本文為您介紹警示堆積量和控制台堆積量不一致的原因。
問題現象
警示堆積量與控制台堆積量之間存在不一致現象。
可能原因
原因一
分區訊息堆積量=分區最大位點-分區消費位點,而訊息總堆積量則為各分區堆積量的總和。
例如:在一個執行個體中,有m個消費組和n個Topic,並且每個消費組都訂閱了所有Topic,在計算某個消費組的訊息堆積量時,有下面兩種方式:
一般請求方式
首先會發起一次RPC請求以擷取該消費組的消費位點,然後再發起一次RPC請求以擷取對應Topic的分區最大位點。此時,至少會產生
m * n * Broker節點數次RPC請求,這將大大影響監控的計算效率。批處理請求方式
先擷取所有消費組的消費位點,然後再批量請求擷取所有訂閱分區的最大位點。通過這種方式,能夠將RPC請求的次數從
m * n * Broker節點數縮減到僅為Broker節點數。由於批量請求的特性,擷取消費位點的時間和擷取分區最大位點的時間之間必然存在延遲,延遲期間分區的最大位點可能因訊息發送而持續增大。這將導致在擷取到消費位點與擷取到分區最大位點之間產生時間差,從而引發訊息堆積量的誤差。
控制台Group 詳情頁面中的訊息堆積總量是通過單獨請求當前消費組的消費位點和分區最大位點來擷取的,由於這兩輪RPC請求之間的時間差相對較小,因此和實際訊息堆積量的誤差較小。監控中的訊息堆積量採用批處理請求方式進行擷取,因擷取到消費位點與擷取到分區最大位點之間產生時間差,必然會導致堆積量的誤差,所以會出現警示堆積量與控制台堆積量之間存在不一致現象。
原因二
當使用者的消費速率過慢且磁碟容量水位過高時,執行個體中的訊息資料可能在未消費的情況下被刪除,從而導致Group的分區消費位點小於最小位點。這種情況下開源Kafka和雲訊息佇列 Kafka 版有不同的處理方式:
開源Kafka
統計堆積量時預設會忽略該堆積量。
雲訊息佇列 Kafka 版
為了協助您更快速地發現分區消費位點異常問題,監控警示策略會將該異常消費位點通過堆積警示的方式進行反饋,您可以根據實際情況進行處理。
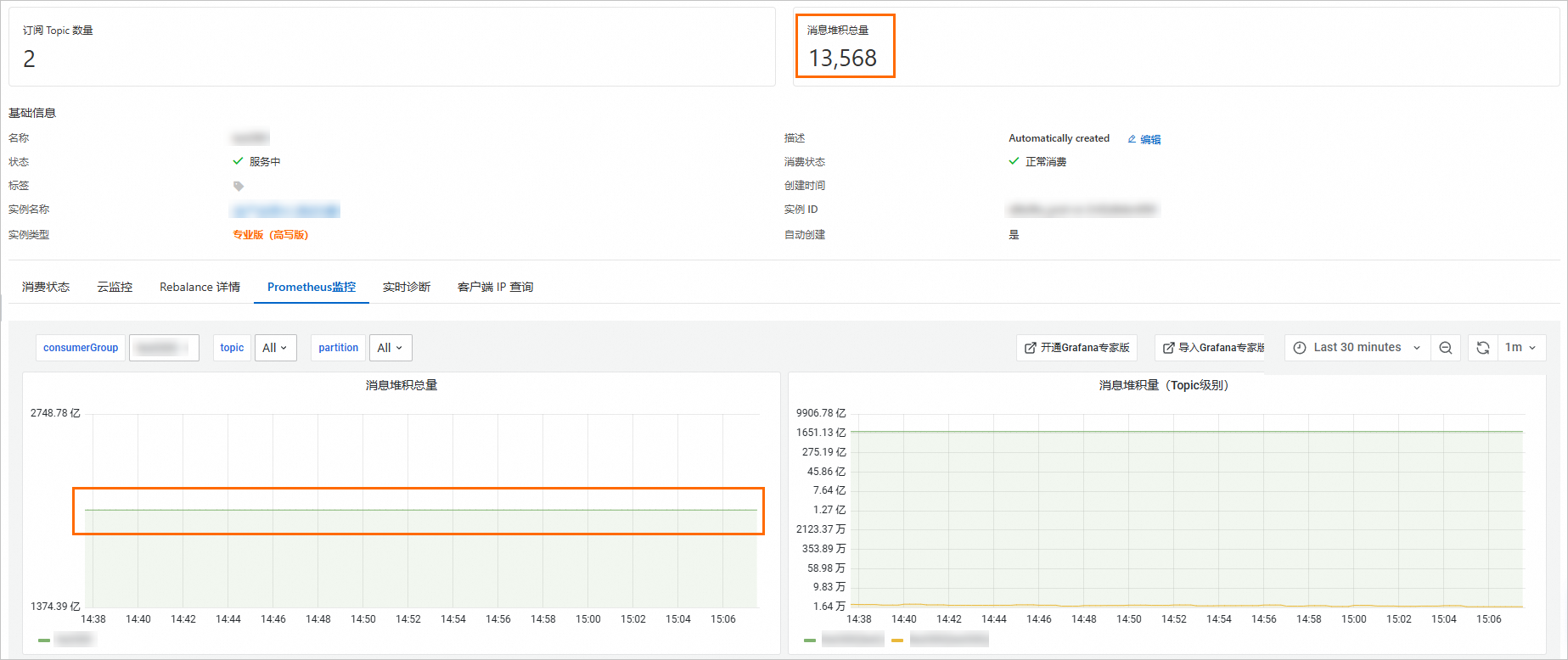
雲訊息佇列 Kafka 版為方便您在控制台上區分異常分區和正常分區,控制台Group 詳情頁面中的訊息堆積總量不會統計該異常堆積量,因此監控中的堆積量會遠大於控制台顯示訊息堆積量,所以會出現警示堆積量與控制台堆積量之間存在不一致現象。
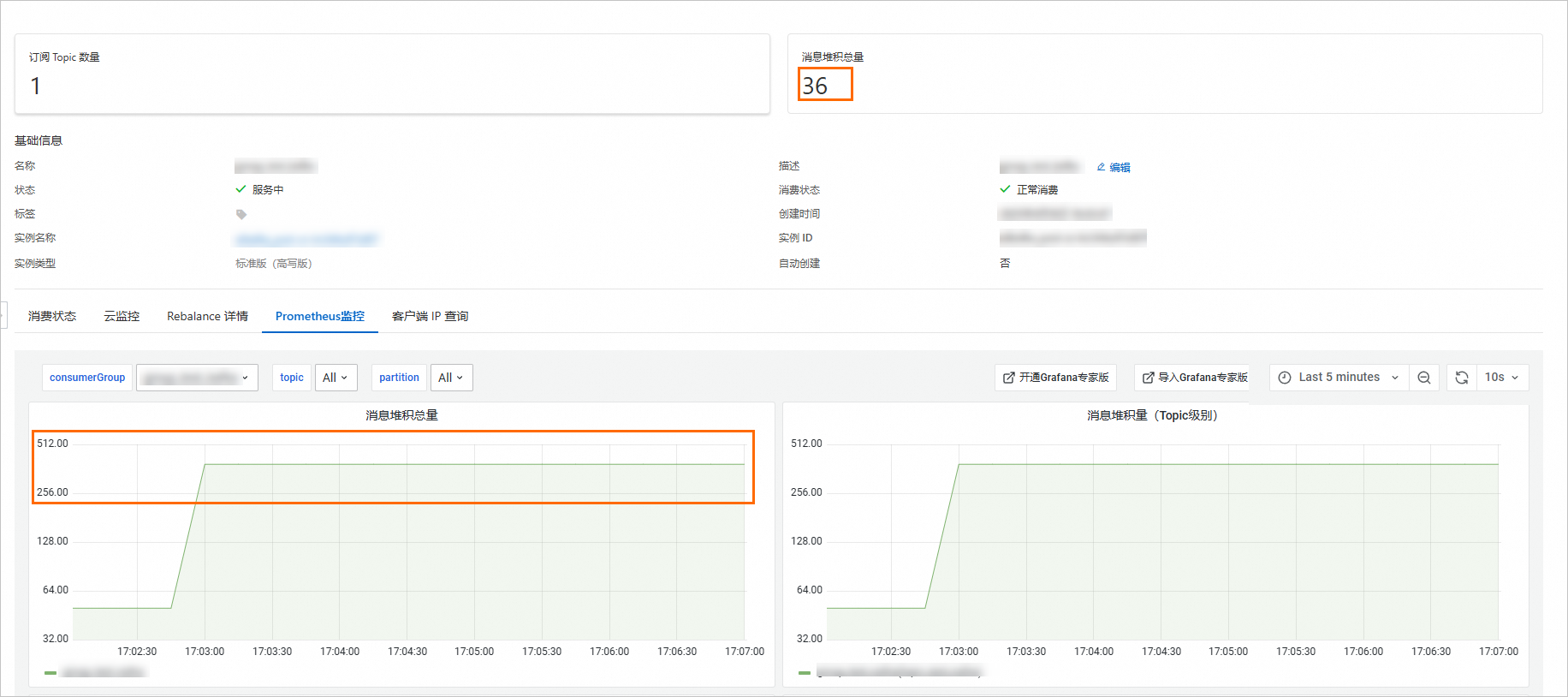
具體現象如下圖所示:
控制台訊息堆積總量和警示堆積總量不一致。
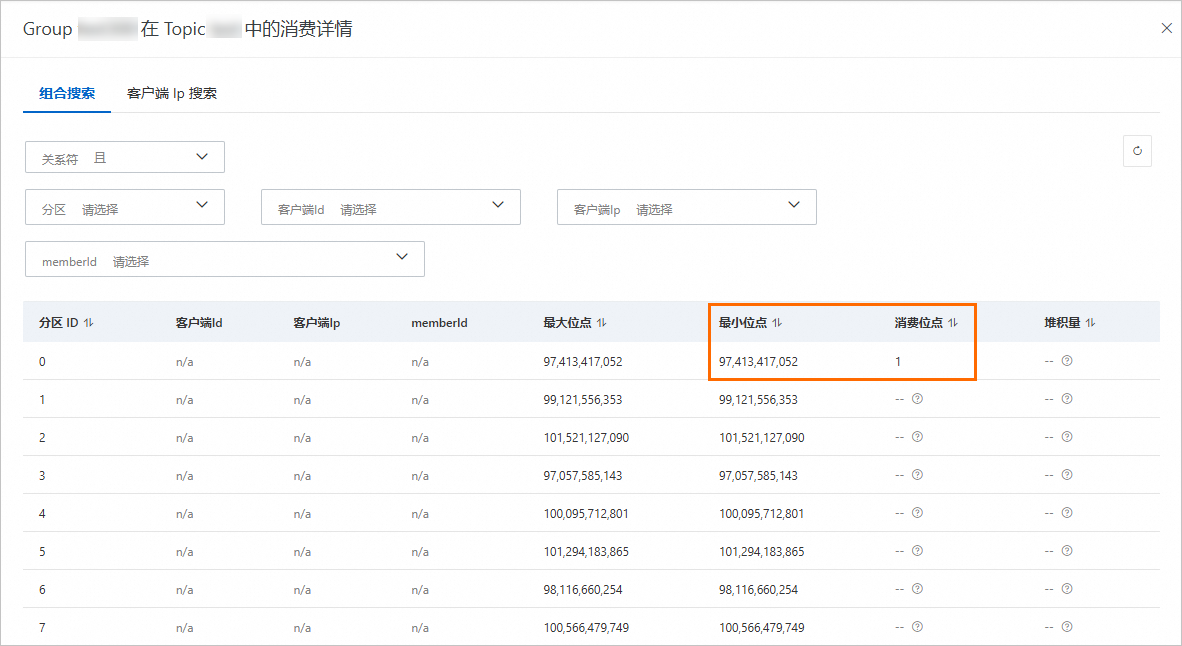
控制台訊息堆積總量沒有統計異常堆積量。

沒有統計異常堆積量的Topic消費詳情中存在分區消費位點小於最小位點的情況。