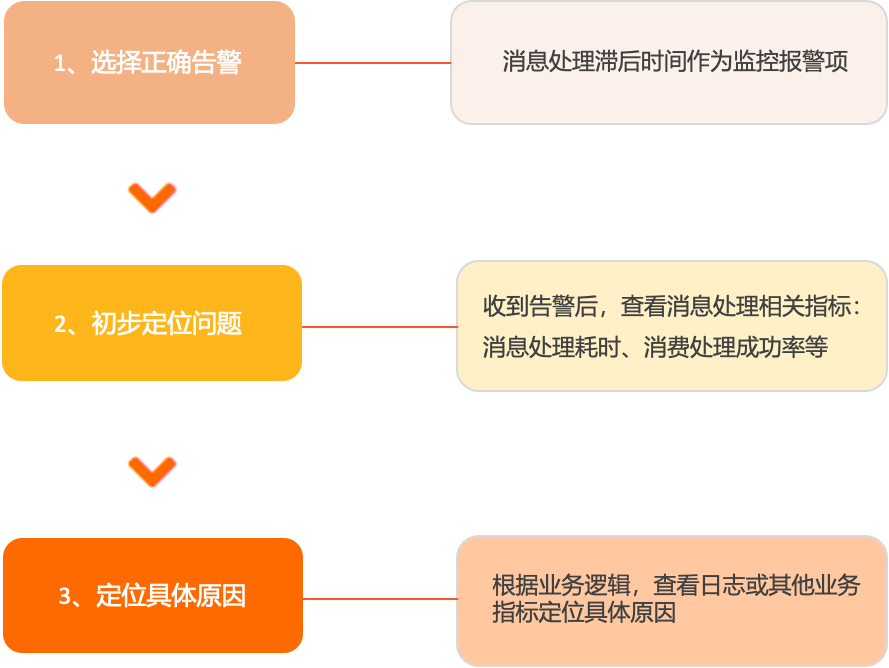
使用訊息處理延遲時間(ConsumerLagLatencyPerGidTopic)作為監控指標項並建立警示規則。具體操作,請參見監控警示。
該指標可明確反映消費鏈路的健康情況,並直接關聯業務影響程度,比訊息堆積量更加準確且沒有歧義。
訊息量少時,使用訊息堆積量作為警示監控項,不容易觸發警示閾值。
訊息量大時,使用訊息堆積量作為警示監控項,容易頻繁產生誤判。
訊息量波動較大時,無法準確設定訊息堆積量警示閾值。
查看訊息處理耗時(rocketmq_process_time)和訊息處理成功率(rocketmq_process_time_count{invocation_status="success"/invocation_status="success|failure"} )等指標是否異常,初步定位是否是消費者用戶端的問題。
訊息處理成功率=訊息處理成功次數/訊息處理失敗次數+成功次數。
查詢方式,請查看儀錶盤中,消費者指標下的統計面板。
根據商務邏輯或指標的變化趨勢定位具體原因,例如訊息處理耗時變長,則可以查看消費者服務的記憶體、CPU等是否過載;或查看消費邏輯依賴的下遊商務邏輯的運行狀態進行進一步分析。
生產異常情境實踐方案
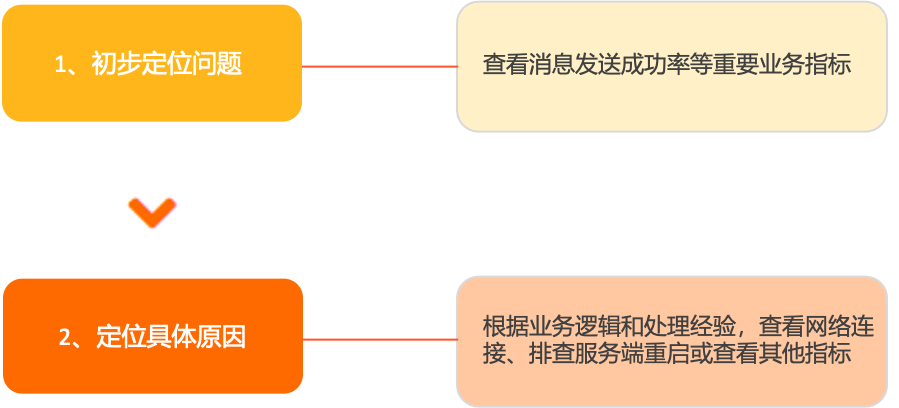
查看訊息發送成功率(rocketmq_send_cost_time_count{invocation_status="success"/invocation_status="success|failure"})是否正常,訊息發送成功率=訊息發送成功次數/訊息發送失敗次數+成功次數。
查詢方式,請查看儀錶盤中,生產者指標下的統計面板。
根據經驗檢查網路是否正常,或檢查是否是服務端重啟造成的短期發送失敗。