本文介紹如何建立使用OSS Sink Connector,您可以通過OSS Sink Connector將資料從雲訊息佇列 Kafka 版的資料來源Topic匯出至Object Storage Service的Object中。
前提條件
詳細步驟,請參見建立前提。
注意事項
Connector基於事件被處理的時間做時間分區,非事件的產生時間,如按時間分區,時間邊界的資料可能被投遞至下一個時間分區目錄。
髒資料處理問題:如果在任務的自訂分區或檔案內容中配置了JsonPath,但資料未命中JsonPath規則,Connector會將這類資料按攢批策略投遞到Bucket下的invalidRuleData/路徑。如發現Bucket下有此目錄,請檢查JsonPath規則的正確性,且避免消費端漏消費資料。
鏈路可能存在秒級到分鐘層級內的延時。
如果自訂分區或檔案內容中配置的JsonPath規則需對Kafka Source訊息內容做提取,需在Kafka Source側將內容編解碼為Json格式。
Connector即時將上遊資料以Append追加方式寫入OSS中,因此單個分區路徑下,可見的最新檔案通常處於寫入中的狀態,而非目標狀態,請謹慎消費。
計費說明
Connector任務運行在阿里雲Function Compute平台,任務加工傳輸產生的計算資源將按Function Compute單價計費,詳情請參見計費概述。
步驟一:建立目標服務資源
在Object Storage Service控制台建立一個儲存空間(Bucket)。詳細步驟,請參見控制台建立儲存空間。
本文以oss-sink-connector-bucket Bucket為例。
步驟二:建立OSS Sink Connector並啟動
登入雲訊息佇列 Kafka 版控制台,在概览頁面的资源分布地區,選擇地區。
在左側導覽列,選擇。
在工作清單頁面,單擊建立任務。
任務建立
在Source(源)設定精靈,選擇数据提供方為訊息佇列 Kafka 版,設定以下參數,然後單擊下一步。
參數
說明
樣本
地區
選擇雲訊息佇列 Kafka 版源執行個體所在的地區。
華北2(北京)
kafka 執行個體
選擇生產雲訊息佇列 Kafka 版訊息的源執行個體。
alikafka_post-cn-jte3****
Topic
選擇生產雲訊息佇列 Kafka 版訊息的Topic。
demo-topic
Group ID
選擇源執行個體的消費組名稱。
快速建立:推薦方案,自動建立以
GID_EVENTBRIDGE_xxx命名的 Group ID。使用已有:請選擇獨立的Group ID,不要和已有的業務混用,以免影響已有的訊息收發
快速建立
消費位點
選擇開始消費訊息的位點。
最新點位
最早點位
最新位點
網路設定
選擇路由訊息的網路類型。
基礎網路
自建公網
基礎網路
Virtual Private Cloud
選擇VPC ID。當網路設定設定為自建公網時需要設定此參數。
vpc-bp17fapfdj0dwzjkd****
交換器
選擇vSwitch ID。當網路設定設定為自建公網時需要設定此參數。
vsw-bp1gbjhj53hdjdkg****
安全性群組
選擇安全性群組。當網路設定設定為自建公網時需要設定此參數。
alikafka_pre-cn-7mz2****
数据格式
資料格式是針對支援二進位傳遞的資料來源端推出的指定內容格式的編碼能力。支援多種資料格式編碼,如無特殊編碼訴求可將格式設定為Json。
Json(Json格式編碼,位元據按照utf-8 編碼為Json格式放入Payload。)
Text(預設文字格式設定編碼,位元據按照utf-8編碼為字串放入Payload。)
Binary(二進位格式編碼,位元據按照Base64編碼為字串放入Payload。)
Json
批量推送条数
調用函數發送的最大批量訊息條數,當積壓的訊息數量到達設定值時才會發送請求,取值範圍為 [1,10000]。
100
批量推送间隔(单位:秒)
調用函數的間隔時間,系統每到間隔時間點會將訊息彙總後發給Function Compute,取值範圍為[0,15],單位為秒。0秒錶示無等待時間,直接投遞。
3
在Filtering(过滤)設定精靈,設定資料模式内容過濾發送的請求。更多資訊,請參見事件模式。
在Transform(转换)設定精靈,設定資料清洗,實現分割、映射、富化及動態路由等繁雜資料加工能力。更多資訊,請參見使用Function Compute實現訊息資料清洗。
在Sink(目标)設定精靈,選擇服务类型為Object Storage Service,配置以下參數,單擊儲存。
參數
說明
樣本
OSS Bucket
已建立的Object Storage Service Bucket。
重要保證填寫的Bucket已手動建立完成,且在任務運行期間不被刪除。
OSS儲存類型請選擇為標準儲存、低頻儲存,暫不支援投遞至Archive StorageBucket。
建立OSS Sink Connector任務後,平台將在此OSS Bucket一級目錄下產生.tmp/系統檔案路徑,請勿刪除和使用該路徑下的OSS Object。
oss-sink-connector-bucket
儲存路徑
OSS Object規則分Path和Name兩部分,例如ObjectKey為
a/b/c/a.txt時,Path為a/b/c/,Name為a.txt,其中自訂分區(即Path)可自訂。Name由Connector內部按關聯規則產生:{毫秒層級unix 時間戳記}_{8位隨機字串},例如:1705576353794_elJmxu3v。如未配置,或配置為 "/",表示無分區,資料將儲存在Bucket一級目錄下。
支援時間變數參數,{yyyy}、{MM}、{dd}、{HH} ,分別代表年、月、天、小時,大小寫敏感。
支援JsonPath規則自訂OSS路徑參數,例如: {$.data.topic}、{$.data.partition}。JsonPath變數需滿足標準JsonPath運算式,受限於OSS路徑規則,通過JsonPath提取值的類型建議為int、string,且值中全部為標準UTF-8字元,不包含空格、".."、Emoji、"/"、 "\"等字元,否則可能會產生資料寫入異常風險。
支援常量。
說明分區配置可以對資料做合理分組,避免單路徑下小檔案過多造成不可控問題。
Connector 的吞吐能力和分區數正相關,無分區或分區少時 Connector 吞吐較弱,可能造成上遊堆積問題。分區較多會導致資料分散、寫入次數增多、片段檔案多等問題,因此分區的配置策略非常關鍵,因為以下為參考建議:
Kafka Source:可同時按時間和 partition 分區,當效能無法滿足時,可通過提升 kafka partition 數量間接提升 Connector 吞吐,例如:prefix/{yyyy}/{MM}/{dd}/{HH}/{$.data.partition}/
業務分組:按照資料中的某個業務欄位分區,此時吞吐速率取決於業務欄位取值的數量,例如:prefixV2/{$.data.body.field}/
不同的任務建議配置不同的常量首碼,避免多個任務共用相同的分區,寫入同一目錄下造成資料混亂,無法區分。
alikafka_post-cn-9dhsaassdd****/guide-oss-sink-topic/YYYY/MM/dd/HH
批量彙總檔案大小
配置需要彙總的檔案大小,取值範圍為[1,1024],單位:MB。
說明Connector 將資料分批寫入到同一個 OSS Object 中,每一批資料大小為 (0 MB,16 MB],因此OSS Object最終大小可能會略大於配置值,最多超出16 MB。
在大流量情境下,建議彙總檔案大小配置百MB層級,例如128MB、512MB,彙總時間視窗配置小時層級,如60 min、120 min。
5
批量彙總時間視窗
配置需要彙總的時間視窗。取值範圍為[1,1440],單位:分鐘。
1
檔案壓縮
無需壓縮:產生的OSS Object無尾碼名。
GZIP:產生尾碼為.gz的 Object。
Snappy:產生尾碼為.snappy的Object。
Zstd:產生尾碼為.zstd的 Object。
當選擇壓縮後,Connector按壓縮前資料大小進行攢批,因此OSS側顯示的Object大小會小於攢批大小,解壓後大小接近攢批值。
無需壓縮
檔案內容
完整資料:Connector通過 CloudEvent協議封裝了原始訊息,完整資料表示包含CloudEvent協議後的資料。如下樣本中,data欄位內容為資料資訊,其他欄位為CloudEvent協議附加的Meta資訊。
{ "specversion": "1.0", "id": "8e215af8-ca18-4249-8645-f96c1026****", "source": "acs:alikafka", "type": "alikafka:Topic:Message", "subject": "acs:alikafka:alikafka_pre-cn-i7m2msb9****:topic:****", "datacontenttype": "application/json; charset=utf-8", "time": "2022-06-23T02:49:51.589Z", "aliyunaccountid": "182572506381****", "data": { "topic": "****", "partition": 7, "offset": 25, "timestamp": 1655952591589, "headers": { "headers": [], "isReadOnly": false }, "key": "keytest", "value": "hello kafka msg" } }資料提取:將JSONPath提取後的部分資料投遞至OSS,比如配置$.data,則僅將data 欄位的值投遞到OSS。
如果對CloudEvent協議的附加欄位無強需求,建議配置部分事件和$.data運算式,保證將Source的原始訊息投遞到OSS,降低儲存成本,提升傳輸效率。
資料提取
$.data
任務屬性
配置事件推送失敗時的重試策略及錯誤發生時的處理方式。更多資訊,請參見重試和死信。
返回任务列表頁面,找到建立好的任務,在其右側操作列,單擊启用。
在提示對話方塊,閱讀提示資訊,然後單擊确认。
啟用任務後,會有30秒~60秒的延遲時間,您可以在任务列表頁面的状态欄查看啟動進度。
步驟三:測試OSS Sink Connector
在工作清單頁面,在OSS Sink Connector任務的事件來源列單擊源Topic。
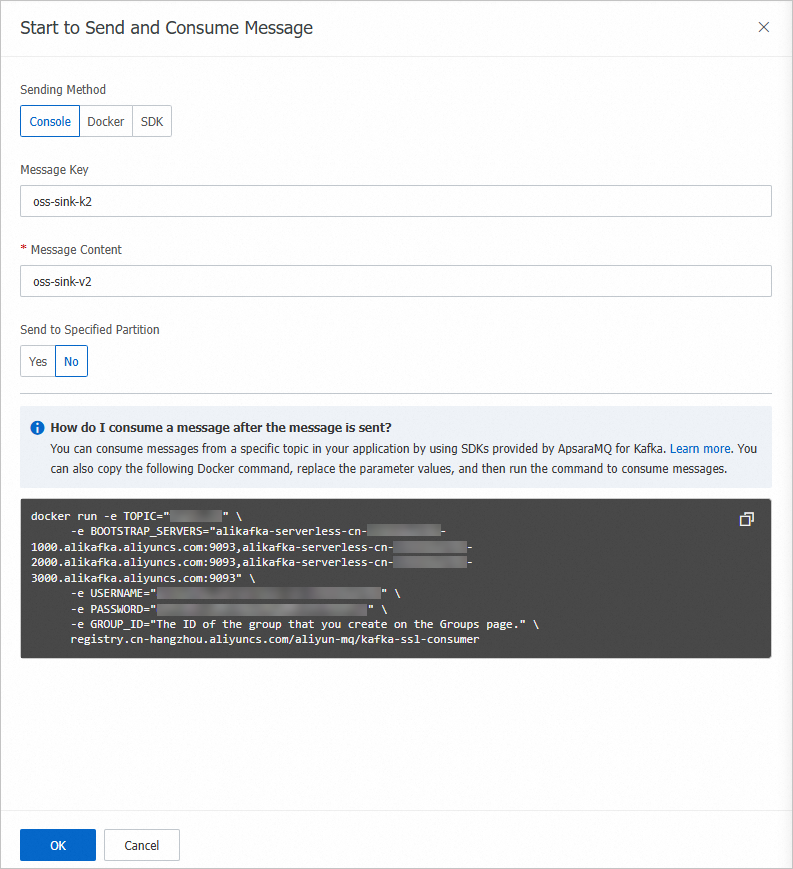
在Topic詳情頁面,單擊體驗發送訊息。
在快速體驗訊息收發面板,按照下圖配置訊息內容,然後單擊確定。
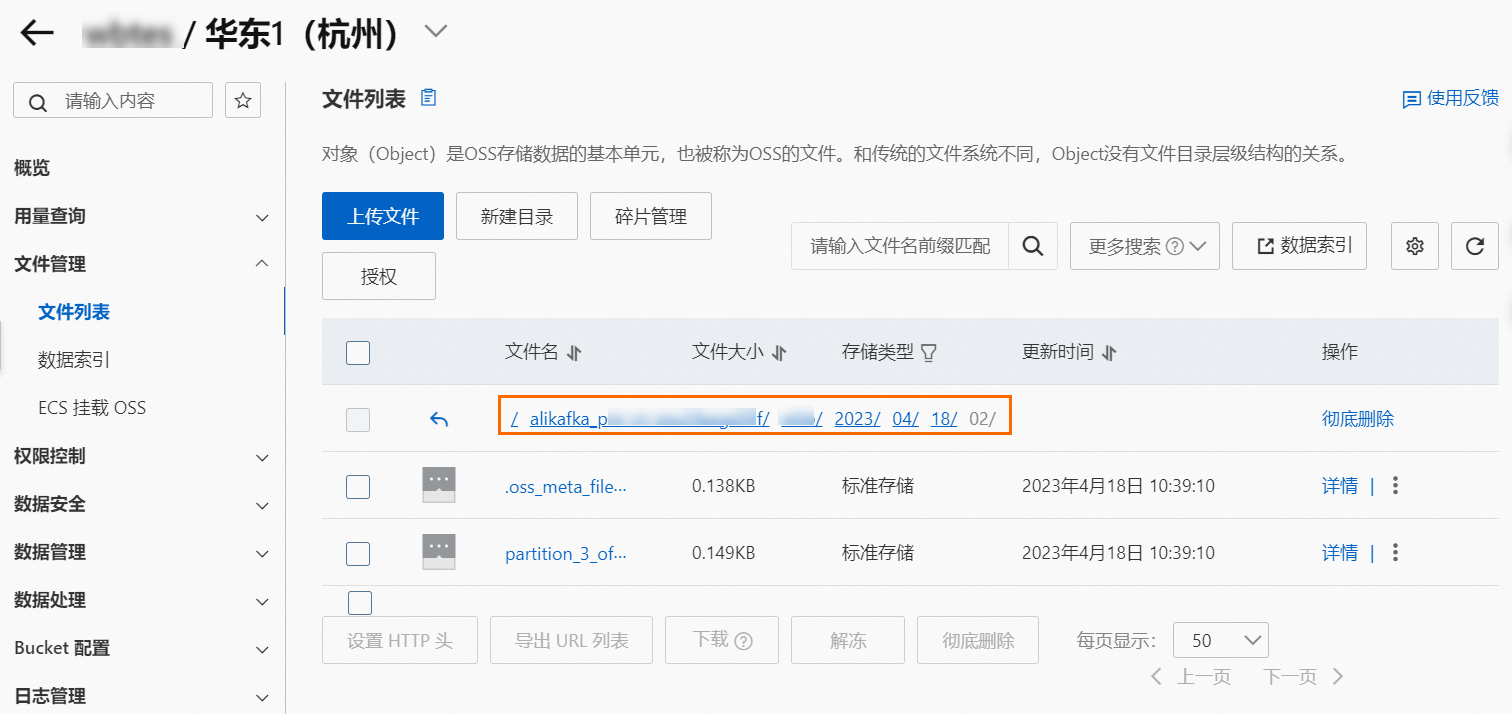
在工作清單頁面,在OSS Sink Connector任務的事件目標列單擊目標Bucket。
在Bucket頁面,選擇左側導覽列的。
tmp目錄:Connector依賴的系統檔案路徑,請勿刪除和使用該路徑OSS Object。
資料檔案目錄:目錄下按任務的分區路徑規則產生子目錄,並在最深層目錄下上傳資料檔案。
在對應Object右側操作列,選擇
 > 下載。
> 下載。開啟下載的檔案,查看訊息內容。

如圖所示,多條訊息之間通過換行分隔。